大数据 | 实验一:大数据系统基本实验 | 常用的 Linux 操作和 Hadoop 操作
Posted 啦啦右一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据 | 实验一:大数据系统基本实验 | 常用的 Linux 操作和 Hadoop 操作相关的知识,希望对你有一定的参考价值。
文章目录
- 📚cd命令:切换目录
- 📚ls命令:查看文件与目录
- 📚mkdir命令:新建目录
- 📚rmdir命令:删除空的目录
- 📚cp命令:复制文件或目录
- 📚mv命令: 移动文件与目录,或更名
- 📚rm命令:移除文件或目录
- 📚cat命令:查看文件内容
- 📚tac命令:反向查看文件内容
- 📚more 命令:一页一页翻动查看
- 📚head 命令:取出前面几行
- 📚tail 命令:取出后面几行
- 📚touch 命令:修改文件时间或创建新文件
- 📚chown 命令:修改文件所有者权限
- 📚find 命令:文件查找
- 📚tar 命令:压缩命令
- 📚grep 命令:查找字符串
- 📚 用hadoop用户登录linux系统
📚cd命令:切换目录
1.切换到目录/usr/local
2.切换到当前目录的上一级目录
3.切换到当前登录Linux系统的用户自己的主文件夹
cd /usr/local
cd ..
cd /home

📚ls命令:查看文件与目录
查看目录/usr下的所有文件和目录
cd /usr
ls

📚mkdir命令:新建目录
进入/tmp 目录,创建一个名为 a 的目录,并查看/tmp 目录下已经存在哪些目录
cd /tmp
mkdir a
ls

进入/tmp 目录,创建目录 a1/a2/a3/a4
mkdir a1
cd a1
mkdir a2
cd a2
mkdir a3
cd a3
mkdir a4
cd a4

📚rmdir命令:删除空的目录
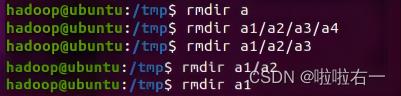
将上面创建的目录 a(在/tmp 目录下面)删除。删除上面创建的目录 a1/a2/a3/a4(在/tmp 目录下面),然后查看/tmp 目录下面存在哪些目录。
rmdir a
rmdir a1/a2/a3/a4
rmdir a1/a2/a3
rmdir a1/a2
rmdir a1
ls
📚cp命令:复制文件或目录
将当前用户的主文件夹下的文件.bashrc 复制到目录“/usr”下,并重命名为 bashrc1
sudo cp ~/.bashrc /usr/bashrc1

在目录“/tmp”下新建目录 test,再把这个目录复制到“/usr”目录下
cd tmp
mkdir test
sudo cp -r /tmp/test /usr
-r:若给出的源文件是一目录文件,此时cp将递归复制该目录下所有的子目录和文件。此时目标文件必须为一个目录名

📚mv命令: 移动文件与目录,或更名
命令格式:
mv [选项] 源文件或目录 目标文件或目录主要选项参数:
-b:若需覆盖文件,则覆盖前先行备份-f:force强制的意思,如果目标文件已经存在,不会询问而直接覆盖-i:若目标文件已经存在时,会询问是否覆盖-u:若目标文件已经存在,且source比较新,才会更新(update)
将“/usr”目录下的文件 bashrc1 移到“/usr/test”目录下
sudo mv /usr/bashrc1 /usr/test

将“/usr”目录下的 test 目录重命名为 test2
sudo mv /usr/test /usr/test2

📚rm命令:移除文件或目录
将“/usr/test2”目录下的 bashrc1 文件删除
sudo rm /usr/test2/bashrc1

将“/usr”目录下的 test2 目录删除
sudo rm -r /usr/test2
-r:递归处理,将指定用户下的所有文件与子目录一并处理

📚cat命令:查看文件内容
查看当前用户主文件夹下的.bashrc 文件内容
cat ~/.bashrc
截图只展示部分

📚tac命令:反向查看文件内容
反向查看当前用户主文件夹下的.bashrc 文件的内容
tac ~/.bashrc
按行反向输出

📚more 命令:一页一页翻动查看
翻页查看当前用户主文件夹下的.bashrc 文件的内容
more ~/.bashrc
用回车翻页

📚head 命令:取出前面几行
命令格式:
head -n number 文件名
查看当前用户主文件夹下.bashrc 文件内容前 20 行
head -n 20 ~/.bashrc

查看当前用户主文件夹下.bashrc 文件内容,后面 50 行不显示,只显示前面几行
head -n -50 ~/.bashrc

对比发现,最后50行没显示

📚tail 命令:取出后面几行
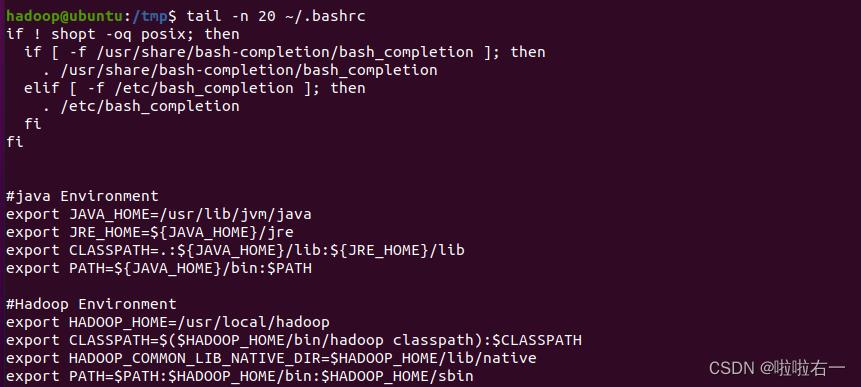
查看当前用户主文件夹下.bashrc 文件内容最后 20 行
tail -n 20 ~/.bashrc
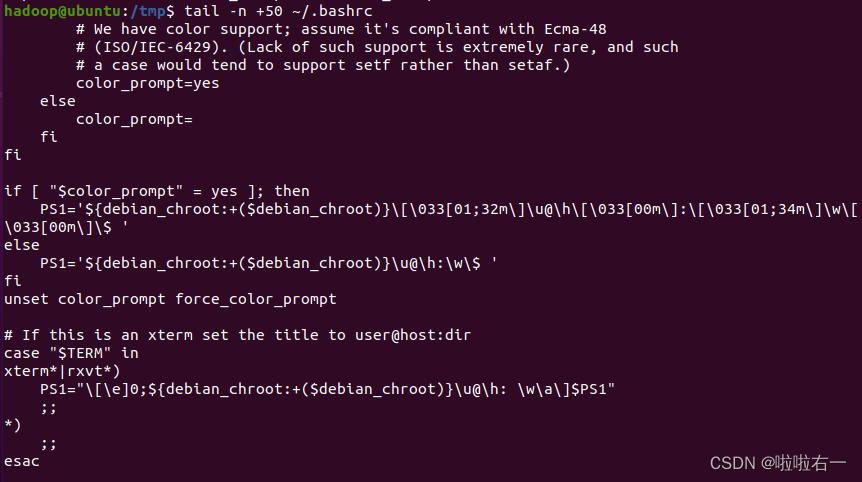
查看当前用户主文件夹下.bashrc 文件内容,并且只列出 50 行以后的数据
tail -n +50 ~/.bashrc
📚touch 命令:修改文件时间或创建新文件
在“/tmp”目录下创建一个空文件 hello,并查看文件时间
cd /tmp
touch hello
ls -l hello
ls的选项参数-l,长数据串行出,包含文件的属性与权限等等数据(常用)

修改 hello 文件,将文件时间整为 5 天前
touch -d "5 days ago" hello
-a:只更改访问时间-d:使用指定字符串表示时间而非当前时间-m:只更改修改时间

📚chown 命令:修改文件所有者权限
将 hello 文件所有者改为 root 帐号,并查看属性
sudo chown root /tmp/hello

📚find 命令:文件查找
找出主文件夹下文件名为.bashrc 的文件
find ~ -name .bashrc
-name:按文件名查找文件-perm:按照文件权限来查找文件-usr:按照文件属主来查找文件-group:按照文件所属的组来查找文件

📚tar 命令:压缩命令

在根目录“/”下新建文件夹 test,然后在根目录“/”下打包成 test.tar.gz
cd /
sudo mkdir /test
sudo tar -zcv -f /test.tar.gz test

把上面的 test.tar.gz 压缩包,解压缩到“/tmp”目录
tar -zxv -f /test.tar.gz -C /tmp

📚grep 命令:查找字符串
从“~/.bashrc”文件中查找字符串’examples’
grep -n 'example' ~/.bashrc

📚 用hadoop用户登录linux系统
Hadoop异常解决:Unable to load native-hadoop library
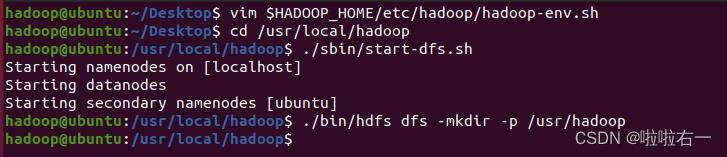
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
->
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
使用 hadoop 用户登录 Linux 系统,启动 Hadoop(Hadoop 的安装目录为“/usr/local/hadoop”),为 hadoop 用户在 HDFS 中创建用户目录“/user/hadoop”
cd /usr/local/hadoop
./sbin/start-dfs.sh
./bin/hdfs dfs -mkdir -p /usr/hadoop
接着在 HDFS 的目录“/user/hadoop”下,创建 test 文件夹,并查看文件列表
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir test
./bin/hdfs dfs -ls

将 Linux 系统本地的“~/.bashrc”文件上传到 HDFS 的 test 文件夹中,并查看 test
cd /usr/local/hadoop
./bin/hdfs dfs -put ~/.bashrc test
./bin/hdfs dfs -ls test

将 HDFS 文件夹 test 复制到 Linux 系统本地文件系统的“/usr/local/hadoop”目录下
cd /usr/local/hadoop
./bin/hdfs dfs -get test ./
以上是关于大数据 | 实验一:大数据系统基本实验 | 常用的 Linux 操作和 Hadoop 操作的主要内容,如果未能解决你的问题,请参考以下文章