Hive数据仓库数据分析
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive数据仓库数据分析相关的知识,希望对你有一定的参考价值。
目录
1 创建数据仓库
我们的目标是在Hive中创建数据仓库,以便利用Hive的查询功能实现交互式数据处理,所以接下来在Hive客户端进行操作。确保Hadoop和mysql服务已经启动后再进入Hive客户端,命令如图10-11所示。
hive

create database sogou;
下面,我们来创建一个外部表,命令如下:
create external table sogou.sogou_20211103(
`time` string,
`uid` string,
`keywords` string,
`rank` int,
`ordering` int,
`url` string)
comment 'This is the sogou search data of one day'
row format delimited
fields terminated by '\\t'
stored as textfile
location '/sogou/20211103';
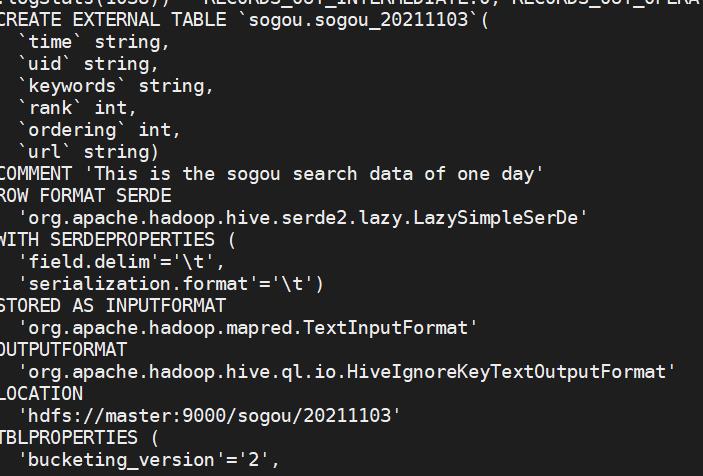
show create table sogou.sogou_20211103;
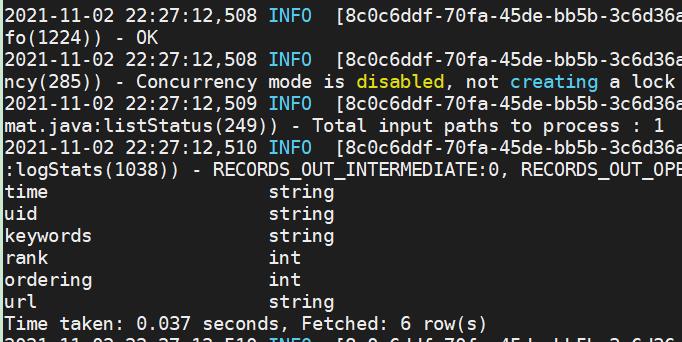
describe sogou.sogou_20211103;
drop table sogou.sogou_20211103;
2 创建Hive分区表
我们正式创建一个外部表,该表包含了扩展字段(即year、month、day、hour),命令如下:
create external table sogou.sogou_ext_20211103(
`time` string,
`uid` string,
`keywords` string,
`rank` int,
`ordering` int,
`url` string,
`year` int,
`month` int,
`day` int,
`hour` int)
comment 'This is the sogou search data extend'
row format delimited
fields terminated by '\\t'
stored as textfile
location '/sogou_ext/20211103';
在上述命令中,特别要注意,“location”后面的“/sogou_ext/20211103”就是我们在前面创建的HDFS目录,并且已经上传了sogou.500w.utf8.flt文件。
接着创建带分区的表,命令如下:
create external table sogou.sogou_partition(
`time` string,
`uid` string,
`keywords` string,
`rank` int,
`ordering` int,
`url` string)
partitioned by (
`year` int,
`month` int,
`day` int,
`hour` int)
row format delimited
fields terminated by '\\t'
stored as textfile;
最后向数据库中导入数据,命令是:
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table sogou.sogou_partition partition(year, month,day,hour) select * from sogou.sogou_ext_20211103;
查询导入数据的命令是:
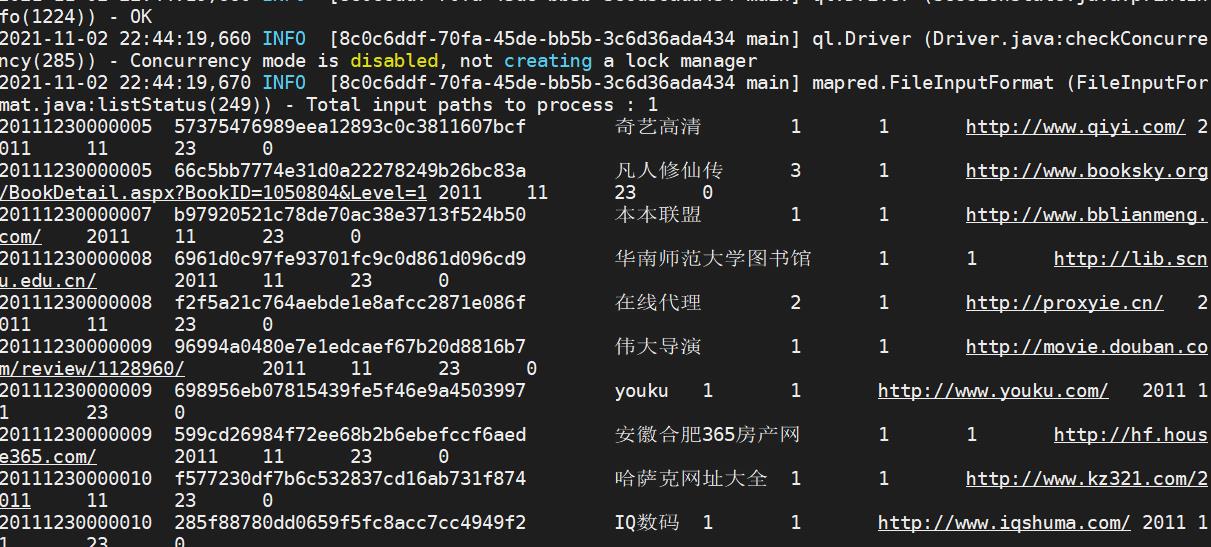
select * from sogou_ext_20211103 limit 10;
其他查询命令还有:
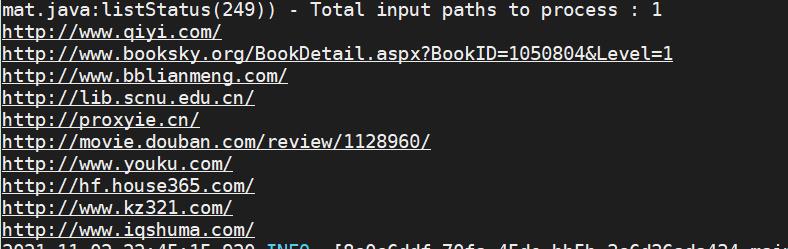
select url from sogou_ext_20211103 limit 10;
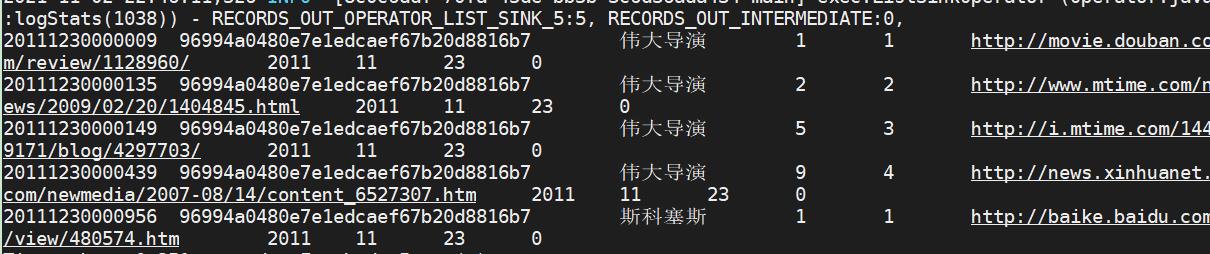
select * from sogou_ext_20211103 where uid='96994a0480e7e1edcaef67b20d8816b7';
3 数据分析
3.1 统计总记录数
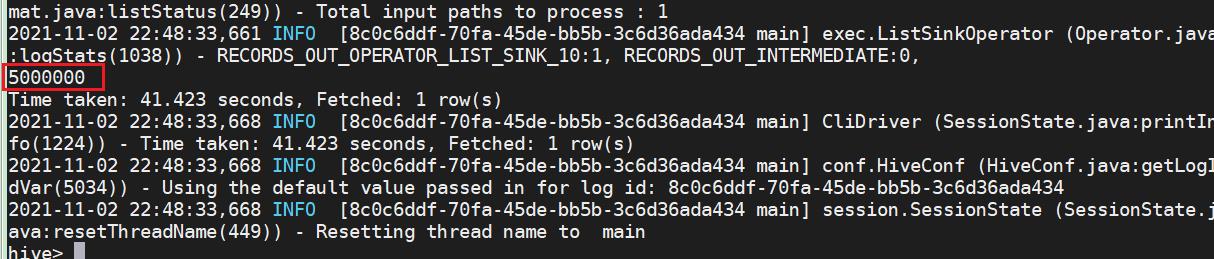
select count(*) from sogou_ext_20211103 ;
3.2 统计非空记录数
select count(*) from sogou_ext_20211103 where keywords is not null and keywords!='';

统计独立uid总数的命令是:
select count(distinct(uid)) from sogou.sogou_ext_20211103 ;
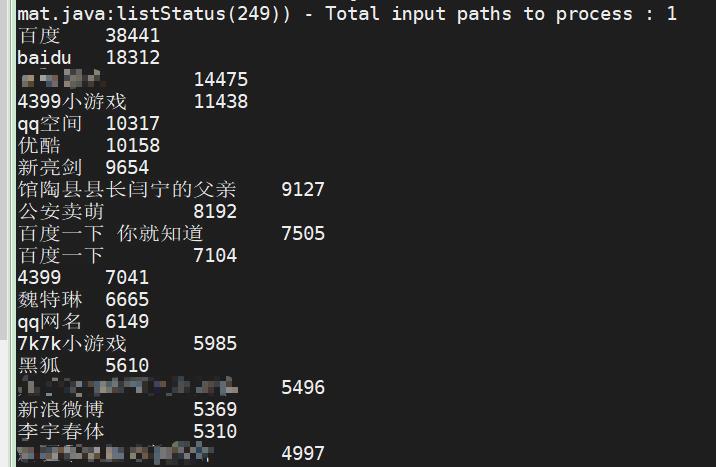
3.3 关键词分析
统计关键词长度的命令是:
select avg(a.cnt) from (select size(split(keywords,'\\\\s+')) as cnt from sogou.sogou_ext_20211103 ) a;
select keywords, count(*) as cnt from sogou.sogou_ext_20211103 group by keywords order by cnt desc limit 20;
频度排名(即频度最高的前20个词)的命令是:
你看看搜狗搜索,搜索最多的是百度.
3.4 uid分析
统计查询次数分布的命令是:
select sum(if(uids.cnt=1,1,0)), sum(if(uids.cnt=2,1,0)), sum (if(uids.cnt=3,1,0)), sum(if(uids.cnt>3,1,0)) from (select uid, count(*) as cnt from sogou.sogou_ext_20211103 group by uid) uids;
统计平均查询次数的命令是:
select sum(a.cnt)/count(a.uid) from (select uid,count(*) as cnt from sogou_ext_20211103 group by uid) a;
统计查询次数大于2次的用户总数的命令是:
select count(a.cnt) from (select uid, count(*) as cnt from sogou.sogou_ext_20211103 group by uid having cnt > 2 ) a;
4 用户行为分析
4.1 单击次数与rank之间的关系
下面我们来计算rank在10以内的单击次数占比。首先执行:
select count(*) from sogou.sogou_ext_20211103 where rank<11;
然后执行:
>select count(*) from sogou.sogou_ext_20161202;

我们知道,用户上网查询往往只会浏览搜索引擎返回结果的前10个项目,也就是位于第一页的内容。这个用户行为说明,尽管搜索引擎返回的结果数目十分庞大,但是真正可能被用户关注的内容往往很少,只有排在最前面的很小部分会被用户浏览到,所以传统的基于全部返回值计算的查全率、查准率的评价方式已经不适应网络信息检索的评价。正确的评价方式应该强调评价指标中有关最靠前的结果与用户查询需求之间的相关性。
我们再来研究直接通过输入URL进行查询的占比:
>select count(*) from sogou.sogou_ext_20211103 where keywords like ‘%www%’;
>select count(*) from sogou.sogou_ext_20211103 ;
实际结果是73979/5000000,等于0.0147958。这个比例是很低的,说明绝大部分用户不会采用URL进行查询。想想也很自然,如果用户知道了URL,完全可以直接在浏览器地址栏输入URL进行查询,没有必要再通过搜索引擎重复一遍。
另外,在通过URL进行的查询中,我们还可以计算用户单击了其输入的URL网址的次数,并计算占比。
select count(*) from sogou.sogou_ext_20211103 where keywords like ‘%www%’;
select count(*) from sogou.sogou_ext_20211103 ;
27561/73979=0.37255167即我们关心的结果。从这个比例可以看出,有37%的用户(因该说是很大一部分)提交了URL进行查询,并且继续单击了查询的结果。这可能是由于用户没有记全URL等原因,而想借助搜索引擎来找到自己想要的网址。因此,这个分析结果就提示我们,搜索引擎在处理这一部分查询请求时,一个可能比较理想的改进方式就是,首先把相关的完整URL返回给用户,这样就有较大可能改善用户的查询体验,满足用户的需求。
4.2 个性化行为分析
例如,如果想知道搜索过“csdn”且次数大于2的uid,可使用下面的命令:
select uid,count(*) as cnt from sogou.sogou_ext_20211103 where keywords='csdn' group by uid having cnt >1;

5 实时数据
在实际应用中,为了实时地显示当天搜索引擎的搜索数据,首先需要创建一些临时表,然后在一天结束后对数据进行处理,并将数据插入临时表中。
- 创建临时表
创建临时表的命令是:
>create table sogou.uid_cnt(uid string, cnt int)
>comment ‘This is the sogou search data of one day’
>row format delimited
>fields terminated by ‘\\t’
>stored as textfile;
- 插入数据
>insert overwrite table sogou.uid_cnt select uid, count(*) as cnt
>from sogou.sogou_ext_20211103 group by uid;
这样前端开发人员就可以访问该临时表,并将数据显示出来,显示方式可以根据实际需要来进行设计,如表格、统计图等。
以上是关于Hive数据仓库数据分析的主要内容,如果未能解决你的问题,请参考以下文章