ICML 2021奖项公布!谷歌大脑摘得桂冠,田渊栋陆昱成获荣誉提名!
Posted 机器学习算法与Python学习-公众号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ICML 2021奖项公布!谷歌大脑摘得桂冠,田渊栋陆昱成获荣誉提名!相关的知识,希望对你有一定的参考价值。
点击 机器学习算法与Python学习 ,选择加星标
精彩内容不迷路

机器之心报道
刚刚,ICML 2021揭晓了本届杰出论文奖和杰出论文荣誉提名奖,来自多伦多大学、谷歌大脑的研究获得了杰出论文奖,包括田渊栋、陆昱成在内的多位学者获得了杰出论文荣誉提名奖。此外,高通副总裁Max Welling和Hinton学生郑宇怀合著的研究获得了本次大会的时间检验奖。
近日,机器学习国际顶级会议 ICML 2021 以线上方式举行,本次会议共收到 5513 篇论文投稿,其中 1184 篇被接收,接收率为 21.5%,与上一年持平。

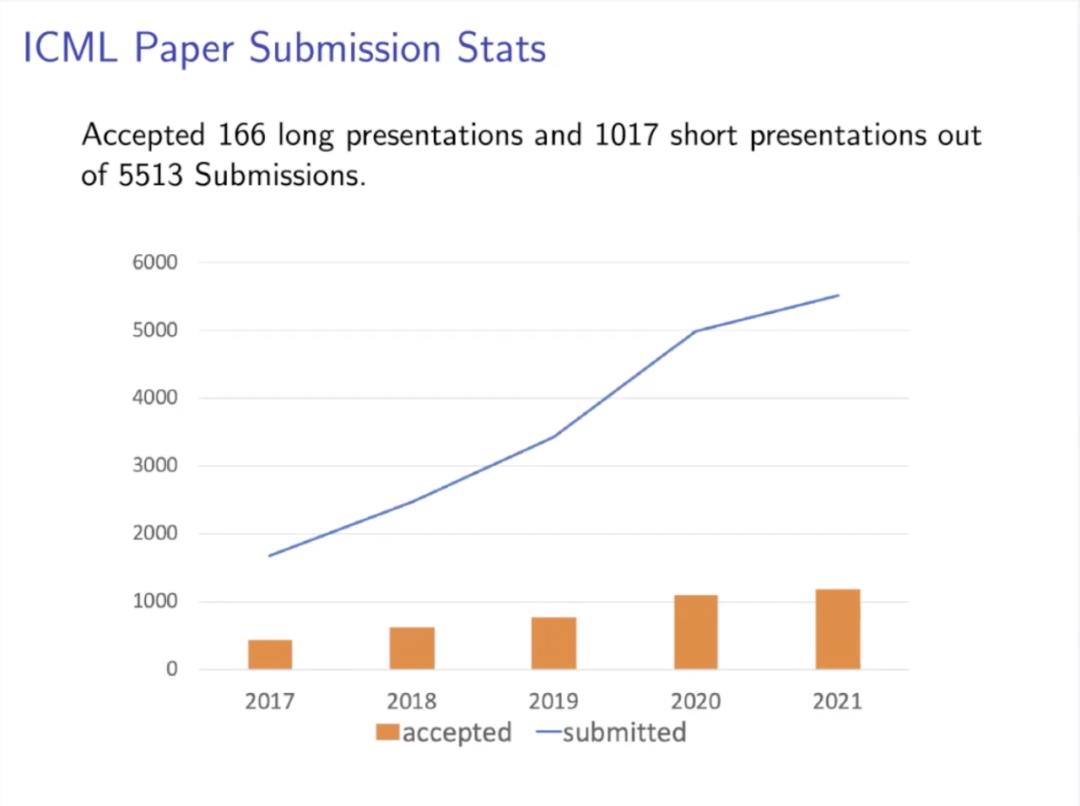
ICML 2021 程序主席张潼(香港科技大学教授)和 Marina Meila(华盛顿大学教授)在线上直播中公布了本次大会提交和接收论文的一些详细数据。首先,下图为 2017 至 2021 年 ICML 会议的论文提交与接收变化曲线:
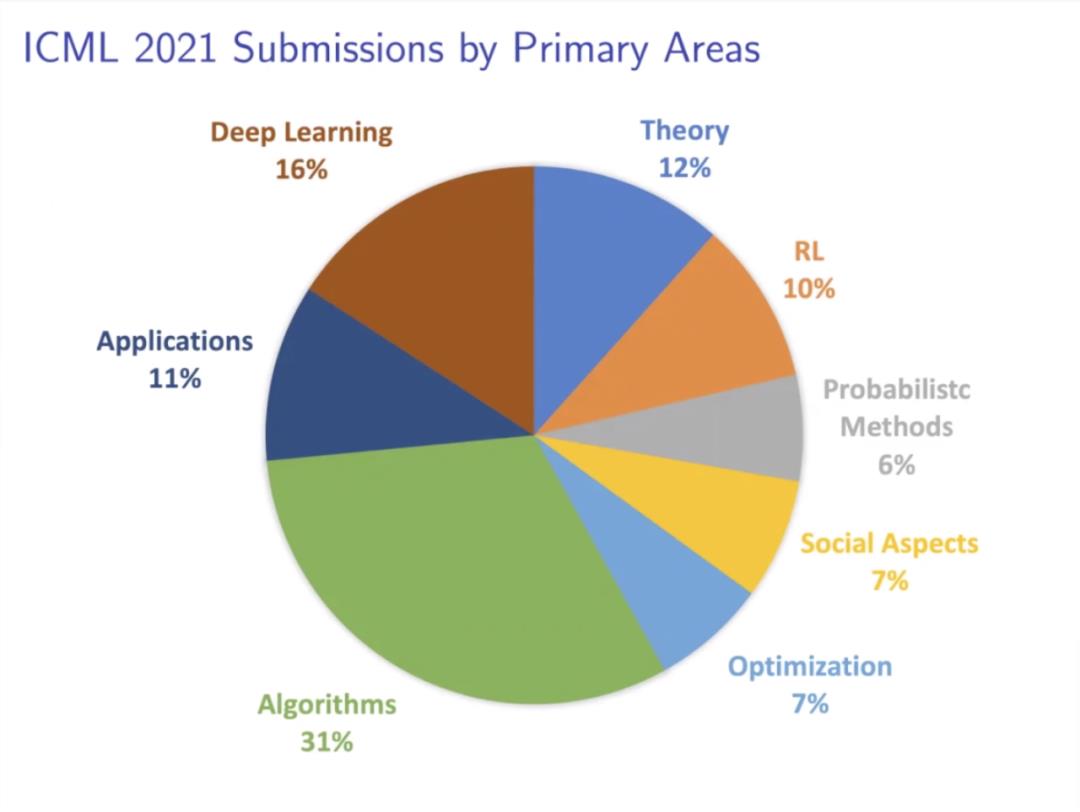
ICML 2021 提交论文所属领域主要包括算法、深度学习(DL)、理论、应用、强化学习(RL)、社会层面、优化和概率方法(按比例从高到低排列)。
ICML 2021 按论文所属领域的接收率分布如下,其中理论论文接收率最高,随后依次为强化学习(RL)、概率方法、社会层面、优化、算法、应用和深度学习。

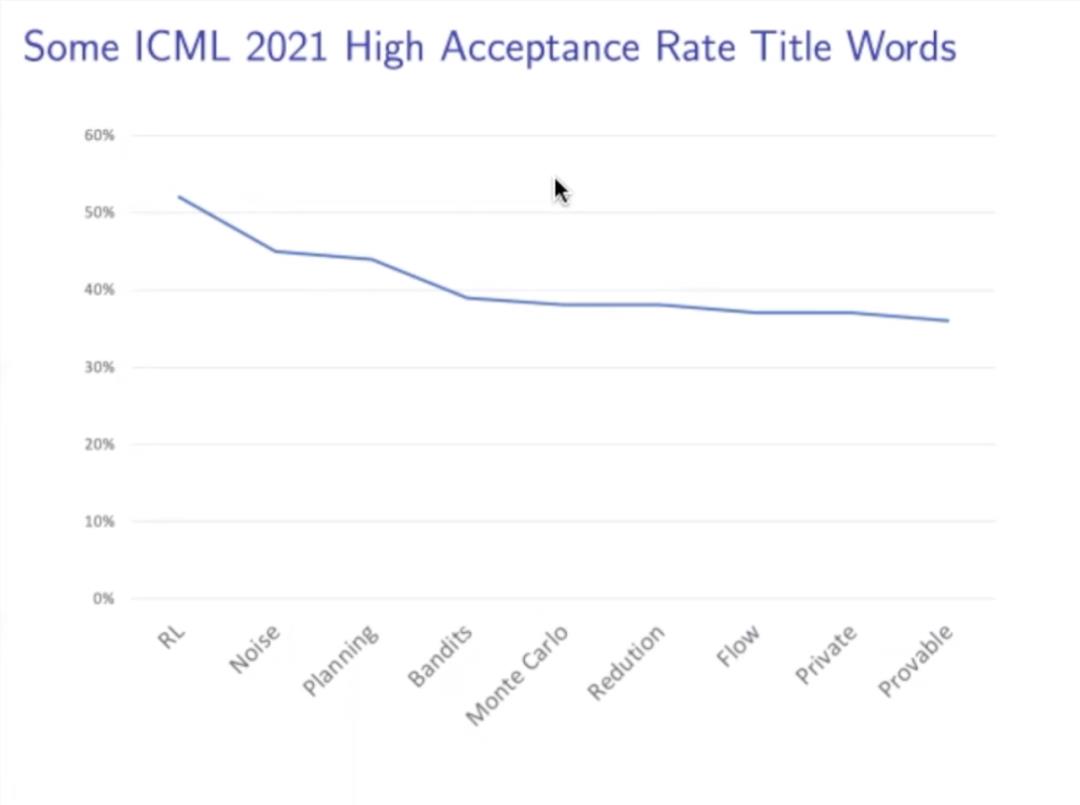
在 ICML 2021 的所有接收论文中,哪些关键词是高频出现的呢?如下图所示,RL 出现频率最高,随后依次是 noise、planning、Bandits、Monte Carlo、Redution、Flow、Private 和 Provable。
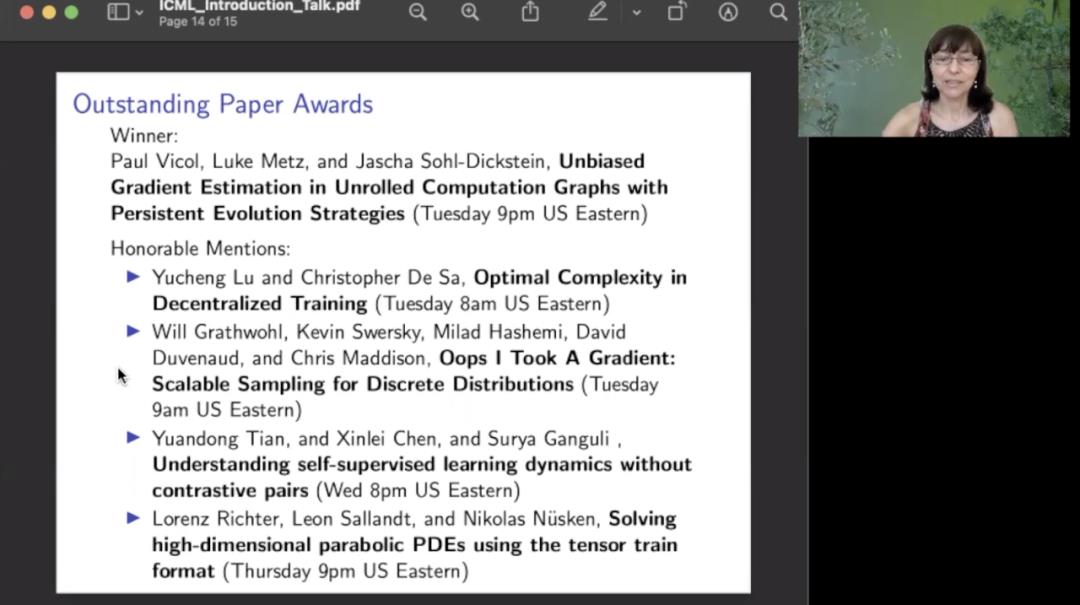
在会议上,ICML 2021 大会公布了杰出论文奖和杰出论文荣誉提名奖的获奖结果,同时也公布了此次大会时间检验奖的结果。
来自多伦多大学和谷歌大脑的论文《Unbiased Gradient Estimation in Unrolled Computation Graphs with Persistent Evolution Strategies》获得了此次会议的杰出论文奖,此外共四篇论文获得了杰出论文荣誉提名奖,其中包括康奈尔大学博士生陆昱成、Facebook 人工智能研究院研究员田渊栋等人参与的研究。
值得注意的是,ICML 2021 官网公布的奖项和直播时程序主席公布的奖项出现不一致的情况,机器之心以直播中程序主席公布的奖项信息为准。
官网公布的杰出论文。
杰出论文奖
获得本次 ICML 杰出论文奖的研究者来自多伦多大学和谷歌大脑,他们提出了一种在展开计算图中高效学习和优化参数的无偏梯度方法,并在实验中展现出了相较于其他方法的优势。

论文地址:http://proceedings.mlr.press/v139/vicol21a/vicol21a.pdf
论文作者:Paul Vicol、Luke Metz、Jascha Sohl-Dickstein
机构:多伦多大学、谷歌大脑
目前,展开(unrolled)计算图应用在很多场景中,包括训练 RNN、通过展开优化微调超参数和训练可学习优化器等。但是,在这类计算图中优化参数的方法存在着高方差梯度、偏差、更新缓慢以及大量内存使用等诸多问题。
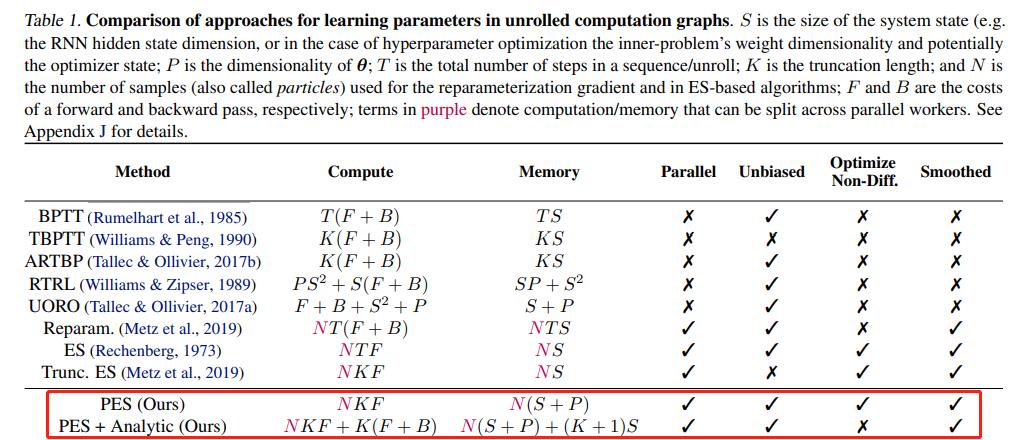
在本文中,研究者提出了一种名为 Persistent Evolution Strategies (PES)的方法,它可以将计算图分成一系列截断的展开,并在每次展开后执行基于进化策略的更新步骤。PES 通过在整个展开序列上累积校正项来消除这些截断的偏差。PES 可以实现快速参数更新,具有低内存使用、无偏差以及合理的方差特征。实验表明,PES 在合成任务上展现出了与其他梯度估计方法的优势,并在训练可学习优化器和微调超参数方面具有适用性。
下图右为一个展开计算图,展示了如何使用图左的公式 1 和公式 2 来描述 RNN 和展开优化。

下表为 PES 方法与其他在展开计算图中学习参数的方法的比较:
杰出论文荣誉提名奖
本次有四篇论文获得 ICML 2021 杰出论文荣誉提名奖,分别由来自康奈尔大学、多伦多大学、谷歌大脑、FAIR、斯坦福大学、德国柏林自由大学、德国波茨坦大学等机构的研究者获得。值得一提的是,来自 Facebook 的科学家田渊栋担任一作的论文也收获此奖。
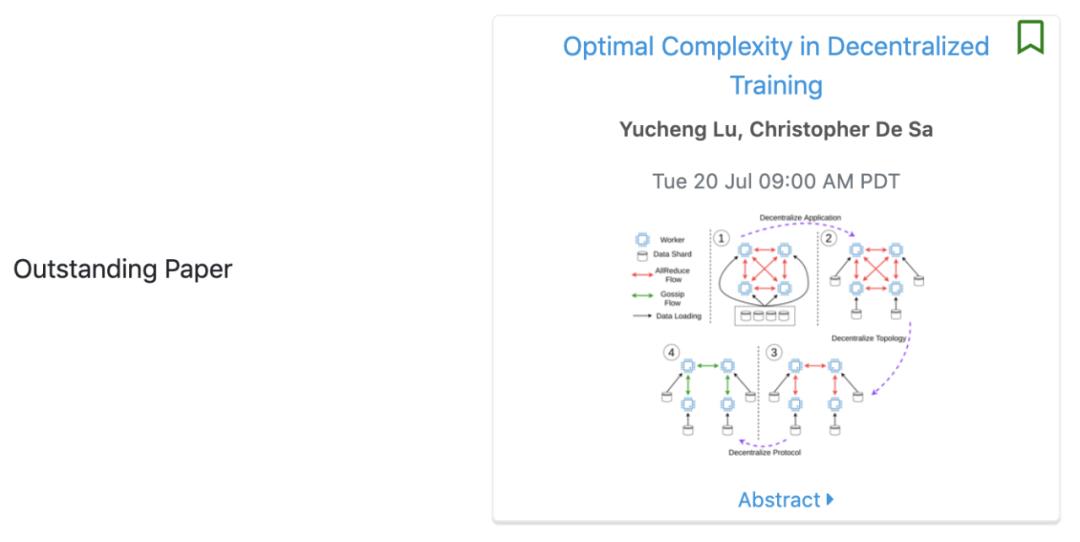
论文 1:Optimal Complexity in Decentralized Training

论文地址:http://proceedings.mlr.press/v139/lu21a/lu21a.pdf
论文作者:Yucheng Lu(陆昱成)、Christopher De Sa
机构:康奈尔大学
去中心化是扩展并行机器学习系统的一种有效方法。本文给出了在随机非凸设置下进行复杂迭代的下界,该下界揭示了现有分散训练算法(例如 D-PSGD)在已知收敛速度方面存在理论差距。该研究通过构造来证明这个下界是严格的,并且可实现。基于这一发现,该研究进一步提出了 DeTAG,一个实用的 gossip 风格去中心化算法,仅以对数间隔(logarithm gap)就能实现下界。该研究将 DeTAG 算法与其他去中心化算法在图像分类任务上进行了比较,结果表明 DeTAG 算法与基线算法相比具有更快的收敛速度,特别是在未经打乱的数据和稀疏网络中。
该论文一作陆昱成本科就读于上海交通大学,现为康奈尔大学计算机科学系博士生。陆昱成的主要研究领域包括分布式优化和机器学习系统。
论文 2:Oops I Took A Gradient: Scalable Sampling for Discrete Distributions

论文地址:https://arxiv.org/pdf/2102.04509.pdf
论文作者:Will Grathwohl、Kevin Swersky、Milad Hashemi、David Duvenaud、Chris Maddison
机构:多伦多大学、谷歌大脑
研究者为带有离散变量的概率模型提供了一种通用且可扩展的近似采样策略,该策略使用似然函数相对于其自身离散输入的梯度以在 Metropolis–Hastings 采样器中进行更新。实验表明,该方法在很多困难的设置下均优于通用采样器,包括 Ising 模型、Potts 模型以及受限玻尔兹曼机和因子隐马尔可夫模型。此外,研究者还展示了改进后的采样器可以在高维离散图像数据上训练基于能量的深度模型。这种方法优于变分自编码器和现有的基于能量的模型。最后,研究者给出了 bounds,表明他们的方法在提出局部更新的采样器中接近最优。
论文 3:Understanding self-supervised learning dynamics without contrastive pair

论文地址:https://arxiv.org/pdf/2102.06810.pdf
论文作者:Yuandong Tian(田渊栋)、Xinlei Chen、Surya Ganguli
机构:FAIR、斯坦福大学
对比自监督学习(SSL)的比较方法通过最小化同一数据点(正样本对)的两个增强视图之间的距离和最大化来自不同数据点的视图(负样本对)来学习表征,然而,最近的非对比 SSL(如 BYOL 、SimSiam)在没有负样本对的情况下表现出了卓越的性能,使用额外的可学习预测器和停止梯度操作(stop-gradient operation),模型性能会更佳。这样会出现一个基本的问题:为什么这些方法不能分解成简单的表征?
该研究通过一个简单的理论研究来回答这个问题,并提出一个新的方法 DirectPred,该方法直接根据输入的统计数据设置线性预测器,而不需要梯度训练。研究者在 ImageNet 上进行了比较,结果显示其结果与使用 BatchNorm 更复杂的两层非线性预测器性能相当,并且在 300-epoch 的训练中比线性预测器高出 2.5%(在 60 个 epoch 中高出 5%)。DirectPred 研究是受到对简单线性网络中非对比 SSL 的非线性学习动力学理论研究的启发。该研究从概念上深入了解了非对比 SSL 方法是如何学习以及如何避免表征崩溃,此外还包括多重因素,例如预测网络、停止梯度、指数移动平均数、权重衰减等因素如何发挥作用。
最后,该研究还简单概括了所提方法在 STL-10 和 ImageNet 消融研究的结果。
论文 4:Solving high-dimensional parabolic PDEs using the tensor train format

论文地址:https://arxiv.org/pdf/2102.11830.pdf
论文作者:Lorenz Richter、Leon Sallandt、Nikolas Nüsken
机构:德国柏林自由大学、德国波茨坦大学等
高维偏微分方程(PDE)在经济学、科学和工程中无处不在。然而,对 PDE 数值的处理还存在巨大的挑战,因为传统的基于网格(gridbased)的方法往往会受到维数诅咒的阻碍。在本文中,研究者认为张量训练为抛物偏微分方程提供了一个合理的近似框架:将倒向随机微分方程和张量格式的回归型方法相结合,有望利用潜在的低秩结构,实现压缩和高效计算。
依照此范式,研究者开发了新的迭代方案,包括显式、快速的或者隐式、准确的更新。与 SOTA 性能的神经网络相比所提方法在准确率和计算效率之间取得了很好的权衡。
时间检验奖

获得本次大会时间检验奖的是一篇 ICML 2011 的论文,主题是「基于随机梯度 Langevin 动力学的贝叶斯学习」。

论文地址:https://www.cse.iitk.ac.in/users/piyush/courses/tpmi_winter21/readings/sgld.pdf
论文作者:Max Welling、Yee Whye Teh

Max Welling 是阿姆斯特丹大学机器学习研究负责人、高通公司技术副总裁,同时也是加拿大高级研究院(CIFAR)的高级研究员。1998 年,Max Welling 在诺贝尔经济学奖获得者 Gerard t Hooft 的指导下获得博士学位。Max Welling 在加州理工学院(98-00)、伦敦大学学院(00-01)和多伦多大学(01-03)均有过博士后工作经历,目前拥有超过 250 篇机器学习、计算机视觉、统计学和物理学方面的科学出版物,h-index 指数为 62。

Yee Whye Teh(郑宇怀)是牛津大学统计学系教授、DeepMind 研究科学家,马来西亚华人。郑宇怀在多伦多大学获得博士学位,师从 Geroffery Hinton,并在加州大学伯克利分校和新加坡国立大学从事博士后工作。他的研究兴趣包括机器学习、计算统计学和人工智能,特别是概率模型、非参数贝叶斯、大规模学习和深度学习。他是深度信念网络和层次狄利克雷过程的最初提出者之一。
在这篇论文中,研究者提出了一种基于 small mini-batches 迭代学习的大规模数据集学习框架。通过在标准的随机梯度优化算法中加入适量噪声,研究者证明了 stepsize 退火时迭代会收敛到真实后验概率的样本。这种优化和贝叶斯后验采样之间的无缝衔接提供了一个防止过拟合的内置保护。此外,论文提出了一种蒙特卡罗后验统计量估计的实用方法,该方法可监测「采样阈值」,并在超过采样阈值后收集样本。研究者将这种方法应用于高斯、逻辑回归、ICA 三种模型的混合,并使用自然梯度。
同样地,为了帮助研究者快速了解本次会议入选的工作,这一次 Paper Digest Team 整理了所有被接收的论文,并给每篇论文提炼了一个金句(通常是主题),帮助读者快速了解每篇论文的主要思想。
网站地址:https://www.paperdigest.org/2021/07/icml-2021-highlights/
参考链接:https://watch.videodelivery.net/b504b00c401ac24e41ab297a9f3781b9
如果对你有帮助。
请不吝点赞,点在看,谢谢
以上是关于ICML 2021奖项公布!谷歌大脑摘得桂冠,田渊栋陆昱成获荣誉提名!的主要内容,如果未能解决你的问题,请参考以下文章