2KV260开发yolov4模型训练量化编译部署
Posted 苍山有雪,剑有霜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2KV260开发yolov4模型训练量化编译部署相关的知识,希望对你有一定的参考价值。
前言
由于毕业设计就是基于KV260搞智能监控那一套,因此主要关注深度学习应用这一块,硬件部门涉及比较少。
通过Vitis AI官方手册可知,成功完成一个深度学习应用需要四个步骤:模型训练、量化、编译、部署。笔者就以YOLOv4模型为例进行一个演示,看看整个过程是否有坑!
模型训练
之前比较熟悉darknet,所以直接基于darknet框架进行yolov4模型的训练,而且将检测类别数改为1,(人体)。
训练过程不赘述,训练完成之后通过caffe-xilinx中提供的脚本将darknet的权重和配置文件转换为caffe版本,也就是两个文件:yolov4_body.prototxt、与
yolov4_body.caffemodel
注意!KV260的DPU核心类型为DPUCZDX8G,其中的算子有一定的兼容性和尺寸限制,例如maxpool只能从22到88,而原版YOLOv4的SPP模块池化尺寸为5、9、13,因此需要修改为3、5、7。
有关DPU算子兼容性的问题,参考:4、【KV260开发】DPU支持OP、算子兼容性。
模型量化
模型量化前需要做一些准备工作:
-
准备200张训练时的样本图片(根据实际使用场景来确定量化的图片数目,一般来说场景越复杂、检测类别数越多,则量化时需要的图片就越多,个人建议图片数为200*类别数)
-
一个txt文件,其中内容为样本图片的地址
-
修改prototxt文件,将原本头部内容修改如下:

其中root_folder是图片的文件夹,quant.txt中是具体图片的名字。
为了方便量化操作,可以写一个脚本:
//quantize.sh
echo "Straing quantize model......"
vai_q_caffe quantize -model ./float/yolov4_body.prototxt -weights ./float/yolov4_body.caffemodel -gpu 0 -calib_iter 20 -keep_fixed_neuron
echo "All done!"
注意!!-keep_fixed_neuron必须加上!虽然在手册上没有写出来,但是经测试如果不加该属性,之后编译出的xmodel无法正常运行!
编译成功之后,在quantize_results文件夹下有四个文件:
-
deploy.caffemodel
-
deploy.prototxt 前两个都是后续编译需要的模型,无法被caffe所读取
-
quantize_train_test.caffemodel
-
quantize_train_test.prototxt 这两个文件是量化过后的caffe模型,可以用作测试和迁移训练
(可选)模型finetuning
有的模型在经过量化时可能会造成精度大幅度下降,这个时候就需要进行模型的finetuning,简单来说就是使用量化的模型进行进行训练。
先创建一个solve.prototxt文件,例如:
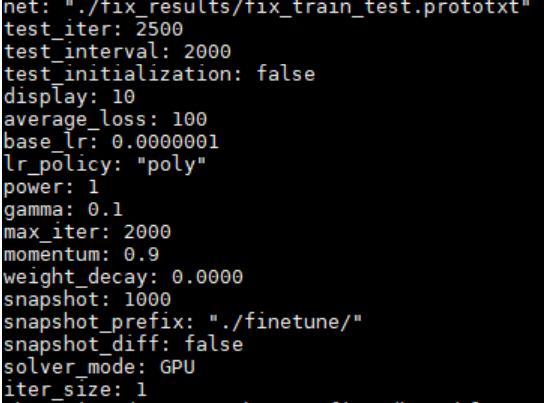
而后使用以下指令进行finetuning:
./vai_q_caffe finetune -solver solver.prototxt -weights quantize_results/
quantize_train_test.caffemodel -gpu 0
而后使用以下指令对finetuned之后的模型进行deploy,简单来说就是生成编译需要的模型:
./vai_q_caffe deploy -model quantize_results/
quantize_train_test.prototxt -weights finetuned_iter10000.caffemodel -
gpu 0 -output_dir deploy_output
模型编译
模型编译,即将caffemodel转换为DPU可以运行的模型。
同样建立一个脚本:
//compile.sh
vai_c_caffe -p ./quantize_results/deploy.prototxt -c ./quantize_results/deploy.caffemodel -a /opt/vitis_ai/compiler/arch/DPUCZDX9G/KV260/arch.json -o ./xmodel -n yolov4_body
编译过程会输出相应的信息,如果有warning一定要注意,一般是DPU不支持某类算子,笔者建议对其进行修改,否则会导致生成多个subgraph,从而对后续模型部署造成困难。

另外,经过编译后的模型文件大小约为原模型大小的1/4,如果对不上,十有八九编译的模型无法运行,需要仔细排查。
模型部署
将上一步的xmodel拷贝至KV260开发板,/usr/share/vitis_ai_library/models/yolov4_body/。
另外,还需要一个配置文件yolov4_body.prototxt,可以下载xilinx官方Model_Zoo中的dk_yolov4,修改相应的参数:
model
kernel
mean: 0.0 #
mean: 0.0 #
mean: 0.0 #分别是BGR的通道均值,根据自身模型来定
scale: 0.00390625
scale: 0.00390625
scale: 0.00390625
model_type : YOLOv3 # yolov3和yolov4都是使用yolov3,不影响
yolo_v3_param
num_classes: 1 #改成你的模型检测类别
anchorCnt: 3
layer_name: "160"
layer_name: "149"
layer_name: "138"
conf_threshold: 0.3
nms_threshold: 0.45
biases: 12
biases: 16
biases: 19
biases: 36
biases: 40
biases: 28
biases: 36
biases: 75
biases: 76
biases: 55
biases: 72
biases: 146
biases: 142
biases: 110
biases: 192
biases: 243
biases: 459
biases: 401
test_mAP: false
运行demo的结果如下:

YOLOv4的运行速度还是比较慢的,笔者做了一个MobileNetV2-YOLOv4,运行FPS可达50,后续将会放出来,敬请期待!
注意,有的玩家在进行这一步的时候,很可能会出现爆粗,大致是!factory.method()什么的。
经过查阅得知,这是由于KV260还没有加载相应的DPU驱动所致。
查看板子DPU指令:

如果没有xclbin路径,或是随有路径,但是实际文件夹下根本找不到xclbin,可以通过这个方式安装xclbin。
- 首先,查看板子支持的dpu驱动:

建议安装第一个,后面三个是开发或测试版本。
sudo dnf install kv260-dpu-benchmark.k26_kv
- 此时,通过命令:sudo xmutil listapps,显示如下:

- 而后通过命令:sudo xmutil loadapp kv260-dpu-benchmark挂载相应驱动,此时可以通过第一步的命令再次查看驱动是否正确。
参考链接
以上是关于2KV260开发yolov4模型训练量化编译部署的主要内容,如果未能解决你的问题,请参考以下文章