图论中的重要算法(Dijstra,Bellman-Ford,Floyd,Ford-Fulkerson,匈牙利算法)的详细解读及实现
Posted 卖寂寞的小男孩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图论中的重要算法(Dijstra,Bellman-Ford,Floyd,Ford-Fulkerson,匈牙利算法)的详细解读及实现相关的知识,希望对你有一定的参考价值。
文章目录

前言
生活中处处有图,最典型的就是地图了,我们需要了解到一个地方的最短距离或者最短时间是多少。还有比如自来水管道所构成的图,我们需要知道如何通水使水流量最大而不会使管道破裂。图论中的一些算法就是来解决这一类问题的,这些算法对人们生活生产的重要程度不只是在编程中体现的。
图中的最短路径
三种算法的适用条件
一般而言我们来求解一张图中节点之间的最短路径一共有三种算法:
1.Dijstra算法:适用于没有权值小于0的边的图。求两点间最短距离。
2.Bellan-Ford算法:无论权值大小为多少都适用,但其时间复杂度比Dijstra算法大,因此当边的权值均不小于0的时候,优先选择Dijstra算法。求两点间最短距离。
3.Floyd算法:可以求出任意两个顶点之间的最短距离,算法复杂度最大。
当图中有负圈时,算法均不适用,因为可以在负圈中无限缩小总的代价
求解最短路径问题的关键–松弛
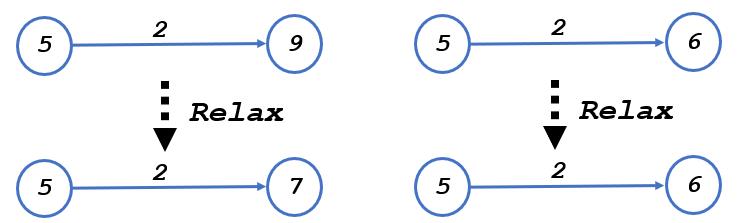
松弛的意思就是选择最短路径并进行节点的更新,每个节点的值为该节点到起始节点的距离。
左边的图,刚开始节点到起始节点的距离为9,发现另一个到起始节点距离为5的节点与该节点相连,且权值为2,则可以更新9为5+2=7
意思是该节点到起始节点的距离变短为7,然后可以继续更新,右边的图就不需要进行松弛操作因为5+2=7>6。
Dijstra算法
算法求解步骤
1.找到起始节点。
2.建立不含有起始节点的表格并初始化(初始化表示只走一条边的话,起始节点到各个节点的距离)。每个小格代表该节点到起始节点的距离。
3.每一次在表格中挑选最小的数并对其相连的数进行更新,此时该节点的值为其到起始节点的最小值,之后不能再发生变化(使用堆进行贪心选择)。
4.更新n-1次(n为节点个数,初始化也算一次更新)。
举例
图论的算法中是难以不靠例子来理解的。
给定下面这张图,使用dijstra来求解s到各个顶点的最小距离。
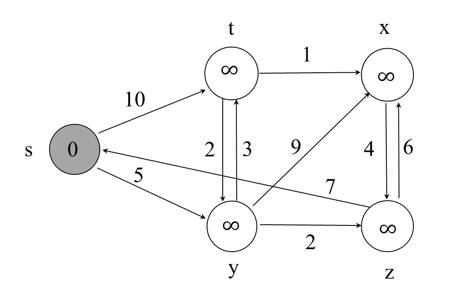
1.根据这张图我们来建立表格并对其进行初始化。
第一次更新
显然起始节点s到t的距离为10,到y的距离为5,经过一条路到达不了x和z,因此将x和z初始化为无穷。
| s->t | s->x | s->z | s->y |
|---|---|---|---|
| 10 | ∞ | ∞ | 5 |
2.找出权值的点进行固定并更新表格。
第二次更新
(1)找到了最小权值是5对应的是y,则起始点到y的最短距离即为5,表格中将y删去。
(2)根据最小值y来更新其他节点,根据y的意思就是经过y之后到达其他节点,与起始点在不经过y时到达其他节点进行比较,如果经过y节点之后比没经过y节点小,则更新节点的值为经过y到达该节点的值,否则不进行更新。
实际上这就是一个松弛的过程
从这张图来看,y到t的距离是3,s到y的距离是5,所以经过y,s到t的距离是3+5=8<10(10为s直接到y的距离),所以更新为8
同理y到x的距离是9,9+5=14<∞,所以更新为14,同理z的部分更新为7
更新的是y所以表格变成:
| s->y->t | s->y->x | s->y->z | s->y |
|---|---|---|---|
| 8 | 14 | 7 | 5 |
每一次更新都会固定一个节点,所以一共固定n-1个节点(因为要排除起始节点)
第三次更新
在这三个节点中选择最小的进行扩展,为7即z节点。同时删除表格中的z(我这里将数字进行了加粗)
z节点到x节点的距离为6,不会到达其他节点,则对x节点进行更新。
经过z节点(注意在此之前还经过了y节点)从起始到x的距离为:7+6=13<14所以进行更新
所以对表格进行更新之后变成:
| s->y->t | s->y->z->x | s->y->z | s->y |
|---|---|---|---|
| 8 | 13 | 7 | 5 |
第四次更新
此时找到两者之间的最小值也就是8,对应的节点为t,将t节点删除。
t到x的值为1,所以经过t到达x的距离为(到达t之前经过了y):1+8=9<13所以更新节点。
此时表格变成了:
| s->y->t | s->y->t->x | s->y->z | s->y |
|---|---|---|---|
| 8 | 9 | 7 | 5 |
此时不需要在进行更新表格,共更新了4次。
s到t的最短路径为:s->y->t,最短距离为:8
s到x的最短路径为:s->y->t->x,最短距离为:9
s到z的最短路径为:s->y->z,最短距离为:7
s到y的最短路径为:s->y,最短距离为5
综上,学会了表格更新就学会了dijstrsa算法
为什么有负边不能使用dijstra算法
其主要原因还是Dijstra的贪心选择性,每一次更新的时候都会选择最小的值,并使其对应的节点不再变化
举一个最简单的例子
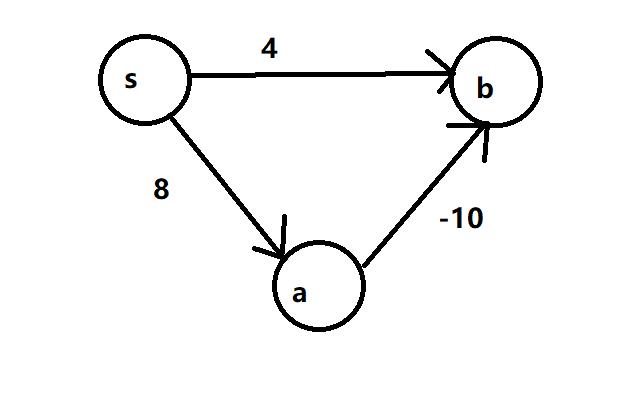
对于这样一张图来说,s到b的距离在第一次贪心选择的时候就已经确定了为4,但实际上其最小距离为-2。
自我检测判断一下会没会
下面在给一个例子,我只画每一个步骤的表格,可以自我测试一下:
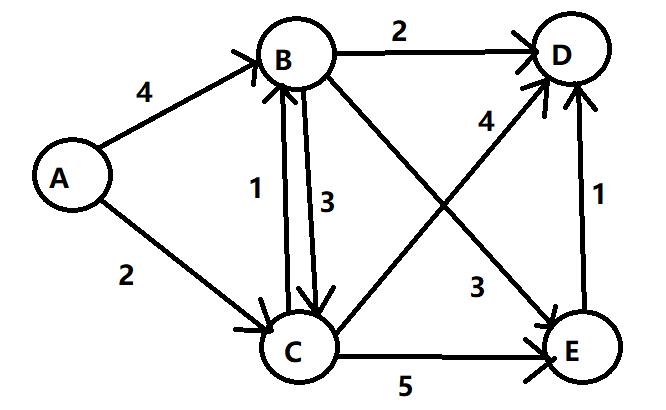
求A到各个点的最短路径:
共需要进行5-1=4次更新。
第一次(初始化)
| A->B | A->C | A->D | A->E |
|---|---|---|---|
| 4 | 2 | ∞ | ∞ |
第二次更新,选择的是C
| A->C->B | A->C | A->C->D | A->C->E |
|---|---|---|---|
| 3 | 2 | 6 | 7 |
第三次更新选择的是B
| A->C->B | A->C | A->C->B->D | A->C->B->E |
|---|---|---|---|
| 3 | 2 | 5 | 6 |
第四次更新,选择的是D,不发生变化
| A->C->B | A->C | A->C->B->D | A->C->B->E |
|---|---|---|---|
| 3 | 2 | 5 | 6 |
因此最终结果为:
A到B的最短路径为:A->C->B,最短长度为:3
A到C的最短路径为:A->C,最短长度为:2
A到D的最短路径为:A->C->B->D,最短长度为:5
A到E的最短路径为:A->C->B->E,最短长度为:6
算法的实现
由于建图太麻烦了我重点是说明算法是如何实现以及为什么可以实现的,所以我找到一个测试通过的版本。
void DijGraph::addEdge(int s, int e, int w)
if (s < v_count_ && e < v_count_)
adj_[s].emplace_back(s, e, w) ;
void DijGraph::dijkstra(int s, int e)
std::vector<int> parent(v_count_);
std::vector<Vertex> vertexes(v_count_);
for (int i = 0; i < v_count_; ++i)
vertexes[i] = Vertex(i, std::numeric_limits<int>::max());
struct cmp
bool operator() (const Vertex &v1, const Vertex &v2) return v1.dist_ > v2.dist_;
;
std::priority_queue<Vertex, std::vector<Vertex>, cmp> queue;
std::vector<bool> shortest(v_count_, false);
vertexes[s].dist_ = 0;
queue.push(vertexes[s]);
while (!queue.empty())
Vertex minVertex = queue.top();
queue.pop();
if (minVertex.id_ == e) break;
if (shortest[minVertex.id_]) continue;
shortest[minVertex.id_] = true;
for (int i = 0; i < adj_[minVertex.id_].size(); ++i)
Edge cur_edge = adj_[minVertex.id_].at(i);
int next_vid = cur_edge.eid_;
if (minVertex.dist_ + cur_edge.w_ < vertexes[next_vid].dist_)
vertexes[next_vid].dist_ = minVertex.dist_ + cur_edge.w_;
parent[next_vid] = minVertex.id_;
queue.push(vertexes[next_vid]);
std::cout << s;
print(s, e, parent);
Bellman-Ford算法
Bellman-Ford算法是Dijstra算法的起源地,Dijstra算法只是Bellman-Ford的算法的特殊情况,两者的实现过程大体相同。
求解步骤
1.找到起始节点。
2.建立不含有起始节点的表格并初始化(初始化表示只走一条边的话,起始节点到各个节点的距离)。每个小格代表该节点到起始节点的距离。
3.每一次将表格中所有的数据所相连的数进行更新,此时该节点的值为其到起始节点的最小值,之后不能再发生变化(使用堆进行贪心选择)。
4.更新n-1次(n为节点个数,初始化也算一次更新)。
两者的区别就在于黑体字的部分,Dijstra是选择最小的进行,而Bellman-Ford算法是选择所有的进行更新。就是这么简单~
来看一个具体的例子就明白了
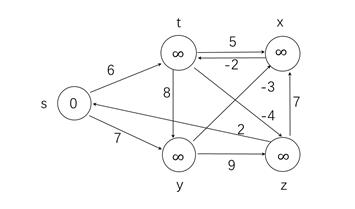
在这张图中找出s到t,x,y,z的最短路径和距离。
和Dijstra建立的表格和对数据处理的方式都一模一样,只是处理数据的个数发生了变化,这也是该算法可以处理负边的原因。
第一次更新(初始化)
| s->t | s->x | s->z | s->y |
|---|---|---|---|
| 10 | ∞ | ∞ | 5 |
第二次更新
在Dijstra算法中我们是选择最小权值5,进行之后的更新。
而在Bellman-Ford中,我们选择所有的节点,对其相连的节点进行更新。
首先从t开始,然后是x,然后是z,然后是y,这里对每个节点采取的操作和Dijstra对权值最小的节点进行的操作是相同的,我就不进行赘述了。
| s->t | s->y->x | s->t->z | s->y |
|---|---|---|---|
| 6 | 4 | 2 | 7 |
第二次同样按照t,x,z,y的顺序来进行,注意顺序不能乱
第三次更新
| s->y->x->t | s->y->x | s->t->z | s->y |
|---|---|---|---|
| 2 | 4 | 2 | 7 |
第四次更新
| s->y->x->t | s->y->x | s->y->x->t->z | s->y |
|---|---|---|---|
| 2 | 4 | -2 | 7 |
此时得到最终结果
s到t的最短路径为:s->y->x->t,最短距离为2
s到x的最短路径为:s->y->x,最短距离为4
s到z的最短路径为:s->y->x->t->z,最短距离为-2
s到y的最短路径为:s->y,最短距离为7
两种算法的关键区别就在于Dijstra是每次只对最小的节点进行操作,而Bellman-Ford是对所有节点进行操作
算法的实现
for (k = 1; k <= n - 1; k++)
for (i = 1; i <= m; i++)
if (dis[v[i]] > dis[u[i]] + w[i])
dis[v[i]] = dis[u[i]] + w[i];
Floyd算法
这个算法就比前两个算法更牛一点,可以计算出任意两点之间的最小距离。但是记录路径就比较麻烦了,需要记录每一次变换的下标。
算法步骤
1.建立一个矩阵来存储只经过一条边时,两点之间的距离。
2.记录经过某一个固定顶点后两点之间的距离。
3.共需要更新矩阵n次(n为节点个数)
举一个栗子
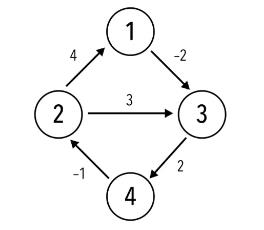
首先对矩阵进行初始化:
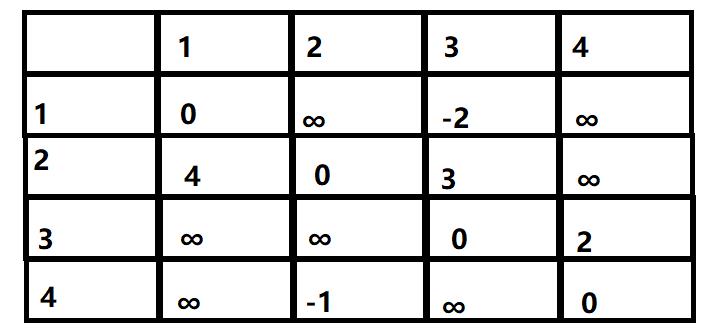
然后进行更新:第一次更新是更新所有经过1的节点,即先把第一行和第一列以及对角线划掉,剩下的元素是待更新的元素。
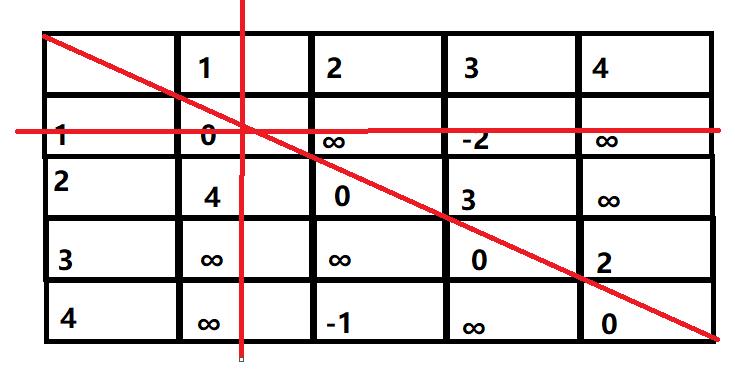
剩余的节点就是我们要更新的节点,比如更新节点[2,3],2经过1到达3的路径长短为4+(-2)=2<3,4与(-2)分别是两个划去的直线上的数字到该节点的正投影,所以将该位置的3更新为2,同理对其他几个位置进行更新。
第一次更新的结果为:
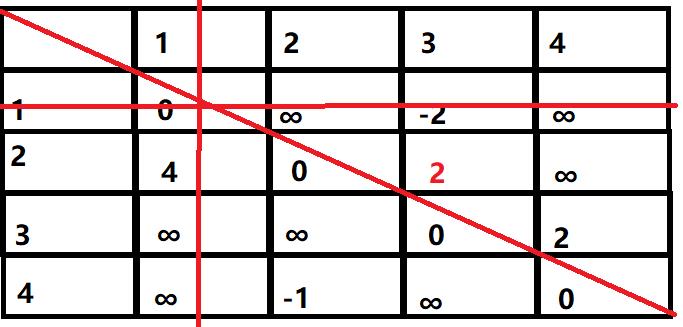
然后进行第二次更新,同理这次是对节点2的更新,首先划去节点2的行与列,然后更新节点的值:
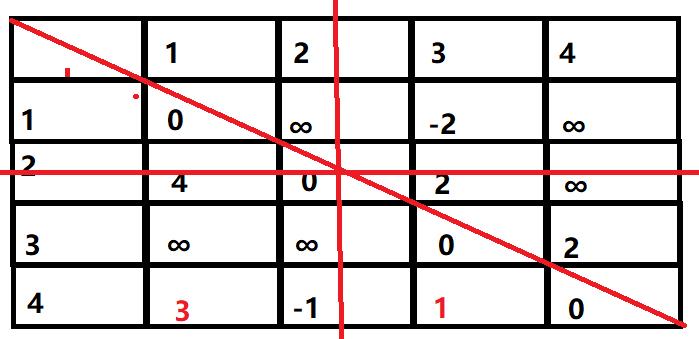
接着是第三次更新,得到这样的结果:
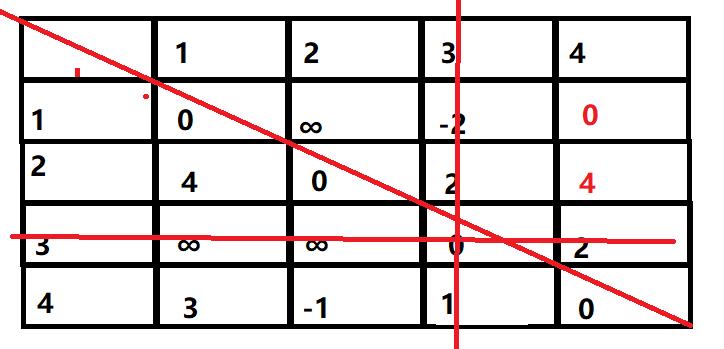
然后是最后一次更新:
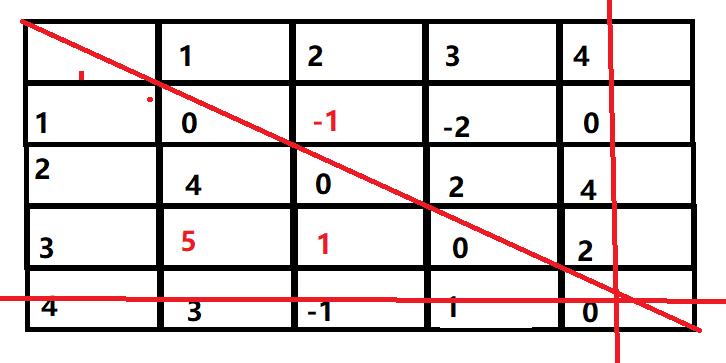
最终得到的结果为:
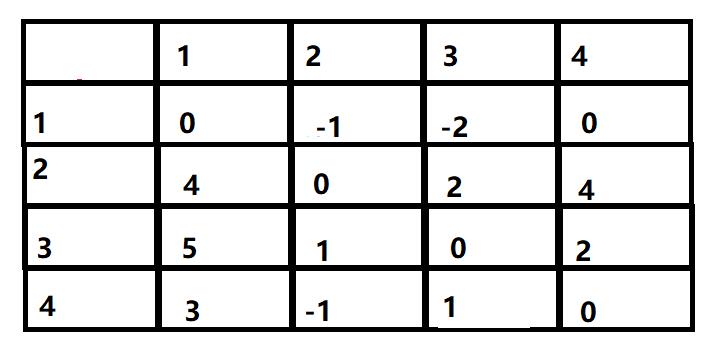
此矩阵即为最小代价矩阵。
即为所有点到点的最短距离,在进行矩阵计算的时候还可以建立一个矩阵来记录经过节点,从而计算出路径。
再来一道练练手
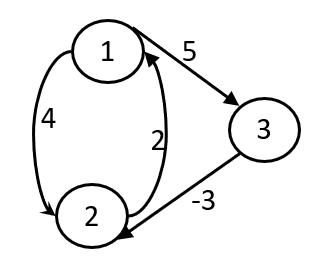
最终矩阵为:
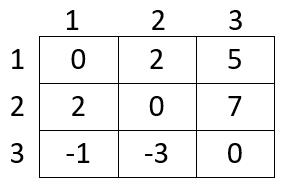
Floyd算法的实现
for (k = 1; k <= n; k++)
for (i = 1; i <= n; i++)
for (j = 1; j <= n; j++)
if (map[i][j] > map[i][k] + map[k][j])
map[i][j] = map[i][k] + map[k][j];
网络流问题
这里只介绍一种算法:
Ford-Fulkerson算法
这是一种通过余图来解决网络流问题的算法。
什么是网络流问题
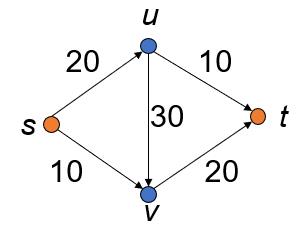
这是一个图,我们可以把每条边想象成管道,标的数字是管道的容量。
现在要对管道进行通水,水从s进入,从t排出,问最大的流量是多少,走的路线是怎样的。
为了解决这个问题我们引入了Ford-Fulkseron算法
算法步骤
1.找一条从起点到终点的路径,并向其中流入最大的水流。
2.将该路径翻转,并清除已经满的轨道。
3.重复这一过程,直到找不到一条从起点到终点路径。
具体过程演示
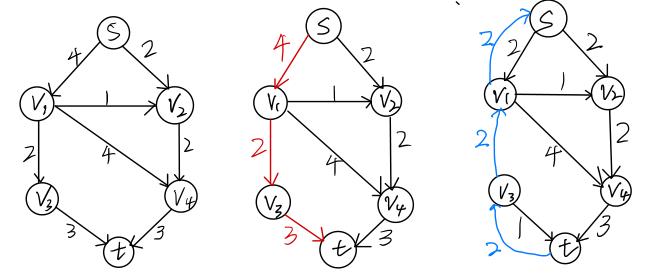
左图表示的是管道的最大流量,每条管道表示的意思是剩余管道空余量。
第二个图表示的是要选择的路径。
第三个图表示的是“余图”,先别管它到底叫啥,下面介绍它是怎么来的:
在第二个图中选择的是红色的那条路径,现向该路径进行通水流,所能流过的最大水流量是该路径管道上的最小容量,即为2。
首先先看黑线,它表示的是管道剩余量,当通水流为2的时候,最上方的那条管道的剩余量为:4-2=2,中间那条水流流满了,所以将该条管道删去,最下方的管道的剩余量为3-2=1,黑线旁边标注的就是剩余量,箭头方向不变。
然后看蓝色的部分,蓝色部分的数字代表的是通入水流的大小,只不过将方向反过来。
在进行下一次路径选择时,可以把它看做一条管道,管道的容量为其大小
下面画出接下来的操作:
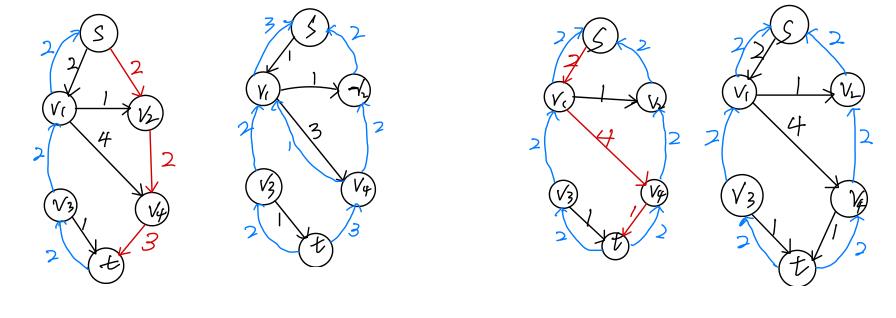
和第一次的操作是一样的,红线代表选择的路径,后面的图表示的是选择后的余图,这里又进行了两组操作。
直到发现不存在一条路径使得S可以到达t,此时删去蓝色的线。剩余的黑线表示的就是管道的剩余量,我们就可以画出水流图,并计算大小。
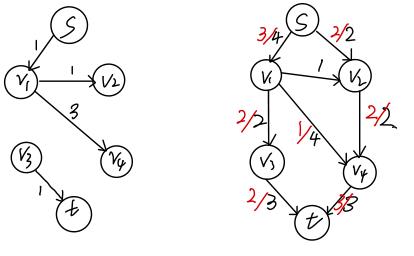
红色数字代表水流量,黑色数字代表管道容量。
代码实现
这里使用伪代码来实现。
Ford-Fulkerson
for <u,v> ∈ E
<u,v>.f = 0
while find a route from s to t in e
m = min(<u,v>.f, <u,v> ∈ route)
for <u,v> ∈ route
if <u,v> ∈ f
<u,v>.f = <u,v>.f + m
else
<v,u>.f = <v,u>.f - m
二分图最大最小匹配问题
这里暂时只介绍一个算法
匈牙利算法
什么是二分图
二分图又称作二部图,是图论中的一种特殊模型。 设G=(V,E)是一个无向图,如果顶点V可分割为两个互不相交的子集(A,B),并且图中的每条边(i,j)所关联的两个顶点i和j分别属于这两个不同的顶点集(i in A,j in B),则称图G为一个二分图。(这是百度百科定义的)大概意思就是将图的节点分为数量相等的两组,每组中的节点互不相连。
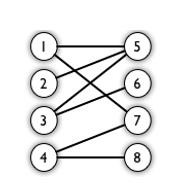
比如这样一张图就是一个二分图:
每一条边上都是带有权重的,我们需要找到一种匹配关系,使得匹配边的权重之和是最小的。
注意下面要讲解的是如何找到最小匹配问题,最大匹配问题只需要对其权值取反,操作步骤是相同的
假设二部图是这样的:
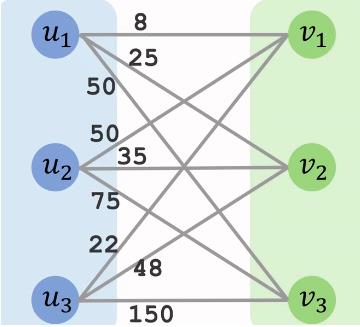
我们可以根据这张图来建立一个矩阵,横坐标为左图上的元素,纵坐标为右图上的元素,矩阵中的值代表权值。
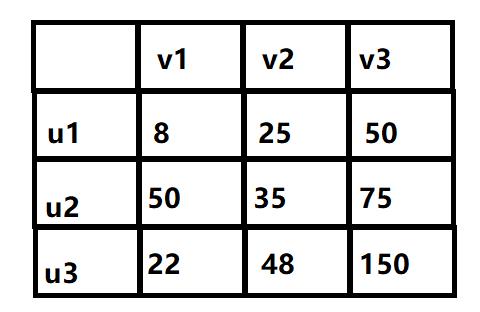
下面对每一行都减去它的最小值,然后对列减去它的最小值,保证每行每列都有0出现(和搜索中的旅行商挺像)。
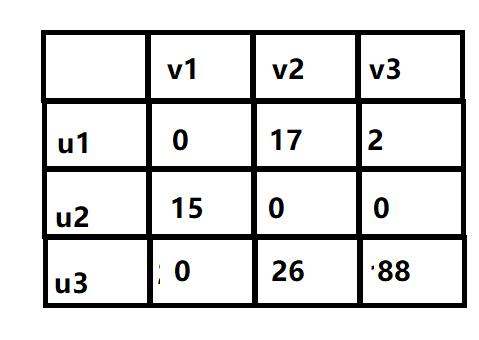
然后用尽量少的直线来覆盖所有的0,这张图中最少使用两条直线进行覆盖,将没被覆盖的所有值减去其中的最小值,然后重复这一过程。直到使用的直线条数与节点数是相等的时候停止覆盖。
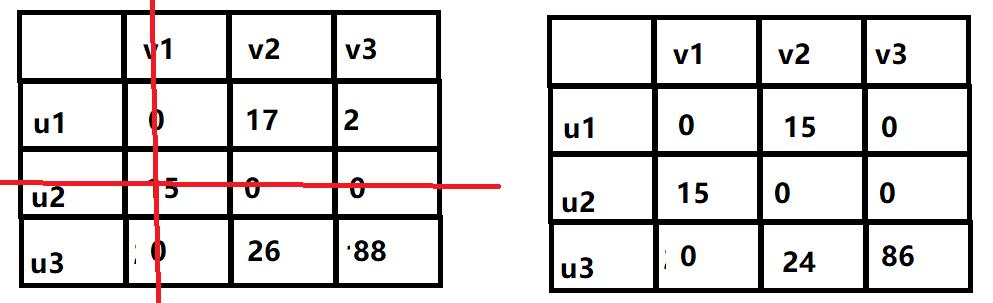
我们发现只需要两条边就可以覆盖所有的0密且2<3,所以将其余的节点减去其中的最小值,得到右图,继续用直线进行覆盖。
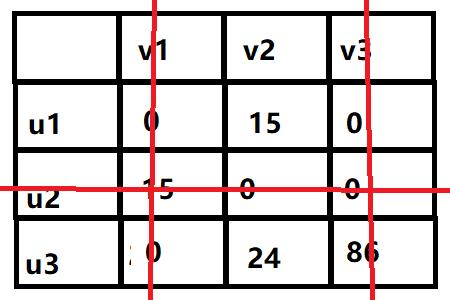
发现至少使用3条直线才能覆盖所有的0且3=3,算法停止。
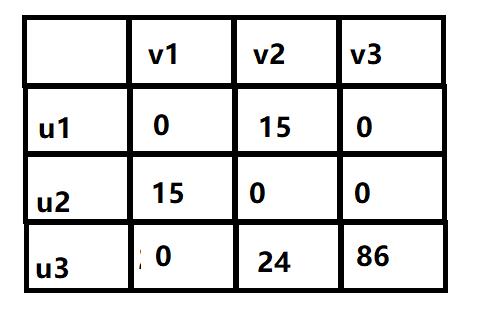
此时0代表匹配边,观察矩阵我们可以发现有些行或者列有多个0即有多个可能匹配边,所以先从只有一个0的开始选择。
此时发现u3只能匹配v1,则u1不能匹配v1了,所以u1匹配v3,同理u2匹配v2
所以最终的最小匹配图为:
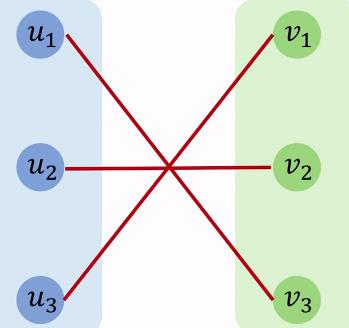
上图即为找到的最小匹配,最大匹配只需要将最小匹配所建立的矩阵的值取反即可,减去一个负数即可得到0。
总结
不知不觉又写了一万多字了,为啥写那些什么论文就没不知不觉过万字过(捂脸),这几个算法还是很重要的,在图的处理中占着重要的地位,我记得学C语言的时候曾经就为了Dijstra算法发愁过,不过我可以甩锅,因为学校老师只讲了算法,没讲本质。。。大家看完(如果你认真看了的话)觉得我讲的是不是很透彻啊,反正我自己觉得挺透彻的。
我总结了学习图论算法的几步:1,首先判断是个什么图,有向还是无向,有没有环。
2,根据边的性质,比如有没有负边呀,是管道还是匹配呀,来选择相应的算法
3,,,,,3连?
无论怎样都很感谢大家可以阅读到这里,如果你感觉文章有啥问题,欢迎给我留言啊。
以上是关于图论中的重要算法(Dijstra,Bellman-Ford,Floyd,Ford-Fulkerson,匈牙利算法)的详细解读及实现的主要内容,如果未能解决你的问题,请参考以下文章