MongoDB详解,用心看这篇就够了重点
Posted sunnyday0426
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MongoDB详解,用心看这篇就够了重点相关的知识,希望对你有一定的参考价值。
1.1 MongoDB概述
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是它支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB服务端可运行在Linux、Windows平台,支持32位和64位应用,默认端口为27017。
推荐运行在64位平台,因为MongoDB在32位模式运行时支持的最大文件尺寸为2GB。
1.2 MongoDB主要特点
1.2.1 文档
MongoDB中的记录是一个文档,它是由字段和值对组成的数据结构。
多个键及其关联的值有序地放在一起就构成了文档。
MongoDB文档类似于JSON对象。字段的值可以包括其他文档,数组和文档数组。

“greeting”:“hello,world”这个文档只有一个键“greeting”,对应的值为“hello,world”。多数情况下,文档比这个更复杂,它包含多个键/值对。
例如:“greeting”:“hello,world”,“foo”: 3 文档中的键/值对是有序的,下面的文档与上面的文档是完全不同的两个文档。“foo”: 3 ,“greeting”:“hello,world”
文档中的值不仅可以是双引号中的字符串,也可以是其他的数据类型,例如,整型、布尔型等,也可以是另外一个文档,即文档可以嵌套。文档中的键类型只能是字符串。
使用文档的优点是:
- 文档(即对象)对应于许多编程语言中的本机数据类型
- 嵌入式文档和数组减少了对昂贵连接的需求
- 动态模式支持流畅的多态性
1.3.2 集合
集合就是一组文档,类似于关系数据库中的表。
集合是无模式的,集合中的文档可以是各式各样的。例如,“hello,word”:“Mike”和“foo”: 3,它们的键不同,值的类型也不同,但是它们可以存放在同一个集合中,也就是不同模式的文档都可以放在同一个集合中。
既然集合中可以存放任何类型的文档,那么为什么还需要使用多个集合?
这是因为所有文档都放在同一个集合中,无论对于开发者还是管理员,都很难对集合进行管理,而且这种情形下,对集合的查询等操作效率都不高。所以在实际使用中,往往将文档分类存放在不同的集合中。
例如,对于网站的日志记录,可以根据日志的级别进行存储,Info级别日志存放在Info 集合中,Debug 级别日志存放在Debug 集合中,这样既方便了管理,也提供了查询性能。
但是需要注意的是,这种对文档进行划分来分别存储并不是MongoDB 的强制要求,用户可以灵活选择。
可以使用“.”按照命名空间将集合划分为子集合。
例如,对于一个博客系统,可能包括blog.user和blog.article两个子集合,这样划分只是让组织结构更好一些,blog集合和blog.user、blog.article没有任何关系。虽然子集合没有任何特殊的地方,但是使用子集合组织数据结构清晰,这也是MongoDB推荐的方法。
1.3.3 数据库
MongoDB 中多个文档组成集合,多个集合组成数据库。
一个MongoDB实例可以承载多个数据库。它们之间可以看作相互独立,每个数据库都有独立的权限控制。在磁盘上,不同的数据库存放在不同的文件中。
MongoDB中存在以下系统数据库。
Admin数据库:一个权限数据库,如果创建用户的时候将该用户添加到admin数据库中,那么该用户就自动继承了所有数据库的权限。Local数据库:这个数据库永远不会被复制,可以用来存储本地单台服务器的任意集合。Config数据库:当MongoDB使用分片模式时,config数据库在内部使用,用于保存分片的信息。
1.3.4 数据模型
一个MongoDB实例可以包含一组数据库,一个DataBase可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。
一个Document包含一组field(字段),每一个字段都是一个key/value pair
key: 必须为字符串类型value:可以包含如下类型- 基本类型,例如,
string,int,float,timestamp,binary等类型 - 一个
document - 数组类型
- 基本类型,例如,
1.4 Windows安装MongoDB
1.4.1 下载MongoDB
MongoDB提供了可用于32位系统和64位系统的预编译二进制包(新版本没有了32位系统的安装文件),你可以进入MongoDB官网下载安装,MongoDB的预编译二进制包的下载地址为:https://www.mongodb.com/download-center/community,打开之后会看到如下图,直接点击Download下载即可,也可以在Version中选择你想要的版本:
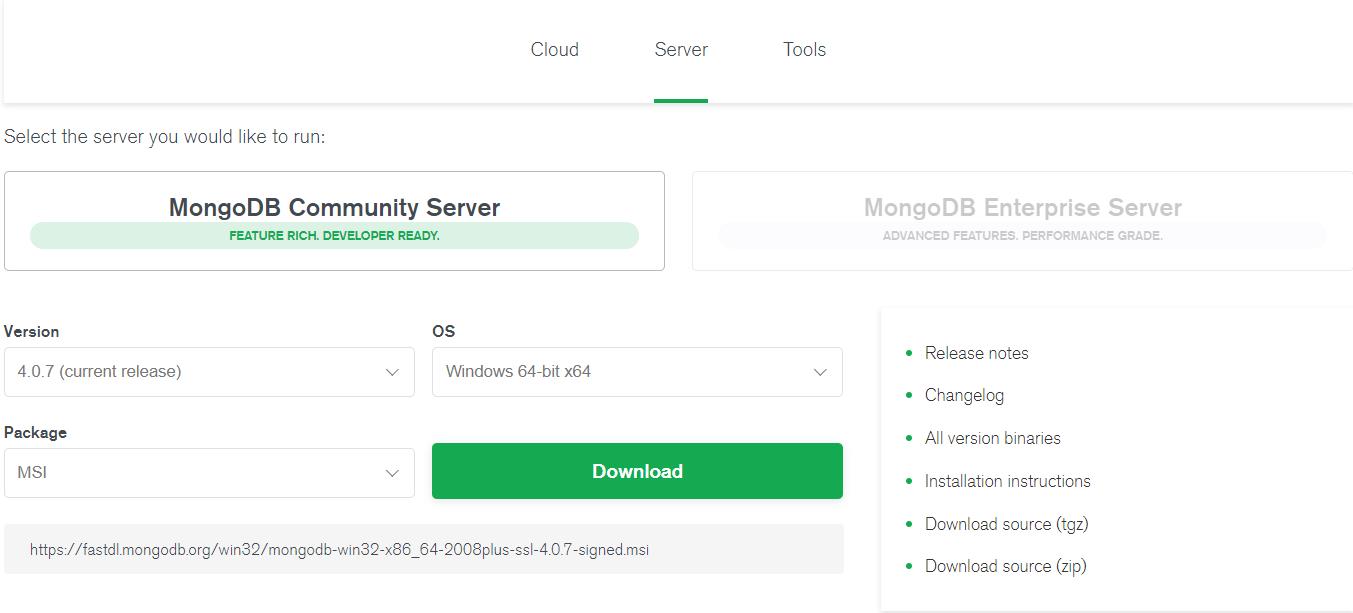
1.4.2 安装MongoDB
双击打开文件进行安装,在安装过程中,可以通过点击 “Custom(自定义)” 按钮来设置你的安装目录。
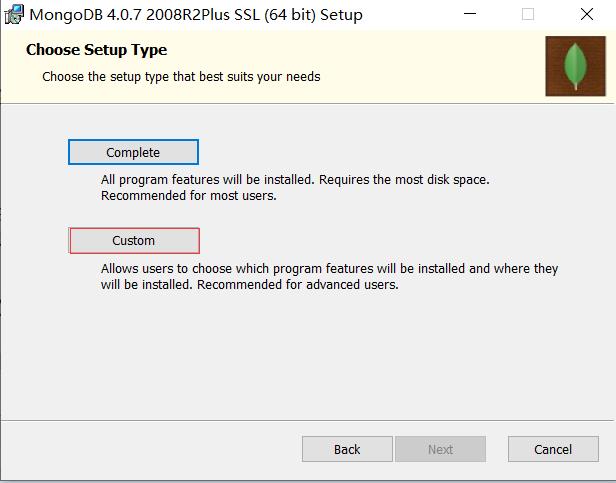
这里我选择安装在E:\\MongoDB这个目录下(安装目录会影响我们后面的配置)
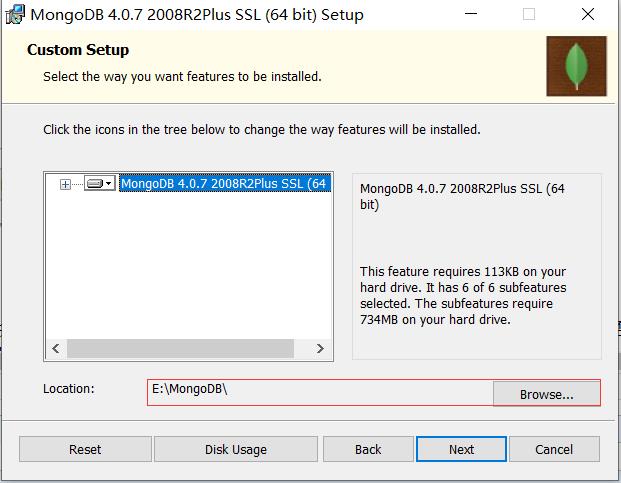
这里选择直接next
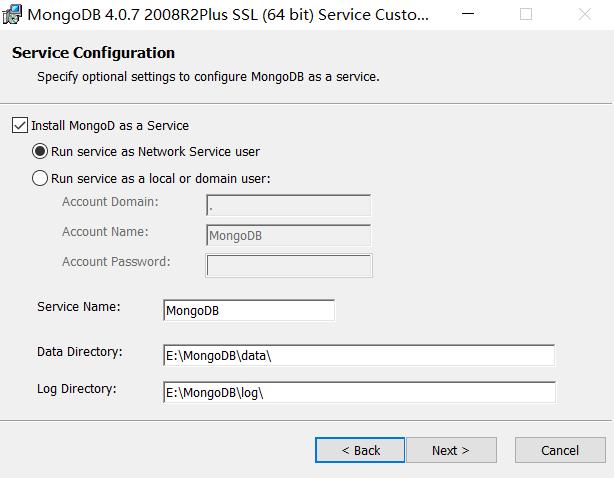
这里安装 "Install MongoDB Compass"不勾选,否则可能要很长时间都一直在执行安装,MongoDB Compass是一个图形界面管理工具,这里不安装也是没有问题的,可以自己去下载一个图形界面管理工具,比如Robo3T。
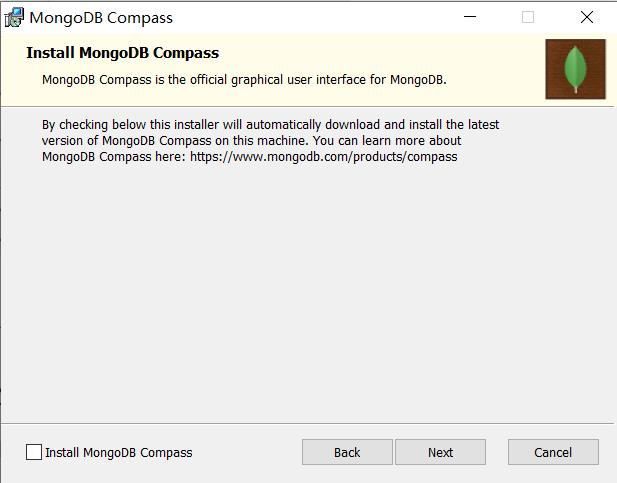
之后稍微等待一会就安装好了。
1.4.3 配置MongoDB
MongoDB的安装过程是很简单的,但是配置就比较麻烦了,可能会遇到各种各样的问题,需要你有足够的耐心和仔细。
首先要在MongoDB的data文件夹里新建一个db文件夹和一个log文件夹:
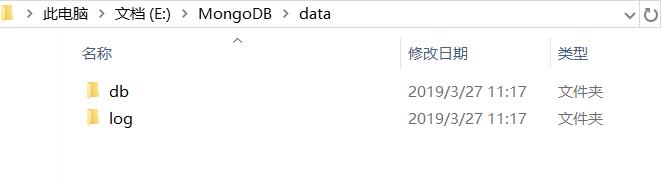
然后在log文件夹下新建一个mongo.log:
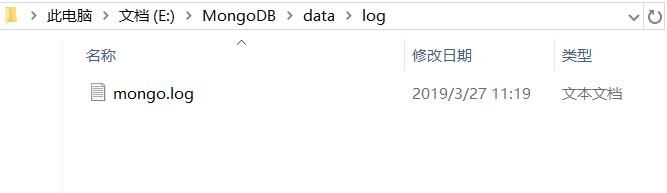
然后将E:\\MongoDB\\bin添加到环境变量path中,此时打开cmd窗口运行一下mongo命令,出现如下情况:

这是为什么呢?这是因为我们还没有启动MongoDB服务,自然也就连接不上服务了。那要怎么启动呢?在cmd窗口中运行如下命令:
mongod --dbpath E:\\MongoDB\\data\\db
需要注意的是:如果你没有提前创建db文件夹,是无法启动成功的。运行成功之后,我们打开浏览器,输入127.0.0.1:27017,看到如下图,就说明MongoDB服务已经成功启动了。

但是如果每次都要这么启动服务的话也太麻烦了吧,这里你可以选择设置成开机自启动,也可以选择用命令net start mongodb来手动启动,这里我选择使用后者,具体方法如下。
还是打开cmd窗口,不过这次是以管理员身份运行,然后输入如下命令:
mongod --dbpath "E:\\MongoDB\\data\\db" --logpath "E:\\MongoDB\\data\\log\\mongo.log" -install -serviceName "MongoDB"
如果没有报错的话就说明成功添加到服务里了,可以使用win+R然后输入services.msc命令进行查看:
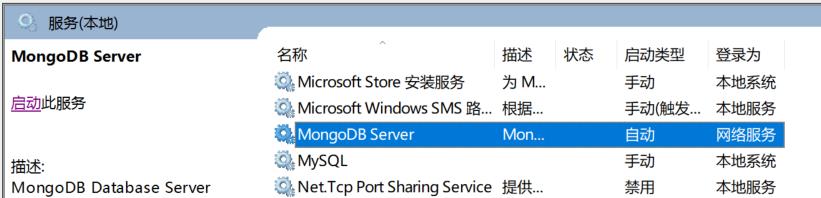
默认是自动运行的,这里我选择把它改成手动的。然后在cmd窗口中运行net start mongodb:

怎么解决呢?两个步骤:
1)运行sc delete mongodb删除服务;
2)再运行一次配置服务的命令:
mongod --dbpath "E:\\MongoDB\\data\\db" --logpath "E:\\MongoDB\\data\\log\\mongo.log" -install -serviceName "MongoDB"
然后再运行net start mongodb,服务启动成功:

可能遇到的问题:
1、mongod不是内部或外部命令
出现这种问题说明你没有把bin目录添加到环境变量之中,重新添加一下即可解决。
2、服务名无效
首先是看你输入的服务名称是否有误,然后再查看本地服务中有没有MongoDB服务,如果没有服务,则运行命令添加服务即可。
3、发生服务特定错误:100
删除db文件夹下的mongod.lock和storage.bson两个文件,若删除完之后仍然出现这种问题,用sc delete mongodb删除服务,再配置一下服务就能解决了。
1.4.4 安装一个可视化工具
官网下载 RoBo 3T(Robomongo is now Robo 3T)
下载地址:https://robomongo.org/download
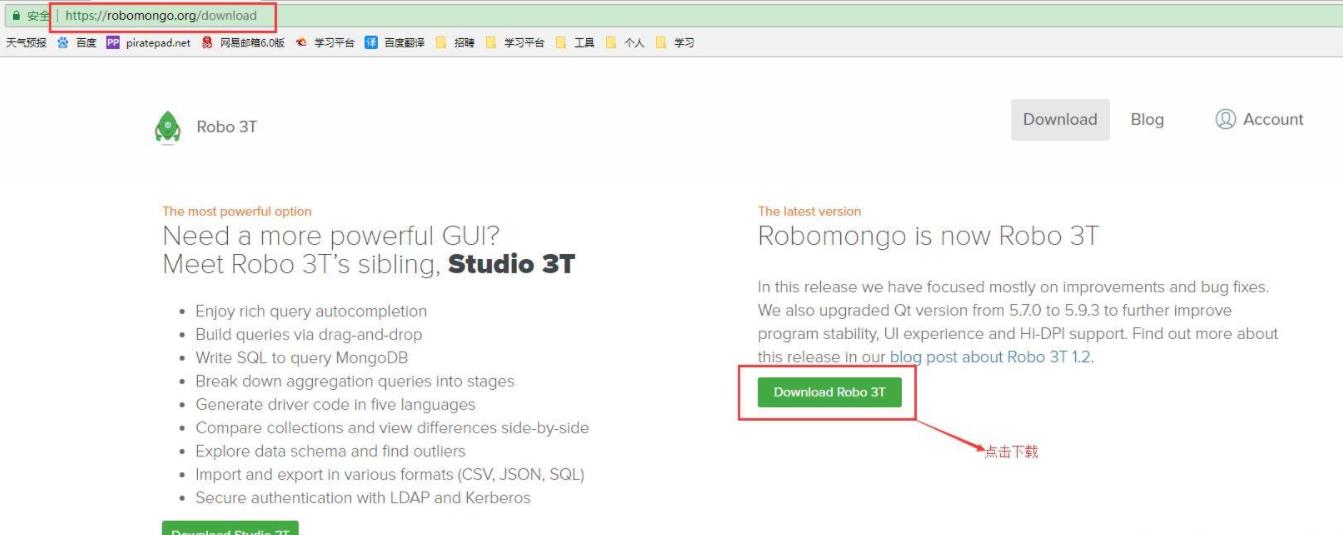
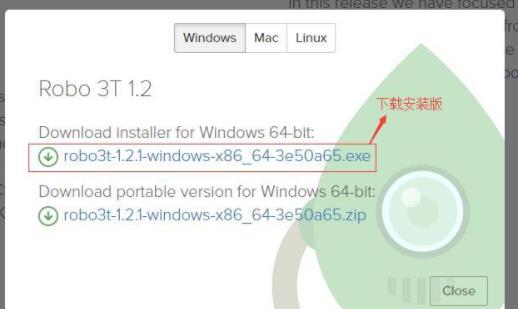
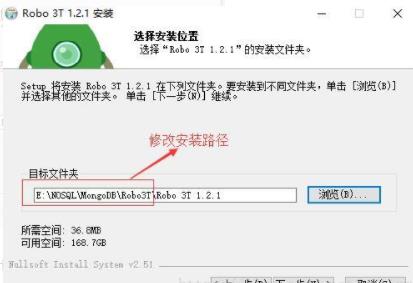
双击安装包安装,修改安装路径,不停下一步,点击安装。
打开后,有一个填信息的页面,name、email,暂时不用管,直接finish。
启动MongoDB服务。
点击弹出框中的create,创建新连接,可以修改连接名name,连接IP(下图IP为本地IP),端口(默认)
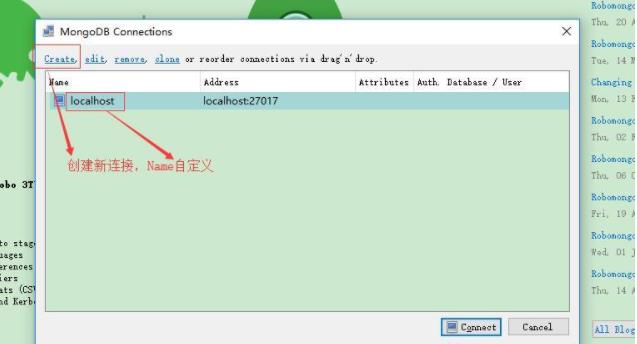
连接成功后,右击localhost,选择create Database,创建数据库
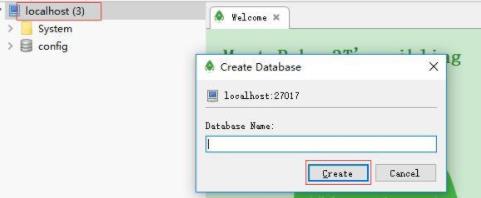
创建数据库firstTest,然后右击firstTest,选择open Shell,开始进行shell命令来创建数据库中的集合和文档。
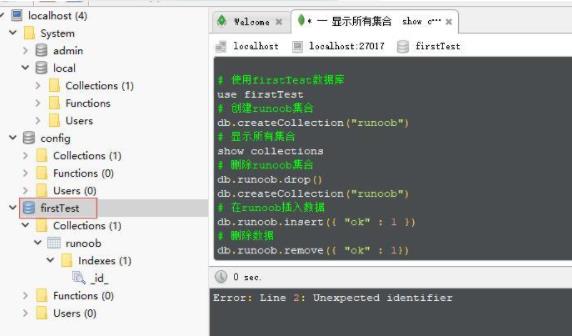
1.5 Linux安装MongoDB
1.5.1 下载MongoDB
官方下载地址:https://www.mongodb.com/download-center/community
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.1.tgz
1.5.2 解压安装
1、解压
tar -zxvf mongodb-linux-x86_64-rhel70-4.2.1.tgz
2、创建目录/usr/local/mongo,并将解压完的mongodb目录移动到/usr/local/mongo下
mkdir -p /usr/local/mongo
mv mongodb-linux-x86_64-rhel70-4.2.1/* /usr/local/mongo/
3、切到/usr/local/mongo目录下,创建目录
mkdir -p data/db #数据库目录
mkdir -p logs #日志目录
mkdir -p conf #配置文件目录
mkdir -p pids #进程描述文件目录
创建好的目录如下:
4、在conf目录,增加配置文件mongo.conf
vi /usr/local/mongo/conf/mongo.conf
#数据保存路径
dbpath=/usr/local/mongo/data/db/
#日志保存路径
logpath=/usr/local/mongo/logs/mongo.log
#进程描述文件
pidfilepath=/usr/local/mongo/pids/mongo.pid
#日志追加写入
logappend=true
bind_ip_all=true
#mongo默认端口
port=27017
#操作日志容量
oplogSize=10000
#开启子进程
fork=true
5、通过配置文件启动mongo服务端
/usr/local/mongo/bin/mongod -f /usr/local/mongo/conf/mongo.conf
启动成功如下:

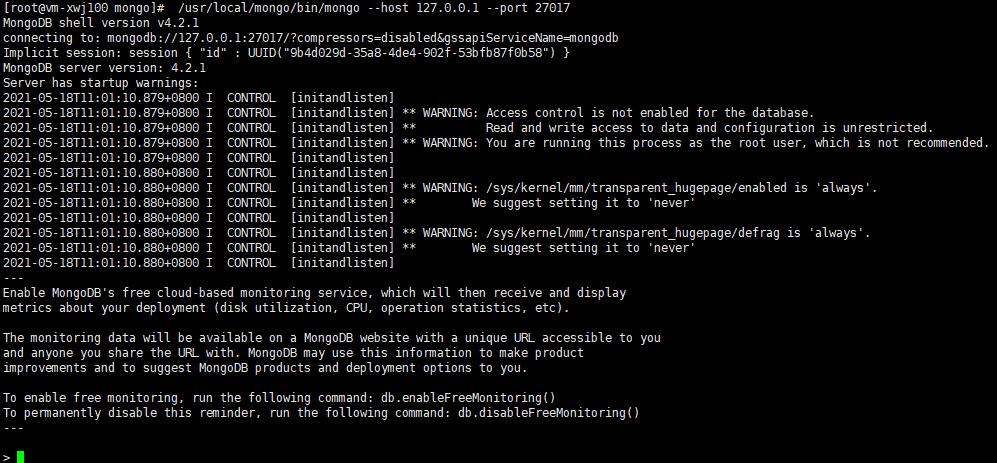
6、启动mongo客户端
/usr/local/mongo/bin/mongo --host 127.0.0.1 --port 27017
启动成功如下:
至此安装完成~
1.6 MongoDB基本操作及增删改查
1.6.1 基本操作
登陆数据库
mongo
查看数据库
show databases;

选择数据库
use数据库名
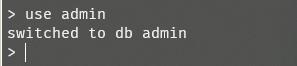
如果切换到一个没有的数据库,例如use admin2,那么会隐式创建这个数据库。(后期当该数据库有数据时,系统自动创建)
use admin2
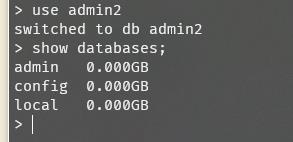
查看集合
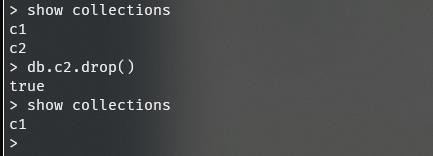
show collections
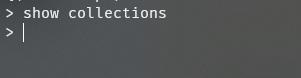
创建集合
db.createCollection('集合名')
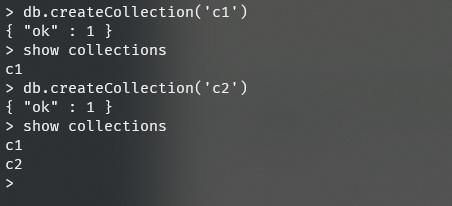
删除集合
`db.集合名.drop()`
删除数据库
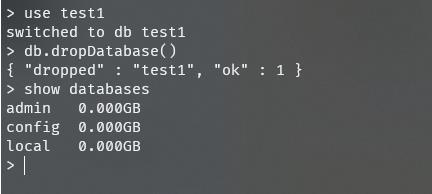
通过use语法选择数据
通过db.dropDataBase()删除数据库
1.6.2 增删改查
1.6.2.1 增加
db.集合名.insert(JSON数据)
如果集合存在,那么直接插入数据。如果集合不存在,那么会隐式创建。
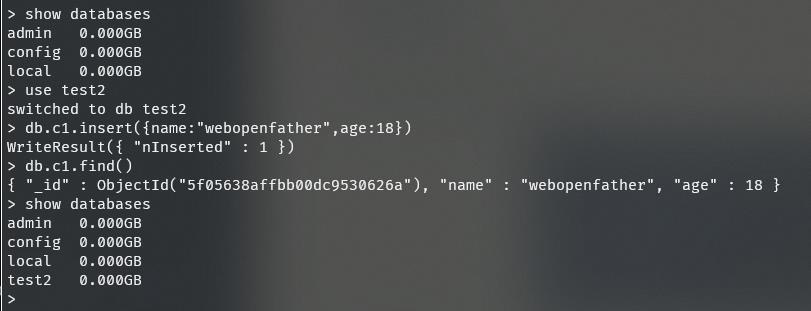
示例:在test2数据库的c1集合中插入数据(姓名叫webopenfather年龄18岁)
use test2 db.c1.insert(uname:"webopenfather",age:18)
- 数据库和集合不存在都隐式创建
- 对象的键统一不加引号(方便看),但是查看集合数据时系统会自动加
mongodb会给每条数据增加一个全球唯一的_id键
_id键的组成

- 自己增加
_id
可以,只需要给插入的JSON数据增加_id键即可覆盖(但实战强烈不推荐)db.c1.insert(_id:1, uname:"webopenfather", age:18)
一次性插入多条数据
传递数据,数组中写一个个JSON数据即可
db.c1.insert([ uname:"z3", age:3, uname:"z4", age:4, uname:"w5", age:5 ])
快速插入10条数据
由于mongodb底层使用JS引擎实现的,所以支持部分js语法。因此:可以写for循环
for (var i=1; i<=10; i++) db.c2.insert(uanme: "a"+i, age: i)
查询文档
db.集合名.find(条件[,查询的列])
| 条件 | 写法 |
|---|---|
| 查询所有的数据 | 或者不写 |
| 查询age=6的数据 | age:6 |
| 既要age=6又要性别=男 | age:6,sex:‘男’ |
| 查询的列(可选参数) | 写法 |
|---|---|
| 查询全部列(字段) | 不写 |
| 只显示age列(字段) | age:1 |
| 除了age列(字段)都显示 | age:0 |
其他语法
db.集合名.find(
键:运算符:值
)
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
实例练习
查询所有数据
db.c1.find()

系统的_id无论如何都会存在
1、查询age大于5的数据
db.c1.find(age:$gt:5)

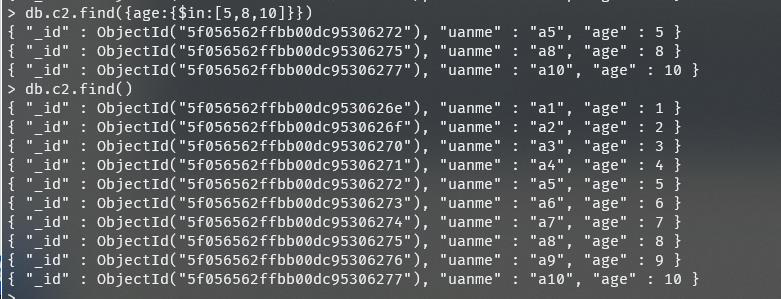
2、查询年龄是5岁、8岁、10岁的数据
db.c2.find(age:$in:[5,8,10])
3、只看年龄列,或者年龄以外的列
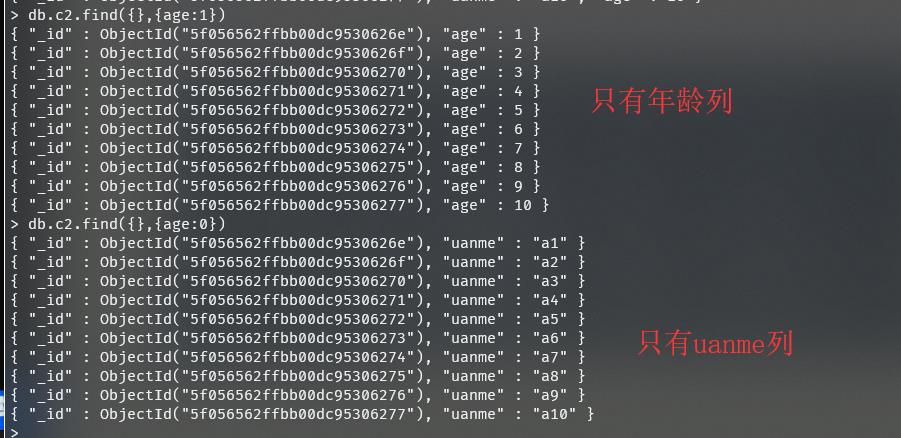
1.6.3 修改文档
db.集合名.update(条件,新数据[是否新增,是否修改多条,])
-
新数据此数据需要使用修改器,如果不使用,那么会将新数据替换原来的数据。
1db.集合名.update(条件,修改器:键:值[是否新增,是否修改多条,])
修改器作用inc递增rename重命名列set修改列值unset删除列 -
是否新增
指条件匹配不到数据则插入(true是插入,false否不插入默认)
db.c3.update(uname:"zs30",$set:age:30,true)

-
是否修改多条
指将匹配成功的数据都修改(true是,false否默认)
db.c3.update(uname:"zs2",$set:age:30,false,true)
实例练习
准备工作
use test2;
for(var i = 1; i<= 10; i++)
db.c3.insert( "uname":"zs"+i,"age":i );
1、将uname:"zs1"改为uname:"zs2"
db.c3.update(uname:"zs1",$set:uname:"zs2")
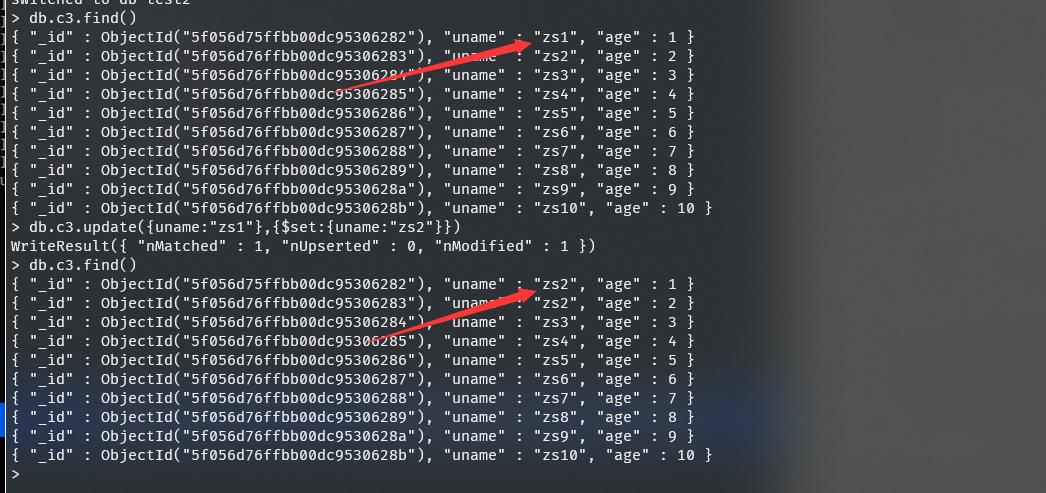
2、给uname:"zs10"的年龄加2岁或减2岁
db.c3.update(uname:"zs10",$inc:age:2)
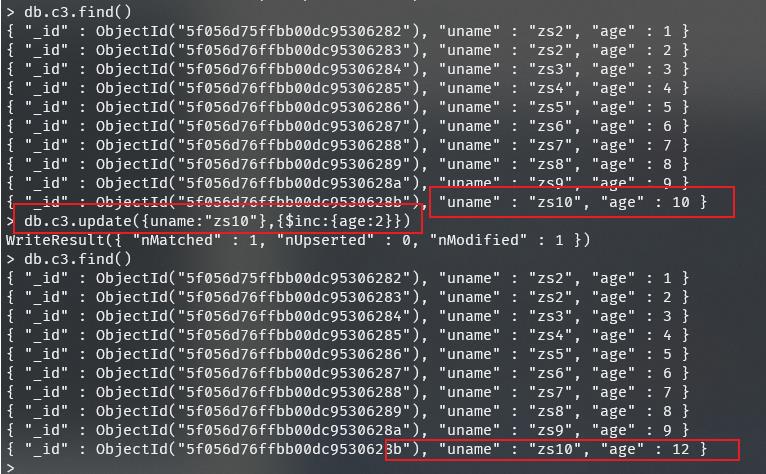
递减只需要将2改为-2即可。
综合练习插入数据:
db.c4.insert( uname:"神龙教主",age:888,who:"男",other:"非国人");
1.6.4 删除文档
db.集合名.remove(条件[,是否删除一条])
- 是否删除一条
true:是(删除的数据为第一条)
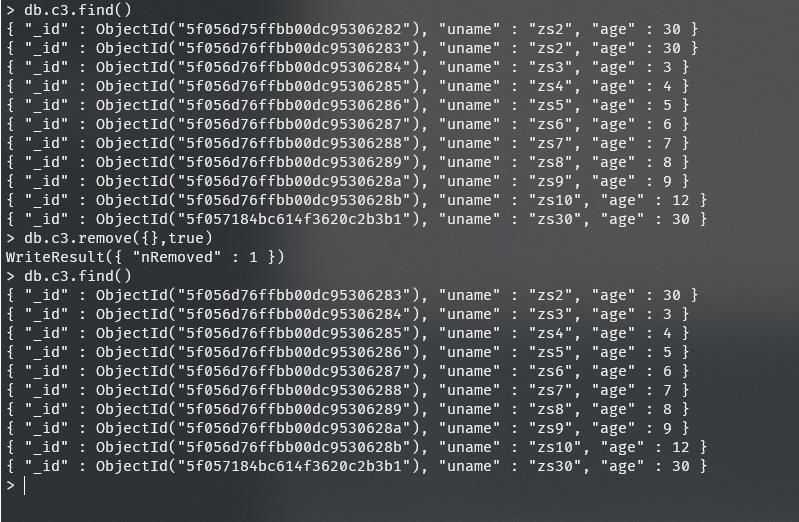
false:否
db.c3.remove(uname:"zs3")
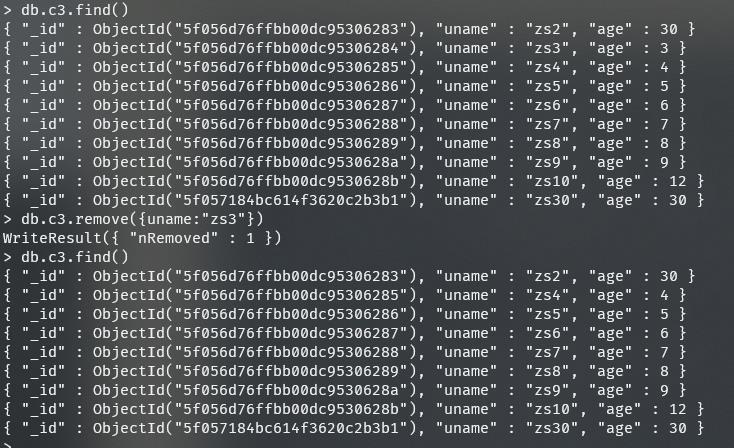
1.6.5 总结
高级开发攻城狮统称:所有数据库都需要增删改查CURD标识
MongoDB删除语法:remove
增Create
db.集合名.insert(JSON数据)
删Delete
db.集合名.remove(条件 [,是否删除一条true是false否默认])
也就是默认删除多条
改Update
db.集合名.update(条件, 新数据 [,是否新增,是否修改多条])
升级语法db.集合名.update(条件,修改器:键:值)
查Read
db.集合名.find(条件 [,查询的列])
1.7 MongoDB存储数据类型
MongoDB中每条记录称作一个文档,这个文档和我们平时用的JSON有点像,但也不完全一样。JSON是一种轻量级的数据交换格式。简洁和清晰的层次结构使得JSON成为理想的数据交换语言,JSON易于阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率,但是JSON也有它的局限性,比如它只有null、布尔、数字、字符串、数组和对象这几种数据类型,没有日期类型,只有一种数字类型,无法区分浮点数和整数,也没法表示正则表达式或者函数。由于这些局限性,BSON闪亮登场啦,BSON是一种类JSON的二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型,MongoDB使用BSON做为文档数据存储和网络传输格式。
1.7.1 数字
shell默认使用64位浮点型数值,如下:
db.sang_collec.insert(x:3.1415926)
db.sang_collec.insert(x:3)
对于整型值,我们可以使用NumberInt或者NumberLong表示,如下:
db.sang_collec.insert(x:NumberInt(10))
db.sang_collec.insert(x:NumberLong(12))
1.7.2 字符串
字符串也可以直接存储,如下:
db.sang_collec.insert(x:"hello MongoDB!")
1.7.3 正则表达式
正则表达式主要用在查询里边,查询时我们可以使用正则表达式,语法和javascript中正则表达式的语法相同,比如查询所有key为x,value以hello开始的文档且不区分大小写:
db.sang_collec.find(x:/^(hello)(.[a-zA-Z0-9])+/i)
1.7.4 数组
数组一样也是被支持的,如下:
db.sang_collec.insert(x:[1,2,3,4,new Date()])
数组中的数据类型可以是多种多样的。
1.7.5 日期
MongoDB支持Date类型的数据,可以直接new一个Date对象,如下:
db.sang_collec.insert(x:new Date())
1.7.6 内嵌文档
一个文档也可以作为另一个文档的value,这个其实很好理解,如下:
db.sang_collect.insert(name:"三国演义",author:name:"罗贯中",age:99);
书有一个属性是作者,作者又有name,年龄等属性。
1.8 MongoDB 中的索引
1.8.1 索引创建
默认情况下,集合中的_id字段就是索引,我们可以通过getIndexes()方法来查看一个集合中的索引:
db.sang_collect.getIndexes()
结果如下:
[
"v" : 2,
"key" :
"_id" : 1
,
"name" : "_id_",
"ns" : "sang.sang_collect"
]
我们看到这里只有一个索引,就是_id。
现在我的集合中有10000个文档,我想要查询x为1的文档,我的查询操作如下:
db.sang_collect.find(x:1)
这种查询默认情况下会做全表扫描,我们可以用上篇文章介绍的explain()来查看一下查询计划,如下:
db.sang_collect.find(x:1).explain("executionStats")
结果如下:
"queryPlanner" :
,
"executionStats" :
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 15,
"totalKeysExamined" : 0,
"totalDocsExamined" : 10000,
"executionStages" :
"stage" : "COLLSCAN",
"filter" :
"x" :
"$eq" : 1.0
,
"nReturned" : 1,
"executionTimeMillisEstimate" : 29,
"works" : 10002,
"advanced" : 1,
"needTime" : 10000,
"needYield" : 0,
"saveState" : 78,
"restoreState" : 78,
"isEOF" : 1,
"invalidates" : 0,
"direction" : "forward",
"docsExamined" : 10000
,
"serverInfo" :
,
"ok" : 1.0
结果比较长,我摘取了关键的一部分。我们可以看到查询方式是全表扫描,一共扫描了10000个文档才查出来我要的结果。实际上我要的文档就排第二个,但是系统不知道这个集合中一共有多少个x为1的文档,所以会把全表扫描完,这种方式当然很低效,但是如果我加上limit,如下:
db.sang_collect.find(x:1).limit(1)
此时再看查询计划发现只扫描了两个文档就有结果了,但是如果我要查询x为9999的记录,那还是得把全表扫描一遍,此时,我们就可以给该字段建立索引,索引建立方式如下:
db.sang_collect.ensureIndex(x:1)
1表示升序,-1表示降序。当我们给x字段建立索引之后,再根据x字段去查询,速度就非常快了,我们看下面这个查询操作的执行计划:
db.sang_collect.find(x:9999).explain("executionStats")
这个查询计划过长我就不贴出来了,我们可以重点关注查询要耗费的时间大幅度下降。
此时调用getIndexes()方法可以看到我们刚刚创建的索引,如下:
[
"v" : 2,
"key" :
"_id" : 1
,
"name" : "_id_",
"ns" : "sang.sang_collect"
,
"v" : 2,
"key" :
"x" : 1.0
,
"name" : "x_1",
"ns" : "sang.sang_collect"
]
我们看到每个索引都有一个名字,默认的索引名字为字段名_排序值,当然我们也可以在创建索引时自定义索引名字,如下:
db.sang_collect.ensureIndex(x:1,name:"myfirstindex")
此时创建好的索引如下:
"v" : 2,
"key" :
"x" : 1.0
,
"name" : "myfirstindex",
"ns" : "sang.sang_collect"
当然索引在创建的过程中还有许多其他可选参数,如下:
db.sang_collect.ensureIndex(x:1,name:"myfirstindex",dropDups:true,background:true,unique:true,sparse:true,v:1,weights:99999)
关于这里的参数,我说一下:
1.
name表示索引的名称
2.dropDups表示创建唯一性索引时如果出现重复,则将重复的删除,只保留第一个
3.background是否在后台创建索引,在后台创建索引不影响数据库当前的操作,默认为false
4.unique是否创建唯一索引,默认false
5.sparse对文档中不存在的字段是否不起用索引,默认false
6.v表示索引的版本号,默认为2
7.weights表示索引的权重
此时创建好的索引如下:
"v" : 1,
"unique" : true,
"key" :
"x" : 1.0
,
"name" : "myfirstindex",
"ns" : "sang.sang_collect",
"background" : true,
"sparse" : true,
"weights" : 99999.0
1.8.2 查看索引
getIndexes()可以用来查看索引,我们还可以通过totalIndexSize()来查看索引的大小,如下:
db.sang_collect.totalIndexSize()
1.8.3 删除索引
我们可以按名称删除索引,如下:
db.sang_collect.dropIndex("xIndex")
表示删除一个名为xIndex的索引,当然我们也可以删除所有索引,如下:
db.sang_collect.dropIndexes()
1.8.4 总结
索引是个好东西,可以有效的提高查询速度,但是索引会降低插入、更新和删除的速度,因为这些操作不仅要更新文档,还要更新索引,MongoDB 限制每个集合上最多有64个索引,我们在创建索引时要仔细斟酌索引的字段。
1.9 Java操作MongoDB
1.9.1 方式一
方式一采用的原生Java操作MongoDB
1.9.1.1 前期准备
首先我们需要驱动,MongoDB的Java驱动我们可以直接在Maven中央仓库去下载,也可以创建Maven工程添加如下依赖:
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongodb-driver</artifactId>
<version>3.5.0</version>
</dependency>
建议通过Maven来添加依赖,如果自己下载jar,需要下载如下三个jar:
1.org.mongodb:bson:jar:3.5.0
2.org.mongodb:mongodb-driver-core:jar:3.5.0
3.org.mongodb:mongodb-driver:jar:3.5.0
另外,在使用Java操作 MongoDB之前,记得启动 MongoDB
1.9.1.2 获取集合
所有准备工作完成之后,我们首先需要一个MongoClient,如下:
MongoClient client = new MongoClient("192.168.248.136", 27017);
然后通过如下方式获取一个数据库,如果要获取的数据库本身就存在,直接获取到,不存在MongoDB会自动创建:
MongoDatabase sang = client.getDatabase("sang");
然后通过如下方式获取一个名为c1的集合,这个集合存在的话就直接获取到,不存在的话MongoDB会自动创建出来,如下:
MongoCollection<Document> c = sang.getCollection("c1");
有了集合之后,我们就可以向集合中插入数据了。
1、增加操作
和在shell中的操作一样,我们可以一条一条的添加数据,也可以批量添加,添加单条数据操作如下:
Document d1 = new Document();
d1.append("name", "三国演义").append("author", "罗贯中");
c.insertOne(d1);
添加多条数据的操作如下:
List<Document> collections = new ArrayList<Document>();
Document d1 = new Document();
d1.append("name", "三国演义").append("author", "罗贯中");
collections.add(d1);
Document d2 = new Document();
d2.append("name", "红楼梦").append("author", "曹雪芹");
collections.add(d2);
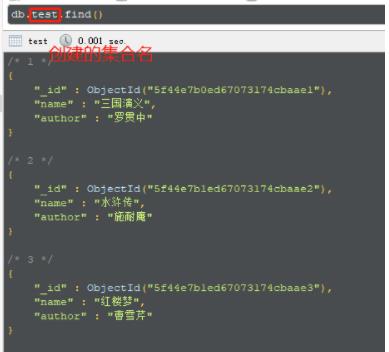
c.insertMany(collections);
当然也可以通过 Robo 3T查看修改结果:db.集合名.find()
2、修改操作
可以修改查到的第一条数据,操作如下:
c.updateOne(Filters.eq("author", "罗贯中"), new Document("$set", new Document("name", "三国演义123")));
上例中小伙伴们也看到了修改器要如何使用,不管是inc,用法都一致,我这里不再一个一个演示。也可以修改查到的所有数据,如下:
c.updateMany(Filters.eq("author", "罗贯中"), new Document("$set", new Document("name", "三国演义456")));
3、删除操作
可以删除查到的一条数据,如下:
c.deleteOne(Filters.eq("author", "罗贯中"));
也可以删除查到的所有数据:
c.deleteMany(Filters.eq("author", "罗贯中"));
Filters里边还有其他的查询条件,都是见名知意,不赘述。
4、 查询操作
可以直接查询所有文档:
FindIterable<Document> documents = c.find();
MongoCursor<Document> iterator = documents.iterator();
while (iterator.hasNext())
System.out.println(iterator.next());
也可以按照条件查询:
FindIterable<Document> documents = c.find(Filters.eq("author", "罗贯中"));
MongoCursor<Document> iterator = documents.iterator();
while (iterator.hasNext())
System.out.println(iterator.next());
其他的方法基本都是见名知意,这里不再赘述。
5、验证问题
上面我们演示的获取一个集合是不需要登录MongoDB数据库的,如果需要登录,我们获取集合的方式改为下面这种:
ServerAddress serverAddress = new ServerAddress("192.168.248.128", 27017);
List<MongoCredential> credentialsList = new ArrayList<MongoCredential>();
MongoCredential mc = MongoCredential.createScramSha1Credential("readuser","sang","123".toCharArray());
credentialsList.add(mc);
MongoClient client = new MongoClient(serverAddress,credentialsList);
MongoDatabase sang = client.getDatabase("sang");
c = sang.getCollection("c1");
MongoCredential是一个凭证,第一个参数为用户名,第二个参数是要在哪个数据库中验证,第三个参数是密码的char数组,然后将登录地址封装成一个ServerAddress,最后将两个参数都传入MongoClient中实现登录功能。
6、其他配置
在连接数据库的时候也可以设置连接超时等信息,在MongoClientOptions中设置即可,设置方式如下:
ServerAddress serverAddress = new ServerAddress("192.168.248.128", 27017);
List<MongoCredential> credentialsList = new ArrayList<MongoCredential>();
MongoCredential mc = MongoCredential.createScramSha1Credential("rwuser","sang","123".toCharArray());
credentialsList.add(mc);
MongoClientOptions options = MongoClientOptions.builder()
//设置连接超时时间为10s
.connectTimeout(1000*10)
//设置最长等待时间为10s
.maxWaitTime(1000*10)
.build();
MongoClient client = new MongoClient(serverAddress,credentialsList,options);
MongoDatabase sang = client.getDatabase("sang");
c = sang.getCollection("c1");
1.9.2 方式二
主要讲解SpringBoot操作MongoDB实现增删改查的功能
1、pom.xml引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-mongodb</artifactId>
</dependency>
2、创建application.yml
spring:
data:
mongodb:
host: 192.168.72.129
database: studentdb
3、创建实体类
创建包com.changan.mongodb,包下建包pojo用于存放实体类,创建实体类
package com.changan.mongdb.pojo;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
@Document(collection = "student")
public class Student implements Serializable
@Id
privat以上是关于MongoDB详解,用心看这篇就够了重点的主要内容,如果未能解决你的问题,请参考以下文章