双11特刊 | 全面云原生化,数据库实例独共享混部 最高降低30%成本
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双11特刊 | 全面云原生化,数据库实例独共享混部 最高降低30%成本相关的知识,希望对你有一定的参考价值。
简介:2021年双十一是阿里巴巴集团的核心应用全面云化的第二年。今年在保证稳定性的前提下,主要探索如何利用云原生的技术优势,降低成本,提升资源利用率。在今年大促中,针对核心集群采用独享共享实例混部,统一了底层资源,结合交易业务云盘化使得混部单元大促成本下降30%+。
引言
2021年双十一是阿里巴巴集团的核心应用全面云化的第二年。今年在保证稳定性的前提下,主要探索如何利用云原生的技术优势,降低成本,提升资源利用率。在今年大促中,针对核心集群采用独享共享实例混部,统一了底层资源,结合交易业务云盘化使得混部单元大促成本下降30%+。
云原生数据库管控
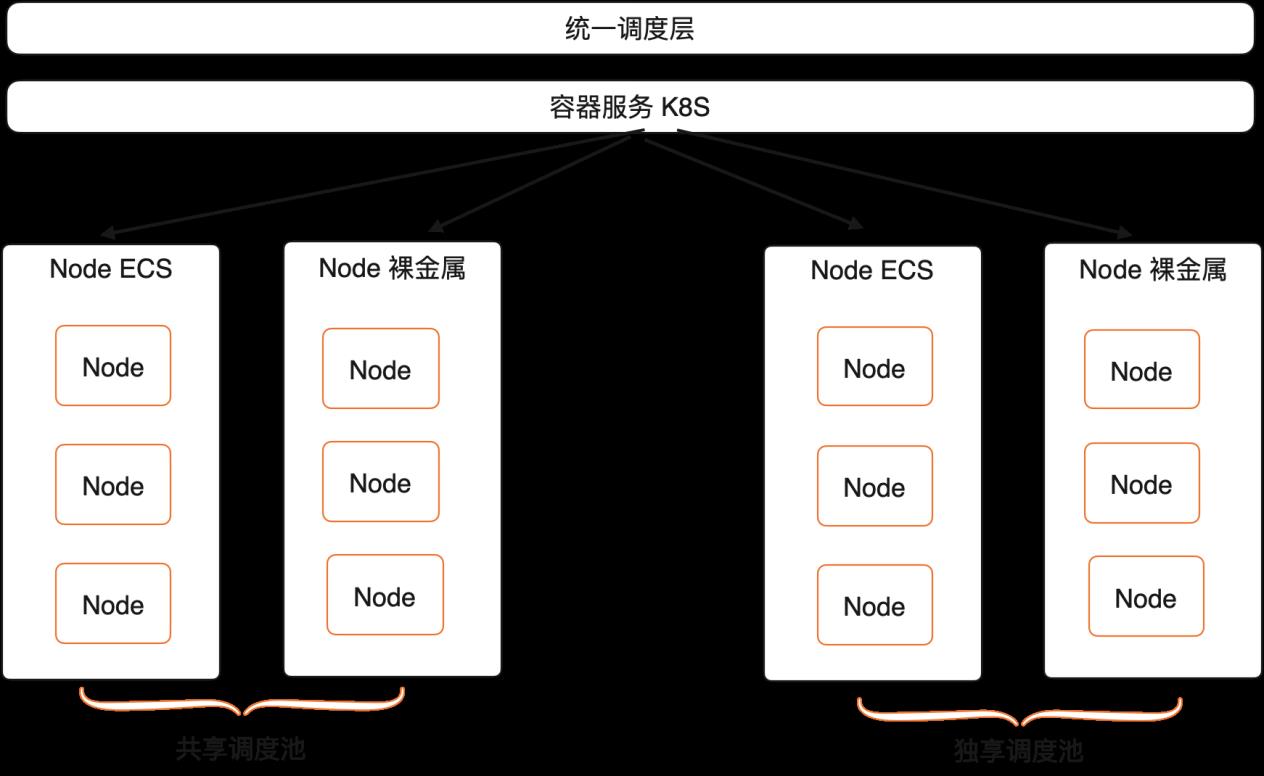
随着云原生技术的普及,越来越多的应用开始运行在Kubernetes上,Kubernetes有一统应用交付界面的趋势。数据库产品内部也在全面推进云原生,期望通过资源池化及与云基础设施深度集成释放数据库产品能力,数据库管控本全面基于Kubernetes来编排DB实例。由于单一的Kubernetes集群规模限制无法满足DB实例的部署规模,所以我们设计了一套多集群的调度编排系统,能够支持多个Kubernetes集群的资源调度。
接入Kubernetes集群的Node,数据库不同的产品会在以下2种模式下根据业务特定自行选择:
- 单实例独占ECS Node:节点实例独占,资源调度工作有ECS完成,特点是节点间隔离性较好,但是由于ECS的资源严格限制,也导致了一些在稳定性和性能的问题
- ECS资源池模式:数据库团队维护一个由较大规格的ECS组成的资源池,由数据库的二次调度在资源池内进行调度。特点是可以在多Pod间协调资源,提升产品的稳定性和性能。
对于第二种,构建ECSPool由数据库团队进行二次调度的场景下,要求采用cgroup隔离组的模式进行实例Pod的资源限制,对于云上的客户而言,存在两种实例形态:
- 独享:采用cgroup里面cpu-set的模式来进行cpu资源的绑定
- 共享:采用cgroup隔离组的里面的cpu-share来进行资源隔离,并一定程度上镜像cpu资源的超卖。
底层的ECS资源池会根据两种不同隔离模式严格划分,分为独占资源池和共享资源池。某一个Node,一旦分配了独享实例就不再允许分配共享实例,严格划分了两个独立的资源池。
一般情况下,资源池由阿里云数据库团队来进行统一调度。由于节点池足够大,区分不同的资源池并不会产生资源利用不佳的情况。但对于服务于企业级的客户而言,由于不与其他客户进行混合部署,这种严格区分的模式资源利用率就不是最佳。举个例子:客户由4个实例,2个采用共享模式,2个需要采用独占模式;按照之前的调度逻辑,客户则必须采购4台机器才能完成实例的部署。因此,为了解决上面的问题,我们希望能够将核心实例和非核心实例混部部署在同一台机器上。同时核心实例采用CPUSet的方式保证独享部分CPU核心,非核心实例采用CPUShare的方式共享剩余的CPU核心,实现资源的充分利用。
CPUSet和CPUShare模式混部方案
独享共享混部的前提是独享实例的性能不受影响,因为必须对共享实例使用的资源进行限制。在Kubernetes中,通过cgroup可以限制pod可以使用的cpu和memory的上下限。其中,对于内存的限制比较简单,给pod设置一个内存最大可用内存,一旦超过内存上限就会触发OOM。对于cpu的限制,Kubernetes采用cfs quota来限制进程在单位时间内可用的时间片。当独享和共享实例在同一台node节点上的时候,一旦实例的工作负载增加,可能会导致独享实例工作负载在不同的cpu核心上来回切换,影响独享实例的性能。所以,为了不影响独享实例的性能,我们希望在同一个node上,独享实例和共享实例的cpu能够分开绑定,互不影响。
Kubernetes原生混部实现
在linux中,通过cgroup的cpuset子系统可以实现绑定进程到指定的CPU上面,docker也有相关的启动参数来支持绑定容器到指定的CPU上。
--cpuset-cpus="" CPUs in which to allow execution (0-3, 0,1) --cpuset-mems="" Memory nodes (MEMs) in which to allow execution (0-3, 0,1). Only effective on NUMA systems.
Kubernetes 从1.8版本以后,提供了CPU Manager特性来支持cpuset的能力。从Kubernetes 1.12版本开始到目前的1.22版本,该特性还是Beta版。CPU Manager是kubelet中的一个模块,主要工作就是给某些符合绑核策略的containers绑定到指定的cpu上,从而提升这些CPU敏感型任务的性能。
目前CPU Manager支持两种Policy,分别为none和static,通过kubelet --cpu-manager-policy设置,未来会增加dynamic policy做Container生命周期内的cpuset动态调整。
none: 为cpu manager的默认值,相当于没有启用cpuset的能力。cpu request对应到cpu share,cpu limit对应到cpu quota。 static: 允许为节点上具有某些资源特征的 pod 赋予增强的 CPU 亲和性和独占性。kubelet将在Container启动前分配绑定的cpu set,分配时还会考虑cpu topology来提升cpu affinity
static策略管理一个共享CPU资源池,最初该资源池包含节点上所有的CPU资源。可用的独占性CPU资源数量等于节点的CPU总量减去通过 --kube-reserved 或 --system-reserved 参数保留的CPU 。从1.17版本开始,CPU保留列表可以通过 kublet 的 '--reserved-cpus' 参数显式地设置。 通过 '--reserved-cpus' 指定的显式CPU列表优先于使用 '--kube-reserved' 和 '--system-reserved' 参数指定的保留CPU。 通过这些参数预留的 CPU是以整数方式,按物理内 核 ID 升序从初始共享池获取的。 共享池是 BestEffort 和 Burstable pod 运行 的 CPU集合。Guaranteed pod中的容器,如果声明了非整数值的CPU requests,也将运行在共享池的CPU上。只有Guaranteed pod中指定了整数型CPUrequests 的容器,才会被分配独占CPU资源。
Kubernetes作为通用的容器编排平台,其提供的绑核功能,具有一定的局限性:
- 需要显示开启,且pod的QoS必须是Guaranteed级别,数据库实例资源超卖,pod的request和limit设置不同。
- kubelet的CPU分配策略固定且不支持灵活扩展,不能满足独共享混部的调度场景。
-
不支持动态放开绑核限制。在大促的时候,为了提高数据库性能,有时需要临时放开实例的资源限制,kubelet不支持放开绑核。
调度平台混部实现方案
Kubernetes默认的绑核能力,其中绑核策略是放在kubelet里面,不易修改和扩展,而针对不同的业务场景,绑核策略可能不同,放在调度测统一管理更加合适。由于kubelet仅负责执行绑核,而具体的绑核策略需要由上层业务来指定;因此在创建CPUSet模式的pod的时候,我们给pod打上annotaion,kubelet在启动容器之前,就会将pod绑定指定的CPU上。
annotations:
alloc-spec: |
"cpu": "Spread"
alloc-status: '"cpu":[0,1]'
alloc-spec:指定具体的分配策略,支持以下几种模式:
- Spread:在物理核上打散绑定逻辑核,在同物理核对端的逻辑上适宜放置压力小的应用,统一调度也提供了应用间物理核堆叠约束的编排算法。
- SameCoreFirst:同物理核绑定优先,尽量讲逻辑核分配在相同的物理核上。
- BindAllCPUs:绑定所有的 CPU 核。
alloc-status:绑定的具体cpu核数。
当调度器在节点上分配或者释放 CPUSet 模式的 Pod 之后,CPUShare Pod 可使用的 CPU 核数量将发生变化,可以通过修改节点的annotation来告知 kubelet可share节点的范围:
kind: Node
metadata:
name: xx
annotations:
cpu-sharepool: '"cpuIDs":[0,1,2,3,4,5,6,99,100,101,102,103]'
要实现独享共享混部,只需要给独享实例指定为CPUSet模式,共享实例指定为CPUShare模式,就可以实现共享和独享实例CPU分开绑定,互不干扰。但该方案有以下限制:对Kubernetes原生的kubelet组件进行了定制开发,这就限制了在通用环境下的部署。
基于调度器和扩展控制器的混部实现方案
上面分析了Kubernetes原生和调度平台的混部实现方案。从分析结果看,都无法完全满足数据库这边对于实现独享共享混部方案的绑核需求,我们希望在不修改Kubernetes源码的基础上,能够支持不同的绑核策略。
在介绍我们的实现方案前,先介绍下混部在数据库管控架构下主要涉及到的三个组件。
- 调度器:调度器具有全局的资源视图,能够根据业务指定的调度策略,分配不同的CPU核心。当前支持的CPU调度策略包括:独共享、NUMA亲和性和反亲和性,IO多队列分布等
- 控制器:负责将调度器分配的CPU核心设置到pod的annotation上,并对业务提供查询接口
- cgroup-controller:以daemonset的方式部署在每个node节点上,watch本节点的pod资源,当发现pod的annotation上有绑核信息时,修改pod对应的cgroup cpuset配置,完成绑核。
这套架构和原生Kubernetes集群相比,最大的区别有两个地方,第一:多Kubernetes集群调度,解决数据库规模化对单集群的约束;第二:数据库资源调度与实例创建逻辑解耦,资源调度发生在pod的创建之前。在实例创建的时候,先通过调度器调度分配资源,成功后,业务才会发起任务流拉起实例。
调度器
调度器的核心流程和Kubernetes调度器流程类似(Filter -> Ranker -> Assume -> Process pod)
- Filter : 过滤不符合要求的Node
- Ranker : 计算Node分值并选择分值最高的Node
- Sync Process Pod :异步处理资源申请(云盘、安全组、ENI等)
在独共享混部中,调度器负责为独享实例分配具体的CPU核心,CPU核心的分配策略支持业务自定义。在集团的独共享混部场景中,主要实现了以下逻辑流程:
Node CPU data/state初始化和同步
IO队列分布信息和具体的物理机型号有关,node节点在上线的时候,会由将node的IO队列信息打到node的annotation上,调度器会watch到node节点的IO队列信息,并进行有效性校验并初始化。当调度器会watch到annotation变化,且满足以下两个条件会更新CPU信息。
- CPU是弹升
- 原IO队列CPU分布和新的IO队列相同CPU分布完全一致
独享实例绑核IO队列打散
在选择独享实例CPU核心的时候,会考虑按IO队列打散。

打散策略依赖node的cpu分配优先级(上图箭头指向是优先级由高到低)
混部Filter编排
调度器解耦不同Filter,以插件化编排的方式实现定义不同业务的Pipline
应用维度全部做反亲和处理
无论独享还是共享,同一应用在同一台机器上只有1个节点,确保集群维度在单机故障时的影响最多1/N
resourceSet.spec.scheduleConfig.policy.machineMaxList.N.key = $APP_NAME resourceSet.spec.scheduleConfig.policy.machineMaxList.N.value = 1
申请一个inver业务的Pod(machineMaxKey=inve、value=1)过程如下
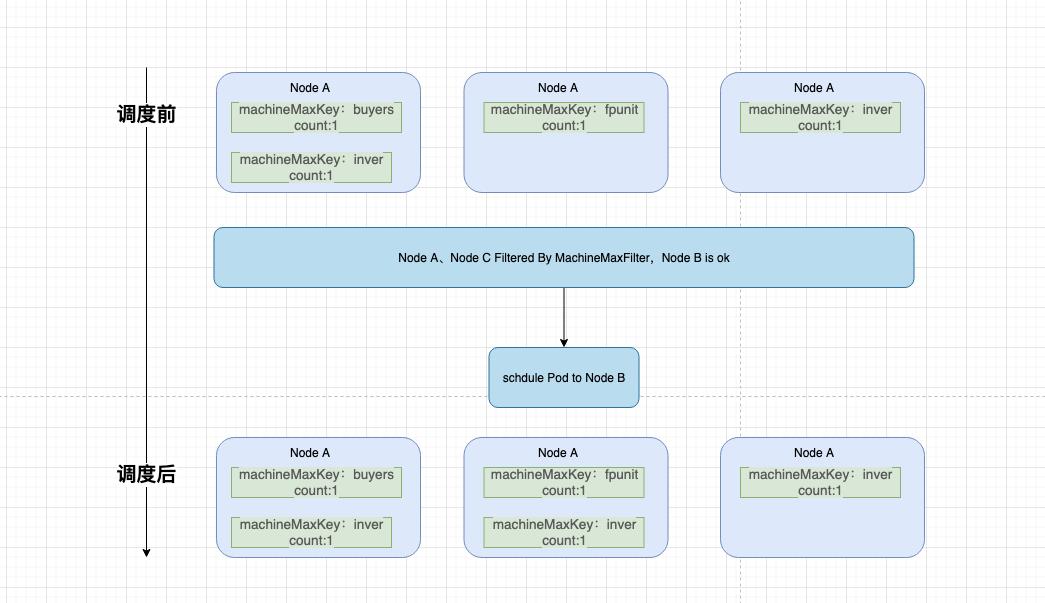
共享独享CPU混合调度
未分配的主机(104C),预留8C,最大可分配是96C。调度两个32C的共享实例,再释迁移一个32C的共享实例流程如下图

单个ECS独享实例可售最大CPU比例为2/3:即96核物理CPU可售卖的最大独享CPU为64核,剩余32核按固定超卖比超卖给其他实例 (独享实例不可占用整台机器)

可售独享实例CPU计算: 可售CPU=min(a,b)
a. 可售CPU规格=单机可售物理CPU-max(共享实例规格)*2
b. 可售CPU规格 = 【单机可售CPU - sum(共享实例已售CPU)】/超卖比
控制器
控制器为业务屏蔽了底层Kubernetes资源接口,业务所有的操作全部由控制器来统一进行转换。在独共享混部方案里面,控制器负责将调度器分配的绑核信息更新到pod的annotation上,并在pod启动的时候校验启动的绑核信息是否正确。同时在大促场景中,一旦独享实例出现性能瓶颈,需要能够临时占用整机的cpu资源,控制器负责向业务提供临时放开CPU绑核的限制的接口。
#独享实例pod需要指定的annotation
annotations:
cpu-isolate-mode: exclusive #指定为独享实例
custom-cgroup-info: '"engine":"cpuset":"2-3"' #指定具体容器绑定的cpu核心
exclude-reserve-cpuset: "true" #是否需要扣除node上预留的cpu核心
release-isolate-mode: "true" #是否需要临时放开绑核限制,如果设置了可以绑定除了预留所有cpu核心,大促时候的应急预案
cgroup-controller
cgroup-controller是Kubernetes里面的一个扩展控制器,它通过daemonset的方式部署在Kubernetes集群里面,它将宿主机上的/sys/fs/cgroup/目录挂载到容器内,在watch到pod需要绑核时,根据pod的qos等级,找到对应的cgroup配置路径,直接修改cgroup的配置文件。
volumes:
- hostPath:
path: /var/run/
type: "Directory"
name: docker-sock
- hostPath:
path: /sys/fs/cgroup/
type: "Directory"
name: cgroups
在独共享混部的方案里面,cgroup-controller除了需要能够为独享实例绑定CPU核心以外,还需要维护共享实例的CPU资源池。cgroup-controller会记录当前节点上独享CPU和共享CPU的核心分布,当节点上的独享实例发生变化时,动态调整node上共享pod的可用的CPU列表。例如,当前node节点预留CPU:[0-1],调度了一个独享实例占用CPU:[2-3],cgroup-controller会计算当前node节点上的共享CPU=总的CPU-node预留-独享CPU,并将共享pod全部绑定到共享CPU核心上。当再调度一个独享pod,cgroup-controller会更新共享CPU核心,并刷新主机上所有共享POD绑定的CPU核心。
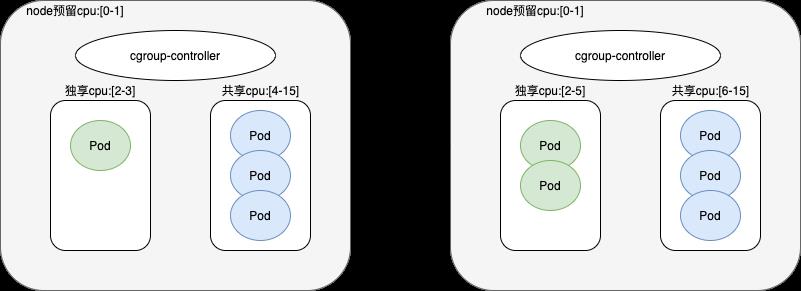
cgroup-controller通过直接修改pod的cgroup配置来实现动态调整pod的资源配额,虽然不需要浸入kubernetes源码,但也存在以下几个问题:
- cgroup-controller只能在容器启动后,才能修改容器的资源配额
- 当独享实例发现变化时,会动态刷新共享实例的CPU绑核,对共享实例的性能可能存在一定的影响
cgroup-controller能够直接操作DB实例cgroup的资源限额,能够直接影响DB实例的数据面,所以在具体执行修改时会做一些必要的安全检查。比如在设置独享实例的绑定的CPU时,会校验绑定的核心是否满足IO队列分布,绑定的CPU核心是否超过单节点可售卖独享CPU的核心数等。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于双11特刊 | 全面云原生化,数据库实例独共享混部 最高降低30%成本的主要内容,如果未能解决你的问题,请参考以下文章
双11特刊 | 全面云原生化,数据库实例独共享混部 最高降低30%成本
双11特刊|一站式在线数据管理平台DMS技术再升级,高效护航双11
我们如何实现“业务 100% 云原生化,让阿里中间件全面升级到公共云架构”?