2021年大数据ELK(十四):Elasticsearch编程(基本操作)
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据ELK(十四):Elasticsearch编程(基本操作)相关的知识,希望对你有一定的参考价值。
全网最详细的大数据ELK文章系列,强烈建议收藏加关注!
新文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。
目录
基本操作

一、根据ID检索指定职位数据
1、实现步骤
- 构建GetRequest请求。
- 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
- 将ES响应的数据转换为JSON字符串
- 并使用FastJSON将JSON字符串转换为JobDetail类对象
- 记得:单独设置ID
参考代码:
@Override
public JobDetail findById(long id) throws IOException
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, id + "");
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json = response.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 设置ID字段
jobDetail.setId(id);
return jobDetail;
2、编写测试用例
参考代码:
@Test
public void findByIdTest() throws IOException
JobDetail jobDetail = jobFullTextService.findById(1);
System.out.println(jobDetail);
二、修改职位
1、实现步骤
- 判断对应ID的文档是否存在
- 构建GetRequest
- 执行client的exists方法,发起请求,判断是否存在
- 构建UpdateRequest请求
- 设置UpdateRequest的文档,并配置为JSON格式
- 执行client发起update请求
参考代码:
@Override
public void update(JobDetail jobDetail) throws IOException
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, jobDetail.getId() + "");
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(!exists) return;
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX_NAME, jobDetail.getId() + "");
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSON.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
2、编写测试用例
-
将ID为1的职位信息查询出来
-
将职位的名称设置为:”大数据开发工程师”
-
执行更新操作
-
再打印查看职位的名称是否成功更新
参考代码:
@Test
public void updateTest() throws IOException
JobDetail jobDetail = jobFullTextService.findById(1);
jobDetail.setTitle("大数据开发工程师");
jobFullTextService.update(jobDetail);
System.out.println(jobFullTextService.findById(1));
三、根据文档ID删除职位
1、实现步骤
- 构建delete请求
- 使用RestHighLevelClient执行delete请求
参考代码:
@Override
public void deleteById(long id) throws IOException
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX_NAME, id + "");
// 2. 使用client执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
2、编写测试用例
- 在测试用例中执行根据ID删除文档操作
- 使用VSCode发送请求,查看指定ID的文档是否已经被删除
参考代码:
@Test
public void deleteByIdTest() throws IOException
jobFullTextService.deleteById(1);
四、根据关键字检索数据
1、实现步骤
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件(搜索title、jd),并配置到SearchSourceBuilder
- 调用SearchRequest.source将查询条件设置到检索请求
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果
- 将JSON字符串转换为对象
- 使用SearchHit.getId设置文档ID
参考代码:
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery(keywords, "jd", "title");
searchSourceBuilder.query(queryBuilder);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits)
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
return jobDetailList;
2、编写测试用例
搜索标题、职位描述中包含销售的职位
@Test
public void searchByKeywordsTest() throws IOException
List<JobDetail> jobDetailList = jobFullTextService.searchByKeywords("销售");
for (JobDetail jobDetail : jobDetailList)
System.out.println(jobDetail);
五、分页检索
1、实现步骤
步骤和之前的关键字搜索类似,只不过构建查询条件的时候,需要加上分页的设置
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
- 设置SearchSourceBuilder的from和size参数,构建分页
- 调用SearchRequest.source将查询条件设置到检索请求
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果
- 将JSON字符串转换为对象
- 使用SearchHit.getId设置文档ID
- 将结果封装到Map结构中(带有分页信息)
- total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
- content -> 当前分页中的数据
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery(keywords, "jd", "title");
searchSourceBuilder.query(queryBuilder);
// 4. 设置SearchSourceBuilder的from和size参数,构建分页
searchSourceBuilder.from((pageNum – 1) * pageSize);
searchSourceBuilder.size(pageSize);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits)
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
Map<String, Object> result = new HashMap<>();
result.put("total", hits.getTotalHits().value);
result.put("content", jobDetailList);
return result;
2、编写测试用例
- 搜索关键字为“销售”,查询第0页,每页显示10条数据
- 打印搜索结果总记录数、对应分页的记录
参考代码:
@Test
public void searchByPageTest() throws IOException
Map<String, Object> resultMap = jobFullTextService.searchByPage("销售", 0, 10);
System.out.println("总共:" + resultMap.get("total"));
List<JobDetail> jobDetailList = (List<JobDetail>)resultMap.get("content");
for (JobDetail jobDetail : jobDetailList)
System.out.println(jobDetail);
六、scroll分页检索
1、实现步骤
判断scrollId是否为空
- 如果为空,那么首次查询要发起scroll查询,设置滚动快照的有效时间
- 如果不为空,就表示之前应发起了scroll,直接执行scroll查询就可以
步骤和之前的关键字搜索类似,只不过构建查询条件的时候,需要加上分页的设置
scrollId为空:
- 构建SearchRequest检索请求
- 创建一个SearchSourceBuilder专门用于构建查询条件
- 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
- 调用SearchRequest.source将查询条件设置到检索请求
- 设置每页多少条记录,调用SearchRequest.scroll设置滚动快照有效时间
- 执行RestHighLevelClient.search发起请求
- 遍历结果
- 获取命中的结果
- 将JSON字符串转换为对象
- 使用SearchHit.getId设置文档ID
- 将结果封装到Map结构中(带有分页信息)
- scroll_id -> 从SearchResponse中调用getScrollId()方法获取scrollId
- content -> 当前分页中的数据
scollId不为空:
- 用之前查询出来的scrollId,构建SearchScrollRequest请求
- 设置scroll查询结果的有效时间
- 使用RestHighLevelClient执行scroll请求
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize)
Map<String, Object> result = new HashMap<>();
List<JobDetail> jobList = new ArrayList<>();
try
SearchResponse searchResponse = null;
if(scrollId == null)
// 1. 创建搜索请求
SearchRequest searchRequest = new SearchRequest("job_idx");
// 2. 构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery(keywords, "title", "jd"));
// 3. 设置分页大小
searchSourceBuilder.size(pageSize);
// 4. 设置查询条件、并设置滚动快照有效时间
searchRequest.source(searchSourceBuilder);
searchRequest.scroll(TimeValue.timeValueMinutes(1));
// 5. 发起请求
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
else
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(1));
searchResponse = client.scroll(searchScrollRequest, RequestOptions.DEFAULT);
// 6. 迭代响应结果
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits)
JobDetail jobDetail = JSONObject.parseObject(hit.getSourceAsString(), JobDetail.class);
jobDetail.setId(Long.parseLong(hit.getId()));
jobList.add(jobDetail);
result.put("content", jobList);
result.put("scroll_id", searchResponse.getScrollId());
catch (IOException e)
e.printStackTrace();
return result;
2、编写测试用例
- 编写第一个测试用例,不带scrollId查询
- 编写第二个测试用例,使用scrollId查询
@Test
public void searchByScrollPageTest1() throws IOException
Map<String, Object> result = jobFullTextService.searchByScrollPage("销售", null, 10);
System.out.println("scrollId: " + result.get("scrollId"));
List<JobDetail> content = (List<JobDetail>)result.get("content");
for (JobDetail jobDetail : content)
System.out.println(jobDetail);
@Test
public void searchByScrollPageTest2() throws IOException
Map<String, Object> result = jobFullTextService.searchByScrollPage("销售", "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAA0WRG4zZFVwODJSU2Uxd1BOWkQ4cFdCQQ==", 10);
System.out.println("scrollId: " + result.get("scrollId"));
List<JobDetail> content = (List<JobDetail>)result.get("content");
for (JobDetail jobDetail : content)
System.out.println(jobDetail);
七、高亮查询
1、高亮查询简介
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
京东商城搜索"笔记本"
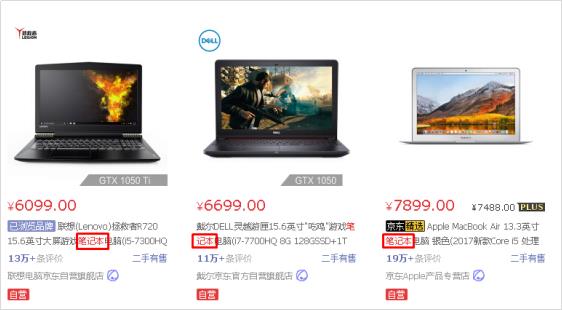
2、高亮显示的html分析
通过开发者工具查看高亮数据的html代码实现
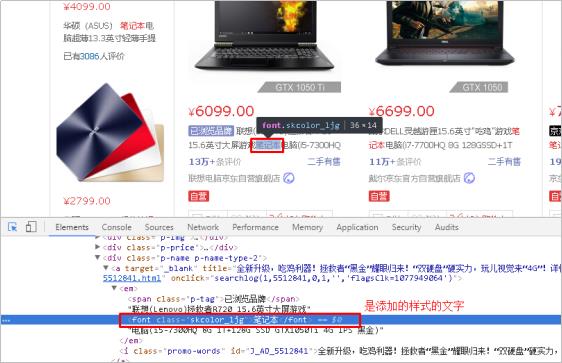
ElasticSearch可以对查询出的内容中关键字部分进行标签和样式的设置,但是你需要告诉ElasticSearch使用什么标签对高亮关键字进行包裹
3、实现高亮查询
- 在我们构建查询请求时,我们需要构建一个HighLightBuilder,专门来配置高亮查询。
- 构建一个HighlightBuilder
- 设置高亮字段(title、jd)
- 设置高亮前缀(<font color=’red’>)
- 设置高亮后缀(</font>)
- 将高亮添加到SearchSourceBuilder
代码如下:
// 设置高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.field("jd");
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
searchSourceBuilder.highlighter(highlightBuilder);- 我们将高亮的查询结果取出,并替换掉原先没有高亮的结果
- 获取高亮字段
- 获取title高亮字段
- 获取jd高亮字段
- 将高亮字段进行替换普通字段
- 处理title高亮,判断高亮是否为空,不为空则将高亮碎片拼接在一起
- 替换原有普通字段
- 获取高亮字段
参考代码:
// 1. 获取高亮字段
Map<String, HighlightField> highlightFieldMap = hit.getHighlightFields();
// 1.1 获取title高亮字段
HighlightField titleHl = highlightFieldMap.get("title");
// 1.2 获取jd高亮字段
HighlightField jdHl = highlightFieldMap.get("jd");
// 2. 将高亮字段进行替换普通字段
// 2.1 处理title高亮,判断高亮是否为空,不为空则将高亮Fragment(碎片)拼接在一起,替换原有普通字段
if(titleHl != null)
Text[] fragments = titleHl.getFragments();
StringBuilder stringBuilder = new StringBuilder();
for (Text fragment : fragments)
stringBuilder.append(fragment.string());
jobDetail.setTitle(stringBuilder.toString());
// 2.2 处理jd高亮
if(jdHl != null)
Text[] fragments = jdHl.getFragments();
StringBuilder stringBuilder = new StringBuilder();
for (Text fragment : fragments)
stringBuilder.append(fragment.string());
jobDetail.setJd(stringBuilder.toString());
八、完整参考代码
public class JobFullTextServiceImpl implements JobFullTextService
private RestHighLevelClient restHighLevelClient;
private static final String JOB_IDX_NAME = "job_idx";
public JobFullTextServiceImpl()
restHighLevelClient = new RestHighLevelClient(RestClient.builder(
new HttpHost("node1", 9200, "http")
, new HttpHost("node2", 9200, "http")
, new HttpHost("node3", 9200, "http")
));
@Override
public void add(JobDetail jobDetail)
// 1. 构建IndexRequest对象,用来描述ES发起请求的数据。
IndexRequest indexRequest = new IndexRequest(JOB_IDX_NAME);
// 2. 设置文档ID。
indexRequest.id(jobDetail.getId() + "");
// 3. 构建一个实体类对象,并使用FastJSON将实体类对象转换为JSON。
String json = JSON.toJSONString(jobDetail);
// 4. 使用IndexRequest.source方法设置请求数据。
indexRequest.source(json, XContentType.JSON);
try
// 5. 使用ES High level client调用index方法发起请求
restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
catch (IOException e)
e.printStackTrace();
System.out.println("索引创建成功!");
@Override
public void update(JobDetail jobDetail) throws IOException
// 1. 判断对应ID的文档是否存在
// a) 构建GetRequest
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, jobDetail.getId() + "");
// b) 执行client的exists方法,发起请求,判断是否存在
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
if(!exists) return;
// 2. 构建UpdateRequest请求
UpdateRequest updateRequest = new UpdateRequest(JOB_IDX_NAME, jobDetail.getId() + "");
// 3. 设置UpdateRequest的文档,并配置为JSON格式
updateRequest.doc(JSON.toJSONString(jobDetail), XContentType.JSON);
// 4. 执行client发起update请求
restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
@Override
public JobDetail findById(long id) throws IOException
// 1. 构建GetRequest请求。
GetRequest getRequest = new GetRequest(JOB_IDX_NAME, id + "");
// 2. 使用RestHighLevelClient.get发送GetRequest请求,并获取到ES服务器的响应。
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
// 3. 将ES响应的数据转换为JSON字符串
String json = response.getSourceAsString();
// 4. 并使用FastJSON将JSON字符串转换为JobDetail类对象
JobDetail jobDetail = JSONObject.parseObject(json, JobDetail.class);
// 5. 设置ID字段
jobDetail.setId(id);
return jobDetail;
@Override
public void deleteById(long id) throws IOException
// 1. 构建delete请求
DeleteRequest deleteRequest = new DeleteRequest(JOB_IDX_NAME, id + "");
// 2. 使用client执行delete请求
restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
@Override
public List<JobDetail> searchByKeywords(String keywords) throws IOException
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery(keywords, "jd", "title");
searchSourceBuilder.query(queryBuilder);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits)
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
return jobDetailList;
@Override
public Map<String, Object> searchByPage(String keywords, int pageNum, int pageSize) throws IOException
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery(keywords, "jd", "title");
searchSourceBuilder.query(queryBuilder);
// 4. 设置SearchSourceBuilder的from和size参数,构建分页
searchSourceBuilder.from(pageNum);
searchSourceBuilder.size(pageSize);
// 4. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 5. 执行RestHighLevelClient.search发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 6. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits)
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
jobDetailList.add(jobDetail);
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
Map<String, Object> result = new HashMap<>();
result.put("total", hits.getTotalHits().value);
result.put("content", jobDetailList);
return result;
@Override
public Map<String, Object> searchByScrollPage(String keywords, String scrollId, int pageSize) throws IOException
SearchResponse searchResponse = null;
if(scrollId == null)
// 1. 构建SearchRequest检索请求
SearchRequest searchRequest = new SearchRequest(JOB_IDX_NAME);
// 2. 创建一个SearchSourceBuilder专门用于构建查询条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3. 使用QueryBuilders.multiMatchQuery构建一个查询条件,并配置到SearchSourceBuilder
MultiMatchQueryBuilder queryBuilder = QueryBuilders.multiMatchQuery(keywords, "jd", "title");
searchSourceBuilder.query(queryBuilder);
searchSourceBuilder.size(pageSize);
// 设置高亮查询
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
highlightBuilder.field("title");
highlightBuilder.field("jd");
searchSourceBuilder.highlighter(highlightBuilder);
// 4. 调用searchRequest.scroll设置滚动快照有效时间
searchRequest.scroll(TimeValue.timeValueMinutes(10));
// 5. 调用SearchRequest.source将查询条件设置到检索请求
searchRequest.source(searchSourceBuilder);
// 6. 执行RestHighLevelClient.search发起请求
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
else
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(TimeValue.timeValueMinutes(10));
searchResponse = restHighLevelClient.scroll(searchScrollRequest, RequestOptions.DEFAULT);
if(searchResponse != null)
// 7. 遍历结果
SearchHits hits = searchResponse.getHits();
List<JobDetail> jobDetailList = new ArrayList<>();
for (SearchHit hit : hits)
// 1) 获取命中的结果
String json = hit.getSourceAsString();
// 2) 将JSON字符串转换为对象
JobDetail jobDetail = JSON.parseObject(json, JobDetail.class);
// 3) 使用SearchHit.getId设置文档ID
jobDetail.setId(Long.parseLong(hit.getId()));
// 1. 获取高亮字段
Map<String, HighlightField> highlightFieldMap = hit.getHighlightFields();
// 1.1 获取title高亮字段
HighlightField titleHl = highlightFieldMap.get("title");
// 1.2 获取jd高亮字段
HighlightField jdHl = highlightFieldMap.get("jd");
// 2. 将高亮字段进行替换普通字段
// 2.1 处理title高亮,判断高亮是否为空,不为空则将高亮Fragment(碎片)拼接在一起,替换原有普通字段
if(titleHl != null)
Text[] fragments = titleHl.getFragments();
StringBuilder stringBuilder = new StringBuilder();
for (Text fragment : fragments)
stringBuilder.append(fragment.string());
jobDetail.setTitle(stringBuilder.toString());
// 2.2 处理jd高亮
if(jdHl != null)
Text[] fragments = jdHl.getFragments();
StringBuilder stringBuilder = new StringBuilder();
for (Text fragment : fragments)
stringBuilder.append(fragment.string());
jobDetail.setJd(stringBuilder.toString());
jobDetailList.add(jobDetail);
// 8. 将结果封装到Map结构中(带有分页信息)
// a) total -> 使用SearchHits.getTotalHits().value获取到所有的记录数
// b) content -> 当前分页中的数据
Map<String, Object> result = new HashMap<>();
result.put("scrollId", searchResponse.getScrollId());
result.put("content", jobDetailList);
return result;
return null;
@Override
public void close()
try
restHighLevelClient.close();
catch (IOException e)
e.printStackTrace();
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于2021年大数据ELK(十四):Elasticsearch编程(基本操作)的主要内容,如果未能解决你的问题,请参考以下文章