11.软件架构设计:大型网站技术架构与业务架构融合之道 --- 多副本一致性
Posted enlyhua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了11.软件架构设计:大型网站技术架构与业务架构融合之道 --- 多副本一致性相关的知识,希望对你有一定的参考价值。
第11章 多副本一致性
无论是 mysql 的 master/slave,还是redis的 master/slave,或者是kafka 的多副本复制,都是通过牺牲一致性换取高性能的。
但如果需要一个既满足高可用,又满足一致性的系统,就需要一致性算法或者说一致性协议 --- Paxos,Raft,Zab。
工业界基于这些算法的工程实践有哪些:
1.Paxos
腾讯的 PhxPaxos,PhxSQL,PaxosStore;
阿里的 AliSQL X-Cluster,X-Paxos;
MySQL的 MGR;
Google 的分布式锁服务 Chubby;
2.Raft
阿里云的 RDS;
etcd;
TiDB;
百度的 bRaft;
3.Zab
Zookeeper;
11.1 高可用且强一致性到底有多难
11.1.1 Kafka的消息丢失问题
熟悉kafka 的人都知道,如果是客户端异步发送(有内存队列),则客户端宕机再重启,部分消息就丢失了;如果ACK=1,也只是master收到消息,就给客户端
返回成功,master到slave之间异步复制,这时master宕机切换到slave,消息也会丢失。
但这里要说的是,即使客户端同步发送,服务器端ACK=ALL(或者-1),也就是等master把消息同步给所有slave后,再成功返回给客户端,这样如此"可靠的"情况
下,消息仍然可能丢失。
这个丢失不是指没有Flush刷盘,所有的机器同时宕机导致的丢失,而是说master宕机,切换到slave,可能导致消息丢失。
这个丢失由kafka的ISR算法本身的缺陷导致的,而不是系统问题。
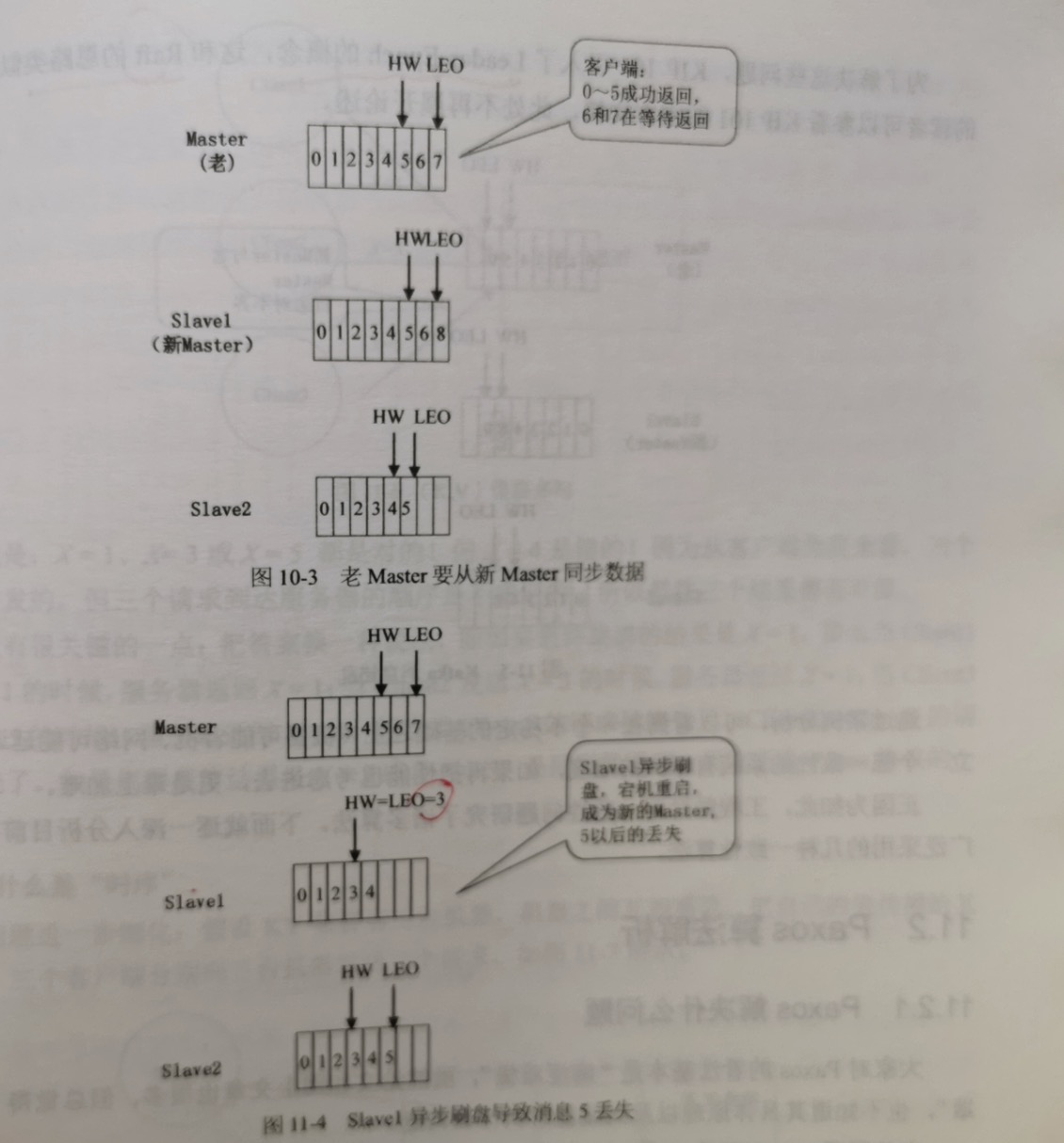
假设一个Topic的一个Partition有三台机器,一个master和2个slave。
日志(也就是消息)有2个关键的变量需要记录,LEO和HW。
LEO(Log End Offset)是日志最后一条记录的offset所在位置。
HW(High Water)取的是master和2个slave的HW的最小值,表示已经复制成功的消息的最大offset。
LEO 很好理解,但是为什么要有HW呢?
以该场景为例,master 的 LEO=7,slave1 的 LEO=6,slave2的 LEO=5。kafka用的是pipeline,各个slave是从master处批量拉取日志,所以各个节点
的LEO是不相等的。
HW 取3个LEO的最小值,也就是HW=5,也就是说:5之前的日志(包括5)已经被复制到所有机器,6和7还在处理中。对于客户端来说,就是0~5已经成功返回,6和7还
在等待master复制。
问题就出在 HW 上面:HW的真实值是5,在master上面。但是slave1和slave2的HW的值还是3,没来得及更新到5,为什么会这样呢?
master是等slave1和slave2把 HW=5 之前的日志都复制过去之后,才把HW更新到5的。但它把HW=5传递给slave1和slave2,要等下一个网络来回,也就是说:
先通知客户端5之前的都写入成功了,等下一个网络来回,在把HW=5这个消息通知给slave1和slave2。但它等把HW=5传递给slave1和slave2的时候,自己可能已经更新到
HW=7。这意味着,slave1和slave2的HW的值一直会比master延迟一个网络来回。
假设这时master宕机,切换到slave1,会发生什么?对于客户端来说,0~5成功了,6,7肯定是超时或者网络出错了。6,7这两条日志会被丢弃,还是保留?下面分
几种场景讨论。
场景1:slave1变成master,slave2要从slave1开始同步数据。这如何做到的呢?过程如下:
slave2为了和slave1对齐,首先会做HW截断,也就是把 HW=3之后的日志全部删除,因为对slave2来说,它只能保证HW=3之前是正确的,3和5之间的部分处于
不确定状态,所有要删除,然后从slave1开始同步,把3和6之间的部分同步过来。
所以最终结果是:6被保留,7被丢弃,根据网络的2将军问题,这是正确的。对于客户端来说,6,7本来就处于不确定状态,服务器无论是保留还是丢弃,都是正确的。
场景2:slave2发生截断,然后变成了master,发生数据丢失。
slave2 发生HW截断之后,也就是 HW=3之后的数据删除了,此时HW=LEO=3。就是此时,又发生了一次master切换(slave1宕机,slave2变成了master,
然后slave1又恢复了,从slave2开始同步数据)。
此时,所有的节点都从slave2同步数据,HW=LEO=3,4和5两条日志都丢失了。对于客户端来说,4和5明明返回成功了,现在却丢失了,系统出现错误。
出现这个问题的原因是:slave2做了截断,为什么要截断呢?为了和slave1保持一致,因为HW有一个网络延迟,当master宕机后,slave1和slave2都不知道
最新的日志同步到哪里了,为了保险起见,slave2根据自己的日志做了截断,然后从slave1开始同步数据。
总结下,HW会在两种场景下发生截断:
1.新的master上位,其他slave要从新的master同步数据,在同步之前,会先根据HW截断自己的日志
2.机器宕机重启,要做HW截断
为了解决这个问题,一个方法是不要让HW延迟一个网络来回,就是master等所有slave都更新了HW后再更新自己的HW,但这需要一个网络来回确认,对客户端来说
无法接受。并且即使这样也有问题,如果所有的slave都把自己的HW更新了,master正要更新自己的HW的时候出现宕机,会导致master的 HW比slave的HW要小,又会引起
其他问题。
另一个方法是slave不做截断,slave2和slave1对比HW=3以后的部分,不一样的数据补齐。但这无法解决另外一个问题:如果这时候master恢复了,变成了slave,
也要从slave2同步数据,怎么处理?老的 master的HW已经等于5,新的master的HW也追上了5,同时新的master已经新写入了消息8(还未同步到其他节点)。此时老的
master还要做HW截断,把5之后的删除了,然后将6和8同步过来,用8覆盖自己的7.
11.1.2 Kafka消息错乱问题
除了HW截断日志导致消息丢失,还会存在日志错乱的问题。发生日志错乱的场景的前提是"异步刷盘"。因为kafka默认是异步刷盘,每3s调用一次fsync。当然,
kafka也支持同步刷盘,也就是说每写入一条消息就刷盘一次。
仍然以上面的场景为例,master的 HW=5 表示5之前(包括5)的消息已经复制成功了,但由于异步刷盘,master宕机后,slave1也宕机(断电重启)之后重启,
成为master,此时消息5就丢失了。
在此基础上,slave1接着接收新的消息,在本来属于5的位置写入了消息8。然后老master宕机后重启,变成了slave,从slave1同步数据。因为老的master的
HW=5,所以只会从5之后的位置开始同步数据。这会导致master和slave1在HW=5的位置日志不一致,也就是发生了日志错乱。
当然,如果改成同步刷盘,每写一条日志就刷一次盘,不会发生这个问题。但同步刷盘的性能损失太大,所以默认是异步刷盘。而在异步刷盘的情况下,可能发生日志
错乱,这比日志丢失更严重。
为了解决这些问题,KIP 101 引入了 Leader Epoch 的概念,这和Raft的思路类似。
11.2 Paxos算法解析
11.2.1 Paxos解决什么问题
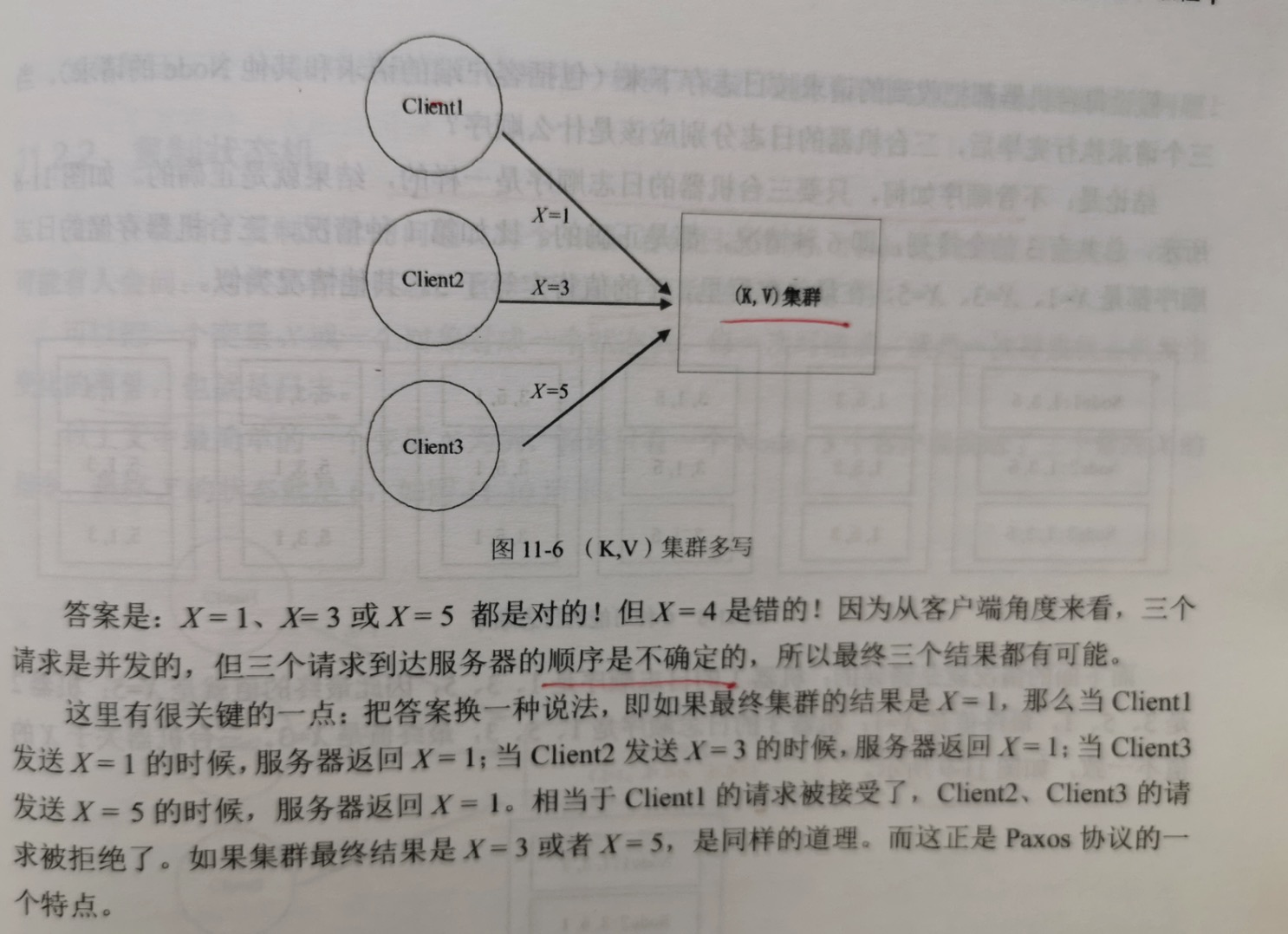
1.一个基本的并发问题
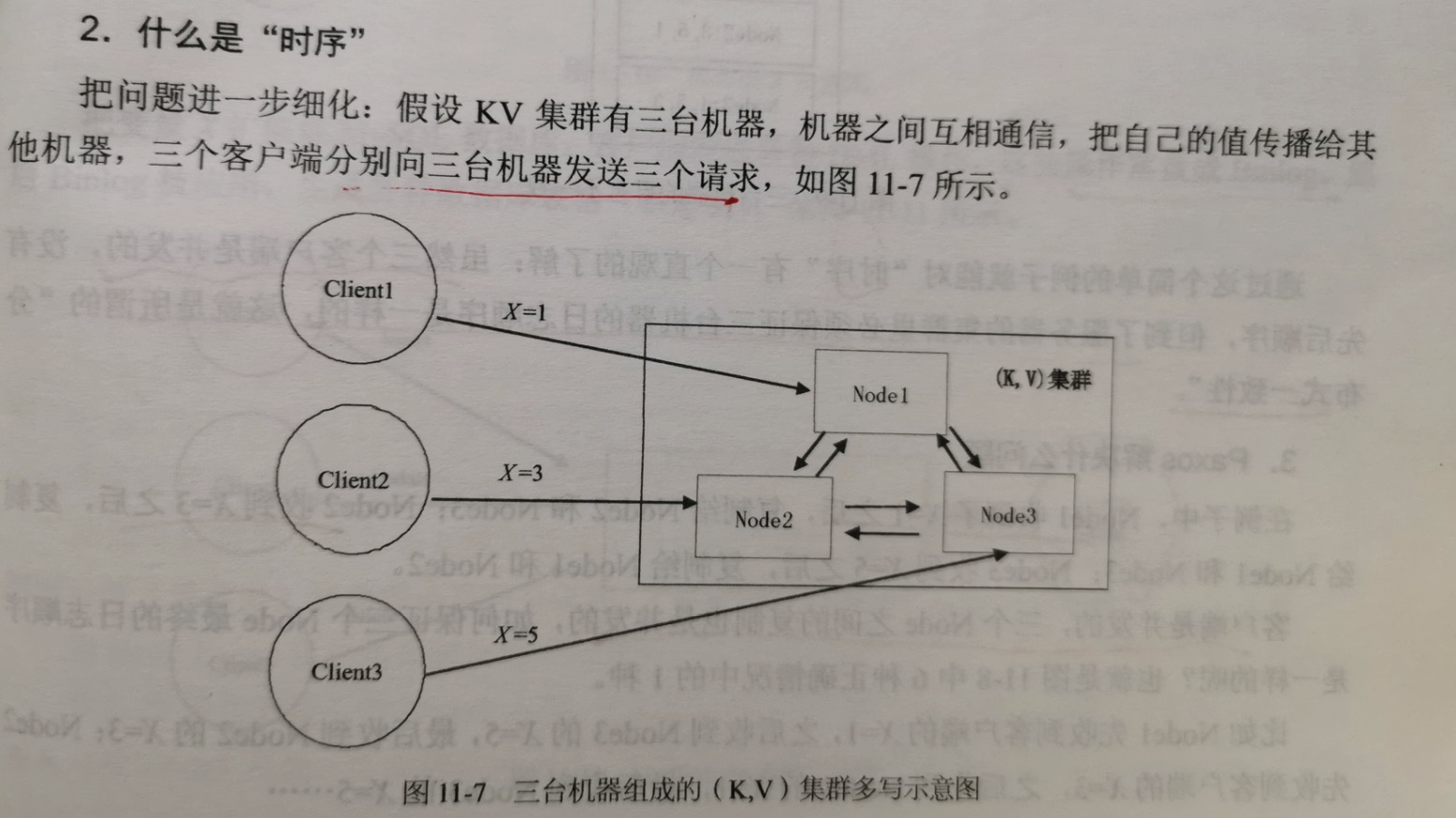
2.什么是"时序"
虽然客户端是并发的,没有先后顺序,但到了服务器的集群里必须保证三台机器的日志顺序是一样的,这就是所谓的"分布式一致性"。
3.Paxos 解决什么问题
如何保证三个Node中存储的日志顺序是一样的?这正是Paxos要解决的问题。
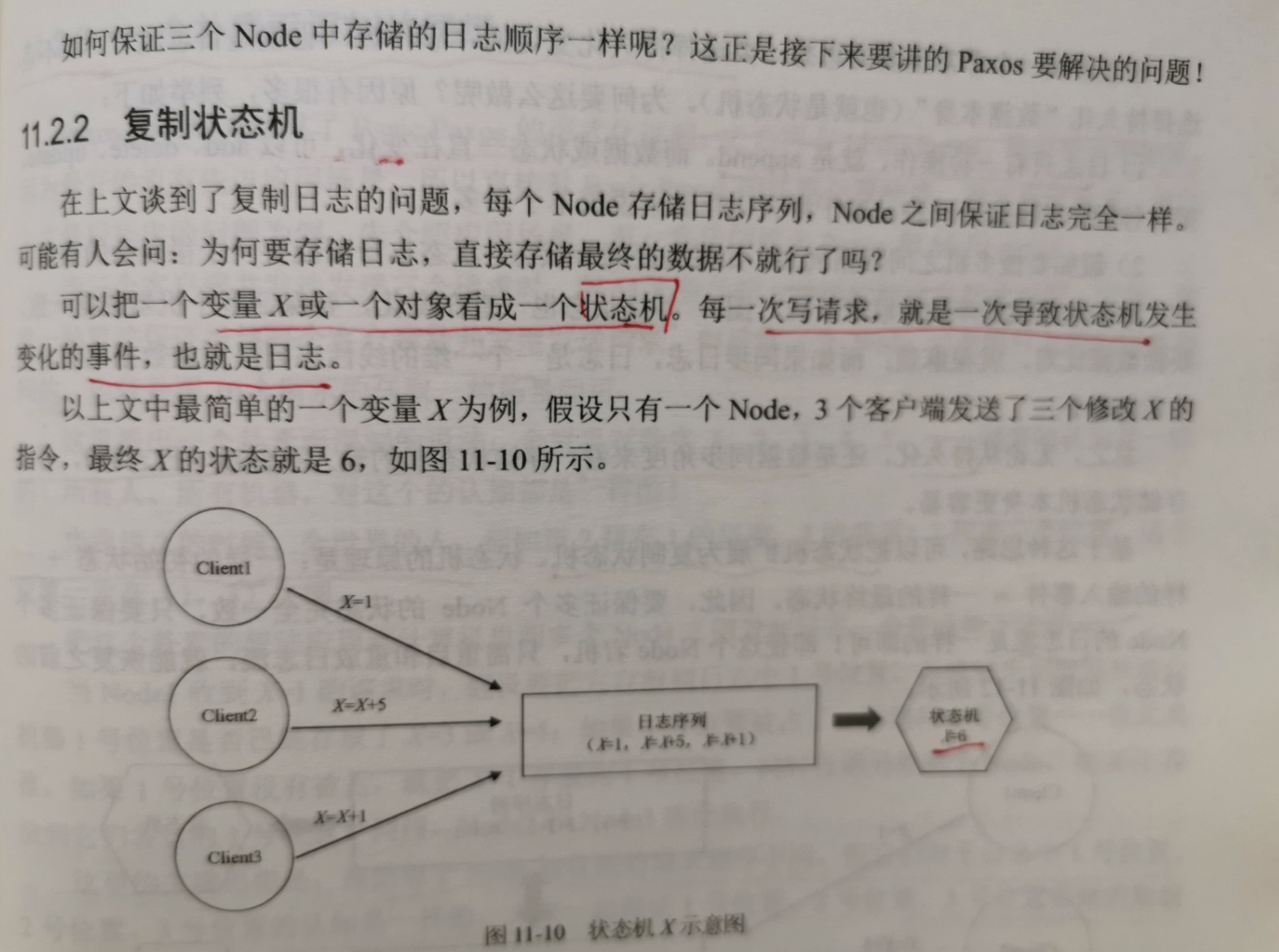
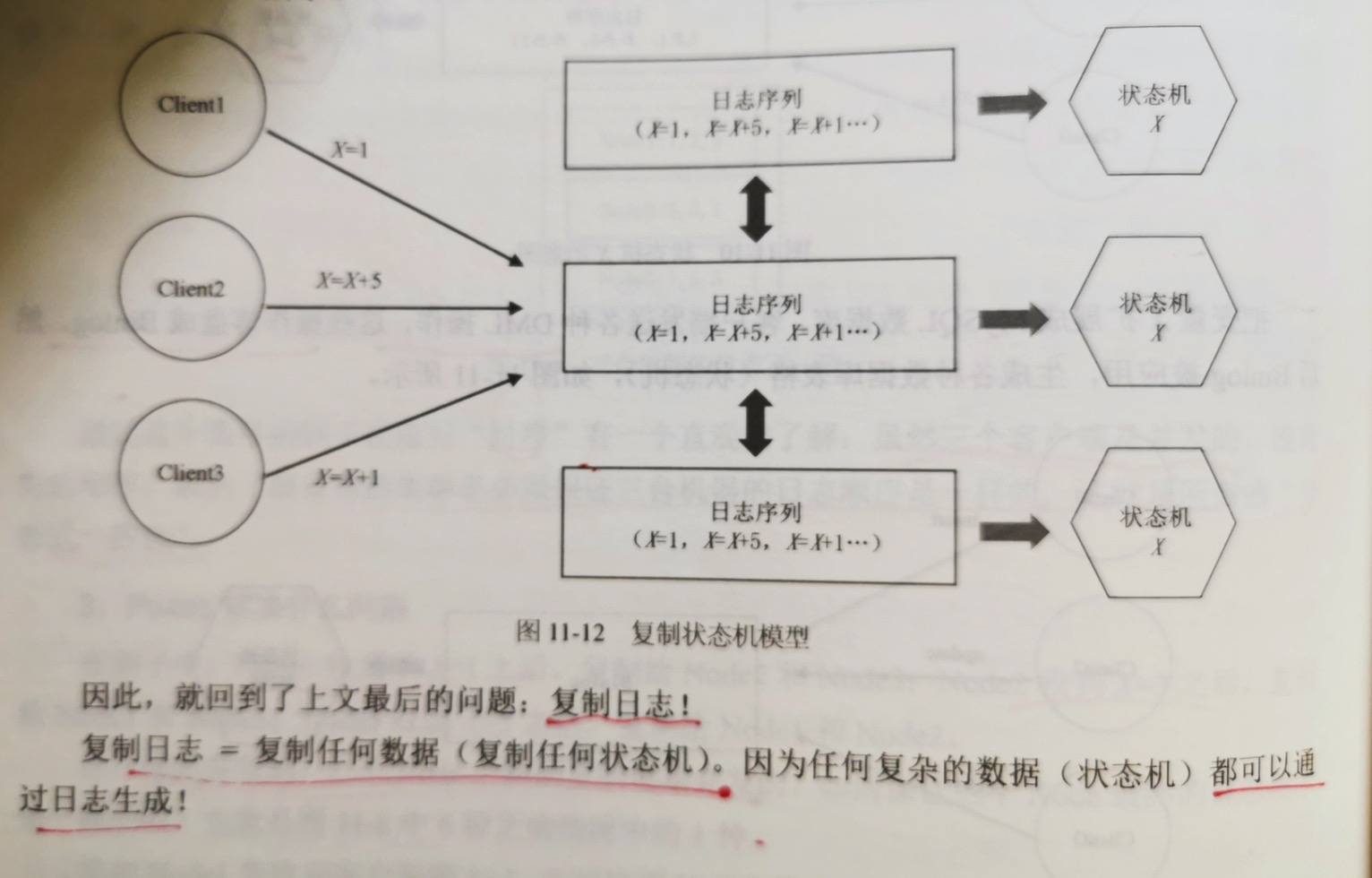
11.2.2 复制状态机
可以把一个变量X和一个对象看成一个状态机。每一次写请求,就是一次导致状态机变化的事件,也就是日志。
这里有一个非常重要的思想:要选择持久化变化的"事件流(也就是日志流)",而不是选择持久化"数据本身"(也就是状态机)。原因如下:
1.日志只是一种操作,就是append。而数据或状态一直变化,可以add,delete,update,把三种操作转换成一种操作,对于持久化存储来说简单多了;
2.假如要做多机之间数据同步,如果直接同步状态,状态本身可能有一个复杂的数据结构(比如关系数据库的关联表,树,图),并且状态一直变化,要保证
多机数据一致,要做数据对比,就很麻烦;而通过同步数据,日志是一个一维的线性序列,要做数据对比,则非常容易。
总之,无论从持久化,还是数据同步角度来看,存储状态机的输入事件流(日志流),都比存储状态机本身更容易。
基于这种思路,可以把状态机扩展为复制状态机。状态机的原理是:一样的初始状态 + 一样的输入事件 = 一样的最终状态。因此,要保证多个node的状态完全
一致,只要保证多个node的日志流是一样的即可。即使这个node宕机,只需要重启和重放日志流,就能恢复之前的状态。
复制日志 = 复制任何数据(复制任何状态机)。因为任何复杂的数据结构(状态机)都可以通过日志生成。
11.2.3 一个朴素而深刻的思想
Paxos的出现先经过了Basic Paxos的形式化证明,之后再有Multi Paxos,最后是应用场景。
当node1收到x=1的请求时,假设要把它存放在日志中的1号位置,存放前先询问另外2台机器1号位置是否已经存放了x=3或x=5;如果1号位置被占了,则询问2号
位置...以此类推。如果1号位置没有被占,就把x=1存放到1号位置,同时告知另外2个node,把x=1存放在各自的1号位置。同样,node2和node3按此执行。
这里的关键思想是:虽然每个node收到的请求顺序不同,但他们对于日志中1号位置,2号位置,3号位置的认知是一样的,大家一起保证1号位置,2号位置,3号
位置存储的数据是一样的。
在例子中可以看到,每个node在存储日志之前先要问一下其他node,之后在决定把这个日志写到哪个位置。这里有2个阶段:先问,再做决策。这也就是Paxos 2PC
的原型。
把问题进一步拆解,不是复制三条日志,只复制一条。先确定3个node的第1号的日志,看有什么问题?
node1询问后发现1号位置没有被占,因此它打算把x=1传播给node2,node3;同一时刻,node2询问后发现1号位置也没有被占,因此也打算把x=3传播给node1,
node2,同样,node3打算把x=5传播给node1,node2。这样结果不就冲突了吗?
而 Basic Paxos 正是用来解决这个问题的。
首先,1号位置要么被node1占用,大家都存放x=1;要么被node2占用,大家都存放x=3;要么被node3占用,大家都存放x=5,少数服从多数。为了达到这个目的,
Basic Paxos提出了一个方法,这个方法包括2个点:
1.node1 在填充1号位置的时候,发现1号位置被大多数确定了,比如是x=5(node3占领了1号位置,node2跟从了node3),则node1就接受这个事实:1号位置不能
用了,也得把自己的1号位置赋值成x=5。然后看2号位置能否把x=1存进去。同样的,如果2号位置也被占用了,就只能把他们的值拿过来填自己的2号位置。看3号位置...
2.当发现1号位置没有被占,就锁定这个位置,不允许其他node占领这个位置,除非权利更大。
如果发现1号位置为空,在提交的时候发现1号位置被其他node占了,就会提交失败,重试,尝试第二个位置,第三个位置...
所以,为了让1号位置日志一样,可能要重试好几次,每个节点都会不断重试2PC。这样不断重试2PC,直到最终各方达成一致的过程,就是Paxos协议执行的过程,
也就是一个Paxos instance,最终确定一个值。而Multi Paxos就是重复这个过程,确定一系列值,也就是日志中的每一条。
11.2.4 Basic Paxos算法
在前面的场景中提到三个client并发的向三个node发送三条写指令。对应到Paxos协议,就是每个node同时充当了2个角色:Proposer和Acceptor。在实现的
过程中,一般这2个角色是在同一个进程里面的。
当node1收到client1发送的x=1的指令时,node1作为一个Proposer向所有Acceptor(自己和其他2个node)提议把x=1日志写到3个node里面。
同理,node2收到client2发送的x=3的指令,node2作为一个Proposer向所有的Acceptor提议;node3同理。
下面详细阐述Paxos的算法细节。首先,每个Acceptor需要持久化3个变量(minProposalId,AcceptProposalId,acceptValue)。在初始化阶段:
minProposalId = acceptProposalId = 0,acceptValue = null。然后,算法有2个阶段:P1(Prepare阶段)和P2(Accept阶段)。
1.P1(Prepare阶段)
P1a:Proposer广播prepare(n),其中n是一个本机生成的自增ID,不需要全局有序,比如可以用时间戳+IP。
P1b:Acceptor收到 Prepare(n),做出如下决策:
if n > minProposalId,回复yes。
同时,minProposalId = n (持久化),
返回(acceptProposalId, acceptValue)
else
回复 no
P1c:Proposer 如果收到半数以上的yes,则取 acceptorProposalId最大的acceptValue作为v,进入第二阶段,即开始广播 accept(n,v)。如果
acceptor返回的都是null,则取自己的值作为v,进入第二阶段。否则,n自增,重复P1a。
2.P2(Accept阶段)
P2a:Proposer广播 accept(n,v)。这里n就是P1阶段的n,v可能是自己的值,也可能是第1阶段 acceptValue。
P2b:Acceptor 收到 accept(n,v),做出如下决策:
if n >= minProposalId,回复 yes,同时
minProposalId = acceptProposalId = n (持久化),
acceptValue = value
return minProposalId
else
回复 no
P2c:Proposer 如果收到半数以上的 yes,并且 minPoposalId = n,则算法结束。否则,n 自增,重复 P1a。
通过分析,会发现 Basic Paxos 有2个问题:
1.Paxos 是一个 "不断循环" 的2PC。在P1C或者P2C阶段,算法都可能失败,重新进行P1a。这就是所说的"活锁"问题,即可能陷入不断循环。
2.每确定一个值,至少需要2次RTT(2个阶段,2个网络来回) + 2次写盘,性能也是个问题。
而接下来要讲的 Multi-Paxos 就是要解决这2个问题的。
11.2.5 Multi Paxos算法
1.问题1:活锁问题
在前面已经知道,Basic Paxos 是一个不断循环的2PC。所以如果是多个客户端写多个机器,每个机器都是Proposer,会导致并发冲突很高,也就是每个节点
都可能执行多次循环才能确定一条日志。极端情况下是每个节点都在无限的循环执行2PC,也就是所谓的"活锁问题"。
为了减少冲突,可以变多写为单写,选出一个Leader,只让Leader充当Proposer。其他机器收到写请求,都把写请求转发给Leader;或者让客户端把写请求
都转发给Leader。
Leader的选举方法有很多,下面列举2种:
1.方案1:无租约的Leader选举
Lamport 在他的论文中给出了一个 Leader 选举的简单算法,算法如下:
1.每个节点有一个编号,选取编号最大的节点为Leader;
2.每个节点周期性的向其他节点发送心跳,假设周期为 T ms;
3.如果一个节点在最近的 2T ms内还没有收到比自己编号更大的心跳,则自己变成 Leader;
4.如果一个节点不是Leader,则收到请求后转发给Leader;
可以看出算法很简单,但因为网络超时等原因,很可能出现多个Leader,但这并不影响Multi Paxos协议的正确性,只是增大了并发写冲突的概率,
我们的算法并不需要强制保证,任何时刻只能有一个Leader。
2.方案2:有租约的Leader选举
另外一种方案是严格保证任意时刻只能有1个leader,也就是所谓的"租约"。
租约的意思是在一个限定的时间内,某台机器一直是leader。即使这个机器宕机,leader也不能切换,必须等到租约到期后,才能开始新的leader的
选举。这种方法带来了短暂的不可用,但保证了任意时刻只会有一个leader。具体实现方式可以参照PaxosLease。
2.问题2:性能问题
我们知道 Basic Paxos 是一个无限循环的 2PC,一条日志的确认至少需要2个RTT+2次落盘(一次是 Prepare 的广播与回复,一次是 Accept 的广播与
回复)。如果每条日志都要2个RTT+2次落盘,这个性能就很差了。而Multi Paxos在选出leader之后,可以把2PC优化成1PC,也就是只需要1个RTT+1次落盘。
基本思路是当一个节点被确认为 leader之后,它先广播一次Prepare,一旦超过半数同意,之后对于收到的每条日志直接执行Accept操作。在这里,Prepare
不再是对一条日志的操作了,而是相对于拿到了整个日志的控制权。一旦这个leader拿到了整个日志的控制权,后面就直接略过Prepare,执行Accept。
如果有新的leader出现怎么办?新的leader肯定会先发起Prepare,导致 minProposalId变大。这时旧的leader的广播Accept肯定会失败,旧的leader
会自己转变成一个普通的Acceptor,新的leader把旧的顶替掉了。
下面是具体实现的细节:
在 Basic Paxos 中,2PC 的具体参数形式如下:
prepare(n)
accept(n,v)
在Multi Paxos 中,增加一个日志的index参数,即变成了如下形式:
prepare(n, index)
accept(n, v, index)
3.问题3:被 choose的日志,状态如何同步给其他机器
对于一条日志,当Proposer(也就是leader)接收到多数派对Accept请求的同意后,就知道这条日志被"choose"了,也就是被确认了,不能再更改。
但只有Proposer知道这条日志被确认了,其他的Acceptor并不知道这条日志被确认了,如何把这条信息传递给其他Acceptor呢?
方案1:Proposer 主动通知
给accept再增加一个参数:
accept(n, v, index, firstUnchoosenIndex)
Proposer 在广播 accept 的时候,额外带来一个参数 firstUnchoosenIndex = 7。意思是7之前的日志已经被"choose"了。Acceptor收到
这种请求后,检查7之前的日志,如果发现7之前的日志符合下面的条件:acceptProposal[i] = request.proposal(也就是第一个参数n),就把该日志
的状态置为choose。
方案2:Acceptor 被动查询
当第一个Acceptor被选为leader后,对于所有未确认的日志,可以逐一再执行一遍Paxos,来判断该条日志被多数派确认的值是多少。
因为Basic Paxos 有一个核心特性:一旦一个值被确认之后,无论再执行多少遍Paxos,该值都不会改变,因此,再执行1遍Paxos,相当于向集群发起了
一次查询。
至此,Multi Paxos 算法就介绍完了,回顾这个算法,有2个精髓:
精髓一:一个强一致的"P2P网络"
任何一条日志,只有2种状态(choose,unchoose)。当然,还有一种状态 applied,也就是被确认的日志被apply到状态机。这种状态和Paxos协议关系不大。
choose是这条日志被多数派接受,不可更改。
unchoose 就是还不确定,就是"薛定谔的猫",或者"最大commit原则"。一条unchoose的日志可能是被choose了,只是该节点自己不知道;也可能是还没被
choose。想要确认,就再执行一次Paxos,也就是所谓的"最大commit原则"。
整个Multi Paxos就是一个类似P2P网络,所有节点都双向同步,对所有的unchoose的日志进行不断确认的过程。在这个过程中可能会出现多个leader,多个
leader的切换,但这都不影响算法的正确性。
精髓二:"时序"
Multi Paxos 保证了所有的节点的日志顺序是一模一样的,但对于每个节点自身来说,可以认为它的日志并没有所谓的"顺序"。什么意思呢?
a) 假如一个客户端连续发送了两条日志a,b(a 没有收到回复,就发出了b)。对于服务器来讲,存储顺序可能是a,b,也可能是b,a,还可能是在a,b之间
插入了其他客户端发来的日志。
b) 假如一个客户端连续发送了2条日志a,b(a收到回复之后,再发出b)。对于服务器来说,存储顺序可能是a,b;也可能是a,xxx,b(a,b之间插入了其他客户端
的日志),但不会出现b在a前面。
所谓的时序,只有在单个客户端串行的发送日志时,才有所谓的时序。多个客户端并发的写,服务器又是并发的对每个日志执行Paxos,整体看起来就没有所谓的
时序。
11.3 Raft算法解析
11.3.1 为“可理解性”而设计
11.3.2 单点写入
Paxos 算法可以多点写入,不需要选出leader,每个节点都可以接受客户端的写请求。虽然为了避免"活锁"问题,Multi Paxos 可以选出一个leader,但也不是
强制执行的,允许同一时间有多个leader同时存在。多点写入,使得算法理解起来复杂多了。
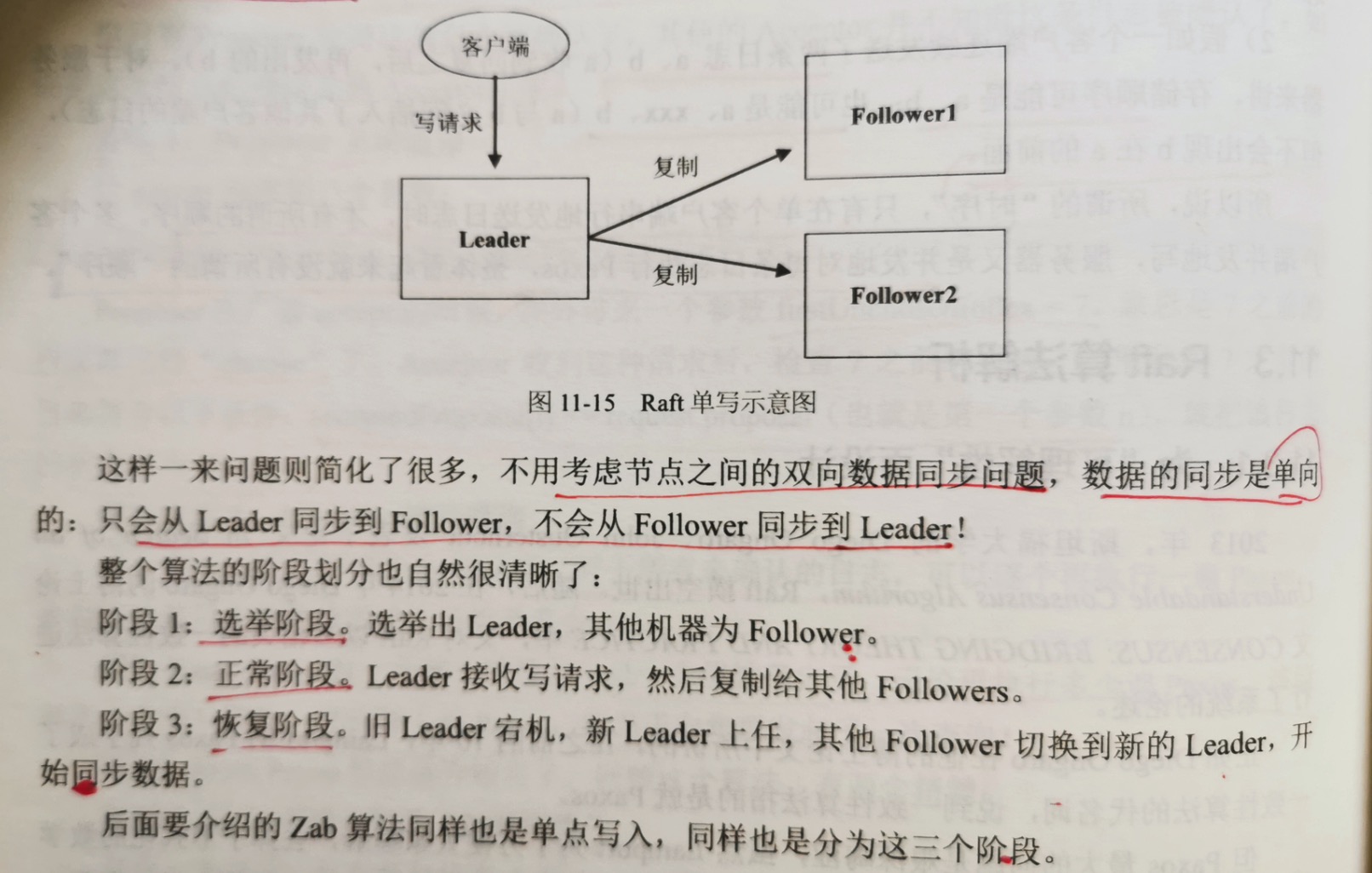
为了简化这一问题,Raft限制为"单点写入"。必须选出一个leader,并且任一时刻只允许一个有效的leader存在,所有的写请求都传到leader上,然后由leader
同步给超过半数的Follower。
这样一来问题就简化很多了,不用考虑节点之间的双向数据同步问题,数据的同步是单向的:只会从 leader 同步到 Follower,不会从Follower同步到Leader。
整个算法的阶段划分也自然很清晰了:
阶段1:选举阶段。选出leader,其他机器为Follower。
阶段2:正常阶段。leader接收请求,然后复制给其他Follower。
阶段3:恢复阶段。旧leader宕机,新leader上任,其他follower切换到新的leader,开始同步数据。
11.3.3 日志结构
因为复制的是日志,日志的存储结构是这个算法的基石。
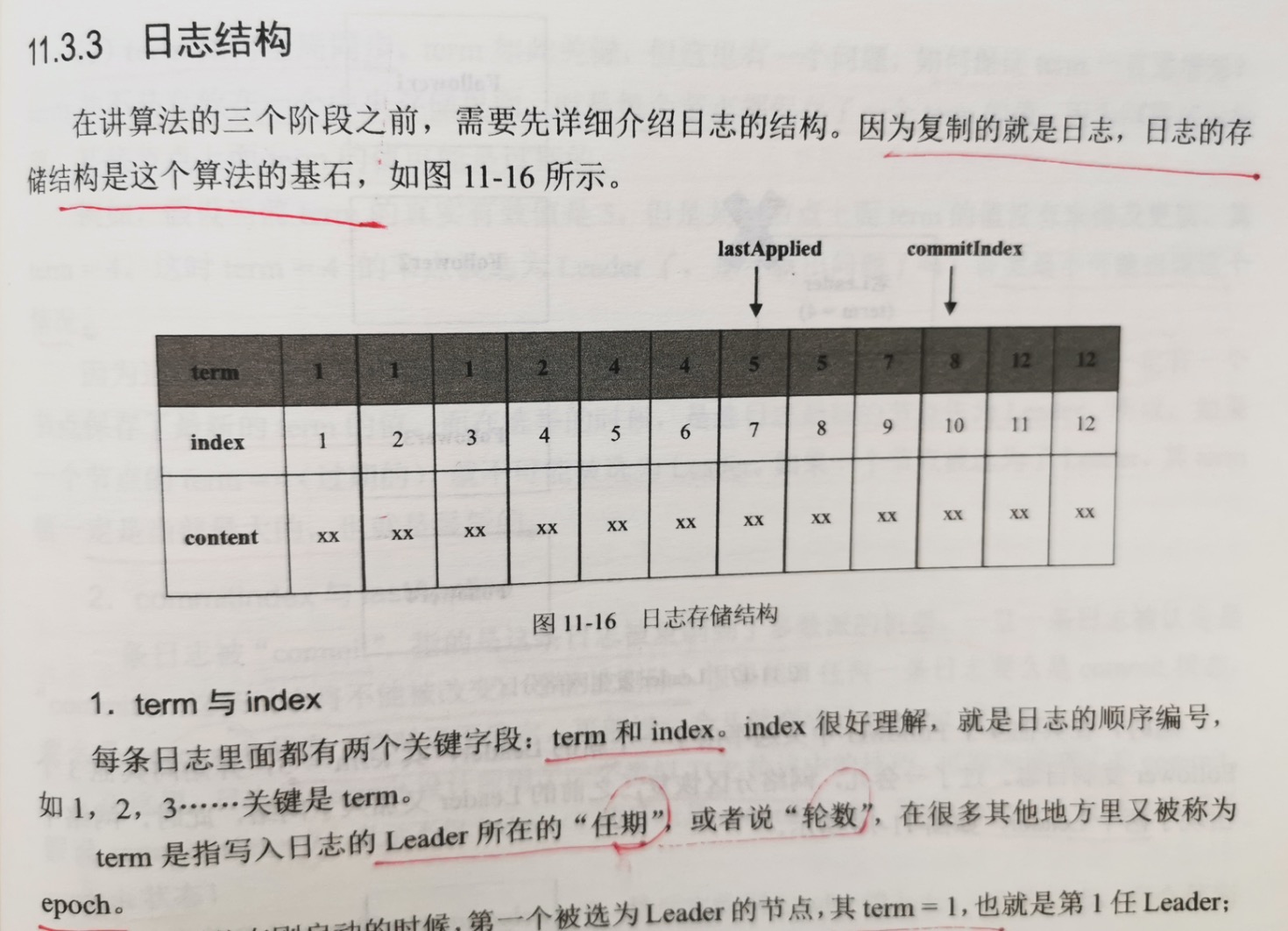
1.term 和 index
每条日志里面都有2个关键字段:term和index。index很好理解,就是日志的顺序编号,如1,2,3 ...
term是指写入日志的leader所在的 "任期",后者说 "轮数"。在其他很多地方又称为 epoch。
关于term,有2个关键问题需要讨论。
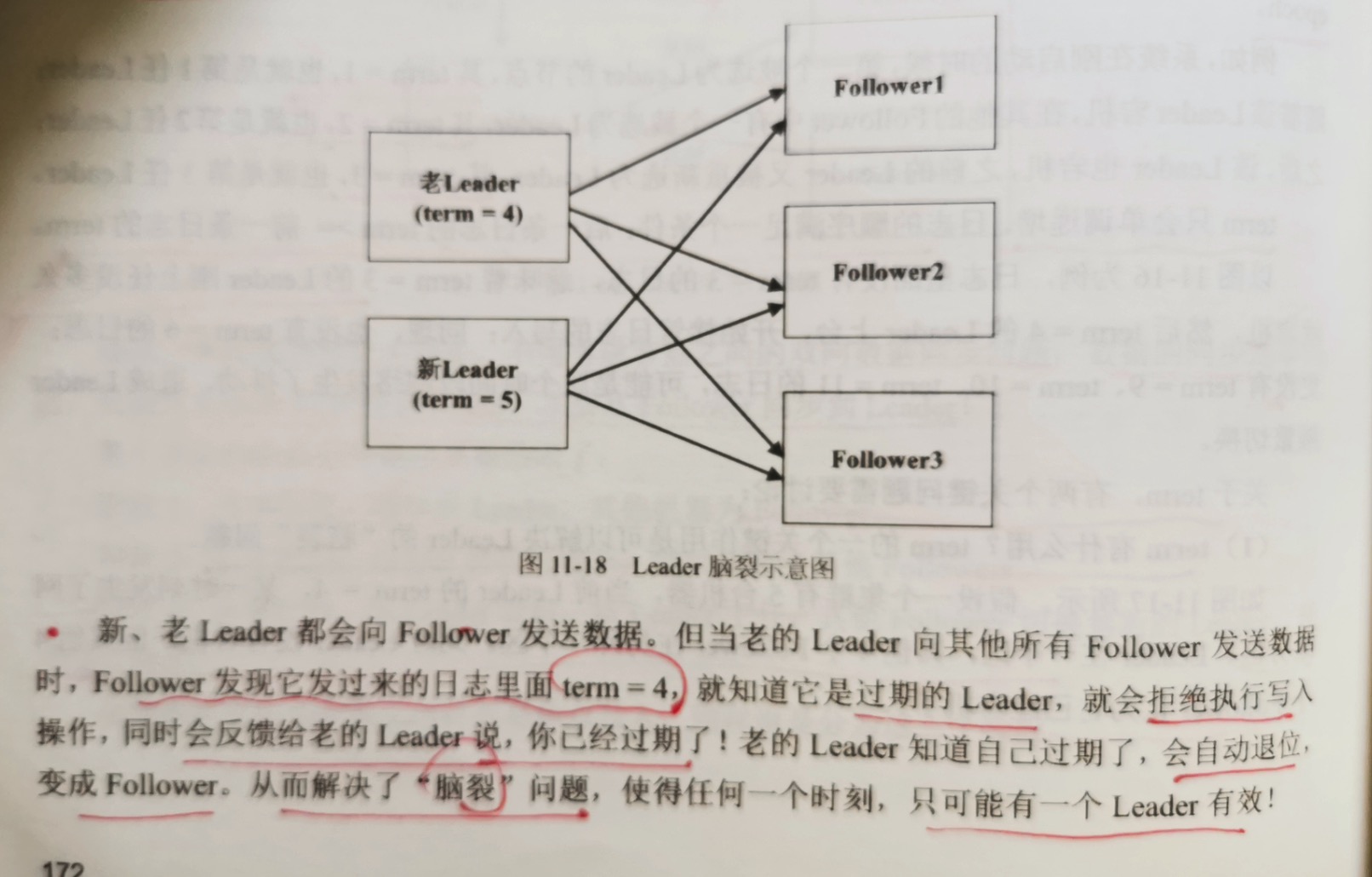
1.term有什么用?term的一个关键作用是可以解决leader的"脑裂"问题。
5台机器,当前leader的 term = 4,某一时刻,发生网络分区,leader在一个区,其他4个follower在另外一个区。此时leader没有宕机,但
其他follower认为它已经宕机了。
这时候又选出新的leader,term = 5,开始向其他3个follower同步数据。过了一会,网络分区恢复,之前的leader又加入网络。此时出现2个
leader。
新老leader都会向follower发送数据。但当老的leader向其他所有follower发送数据时,follower发现其发过来的term=4,就知道是过期的
leader,就会拒绝写入,同时会反馈给旧leader,说你已经过期了。老的leader知道自己过期后,就会自动退位,变成follower。从而解决"脑裂"
问题,使得任何时刻,只可能有一个leader存在。
2.term如何全局同步。term如此关键,但这里有个问题,如何保证term一直递增呢?term并不是放在一个中央存储里面,而是每个节点都保存了一个term
值。因为网络延迟问题,某些节点上term的值可能是过期的。
假设当前有效的term=5,但是某些节点上term值没有来得及更新,还是term=4,这时term=4的节点被选为leader了,那不就出问题了?答案是
不可能出现这个情况。
因为选举的时候是要多数派(超过半数节点)同意的,意味着多数派里面一定有一个节点保存了最新的term的值。而在选举的时候,是选日志最新的节点
作为leader的,所以,一个节点term=4(过期的),就不可能被选为leader了。如果一个节点被选为leader,其term的值也一定是当前最大的,也就是
最新的。
2.commitIndex 与 lastApplied
一条日志被 "commit" ,指的是这条日志被复制到了多数派的机器。一旦一条日志被认定是"commit",这条日志将不能被改变,不能被删除。很显然,任何
一条日志要么是 commit 状态,要么是 uncommit 状态(暂时还不确定,可能过一会儿就变成 commit 状态)。
在这里,日志的commit被设计成一个类似tcp协议中的技巧,可称为递增式的commit。假设 commitIndex = 7,表示不仅 index=7的日志是commit状态,
所有index < 7的日志也是commit状态。
假设当前follower的 commitIndex = 7,然后它收到 leader的index=9的日志,它会等到index=8的日志到来之后,一次性告诉leader 9之前的日志
都commit了。这样有2个好处:
1.不需要为每条日志都维护一个commit或者uncommit状态,而只需要维护一个全局变量commitIndex即可。
2.follower不需要逐条反馈leader,那一条commit了,哪一条uncomimt。
至于lastApplied 很好理解,就是记录哪些日志已经被放回到了状态机。很显然 lastApplied <= commitIndex。lastApplied 在Raft算法本身其实
不需要,只是上层的状态机的实现所需要的。
3.State变量
每个节点都维护了哪些变量,这些变量一起构成了每个节点的State。
变量名称:变量描述:存储特性
1.log[];每个节点存储的日志序列;落盘
2.currentTerm;该节点最新看到的term;落盘
3.votedFor;当前term下,把票头给了谁,一个term,只能投一次;落盘
4.commitIndex;上面已讲;内存
5.lastApplied;上面已讲;内存
6.nextIndex[];leader上面,为每个follower维护一个nextIndex,即要将同步的日志的起始位置;内存,只有leader上面有
7.matchIndex[];leader上面,为每个follower维护的,match日志的最大index。nextIndex和matchIndex是[begin,end]关系,这个区间里面的日志意味着要复制,还没复制的;内存,只有leader上面有
11.3.4 阶段1:Leader选举
任何一个节点有且仅有三种状态:Leader,Follower,Candidate。Candidate是一种中间状态,是正在选举中,选举结束后要么切换到leader,要么切换到
follower。
1.初始时,所有机器处于follower状态,等待leader的心跳消息(一个机器成为leader之后,会周期性的给其他follower发心跳)。很显然,此时没有leader,
所以收不到心跳;
2.当follower在给定的时间内(比如2000ms)内收不到leader消息,就会认为leader宕机了,也就是选举超时。然后,随机睡眠0~1000ms之间的一个值(为了
避免大家同时发起选举),把自己切换成Candidate状态,发起选举;
3.选举结束,自己变成leader或者follower;
4.对于leader,发现有更大的term的leader存在,自己主动退位,变成follower。
这里有个关键点:心跳是单向的,只存在leader 周期性的向follower 发送心跳,follower不会反向向leader发送心跳。后面要讲的Zab心跳是双向的,很显然,
单向比双向简单的多。
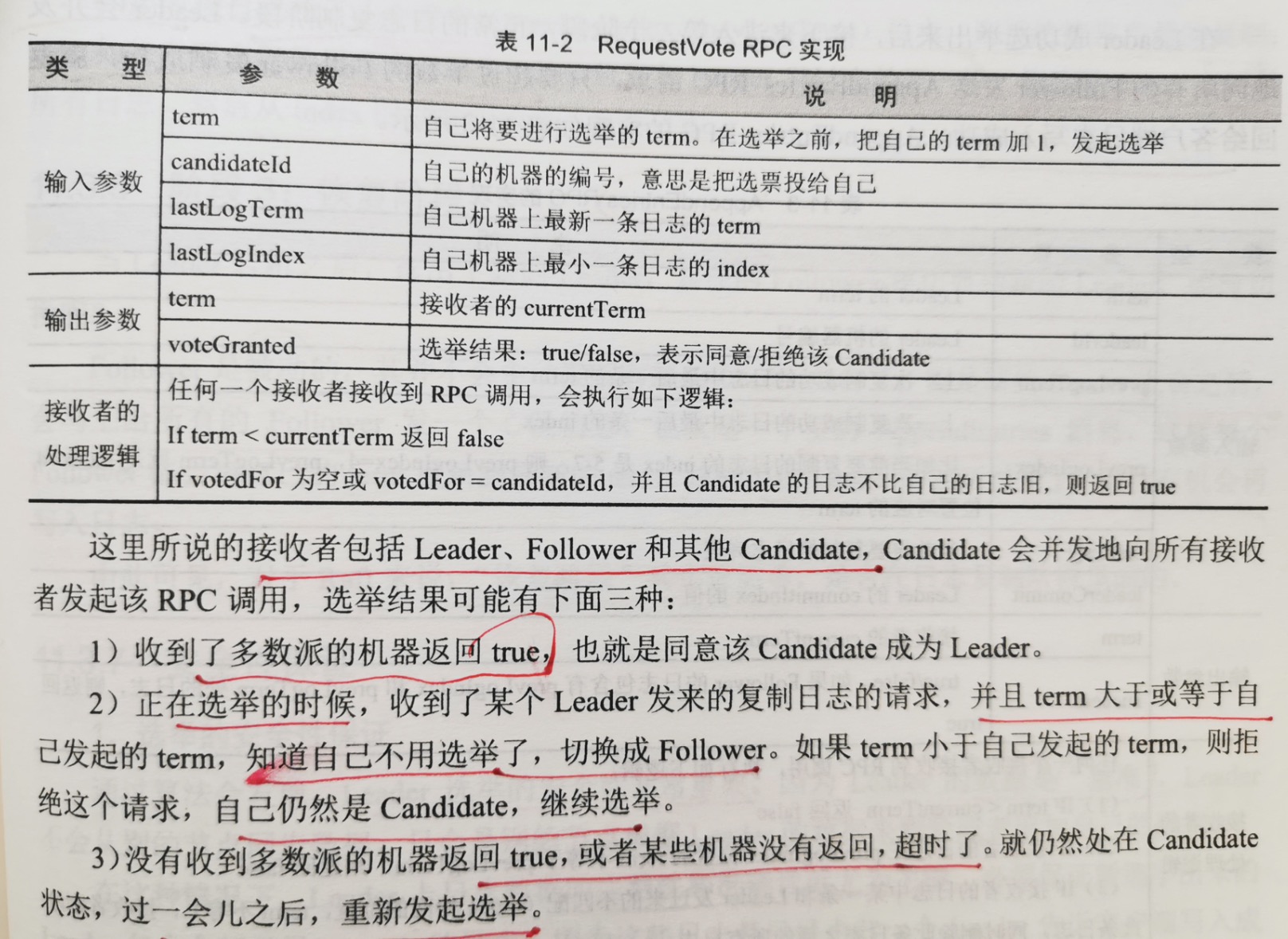
下面来看选举算法的过程:处于Candidate状态的节点会向所有节点发起一个RequestVote的RPC调用,如果有超过半数的节点回复true,则该节点成为leader。
这里说的接收者包括 leader,follower 和 其他Candidate,Candidate会向所有接收者发起该RPC调用,选举结果可能有三种:
1.收到了多数派的机器回复true,也就是同意该Candidate成为leader;
2.正在选举的时候,收到了某个leader发来的复制日志的请求,并且term大于或等于自己发起的term,知道自己不用选举了,切换成follower,如果term小于
自己发起的term,则拒绝这个请求,自己仍然是Candidate,继续选举;
3.没有收到多数的机器返回true,或者某些机器超时没有返回。就仍然处于Candidate状态,过一会儿,重新发起选举。
通过看接收者的处理逻辑会发现,新选出的leader一定拥有最新的日志。因为只有Candidate的日志和接收者一样新,或者比接收者还新,接收者才会返回true。
这里有关于日志新旧的准则:
1.term > b.term;
2.term = b.term 且 a.index > b.index
这里有一点需要说明:假设有2个Candidate,term=5,同时发起一次选举。对于follower来说,先到先得,先收到谁的请求,就把票投给谁。保证对于一个term
而言,一个follower只能投一次票,如果投给了Candidate1,就不能再投给Candidate2。这意味着Candidate可能都得不到多数派的票,就把自己的term自增到6,
重新发起一次投票。
11.3.5 阶段2:日志复制
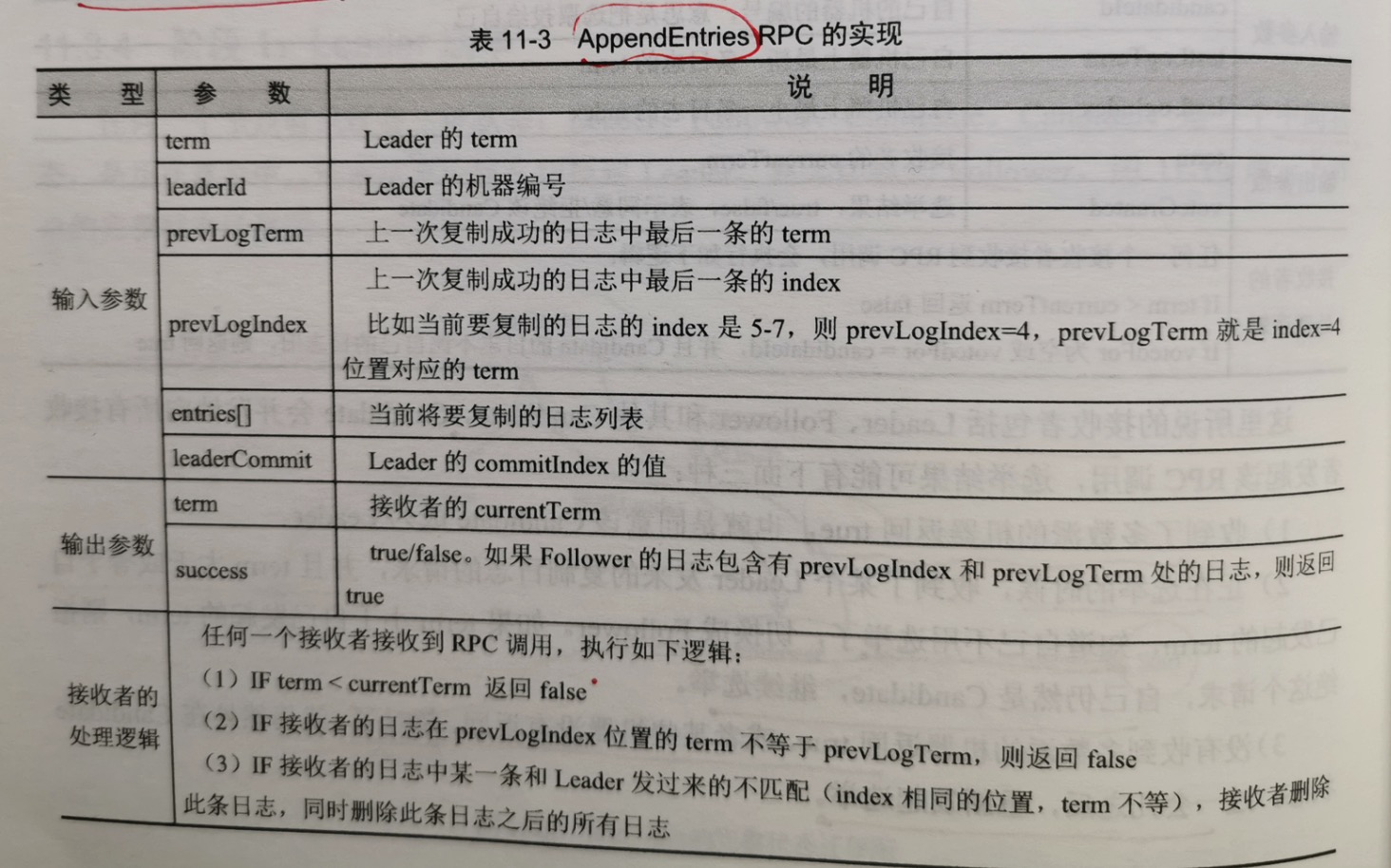
在Leader选举成功后,接下来进入第二个阶段,正常的日志复制阶段。leader会并发的向所有follower发送AppendEntries RPC 请求。只要超过半数follower
复制成功,就返回给客户端日志写入成功。
在这个rpc里面,有两个关键的"日志一致性"保证,保证leader和follower日志序列完全一样:
1.对于2个日志序列里面的两条日志,如果其index和term都相同,则日志内容必定相同;
2.杜宇2个日志序列,如果index=M处的日志相同,则在M之前的所有日志完全相同。
在这两个保证中,第二个尤为重要。意味着:如果知道follower和leader在index=7位置的日志是相同的,则index=7之前的日志也相同。
利用这个保证,follower接收到日志之后,可以很方便的做一致性检查:
如果发现日志中没有(preLogIndex, preLogTerm)日志,则拒绝接收当前的复制;
如果发现自己的日志中,某个index位置和leader发过来的不一样,则删除index之后的所有日志,然后从index的位置同步接下来的日志。
11.3.6 阶段3:恢复阶段
当Leader宕机后,选出了新的leader,其他的follower要切换到新的leader,如何切换呢?
follower是被动的,并不会主动发现有新的leader上台;而是新的leader上台后,会马上给所有的follower发一个心跳消息,也就是一个空的AppendEntries,
这样每个follower都会将自己的term更新到最新的term。这样旧的leader即使活过来了,也再也没有机会写入日志。
由此可见,对于Raft来说,"恢复阶段"其实很简单,是合在日志复制阶段里面的。
11.3.7 安全性保证
1.选举的安全性保证
通过算法发现,leader选举的安全性非常重要。因为leader的数据是"基准",Leader不会从别的节点同步数据,只会是别的节点根据leader的数据来删除
或者追加自己的数据。
在这种情况下,leader上的日志的完整性和准确性就尤为关键了,必须保证新选举出来的leader包含全部已经commit的日志,因为这些日志是已经由前一个
leader告诉客户端写入成功的。至于uncommit的日志,无论丢弃,还是保存,都是正确的。
但这里有个问题: follower的 commitIndex 要比leader的延迟一次网络调用,也就是要等下一次AppendEntries的时候,follower才知道leader的
上一次commitIndex是多少,这个问题与kafka丢数据的场景是一样的。
follower根本不知道新的commitIndex在哪,它被选为了leader,怎么知道最新的commit日志一定在它的日志里面呢?
这里有个推论性的内容:
新选出的leader的日志,是超过半数的节点的最新的日志,这个"最新",是指所有的commit和uncommit日志中最新的,也因此新选出的leader一定
包含所有commit日志。
但这里有个关键点要说明:虽然新选出的leader包含所有commit的日志,但不代表这些日志的状态都是commit的,原因前面已经说了,新选出来的leader
的commitIndex比之前的leader的commitIndex 延迟一个网络调用。
不过没关系,虽然这些日志暂时是uncommit,但稍后一定会变成commit,因为leader不会删日志,这些日志最终都会被多数派的节点复制。
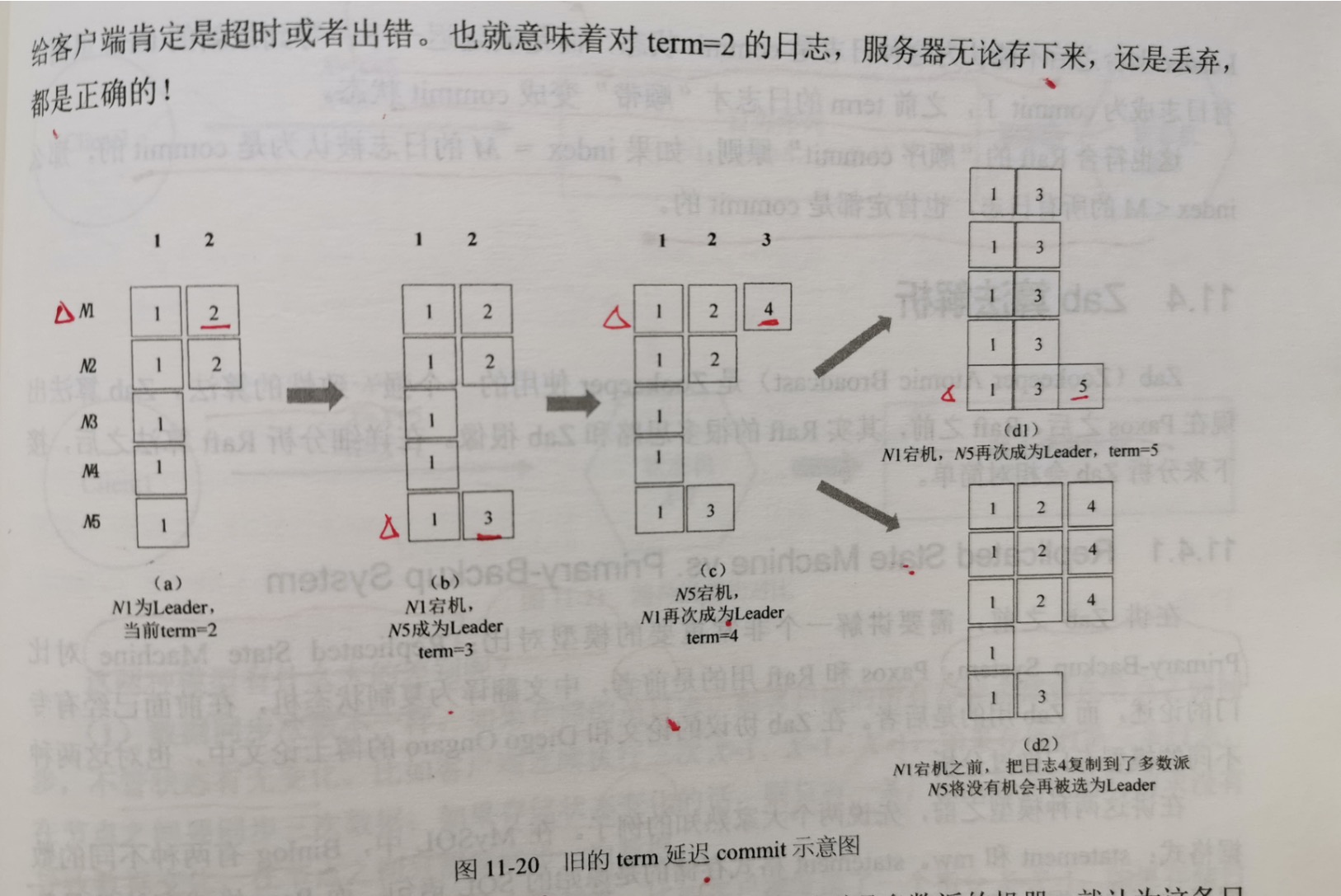
2.前一个term的日志延迟commit
新的leader上台之后,对于自己的term的日志很确信一点:就是一旦自己的term的日志被多数派复制成功了,这些日志就是commit状态。但对于前一个term
遗留的日志,这些日志还是uncommit状态,那是否一旦被多数派复制成功,就认为是commit的呢? 实际情况并非如此。
前面情况违背了Raft定义的一条原则:一条日志一旦被复制到了多数派的机器,就认为这条日志是commit状态,这条日志就不能被覆盖。
怎么办呢?要改变"commit"的定义,重新定义什么叫做一条日志被commit了,定义改为如下:
新的leader上台后,对于旧的term的日志,即使被复制到了多数派,仍然不认为是commit的,只有等到新的leader在自己的term内commit了日志,之前
的term 的日志才能算是被commit了。
最后总结一下:站在客户端的角度,场景d1和d2都是正确的,但场景d1发生了多数派的日志被覆盖的情况,之所以会出现这个情况,是因为term=2的日志不是
一次性被复制到多数派的,而是跨越了多个term,"断断续续"的被复制到多数派。对于这种日志,新的leader上台之后不能认为这种日志是commit的,而是要延迟
一下,等到新的term里面,有日志成为commit了,之前term的日志才"顺带"变成commit了。
这也符合Raft的"顺序commit"原则:如果index=M的日志被认为是commit的,那么index<M的所有日志,也肯定是commit了。
11.4 Zab算法解析
ZAB(Zookeeper Atomic Broadcast)是zookeeper使用的一个强一致性的算法。Zab算法出现在Paxos之后,Raft之前。
11.4.1 Replicated State Machine vs. Primary-Backup System
在讲Zab之前,需要讲解一个非常重要的模型对比:Replicated State Machine 对比 Primary-Backup System。Paxos 和 Raft 用的是前者,中文译为
复制状态机,而zab使用的是后者。
举例:
在mysql中,binlog有两种不同的数据格式:statement和raw。statement格式存储的是原始的sql语句,而raw格式存储的是数据表的变化数据。
在redis中,有rdb和aof 两种持久化方式。rdb格式持久化的是内存的快照,aof持久化的是客户端 set/incr/decr 指令。
通过2个例子可以看出,一个持久化的是客户端的请求序列(日志序列),另外一个是持久化数据的状态变化,前者对应的是 Replicated State Machine,后者对应
的是 Primary-Backup System。
以一个变量X为例,展示两种模型:
假设初始时 x=0,客户端发送了x=1,x=x+5,x=x+1 三条指令。
如果是 Replicated State Machine,节点持久化的是日志序列,在节点之间复制的是日志序列,然后把日志序列应用到状态机(X),最终x=7;如果是
Primary-Backup System,则先执行 x=1,状态机的状态变成x=1,再执行x=x+5,状态机的状态变成x=6;再执行x=x+1,状态机的状态变成x=7。在这种模型下,
节点存储的不再是日志序列,而是x=1,x=6,x=7这种状态的变化序列,节点之间复制的也是这种状态的变化序列。
这两种模型有什么区别呢?
1.数据同步次数不一样。
如果存储的是日志,则客户端的所有写请求都要在节点之间同步,不管状态有无变化。比如客户端连续执行x=1,x=1,x=1,如果存储的是3条日志,在节点
之间要同步三次数据;如果存储的是状态的变化,则只有1条,因为后2次的写请求没有导致数据的变化,在节点之间只需要同步一次即可。
2.存储状态变化。
其天然具有幂等性。比如客户端发送了一个指令x=x+1,如果存储日志x=x+1,Apply多次就会出现问题;但如果存储的是状态的变化x=6,即使Apply
多次也没有关系。
具体到zookeeper,其数据模型是一个树状结构,对应的Primary-Backup 复制模型如下。
同Raft一样,zab也是单点写入。客户端的写请求都会写入Primary Node,Primary Node 更新自己本地的树,这棵树也就是上面所说的状态机,完全在内存中,
对应的树的变化存储在磁盘上面,称为Transaction日志。Primary节点把Transaction日志复制到多数派的Backup Node上面,Backup Node 根据Transaction
日志更新各自内存中的这棵树。
11.4.2 zxid
zookeeper 中的 Transaction 指的并不是客户端的日志,而是zookeeper的这颗内存树的变化。每一次客户端的写请求导致的内存树的变化,生成一个对应的
Transaction,每个Transaction有一个唯一的ID,称为zxid。
在Raft里面,每一条日志有一个term和index,把这2个拼凑起来,就类似于zxid。zxid是一个64位的整数,高32位表示leader的任期,在Raft里面叫term,
这里叫epoch;低32位是任期内日志的顺序编号。
对于每一个新的epoch,zxid的低32位的编号都从0开始,这不同于Raft的一个地方,在Raft里面,日志的编号呈全局递增。
两条日志的新旧比较办法和Raft中2条日志的比较办法类似:
1.日志a的epoch大于b的epoch,则日志a的zxid大于b的zxid,日志a比日志b新;
2.日志a的epoch大于b的epoch,并且日志a的编号大于日志b的编号,则日志a的zxid大于b的zxid,日志a比日志b新。
11.4.3 “序”:乱序提交 vs. 顺序提交
在分析Paxos算法的时候,专门提到"时序"背后的含义。现在知道了zxid是"有序"的,知道了Raft算法的日志也是有序的,在此对有序进行一个讨论,这是所有
分布式一致性的基石。
Paxos 多点写入 --- 乱序提交:
node1,node2,node3 同时接受client的写入请求,clien1在请求1还没返回之前,又发送了请求2;同样,client2在请求3没有返回之前,发送了请求4;
client3类似。clien1,clien2,clien3 是并行的。
试问:请求1到请求6,能按时间排除顺序吗?
请求1和请求2是可以按时间排序的,如果客户端用tcp发送,则node1肯定先收到请求1,再收到请求2;如果客户端用udp发送,node1可能先收到请求2,后
收到请求1,但无论如何,对node1来说,它可以对请求1,请求2接收到的时间顺序排序;node2,node3同理。
但要对请求1到请求6做一个全局排序,是做不到的。因为并没有一个全局的时钟,node1,node2,node3 上面各有各的时钟,三个时钟无法完全对齐,虽然
时间误差可能在百万分之一或千万分之一。
所以对Paxos来首,它的一个关键特性是"乱序提交",也就是说在日志里面,请求1到请求6是没有时序的,只有多个node节点日志顺序一样。
即使对于单个客户端发送的请求,请求1和请求2也无法保证顺。即Paxos可能会在日志里面,把请求2存储在请求1的前面。要保证顺序,只能靠客户端保证,等
请求1返回之后,再发送请求2,这也就是同步发送,而不是异步发送。
这就是多点写入带来的问题,日志没有"时序"。而Raft和Zab都是单点写入,可以让日志有"时序"。
如有3个节点,node1是leader,所有client都把写请求发送给node1,再由node1同步给node2,node3。虽然3个客户端是并发发送的,但node1接收
肯定有先后顺序,node1一定可以对请求1,请求2,请求3排一个顺序。
这样一来,可以对6个请求按时间排一个顺序,这就是"逻辑时钟",6个请求的顺序如下:
term1,请求1;
term1,请求3;
term1,请求2;
term2,请求4;
term2,请求6;
term2,请求5;
日志有了时序的保证,就相当于在全局为每条日志做了顺序的编号。基于这个编号,就可以做日志的顺序提交,不同节点间的日志对比,回放日志的时候,也可以
按照编号从小到大回放。
在zab协议里面有一系列的名词,比如"原子广播","全序"。基于序的概念,可以保证下面几点:
1.如果日志a小于日志b,则所有节点一定先广播a,后广播b;
2.如果日志a小于日志b,则所有节点一定先Commita,后Commitb。这里的commit指的是Apply到状态机。
11.4.4 Leader选举:FLE算法
Zab 协议本身有4个阶段,但Zookeeper在实现过程中实际只有3个阶段。
Zab:
阶段1:Leader选举
阶段2:Discovery(发现)
阶段3:Synchornization
阶段4:Broadcast(广播)
Zookeeper:
阶段1:Leader选举
阶段2:恢复阶段
阶段3:Broadcast(广播)
zookeeper 的实现 和 raft 同样也是三个阶段,第三个阶段称为广播,也就是raft里面的复制。zab和raft一样,任何一个节点也有3个状态:leader,
follower和Election。Election 状态是中间状态,也被称作"Looking"状态,在Raft里面叫做 Candidate 状态,只是名字不同而已。
在初始化的时候,节点处于Election状态,然后开始发起选举,选举结束,处于leader或者follower状态。
在raft里面,leader和follower之间是单向心跳,只会是leader给follower发送心跳,但在zab里面是双向心跳,follower收不到leader的心跳,就
切换到election发起选举,反过来,leader收不到超过半数的follower心跳,也切换到election状态,重新发起选举,显然,raft实现比zab简单。
至于选举方式,raft选取日志最新的节点作为新的leader,zab的FLE(Fast Leader Election)算法也类似,选取zxid最大的节点作为leader。如果所有
节点的zxid相等,比如整个系统刚刚初始化的时候,所有节点zxid都为0,此时,将选取的节点编号最大的节点作为leader(zookeeper为每个节点配置一个编号)。
11.4.5 正常阶段:2阶段提交
leader 选举出来之后,接下来就是正常阶段:接收客户端的请求,然后复制到多数派,在zookeeper里面也变成2阶段提交。
阶段1:leader收到客户端的请求,先发送propose消息给所有的follower,收到超过半数的follower返回的ack消息;
阶段2:给所有节点发送commit消息。
这里有几个关键点说明:
1.commit是纯内存操作。这里说的commit指的是raft里面的Apply,apply到Zookeeper的状态机;
2.在阶段1,收到多数派的ack后,就表示返回给客户端成功了。而不是等多数派的节点收到commit,再返回给客户端;
3.Propose阶段有一次落盘操作,也就是生成一条Transaction日志,落盘,这与mysql的 Write-Ahead log 原理类似。
11.4.6 恢复阶段
在Raft里面恢复阶段很简单,新选出的leader发出一个空的AppendEntries RPC 请求,也就是复用了正常复制阶段的通信协议。
在zab里面用来专门的协议,但思路和Raft也类似,leader的日志不会动,follower要与leader的日志做对比,然后可能要进行日志截断,日志的补齐等操作。
恢复的算法和Raft的AppendEntries很类似,只是在Raft里面这些工作都由follower自己做了。而在这里,是leader把主要的工作做了,leader对比日志,
然后告诉follower做截断,补齐或者全量同步。
11.5 三种算法对比
关键点差异:
算法分类;复制模型;写入方式;同步方向;是否支持Primary Order;leader心跳检测方向;实现难度;
Multi-Paxos:
复制状态机;
多点写入,乱序提交;
节点之间双向同步;
否(但可以做);
选leader不是必须的,可以没有Leader;
最难;
Raft:
复制状态机;
单点写入,顺序提交;
单向,leader到follower;
否(但可以做);
单向: 只leader到follower发送心跳;
最简单;
Zab:
Primary-Backup;
单点写入,顺序提交;
单向:leader到follower;
支持;
双向:leader到follower之间互相发送心跳;
次之;
特别说明,Primary Order 也就是 FIFO Client Order,是zookeeper的一个关键特性。对于单个客户端来说,zookeeper使用tcp与服务器连接,可以保证
先发送的请求先被复制,先被apply;后发送的请求后被复制,后被apply。当然,客户端与客户端之间是并发的,不存在谁先谁后的问题,这里只是针对一个客户端的一个
tcp来说。
这个特性在客户端异步发送或者说pipeline的时候有用,也就是在这个tcp上,客户端没有等请求1返回就发送了请求2和请求3,zookeeper会保证请求1,请求2,
请求3按发送的顺序存储,复制,Apply。但用tcp的话,没有办法保证同一个客户端的多个tcp session保持 FIFO Order,如果要做这个就不能依赖tcp本身的机制,
而要自己在客户端对请求进行编号。
Multi-Paxos 算法本身没有保证 FIFO Client Order,即使同一个客户端发送的请求,在服务端也是并发复制的。但要限制并发复制,也可以做,比如客户端
可以同步发送,而不是异步发送,或者把多个请求打包成一个一次性发送,对应到服务器中是一条日志。同样,Raft算法也可以做到,不过没有做这个限制。