实时高分辨率视频抠像
Posted miss9785
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时高分辨率视频抠像相关的知识,希望对你有一定的参考价值。
一、实验目的
视频抠像有许多实际应用。许多正在兴起的用例,例如视频会议和娱乐视频
创作,都需要在没有绿幕道具的情况下对人体主体进行实时背景替换。因此我选
择该项目作为大作业方向
1、在视频流上提取前景并融合,即给定一段录制好的视频,输入模型后得到抠
像高分辨率和高帧率的视频。
2、通过摄像在线实时进行抠像,类似腾讯会议的虚拟背景功能。
3、在网页端部署功能,将来继续拓宽此项目。
二、实验原理
1、基于 Trimap 的 matting
数学上,一张图片 S_I 可以被建模为前景 F_I 和背景 B_I 的线性组合:
然而,上式只有 S_I 是已知的,α表示对应的 Alpha 通道,因此这是一个定
义不明确的问题。为了解决这个问题,多数方法需要一个 trimap 来表示一张图
片中已知的前景、背景和未知的部分。
Alpha 通道,指的是一张图片的透明度。比如真彩色图像,它是 24bit,含
有 RGB 三彩色通道,每个通道占 8 位。在这个基础上,我们可以给它扩充到 32bit,
增加一个独立的通道,即α通道(黑白灰通道),来控制图片显示的透明度,从
而得到 RGBA 四个通道。其中,值越大,图像的透明度越低。我们知道二进制下
的 8 位可以表示的范围是 0-255,即 255 代表不透明(白色),0 表示完全透明
(黑色),中间值则为半透明(灰色);因此只有当α=255 时叠加到原始图像
上才会显示其真正的颜色。一般来说,TIFF、PNG 和 GIF 均是支持 Alpha 通道的,
我们经常会利用 Alpha 通道的性质来实现抠图或者获得具有透明背景的图片。

当 α 为 0 时,图像为背景图像;当 α 为 1 时,图像为前景图像。因此,对
于图像中的每个像素点,均可以表示为一个类似于上述的线性方程组。因此,抠
图的主要目标是根据原始输入图像,来获得前景、背景和透明度。
2、分割
图像是由许多像素组成,而语义分割顾名思义就是将像素按照图像中表达语
义含义的不同进行分组(分割)。例如让计算机在输入下面左图的情况下,能够
得到右图。在图像领域,语义指的是图像的内容,对图片意思的理解。

matting 与 segmentation 的一个不同之处在于 matting 的预测结果是连续
的,即预测结果是 0-1 的任意值,而 segmentation 的预测结果则是 0 或 1 的整
数。
语义分割是为每个像素预测一个类别标签,通常没有辅助输入。其二元分割
掩码可用于定位人类主体,但直接使用它进行背景替换将导致强烈的伪影。尽管
如此,分割任务与无辅助设置中的消光任务类似,人像语义分割和 matting 任务
在某种程度上是共通的,这就为两者联合起来提供基础,为了拓展到视频应用中,
需要第一帧的 trimap,并且会将其广播至剩下的所有帧。
3、循环神经网络
大多数现有的视频抠像方法是仅仅将视频逐帧作为独立图像进行消融,这些
方法忽略了视频中最广泛存在的特征:时间信息。时间信息可以改善视频的消光
性能,原因如下:
1、它允许预测更连贯的结果,因为模型可以看到多个帧和它自己的预测结
果。这大大减少了瑕疵,提高了感知质量。
2、时间信息可以提高消光的稳健性。在个别帧可能是模糊的情况下,例如,
前景颜色变得与背景中的一个经过的物体相似,模型可以通过参考以前的帧来更
好地猜测边界。
3、时间信息允许模型随着时间的推移了解更多关于背景的信息。当相机移
动时,由于视角的变化,被摄者背后的背景就会显现出来。即使摄像机被固定住
了,被遮挡的背景仍然经常由于被摄者的移动而显现出来。对背景有一个更好的
了解可以简化消光任务。
递归神经网络已被广泛用于序列任务。两个最流行的架构是 LSTM 和 GRU,它
们也被采用于视觉任务来捕获时间信息,如 ConvLSTM 和 ConvGRU。因此可以在
之前的基础上加一个递归结构,而不是使用注意力或简单的前馈多帧作为额外的
输入通道,有几个原因。递归机制可以学习在连续的视频流中保留和遗忘哪些信
息,而其他两种方法必须依靠一个固定的规则,在每个设定的时间间隔内删除旧
的和插入新的信息到有限的内存池中。适应性地保留长期和短期时间信息的能力
使递归机制更适合于视频抠像任务。
这里用多尺度的 ConvGRU 来聚合时间信息:

其中,运算符∗ 和⊙分别代表卷积和 Hadamard 乘积,表示对应位置元素相
乘;tanh 和σ分别代表双曲切线和 sigmoid 函数。w 和 b 是卷积核和偏置项。隐
藏状态 h t 既作为输出,也作为下一个时间步骤的递归状态 ht-1。初始递归状
态 h0 是一个全零张量。
三、实验内容
主要工作是构建了一个视频抠图网络框架,并将模型部署到 web 端组成系统。
其包括一个提取单个帧特征的编码器,一个汇总时间信息的递归解码器,以及一
个用于高分辨率上采样的深度引导滤波器模块。然后将功能都部署到 Web 端
编码器:
编码器模块应该遵循最先进的语义分割网络的设计,因为准确定位人类主体
的能力是底层任务的基础。因此采用 MobileNetV3-Large 作为高效的主干,然后
采用 MobileNetV3 提出的 LR-ASPP 模块来完成语义分割任务。
下图是 MobileNetV3 的网络架构:large 和 small 的整体结构一致,区别就
是基本单元 bneck 的个数以及内部参数上,主要是通道数目。

核心模块,也是网络的基本模块。主要实现了通道可分离卷积+SE 通道注意
力机制+残差连接。结构图如下:
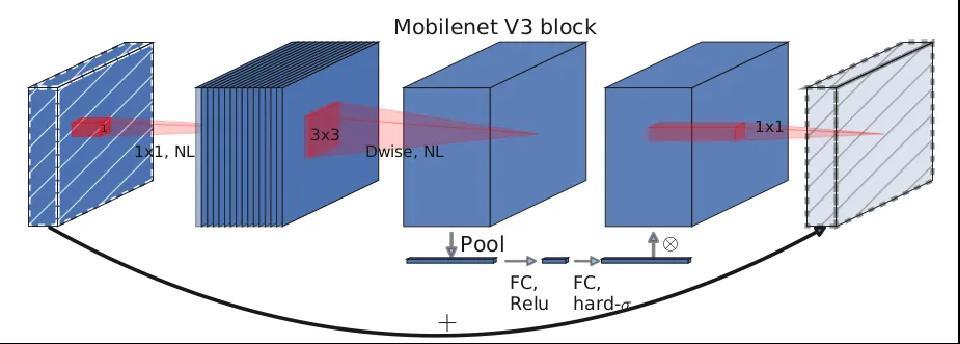
解码器:
为了更好的利用视频流数据的时间信息,这里使用一个递归结---ConvGRU,
其可以学习在连续的视频流中保留和遗忘哪些信息,适应性地保留长期和短期时
间信息的能力使递归机制更适合视频抠图的任务。
在 LR-ASPP 语义分割模块之后,解码器在 1/16 特征尺度上运行。通过拆分
和连接,ConvGRU 层只在一半的通道上操作。上采样块在 1/8、1/4 和 1/2 刻度
重复。首先,它将前一个块的双线性上采样输出、编码器对应比例尺的特征图和
重复 2×2 平均池化的下采样输入图像连接起来。然后,使用卷积和批处理正常
化和 ReLU 激活进行特征合并和信道缩减。最后,通过分裂和连接将 ConvGRU 应
用到一半的通道。输出块只使用正则卷积来优化结果。它首先将输入图像和来自
前一个块的双线性上采样输出连接起来。然后使用两次重复卷积、批处理归一化
和 ReLU 栈生成最终的隐藏特征。最后,将特征投影到输出中,包括 1 通道 alpha
预测、3 通道前景预测和 1 通道分割预测。
深导滤波器(
DGF):
最后是深导滤波器(
DGF)用于处理高分辨率视频,对输入帧进行因子 s 的
下采样,然后将低分辨率α、前景 F、最终隐藏特征以及高分辨率输入帧提供给
DGF 模块,生成高分辨率α和前景 F。实际上就是一个融入了可学习参数的引导
滤波器,可以更好地拟合出一个边缘精确的分割结果。
训练过程:
模型在 VideoMatte240K (VM)、Distincations -646 (D646)和 Adobe Image
Matting (AIM)数据集上进行训练。虚拟机提供 484 个 4K/HD 视频片段。将数据
集分为 475/4/5 个片段,用于训练/val/测试分割。D646 和 AIM 是图像抠图数据
集。只使用人类的图像,并将它们组合成 420/15 train/val 分割用于训练。D646
和 AIM 分别提供 11 张和 10 张测试图像进行评估。对于背景,的数据集提供了适
合抠图构图的高清背景视频。这些视频包括各种各样的运动,如汽车经过,树叶
摇动,以及相机的运动。选择 3118 个不包含人类的片段,并从每个片段中提取
前 100 帧。还按照的方法抓取 8000 个图像背景。图像中有更多的室内场景,如
办公室和客厅。在前景和背景上应用运动和时间增强来增加数据的多样性。运动
增强包括仿射平移、缩放、旋转、纯光、亮度、饱和度、对比度、色调、噪声和
模糊,这些都是随着时间不断变化的。该运动应用不同的缓动函数,这样的变化
并不总是线性的。该增强还将人工运动添加到图像数据集。此外,将时间增强应
用于视频,包括剪辑反转、速度变化、随机暂停和跳帧。其他离散增强,如水平
翻转、灰度和锐化,应用于所有帧一致。
1、首先在 VM 数据集上没有 DGF 模块的低分辨率上训练 15 个 epoch。设置一
个短序列长度 T = 15 帧,这样网络可以更快地更新。MobileNetV3 骨干网络使
用预训练的 ImageNet 权重进行初始化,并使用 1e−4 学习率,而网络的其余部分
使用 2e−4。分别对 256 和 512 像素之间的输入分辨率 h, w 的高度和宽度进行采
样。使得网络能够适应不同的分辨率和高宽比;
2、将 T 增加到 50 帧,学习速率减半,保持其他参数设置并训练;
3、增加 DGF 模块在 VM 数据集上训练高分辨率样例 1 个 epoch;
4、在 D646 和 AIM 的组合数据集上进行 5 个 epoch 的训练。
5、分割训练被穿插在每个抠图训练迭代之间,在每次奇次迭代后对图像分
割数据进行训练,在每次偶数次迭代后对视频分割数据进行训练。
部署:
然后使用 WebGL 将训练好的模型部署到 web 端,调用摄像头进行实时抠像,
不仅可以看到实时抠像的效果,还可以实时看到 Alpha 通道,循环隐藏状态和背
景状态,并对 html 页面进行了一定的美化,形成了一个可展示的系统。
四、实验要求
由于视频抠像存在许多难点,该大作业应该基本克服这些难点,达到不错的
效果,难点有如下:


1、背景噪音:人物所处的环境通常是比较嘈杂的,对模型来说比较难以分
辨,肯造成划分错误。
2、人物动作:人物在视频中常常伴随着动作,特别是对于比较快速的动作,
比如跳舞,运动等,模型可能来不及识别或者模糊处理。
3、细微部分:人物主体存在细微的部分,比如头发丝,衣服褶皱边缘等,
模型可能精度不够,造成错误。
4、分辨率及帧率:由于深度学习处理视频的模型基本都比较大且复杂,特别
是对实时摄像头,可能造成视频模糊,以及卡顿情况,即帧率低。
项目在结束阶段应该完成以下目标:
1、给定一段录制好的视频,输入模型后能够得到高分辨率和高帧率的抠像视频。
2、能够通过摄像头在线实时进行抠像,类似腾讯会议的虚拟背景功能。
能够展示一个较为完整的系统,比如在网页端部署功能。
六、实验结果
这是从所选的数据集的测试子集中选择的一些测试结果,可以看出视频抠像
效果还可以,由于这里放置不了视频,因此截取图片:


七、实验心得
1、通过大项目这次机会,了解视频抠像这一领域的基本发展以及各种算法,
视野得到极大拓展。
2、在大项目中为了实现一个完整的系统,额外的学习了一些新的知识,且
通过查阅与钻研,克服了诸多困难,能力得到了提升。
3、将来可能的话,会把 Web 端系统运行在服务器上,并注册网站,最终建
设并维护一个网站供其他人使用,可以输出用户上传视频的抠像结果。类似著名
的 unscreen 网站。
以上是关于实时高分辨率视频抠像的主要内容,如果未能解决你的问题,请参考以下文章