实时作业转离线作业的几种场景及方案
Posted 咬定青松
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时作业转离线作业的几种场景及方案相关的知识,希望对你有一定的参考价值。
经常听到人抱怨:所在公司太小,业务不稳定,学不到东西。不可否认,的确是这么回事,假如无法改变现状,何不换个角度来看呢?往往小公司和摇摆不定的公司才能锻炼能力和出现“英雄”般的人物,才能分离出常人和非常人,比如乔布斯 如果不是 二次被 邀请回来 拯救了苹果公司,谁又知道这个人呢?雷军能够在金山坚持20多年,从一线程序员到总经理,然后创办小米,并且把小米从低谷重新拉回巅峰,走出了漂亮的深“V”走势,没有这样一股韧性和坚持,又怎么能到达今日的辉煌?类似的还有董明珠女士。在我党早期的“创业”历史中,如果没有第5次反围剿的失败和在全党面临全军覆没的情形下,其他人又怎么会承认毛泽东的正确意见和才能呢?所谓乱世出人才就是这个道理,大平台是集体的能力而不是个人能力,和平时期也难现真英雄,好好利用当下不那么优越的条件,即使做不到伟人,一个才华出众的,能力全面,受人敬重的公司元老也不错。
将Flink流式计算引擎作为实时计算作业的标配带来的重大挑战之一是资源占用问题,因为大量的Flink作业一旦启动,将一直占用分配的CPU和内存资源,而不会自动释放(除非是批处理模式),并且不会随着处理负载自动伸缩。本文探讨如何在计算资源有限的情况下,如何最大化利用计算资源。基本思路是将流式计算任务中基于时间触发的子过程转化为离线定时调度计算任务。下面列举几种常见的场景,权且当做验证。
一、Kafka数据入湖(仓)作业
比如这样一个kafka topic数据导入示例,将拉取的数据不加处理地写入到Iceberg表:

如果对拉取的频率要求不高,这种情况是可以转换为定时拉取,比如1分钟拉取一批,写入到iceberg,但是需要自己实现拉取的并发控制、状态保存、提交Iceberg的事务性、消费负载均衡等功能。
二、S3对象通知事件处理作业
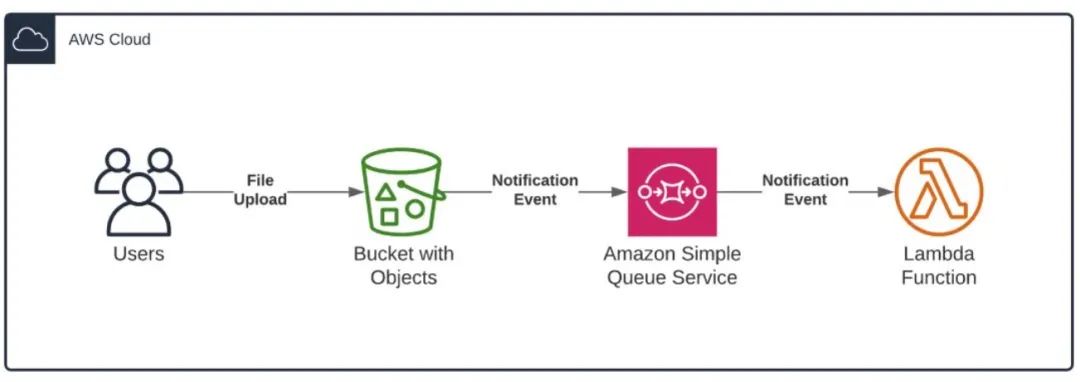
基于S3对象存储,用户能够实时监听对象的CREATE、PUT、Remove、Expiration或者Replication等事件通知,通过使用形如下面的流程可以省去基于Flink FileSystem 加载数据的过程。下图是基于SQS和Lambda 函数的一种架构案例,实际上 SQS和Lambda 都可以替换为自定义的处理程序,因为每个事件处理都是小处理单元,可以短时间快速完成,这时候事件通知很适合直接对接基于事件触发的调度系统(如Celery),而不需要启动一个实时Flink作业,但因为S3事件通知只投递一次,用户程序需要保证消息处理的服务等级。
三、CDC 近实时作业入湖(仓)作业
CDC数据同Kafka数据相似,对允许高延迟(比如分钟级)的场景也可以转为定时拉取的方式,用户程序定期向服务器发送Dump指令,接受binlog数据,然后再存储到其他介质,比如Canal Server模拟数据库Slave同数据库Master交互,将收到的binlog暂存内存RingBuffer或者路由到指定的Kafka topic,Canal Client定期从Canal Server或者Kafka拉取数据,如下图所示:
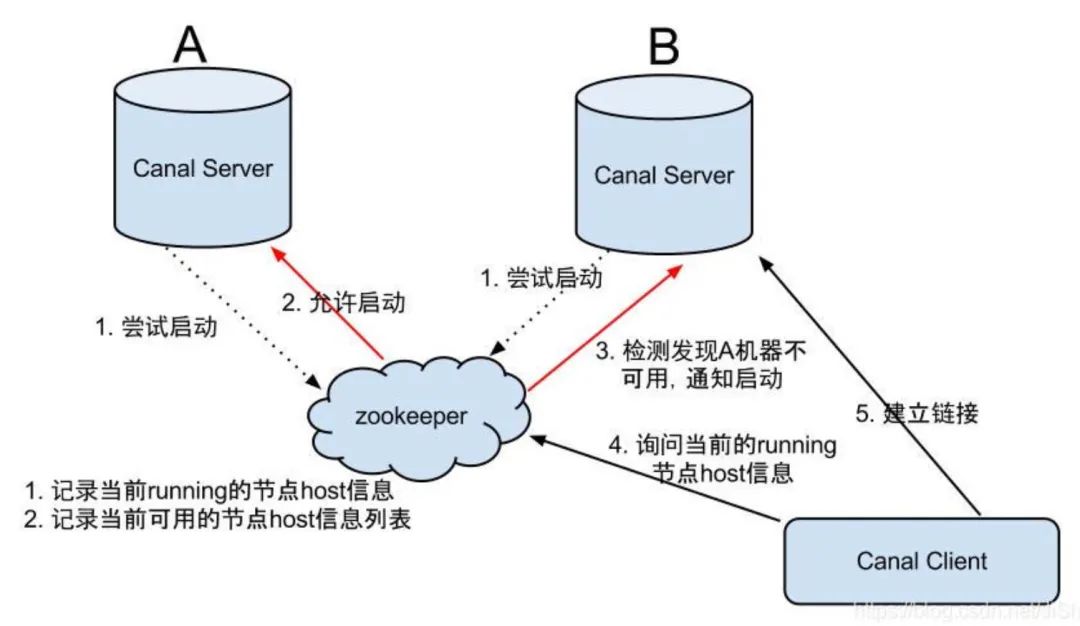
这里的canal client就可以根据需要替换Flink,比如直接将消费到的数据提交到数据湖Iceberg,用户程序需要实现的是并发控制、异常恢复、消费负载均衡、数据合并与去重等功能。Canal Server通过多实例部署,增强了HA功能,但是整体架构过于复杂,而Debezium则更为简洁,它提供Embeded的方式,用户可以基于Debezium API直接读取并消费binlog,开发自由度大大提高,也不需要依赖Kafka、Server等三方服务。
四、JDBC 增量数据入湖(仓)作业
由于JDBC的数据读取方式对业务数据库影响较大,不适合做高频低延迟的批量拉取,因此天然适合低频、增量拉取,在这种场合下,很适合替代Flink JDBC Connector的作业方式。增量拉取可以基于数据库的修改时间字段、自增ID字段。这种用法在离线数仓开发过程中广泛应用,比如每天拉取前一天的增量数据,并保存到Hive数仓中的一个分区,因为同一条记录可能存在多个版本,因此需要下游完成基于主键的数据去重。另外,上次拉取位置等状态也需要用户自己实现。
五、Flink批处理或有界流处理作业
Flink批处理由于本身会结束并释放资源,所以不用担心资源占用问题,但是基于纯SQL方式的作业无法自适应资源弹性伸缩,如果能够转为离线Hive SQL,能够在YARN等资源管理框架中最大化利用计算资源。比如下面的有界流处理上的一个示例SQL作业:
select a,count(b) from t group by a
因为其计算结果随着数据的到来实时触发,并更新结果,其实在允许高延迟的场景下,上述过程 可以等数据全部到来一次性计算一次,或者以一定的时间间隔增量计算。这种方式适合任意数据的规模计算,增量方式尤其适合大规模数据集,但是需要用户保证每次增量计算结果的幂等性。
六、Flink无界流处理作业
无界流处理因为数据集大小无限,因此常基于局部窗口进行计算,避免内存移除问题,这里举两个示例说明。
A. Flink简单窗口计算作业
Flink简单窗口计算只处理一个流,不涉及到跨流计算,在单流窗口计算过程中,当一个新的窗口开启,数据先被缓存到内存,当窗口时间到达右边沿,触发窗口内的计算,然后再根据策略要求清理窗口内的缓存数据,如果窗口时间范围过长,会占用较大存储空间,此时就可以将实时计算转为定时增量计算,比如下面的窗口计算,每10分钟计算当前窗口的记录数量:
select count(a) from t group by tumble(ts, interval '10' minute)该过程同以下计算等价:
select count(a) from t where ts between ($scheduleTime -'10' minute) and $scheduleTime其中$scheduleTime为调度时间,离线计算相比之前的实时计算,能够有效减少作业的累计持续时间。
B. Flink window join计算作业
window join计算作业是无界数据流中常用模式,基于Window的Flink双流Join的 API语法为:
stream.join(otherStream)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)比如下面将 Orders 订单表和 Shipments 运输单表依据订单id和运输单的订单id Join 的查询案例:
shipStream.join(orderStream)
.where(ship=>ship.orderId)
.equalTo(order=> order.id)
.window(TumblingEventTimeWindows.of(Time.hours(4)))
.apply((s,o)=>
(s.orderId,o.id,...)
)其中 join条件是ship.orderId=order.id,窗口为4 hour 长度的滚动窗口:这个示例用SQL描述就是:
select *
from Orders o,Shipments s
where o.id=s.orderId
and s.shipTime between o.orderTime and o.orderTime+interval '4' hour查询为 Orders 表设置了 o.ordertime > s.shiptime- INTERVAL ‘4’ HOUR 的时间下界:
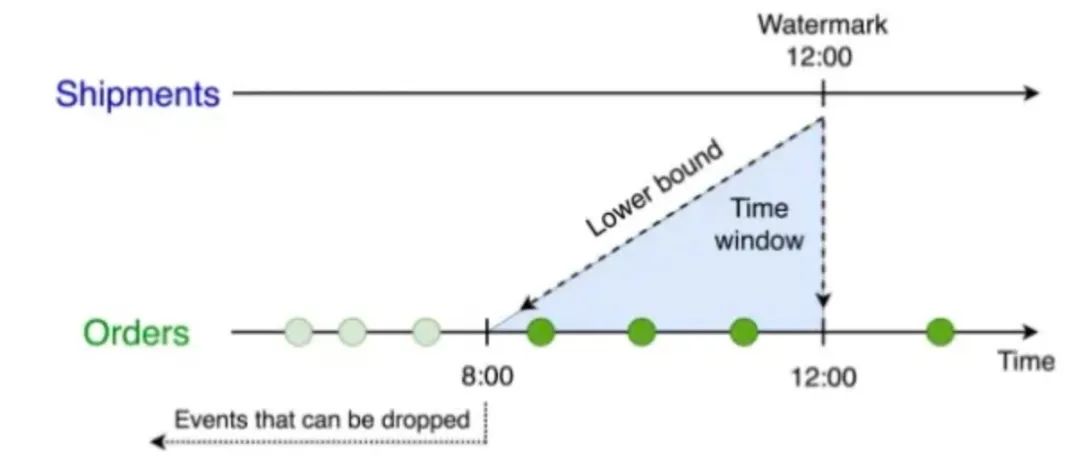
上述SQL跟以下基于离线调度的方式等价:
select *
from Orders o,Shipments s
where o.id=s.orderId
and s.shipTime between $scheduleTime and $scheduleTime+4 hour
and o.orderTime between $scheduleTime and $scheduleTime+4 hour经过离线处理转换后的任务就可以按照增量计算了,此时也需要用户去处理数据的合并、更新与幂等性等问题。
七、Iceberg湖数据增量消费作业
形如下面的增量消费Iceberg湖数据的作业,如果monitor-interval达到分钟级以上的延迟,也是可以转为离线增量计算作业:
SELECT * FROM sample /*+ OPTIONS('streaming'='true', 'monitor-interval'='10m', 'start-snapshot-id'='3821550127947089987')*/ ;转换方式可以通过修改OPTIONS,增加计算条件等,以上述示例其转换后的示例可以是:
SELECT * FROM sample where processing_time between $scheduleTime and ($scheduleTime+10 minute)
/*+ OPTIONS('streaming'='false', 'start-snapshot-id'='3821550127947089987')*/ ;其中的时间过滤字段可以根据使用上下文的设置决定使用processing_time还是Event_time。这里为保持SQL语法兼容性,继续使用FLinkSQL,如果没有特殊语法,也可以转为其他计算引擎支持的SQL。
小结
本文梳理了实时计算中,能够将实时计算转为离线计算的几个场景,通过转换后的对比可见,离线计算基于有界数据计算完成之后释放资源,虽然累计计算资源不会少,但是释放了大量空闲时期的资源占用比例,增大了资源的整体利用率,同时转为离线计算有了更多的计算引擎选型空间,另外在可抢占资源分配方式的资源管理框架中(如YARN),能够解决Flink实时作业使用资源无法伸缩的问题。
将实时作业转为离线作业时,我们除了需要解决离线调度的资源隔离与分配问题,还需要解决任务依赖问题,比如再来看上面基于窗口Join的案例:
shipStream.join(orderStream)
.where(ship=>ship.orderId)
.equalTo(order=> order.id)
.window(TumblingEventTimeWindows.of(Time.hours(4)))
.apply((s,o)=>
(s.orderId,o.id,...)
)上述实时计算作业转为离线作业时,其实存在着这样的依赖T拓扑结构:
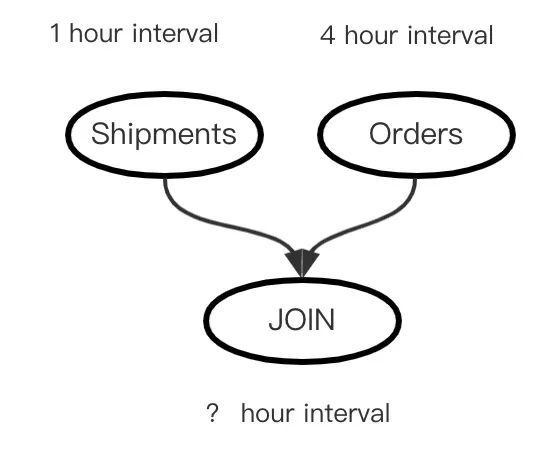
假设Shipments增量更新频率为每小时一次,Orders更新频率为4小时一次,那么Join计算任务的更新频率设置多少合适呢?实际上Join的频率理论上以被依赖任务中较小者为准比较合适,但是在实际面向用户的应用上,很难做到准确,除非系统把实时转离线的过程以及依赖的确立工作完全自动化。尽管如此,我们仍然需要解决不同调度周期依赖的问题:
1. JOIN任务计算频率跟Shipments相同,也是1小时一次。那么JOIN完全依赖Shipments,即当当前周期的Shipments计算完成才可能计算JOIN。而JOIN频率高于Orders,只需要利用最新计算结果数据即可,可看做JOIN弱依赖Orders。
2. JOIN任务计算频率跟Orders相同,也是4小时一次。那么JOIN完全依赖Orders,必须等当前周期的Orders计算完成才可能执行JOIN,但是JOIN频率低于Shipments,理论上可以不依赖Shipments,但是实际中可能存在业务上的依赖关系,比如一个日周期类型的任务必须等小时任务执行满24周期才可以执行进行小时级别的数据结果汇总,那么此时可以将高频任务按照低频任务周期对齐。
将上述问题应用到数仓开发中,就是下面常见的依赖模型:
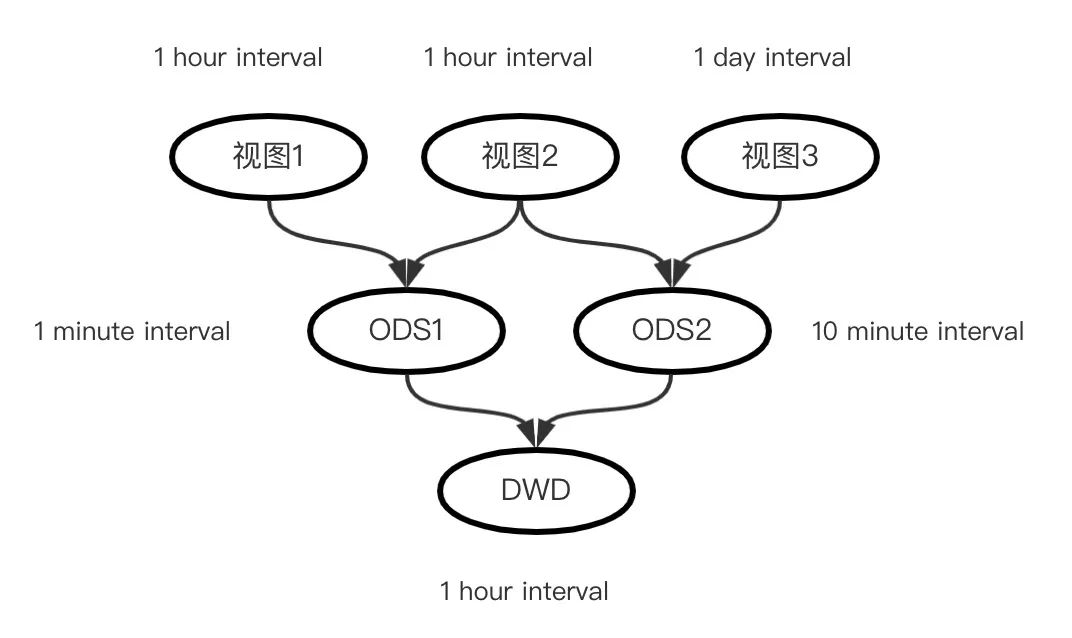
其中视图任务可以看做业务数据到数仓Staging area的映射,ODS是基于视图数据进行贴源层的计算,DWD再基于ODS做数据明细建模等,上述每个节点的任务计算频率都不一样,参照上面的两种情况很容易实现这种依赖调度。
以上是关于实时作业转离线作业的几种场景及方案的主要内容,如果未能解决你的问题,请参考以下文章