ClickHouse vs StarRocks 选型对比
Posted dan20211
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse vs StarRocks 选型对比相关的知识,希望对你有一定的参考价值。
ClickHouse vs StarRocks 选型对比
面向列存的 DBMS 新的选择
Hadoop 从诞生已经十三年了,Hadoop 的供应商争先恐后的为 Hadoop 贡献各种开源插件,发明各种的解决方案技术栈,一方面确实帮助很多用户解决了问题,但另一方面因为繁杂的技术栈与高昂的维护成本,Hadoop 也渐渐地失去了原本属于他的市场。对于用户来说,一套高性能,简单化,可扩展的数据库产品能够帮助他们解决业务痛点问题。越来越多的人将目光锁定在列存的分布式数据库上。
ClickHouse 简介
ClickHouse 是由俄罗斯的第一大搜索引擎 Yandex 公司开源的列存数据库。令人惊喜的是,ClickHouse 相较于很多商业 MPP 数据库,比如 Vertica,InfiniDB 有着极大的性能提升。除了 Yandex 以外,越来越多的公司开始尝试使用 ClickHouse 等列存数据库。对于一般的分析业务,结构性较强且数据变更不频繁,可以考虑将需要进行关联的表打平成宽表,放入 ClickHouse 中。
相比传统的大数据解决方案,ClickHouse 有以下的优点:
- 配置丰富,只依赖与 Zookeeper
- 线性可扩展性,可以通过添加服务器扩展集群
- 容错性高,不同分片间采用异步多主复制
- 单表性能极佳,采用向量计算,支持采样和近似计算等优化手段
- 功能强大支持多种表引擎
StarRocks 简介
StarRocks 是一款极速全场景 MPP 企业级数据库产品,具备水平在线扩缩容,金融级高可用,兼容 mysql 协议和 MySQL 生态,提供全面向量化引擎与多种数据源联邦查询等重要特性。StarRocks 致力于在全场景 OLAP 业务上为用户提供统一的解决方案,适用于对性能,实时性,并发能力和灵活性有较高要求的各类应用场景。
相比于传统的大数据解决方案,StarRocks 有以下优点:
- 不依赖于大数据生态,同时外表的联邦查询可以兼容大数据生态
- 提供多种不同的模型,支持不同维度的数据建模
- 支持在线弹性扩缩容,可以自动负载均衡
- 支持高并发分析查询
- 实时性好,支持数据秒级写入
- 兼容 MySQL 5.7 协议和 MySQL 生态
StarRocks 与 ClickHouse 的功能对比
StarRocks 与 ClickHouse 有很多相似之处,比如说两者都可以提供极致的性能,也都不依赖于 Hadoop 生态,底层存储分片都提供了主主的复制高可用机制。但功能、性能与使用场景上也有差异。ClickHouse 在更适用与大宽表的场景,TP 的数据通过 CDC 工具的,可以考虑在 Flink 中将需要关联的表打平,以大宽表的形式写入 ClickHouse。StarRocks 对于 join 的能力更强,可以建立星型或者雪花模型应对维度数据的变更。
大宽表 vs 星型模型
ClickHouse:通过拼宽表避免聚合操作
不同于以点查为主的 TP 业务,在 AP 业务中,事实表和维度表的关联操作不可避免。ClickHouse 与 StarRocks 最大的区别就在于对于 join 的处理上。ClickHouse 虽然提供了 join 的语义,但使用上对大表关联的能力支撑较弱,复杂的关联查询经常会引起 OOM。一般我们可以考虑在 ETL 的过程中就将事实表与维度表打平成宽表,避免在 ClickHouse 中进行复杂的查询。
目前有很多业务使用宽表来解决多远分析的问题,说明了宽表确有其独到之处:
- 在 ETL 的过程中处理好宽表的字段,分析师无需关心底层的逻辑就可以实现数据的分析
- 宽表能够包含更多的业务数据,看起来更直观一些
- 宽表相当于单表查询,避免了多表之间的数据关联,性能更好
但同时,宽表在灵活性上也带来了一些困扰: - 宽表中的数据可能会因为 join 的过程中存在一对多的情况造成错误数据冗余
- 宽表的结构维护麻烦,遇到维度数据变更的情况需要重跑宽表
- 宽表需要根据业务预先定义,宽表可能无法满足临时新增的查询业务
StarRocks:通过星型模型适应维度变更
可以说,拼宽表的形式是以牺牲灵活性为代价,将 join 的操作前置,来加速业务的查询。但在一些灵活度要求较高的场景,比如订单的状态需要频繁改变,或者说业务人员的自助 BI 分析,宽表往往无法满足我们的需求。此时我们还需要使用更为灵活的星型或者雪花模型进行建模。对于星型/雪花模型的兼容度上,StarRocks 的支撑要比 ClickHouse 好很多。
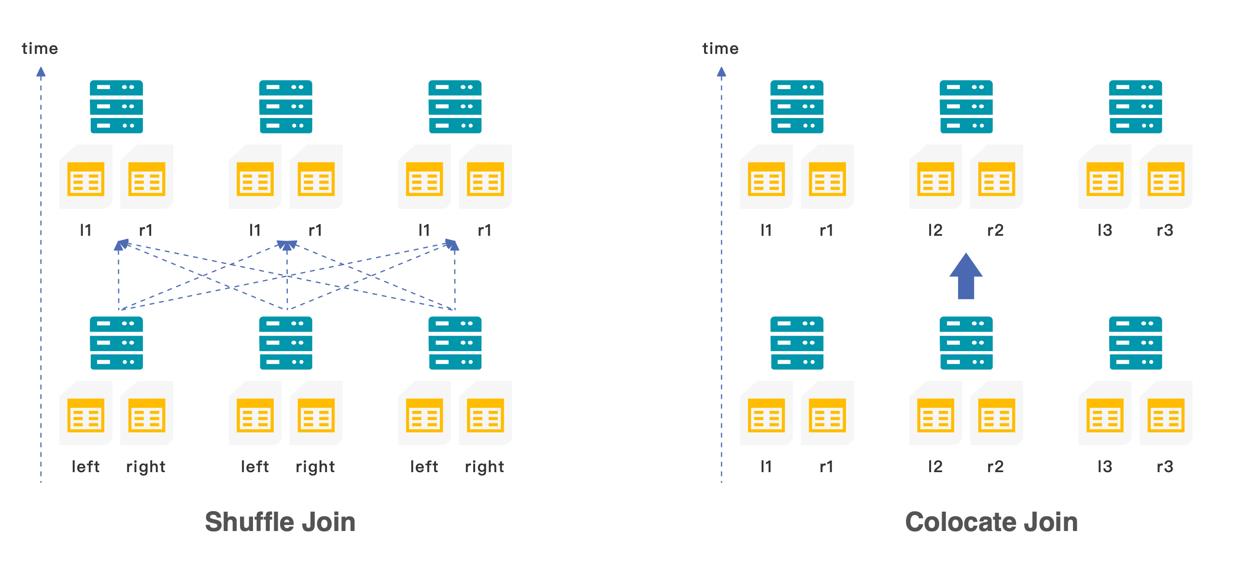
在 StarRocks 中提供了三种不同类型的 join:
- 当小表与大表关联时,可以使用 boardcast join,小表会以广播的形式加载到不同节点的内存中
- 当大表与大表关联式,可以使用 shuffle join,两张表值相同的数据会 shuffle 到相同的机器上
- 为了避免 shuffle 带来的网络与 I/O 的开销,也可以在创建表示就将需要关联的数据存储在同一个 colocation group 中,使用 colocation join
CREATE TABLE tbl (k1 int, v1 int sum)
DISTRIBUTED BY HASH(k1)
BUCKETS 8
PROPERTIES(
"colocate_with" = "group1"
);
目前大部分的 MPP 架构计算引擎,都采用基于规则的优化器(RBO)。为了更好的选择 join 的类型,StarRocks 提供了基于代价的优化器(CBO)。用户在开发业务 SQL 的时候,不需要考虑驱动表与被驱动表的顺序,也不需要考虑应该使用哪一种 join 的类型,CBO 会基于采集到的表的 metric,自动的进行查询重写,优化 join 的顺序与类型。
高并发支撑
ClickHouse 对高并发的支撑
为了更深维度的挖掘数据的价值,就需要引入更多的分析师从不同的维度进行数据勘察。更多的使用者同时也带来了更高的 QPS 要求。对于互联网,金融等行业,几万员工,几十万员工很常见,高峰时期并发量在几千也并不少见。随着互联网化和场景化的趋势,业务逐渐向以用户为中心转型,分析的重点也从原有的宏观分析变成了用户维度的细粒度分析。传统的 MPP 数据库由于所有的节点都要参与运算,所以一个集群的并发能力与一个节点的并发能力相差无几。如果一定要提高并发量,可以考虑增加副本数的方式,但同时也增加了 RPC 的交互,对性能和物理成本的影响巨大。
在 ClickHouse 中,我们一般不建议做高并发的业务查询,对于三副本的集群,通常会将 QPS 控制在 100 以下。ClickHouse 对高并发的业务并不友好,即使一个查询,也会用服务器一半的 CPU 去查询。一般来说,没有什么有效的手段可以直接提高 ClickHouse 的并发量,只能考虑通过将结果集写入 MySQL 中增加查询的并发度。
StarRocks 对高并发的支撑
相较于 ClickHouse,StarRocks 可以支撑数千用户同时进行分析查询,在部分场景下,高并发能力能够达到万级。StarRocks 在数据存储层,采用先分区再分桶的策略,增加了数据的指向性,利用前缀索引可以快读对数据进行过滤和查找,减少磁盘的 I/O 操作,提升查询性能。
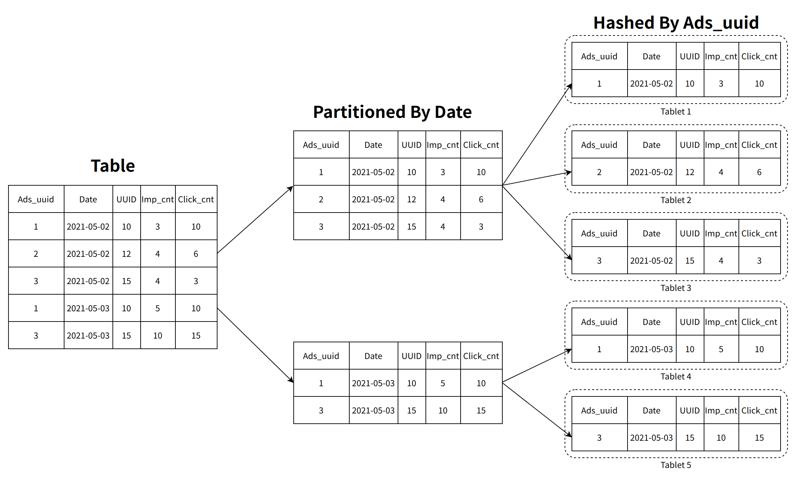
在建表的时候,分区分桶应该尽可能的覆盖到所带的查询语句,这样可以有效的利用分区分桶剪裁的功能,尽可能的减少数据的扫描量。此外,StarRocks 也提供了 MOLAP 库的预聚合能力。对于一些复杂的分析类查询,可以通过创建物化视图进行预先聚合,原有几十亿的基表,可以通过预聚合 RollUp 操作变成几百或者几千行的表,查询时延迟会有显著下降,并发也会有显著提升。
数据的高频变更
ClickHouse 中的数据更新
在 OLAP 数据库中,可变数据(Mutable data)通常是不受欢迎的。ClickHouse 也是如此。早期的版本中并不支持 UPDATE 和 DELETE 操作。在 1.15 版本后,Clickhouse 提供了 MUTATION 操作(通过 ALTER TABLE 语句)来实现数据的更新、删除,但这是一种“较重”的操作,它与标准 SQL 语法中的 UPDATE、DELETE 不同,是异步执行的,对于批量数据不频繁的更新或删除比较有用。除了 MUTATION 操作,Clickhouse 还可以通过 CollapsingMergeTree、VersionedCollapsingMergeTree、ReplacingMergeTree 结合具体业务数据结构来实现数据的更新、删除,这三种方式都通过 INSERT 语句插入最新的数据,新数据会“抵消”或“替换”掉老数据,但是“抵消”或“替换”都是发生在数据文件后台 Merge 时,也就是说,在 Merge 之前,新数据和老数据会同时存在。
针对与不同的业务场景,ClickHouse 提供了不同的业务引擎来进行数据变更。
对于离线业务,可以考虑增量和全量两种方案:
增量同步方案中,使用 ReplacingMergeTree 引擎,先用 Spark 将上游数据同步到 Hive,再由 Spark 消费 Hive 中的增量数据写入到 ClickHouse 中。由于只同步增量数据,对下游的压力较小。需要确保维度数据基本不变。
全量同步方案中,使用 MergeTree 引擎,通过 Spark 将上游数据定时同步到 Hive 中,truncate ClickHouse 中的表,随后使用 Spark 消费 Hive 近几天的数据一起写入到 ClickHouse 中。由于是全量数据导入,对下游压力较大,但无需考虑维度变化的问题。
对于实时业务,可以采用 VersionedCollapsingMergeTree 和 ReplacingMergeTree 两种引擎:
使用 VersionedCollapsingMergeTree 引擎,先通过 Spark 将上游数据一次性同步到 ClickHouse 中,在通过 Kafka 消费增量数据,实时同步到 ClickHouse 中。但因为引入了 MQ,需要保证 exectly once 语义,实时和离线数据连接点存在无法折叠现象。
使用 ReplacingMergeTree 引擎替换 VersionedCollapsingMergeTree 引擎,先通过 Spark 将上游存量数据一次性同步到 ClickHouse 中,在通过 MQ 将实时数据同步到 ReplacingMergeTree 引擎中,相比 VersionedCollapsingMergeTree 要更简单,且离线和实时数据连接点不存在异常。但此种方案无法保重没有重复数据。
StarRocks 中的数据更新
相较于 ClickHouse,StarRocks 对于数据更新的操作更加简单。
StarRocks 中提供了多种模型适配了更新操作,明细召回操作,聚合操作等业务需求。更新模型可以按照主键进行 UPDATE/DELETE 操作,通过存储和索引的优化可以在并发更新的同时高效的查询。在某些电商场景中,订单的状态需要频繁的更新,每天更新的订单量可能上亿。通过更新模型,可以很好的适配实时更新的需求。
| 特点 | 适用场景 | |
|---|---|---|
| 明细模型 | 用于保存和分析原始明细数据,以追加写为主要写入方式,数据写入后几乎无更新。 | 日志,操作记录,设备状态采样,时序类数据等 |
| 聚合模型 | 用于保存和分析汇总类(如:max、min、sum等)数据,不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新。 | 按时间、地域、机构汇总数据等 |
| Primary Key | 模型 支持基于主键的更新,delete-and-insert,大批量导入时保证高性能查询。用于保存和分析需要更新的数据。 | 状态会发生变动的订单,设备状态等 |
| Unique 模型 | 支持基于主键的更新,Merge On Read,更新频率比主键模型更高。用于保存和分析需要更新的数据。 | 状态会发生变动的订单,设备状态等 |
StarRocks 1.19 版本之前,可以使用 Unique 模型进行按主键的更新操作,Unique 模型使用的是 Merge-on-Read 策略,即在数据入库的时候会给每一个批次导入数据分配一个版本号,同一主键的数据可能有多个版本号,在查询的时候 StarRocks 会先做 merge 操作,返回一个版本号最新的数据。
自 StarRocks 1.19 版本之后发布了主键模型,能够通过主键进行更新和删除的操作,更友好的支持实时/频繁更新的需求。相较于 Unique 模型中 Merge-on-Read 的模式,主键模型中使用的是 Delete-and-Insert 的更新策略,性能会有三倍左右的提升。对于前端的 TP 库通过 CDC 实时同步到 StarRocks 的场景,建议使用主键模型。
集群的维护
相比于单实例的数据库,任何一款分布式数据库维护的成本都要成倍的增长。一方面是节点增多,发生故障的几率变高。对于这种情况,我们需要一套良好的自动 failover 机制。另一方便随着数据量的增长,要能做到在线弹性扩缩容,保证集群的稳定性与可用性。
###ClickHouse 中的节点扩容与重分布
与一般的分布式数据库或者 Hadoop 生态不同,HDFS 可以根据集群节点的增减自动的通过 balance 来调节数据均衡。但是 ClickHouse 集群不能自动感知集群拓扑的变化,所以就不能自动 balance 数据。当集群数据较大时,新增集群节点可能会给数据负载均衡带来极大的运维成本。
一般来说,新增集群节点我们通常有三种方案:
- 如果业务允许,可以给集群中的表设置 TTL,长时间保留的数据会逐渐被清理到,新增的数据会自动选择新节点,最后会达到负载均衡。
- 在集群中建立临时表,将原表中的数据复制到临时表,再删除原表。当数据量较大时,或者表的数量过多时,维护成本较高。同时无法应对实时数据变更。
- 通过配置权重的方式,将新写入的数据引导到新的节点。权重维护成本较高。
无论上述的哪一种方案,从时间成本,硬件资源,实时性等方面考虑,ClickHouse 都不是非常适合在线做节点扩缩容及数据充分布。同时,由于 ClickHouse 中无法做到自动探测节点拓扑变化,我们可能需要再 CMDB 中写入一套数据重分布的逻辑。所以我们需要尽可能的提前预估好数据量及节点的数量。
StarRocks 中的在线弹性扩缩容
与 HDFS 一样,当 StarRocks 集群感知到集群拓扑发生变化的时候,可以做到在线的弹性扩缩容。避免了增加节点对业务的侵入。
StarRocks 中的数据采用先分区再分桶的机制进行存储。数据分桶后,会根据分桶键做 hash 运算,结果一致的数据被划分到同一数据分片中,我们称之为 tablet。Tablet 是 StarRocks 中数据冗余的最小单位,通常我们会默认数据以三副本的形式存储,节点中通过 Quorum 协议进行复制。当某个节点发生宕机时,在其他可用的节点上会自动补齐丢失的 tablet,做到无感知的 failover。
在新增节点时,也会有 FE 自动的进行调度,将已有节点中的 tablet 自动的调度到扩容的节点上,做到自动的数据片均衡。为了避免 tablet 迁移时对业务的性能影响,可以尽量选择在业务低峰期进行节点的扩缩容,或者可以动态调整调度参数,通过参数控制 tablet 调度的速度,尽可能的减少对业务的影响。
ClickHouse 与 StarRocks 的性能对比
单表 SSB 性能测试
由于 ClickHouse join 能力有限,无法完成 TPCH 的测试,这里使用 SSB 100G 的单表进行测试。
测试环境
| 机器 | 配置 (阿里云主机 3 台) |
|---|---|
| CPU | 64 核 Intel® Xeon® Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| 内存 | 128G |
| 网络带宽 | 100G |
| 磁盘 | SSD 高效云盘 |
| ClickHouse 版本 | 21.9.5.16-2.x86_64 (18-Oct-2021) |
| StarRocks 版本 | v1.19.2 |
测试数据
| 表名 | 行数 | 说明 |
|---|---|---|
| lineorder | 6 亿 | SSB 商品订单表 |
| customer | 300 万 | SSB 客户表 |
| part | 140 万 | SSB 零部件表 |
| supplier | 20 万 | SSB 供应商表 |
| dates | 2556 | 日期表 |
| lineorder_flat | 6 亿 | SSB 打平后的宽表 |
测试结果
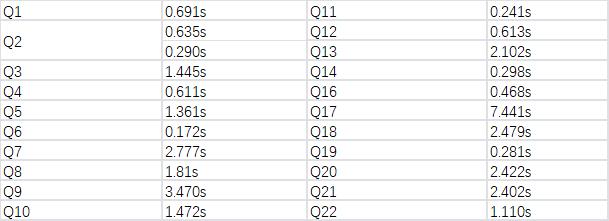
从测试结果中可以看出来,14 个测试中,有 9 个 SQL,StarRocks 在性能上要超过 ClickHouse。
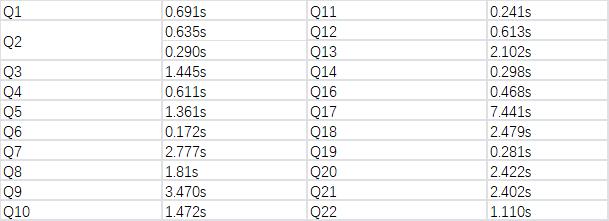
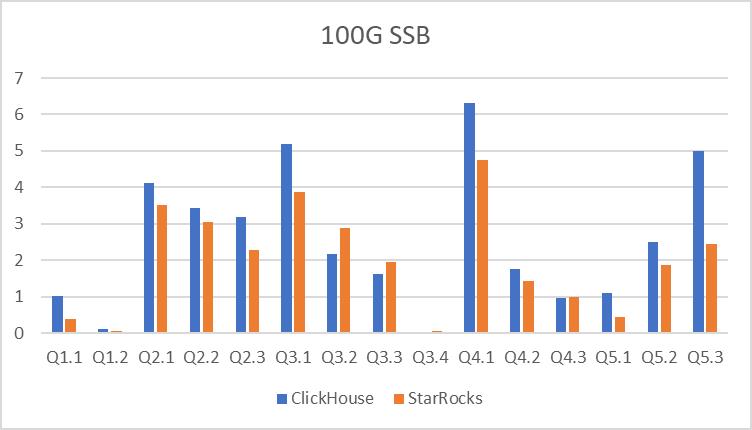
多表 TPCH 性能测试
ClickHouse 不擅长多表关联的场景,对于 TPCH 测试机,很多查询无法跑出,或者 OOM,目前只进行了 StarRocks 的 TPCH 测试。
测试环境
| 机器 | 配置 (阿里云主机 3 台) |
|---|---|
| CPU | 64 核 Intel® Xeon® Platinum 8269CY CPU @ 2.5GHz Cache Size: 36608 KB |
| 内存 | 128G |
| 网络带宽 | 100G |
| 磁盘 | SSD 高效云盘 |
| ClickHouse 版本 | 21.9.5.16-2.x86_64 (18-Oct-2021) |
| StarRocks 版本 | v1.19.2 |
测试数据
选用 TPCH 100G 测试集。
| 表名 | 行数 |
|---|---|
| customer | 15000000 |
| lineitem | 600037902 |
| nation | 25 |
| orders | 150000000 |
| part | 20000000 |
| partsupp | 80000000 |
| region | 5 |
| supplier | 1000000 |
测试结果
导入性能测试
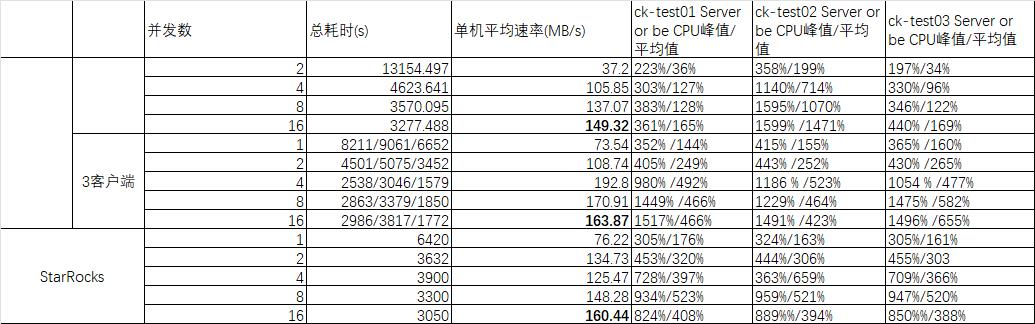
无论是 ClickHouse 还是 StarRocks,我们都可以使用 DataX 进行全量数据的导入,增量部分通过 CDC 工具写入到 MQ 中在经过下游数据库消费即可。
数据集
导入测试选取了 ClickHouse Native Format 数据集。1 个 xz 格式压缩文件大概 85GB 左右,解压后原始文件 1.4T,31 亿条数据,文件格式为 CSV
导入方式
ClickHouse 中采用的 HDFS 外表的形式。ClickHouse 中分布式表只能选择一个 integer 列作为 Sharding Key,观察数据发现技术都很低,因此使用 rand() 分布形式。
CREATE TABLE github_events_all AS github_events_local \\
ENGINE = Distributed( \\
perftest_3shards_1replicas, \\
github, \\
github_events_local, \\
rand());
HDFS 外表定义如下:
CREATE TABLE github_events_hdfs
(
file_time DateTime,
event_type Enum('CommitCommentEvent' = 1, 'CreateEvent' = 2, 'DeleteEvent' = 3, 'ForkEvent' = 4,
'GollumEvent' = 5, 'IssueCommentEvent' = 6, 'IssuesEvent' = 7, 'MemberEvent' = 8,
'PublicEvent' = 9, 'PullRequestEvent' = 10, 'PullRequestReviewCommentEvent' = 11,
'PushEvent' = 12, 'ReleaseEvent' = 13, 'SponsorshipEvent' = 14, 'WatchEvent' = 15,
'GistEvent' = 16, 'FollowEvent' = 17, 'DownloadEvent' = 18, 'PullRequestReviewEvent' = 19,
'ForkApplyEvent' = 20, 'Event' = 21, 'TeamAddEvent' = 22),
actor_login LowCardinality(String),
repo_name LowCardinality(String),
created_at DateTime,
updated_at DateTime,
action Enum('none' = 0, 'created' = 1, 'added' = 2, 'edited' = 3, 'deleted' = 4, 'opened' = 5, 'closed' = 6, 'reopened' = 7, 'assigned' = 8, 'unassigned' = 9,
'labeled' = 10, 'unlabeled' = 11, 'review_requested' = 12, 'review_request_removed' = 13, 'synchronize' = 14, 'started' = 15, 'published' = 16, 'update' = 17, 'create' = 18, 'fork' = 19, 'merged' = 20),
comment_id UInt64,
body String,
path String,
position Int32,
line Int32,
ref LowCardinality(String),
ref_type Enum('none' = 0, 'branch' = 1, 'tag' = 2, 'repository' = 3, 'unknown' = 4),
creator_user_login LowCardinality(String),
number UInt32,
title String,
labels Array(LowCardinality(String)),
state Enum('none' = 0, 'open' = 1, 'closed' = 2),
locked UInt8,
assignee LowCardinality(String),
assignees Array(LowCardinality(String)),
comments UInt32,
author_association Enum('NONE' = 0, 'CONTRIBUTOR' = 1, 'OWNER' = 2, 'COLLABORATOR' = 3, 'MEMBER' = 4, 'MANNEQUIN' = 5),
closed_at DateTime,
merged_at DateTime,
merge_commit_sha String,
requested_reviewers Array(LowCardinality(String)),
requested_teams Array(LowCardinality(String)),
head_ref LowCardinality(String),
head_sha String,
base_ref LowCardinality(String),
base_sha String,
merged UInt8,
mergeable UInt8,
rebaseable UInt8,
mergeable_state Enum('unknown' = 0, 'dirty' = 1, 'clean' = 2, 'unstable' = 3, 'draft' = 4),
merged_by LowCardinality(String),
review_comments UInt32,
maintainer_can_modify UInt8,
commits UInt32,
additions UInt32,
deletions UInt32,
changed_files UInt32,
diff_hunk String,
original_position UInt32,
commit_id String,
original_commit_id String,
push_size UInt32,
push_distinct_size UInt32,
member_login LowCardinality(String),
release_tag_name String,
release_name String,
review_state Enum('none' = 0, 'approved' = 1, 'changes_requested' = 2, 'commented' = 3, 'dismissed' = 4, 'pending' = 5)
)
ENGINE = HDFS('hdfs://XXXXXXXXXX:9000/user/stephen/data/github-02/*', 'TSV')
在 StarRocks 中,采用 Broker Load 的模式进行导入,导入命令如下:
LOAD LABEL github.xxzddszxxzz (
DATA INFILE("hdfs://XXXXXXXXXX:9000/user/stephen/data/github/*")
INTO TABLE `github_events`
(event_type,repo_name,created_at,file_time,actor_login,updated_at,action,comment_id,body,path,position,line,ref,ref_type,creator_user_login,number,title,labels,state,locked,assignee,assignees,comments,author_association,closed_at,merged_at,merge_commit_sha,requested_reviewers,requested_teams,head_ref,head_sha,base_ref,base_sha,merged,mergeable,rebaseable,mergeable_state,merged_by,review_comments,maintainer_can_modify,commits,additions,deletions,changed_files,diff_hunk,original_position,commit_id,original_commit_id,push_size,push_distinct_size,member_login,release_tag_name,release_name,review_state)
)
WITH BROKER oss_broker1 ("username"="user", "password"="password")
PROPERTIES
(
"max_filter_ratio" = "0.1"
);
导入结果
可以看出,在使用 github 数据集进行导入的时候,基本上 StarRocks 和 ClickHouse 导入的性能相差不多。
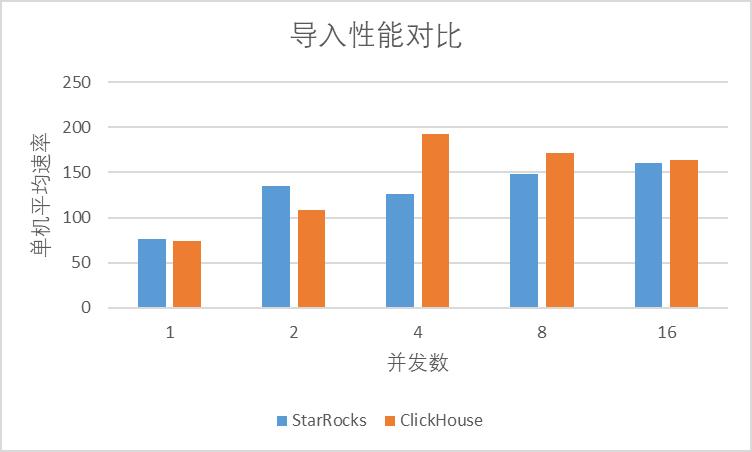
结论
ClickHouse 与 StarRocks 都是很优秀的关系新 OLAP 数据库。两者有着很多的相似之处,对于分析类查询都提供了极致的性能,都不依赖于 Hadoop 生态圈。从本次的选型对比中,可以看出在一些场景下,StarRocks 相较于 ClickHouse 有更好的表现。一般来说,ClickHouse 适合于维度变化较少的拼宽表的场景,StarRocks 不仅在单表的测试中有着更出色的表现,在多表关联的场景具有更大的优势。
以上是关于ClickHouse vs StarRocks 选型对比的主要内容,如果未能解决你的问题,请参考以下文章