HAProxy讲解及HAProxy 负载 mysql 集群
Posted 小毕超
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HAProxy讲解及HAProxy 负载 mysql 集群相关的知识,希望对你有一定的参考价值。
一、HAProxy 简介
HAProxy 是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。 HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在时下的硬件上,完全可以支持数以万计的 并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
HAProxy 实现了一种事件驱动、单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户端(User-Space) 实现所有这些任务,所以没有这些问题。此模型的弊端是,在多核系统上,这些程序通常扩展性较差。这就是为什么他们必须进行优化以 使每个CPU时间片(Cycle)做更多的工作。
HAProxy 支持连接拒绝 : 因为维护一个连接的打开的开销是很低的,有时我们很需要限制攻击蠕虫(attack bots),也就是说限制它们的连接打开从而限制它们的危害。 这个已经为一个陷于小型DDoS攻击的网站开发了而且已经拯救了很多站点,这个优点也是其它负载均衡器没有的。
HAProxy 支持全透明代理(已具备硬件防火墙的典型特点): 可以用客户端IP地址或者任何其他地址来连接后端服务器. 这个特性仅在Linux 2.4/2.6内核打了cttproxy补丁后才可以使用. 这个特性也使得为某特殊服务器处理部分流量同时又不修改服务器的地址成为可能。
HAProxy借助于OS上几种常见的技术来实现性能的最大化。
-
单进程、事件驱动模型显著降低了上下文切换的开销及内存占用。
-
O(1)事件检查器(event checker)允许其在高并发连接中对任何连接的任何事件实现即时探测。
-
在任何可用的情况下,单缓冲(single buffering)机制能以不复制任何数据的方式完成读写操作,这会节约大量的CPU时钟周期及内存带宽;
-
借助于Linux 2.6 (>= 2.6.27.19)上的splice()系统调用,HAProxy可以实现零复制转发(Zero-copy forwarding),在Linux 3.5及以上的OS中还可以实现零复制启动(zero-starting);
-
内存分配器在固定大小的内存池中可实现即时内存分配,这能够显著减少创建一个会话的时长;
-
树型存储:侧重于使用作者多年前开发的弹性二叉树,实现了以O(log(N))的低开销来保持计时器命令、保持运行队列命令及管理轮询及最少连接队列;
-
优化的HTTP首部分析:优化的首部分析功能避免了在HTTP首部分析过程中重读任何内存区域;
-
精心地降低了昂贵的系统调用,大部分工作都在用户空间完成,如时间读取、缓冲聚合及文件描述符的启用和禁用等;
所有的这些细微之处的优化实现了在中等规模负载之上依然有着相当低的CPU负载,甚至于在非常高的负载场景中,5%的用户空间占用率和95%的系统空间占用率也是非常普遍的现象,这意味着HAProxy进程消耗比系统空间消耗低20倍以上。因此,对OS进行性能调优是非常重要的。即使用户空间的占用率提高一倍,其CPU占用率也仅为10%,这也解释了为何7层处理对性能影响有限这一现象。由此,在高端系统上HAProxy的7层性能可轻易超过硬件负载均衡设备。
在生产环境中,在7层处理上使用HAProxy作为昂贵的高端硬件负载均衡设备故障故障时的紧急解决方案也时长可见。硬件负载均衡设备在“报文”级别处理请求,这在支持跨报文请求(request across multiple packets)有着较高的难度,并且它们不缓冲任何数据,因此有着较长的响应时间。对应地,软件负载均衡设备使用TCP缓冲,可建立极长的请求,且有着较大的响应时间。
二、HAProxy 负载mysql集群
在这个数据量大的时代,单机的mysql已不能胜任现在的数据量,为此我们也做了相应的改变,比如搭建主从复制,实现读写分离架构,或者搭建分库分表架构,但这些都有单点故障的问题,当然如果采用mycat中间件可以配多个主节点,可以实现故障的转移,如果不适用mycat,使用HAProxy 也是一个不错的方案。
在该实验中不搭建mysql主主相互复制,目的是为了更方变的看出数据的变化。关于mysql主主复制,可以采用mysql自带的主从复制,注意修改自增的大小,以免冲突,也可以采用otter中间件,高效同步数据。
在实验前,可以关闭防火墙,或把需要的端口释放,以免出现连接不同的情况,关闭selinux :
临时
setenforce 0
永久 需重启
sed -i 's/enforcing/disabled/' /etc/selinux/config
搭建架构:
| 主机 | 角色 |
|---|---|
| 192.168.40.163 | HAProxy 代理 |
| 192.168.40.130 | mysql1 |
| 192.168.40.164 | mysql2 |
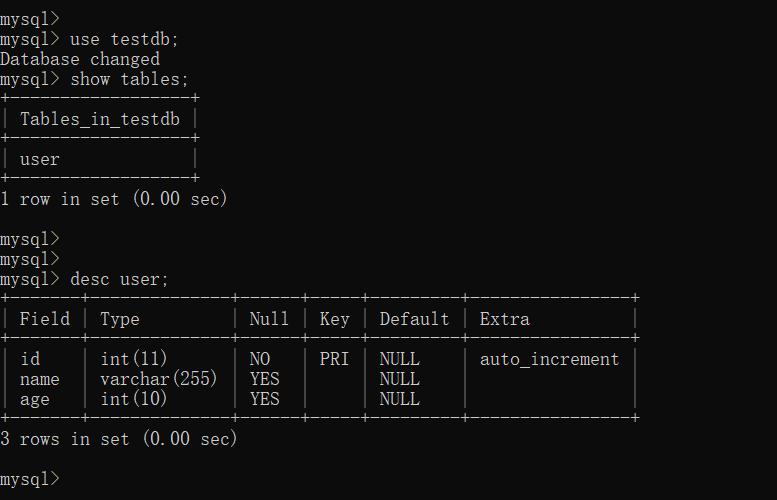
在两个数据库中都创建了testdb库和user表。
安装 HAProxy
在192.168.40.163 主机中:
- 下载HAProxy
yum install -y haproxy
- 修改haproxy.cfg配制文件
cat > /etc/haproxy/haproxy.cfg << EOF
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# mysql apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend mysql-apiserver
mode tcp
bind *:3306
option tcplog
default_backend mysql-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend mysql-apiserver
mode tcp
balance roundrobin
server master1 192.168.40.130:3306 check
server master2 192.168.40.164:3306 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
stats auth admin:awesomePassword
stats refresh 5s
stats realm HAProxy\\ Statistics
stats uri /admin?stats
EOF
- 启动haproxy
systemctl start haproxy
- 设置开机自启
systemctl enable haproxy
查看启动状态
systemctl status haproxy

三、测试
使用客户端连接连个163:
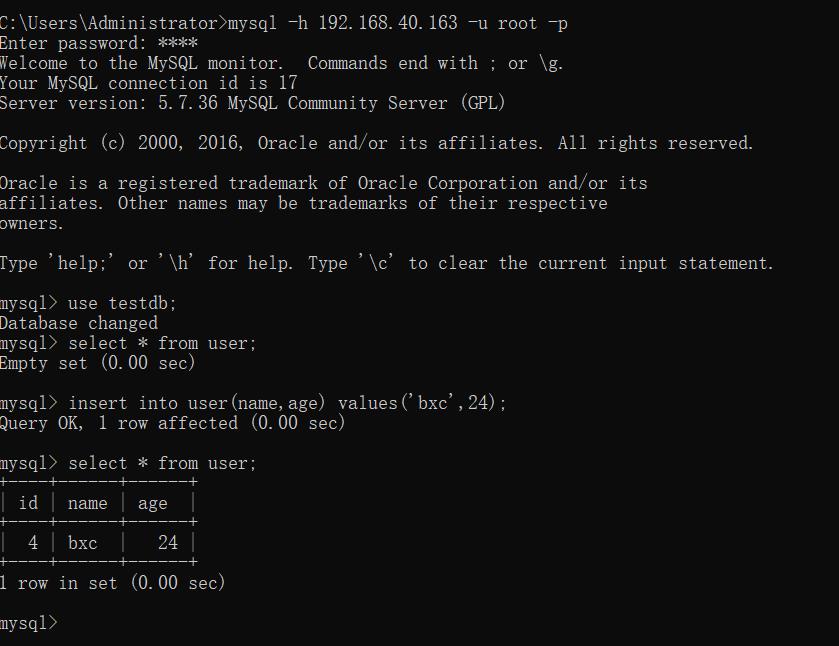
mysql -h 192.168.40.163 -u root -p
在连接中,在user表中添加数据:
insert into user(name,age) values('bxc',24);
断开连接,重新连接再次查询:
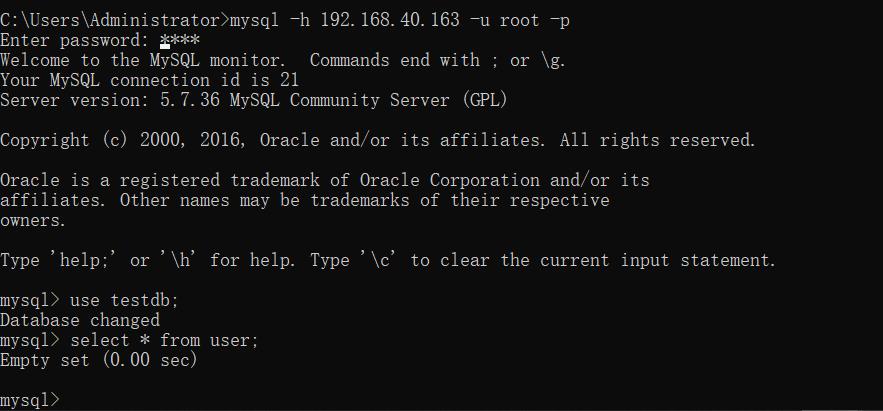
发现查不到数据了,我们再次插入一条不一样的数据:
insert into user(name,age) values('bxc22',24);
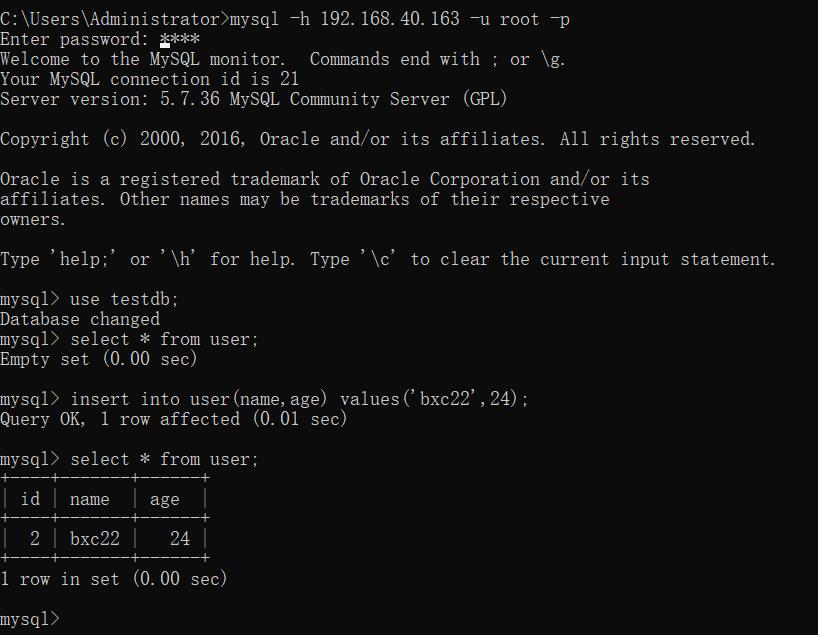
断开连接,重新连接查询:
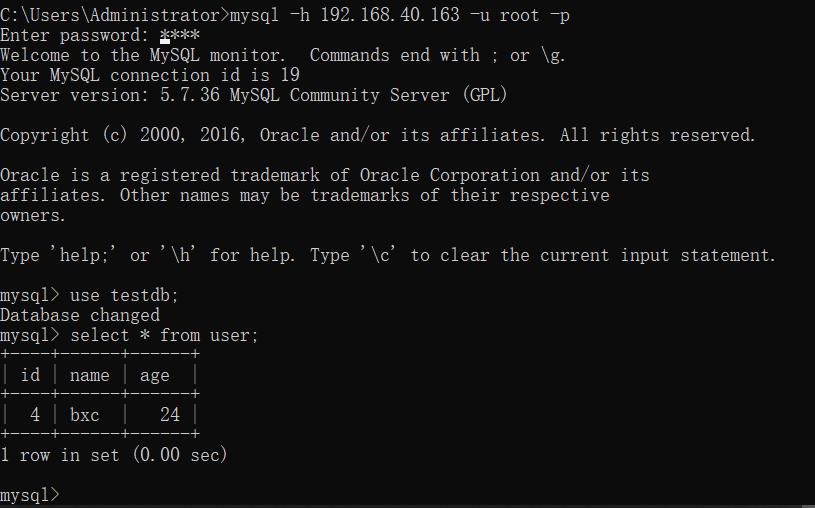
数据又恢复到刚开始写入的内容。
可以连接130和163的mysql 查看数据:
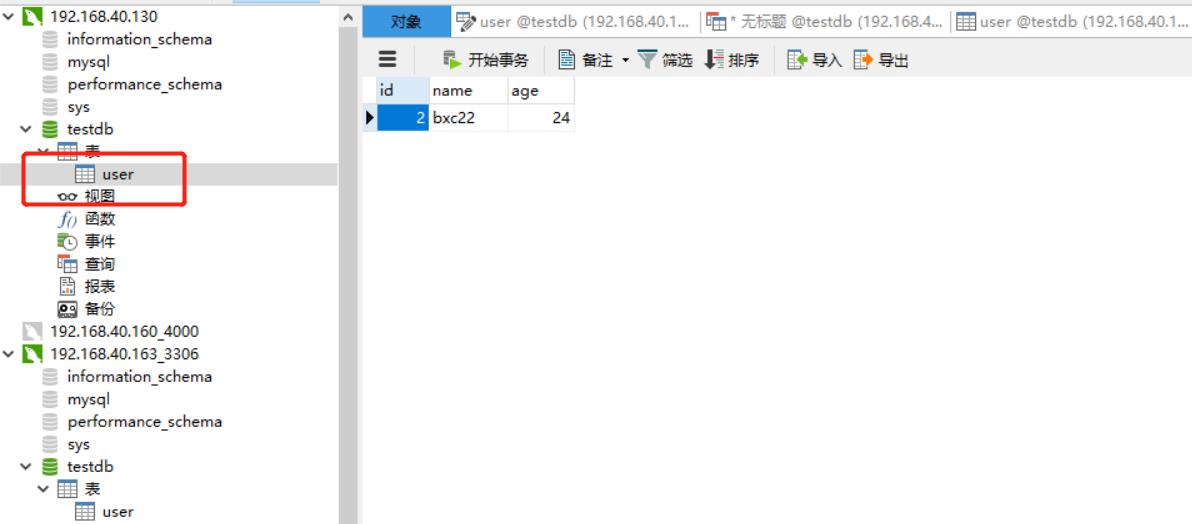
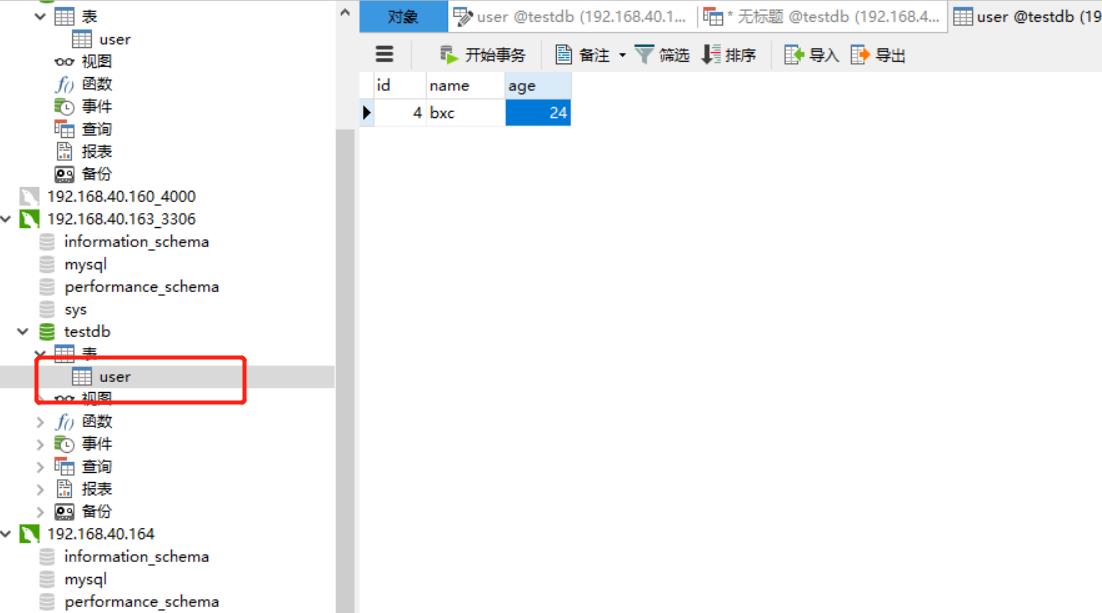
从上面数据就看出来,已经达到负载的效果了,如果搭建了mysql主主复制,就可以分摊压力,达到mysql负载均衡效果了。

喜欢的小伙伴可以关注我的个人微信公众号,获取更多学习资料!
以上是关于HAProxy讲解及HAProxy 负载 mysql 集群的主要内容,如果未能解决你的问题,请参考以下文章