分布式文件系统 HDFS
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式文件系统 HDFS相关的知识,希望对你有一定的参考价值。
课程目标:
- 知道什么是hdfs
- 说出hdfs的架构
- 能够掌握hdfs的环境搭建
- 能够掌握hdfs shell的基本使用
- 知道hdfs shell的优缺点
HDFS的使用
-
启动HDFS
- 来到$HADOOP_HOME/sbin目录下
- 执行start-dfs.sh
[hadoop@hadoop00 sbin]$ ./start-dfs.sh- 可以看到 namenode和 datanode启动的日志信息
Starting namenodes on [hadoop00] hadoop00: starting namenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-namenode-hadoop00.out localhost: starting datanode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-datanode-hadoop00.out Starting secondary namenodes [0.0.0.0] 0.0.0.0: starting secondarynamenode, logging to /home/hadoop/app/hadoop-2.6.0-cdh5.7.0/logs/hadoop-hadoop-secondarynamenode-hadoop00.out- 通过jps命令查看当前运行的进程
[hadoop@hadoop00 sbin]$ jps 4416 DataNode 4770 Jps 4631 SecondaryNameNode 4251 NameNode- 可以看到 NameNode DataNode 以及 SecondaryNameNode 说明启动成功
-
通过可视化界面查看HDFS的运行情况
- 通过浏览器查看 主机ip:50070端口
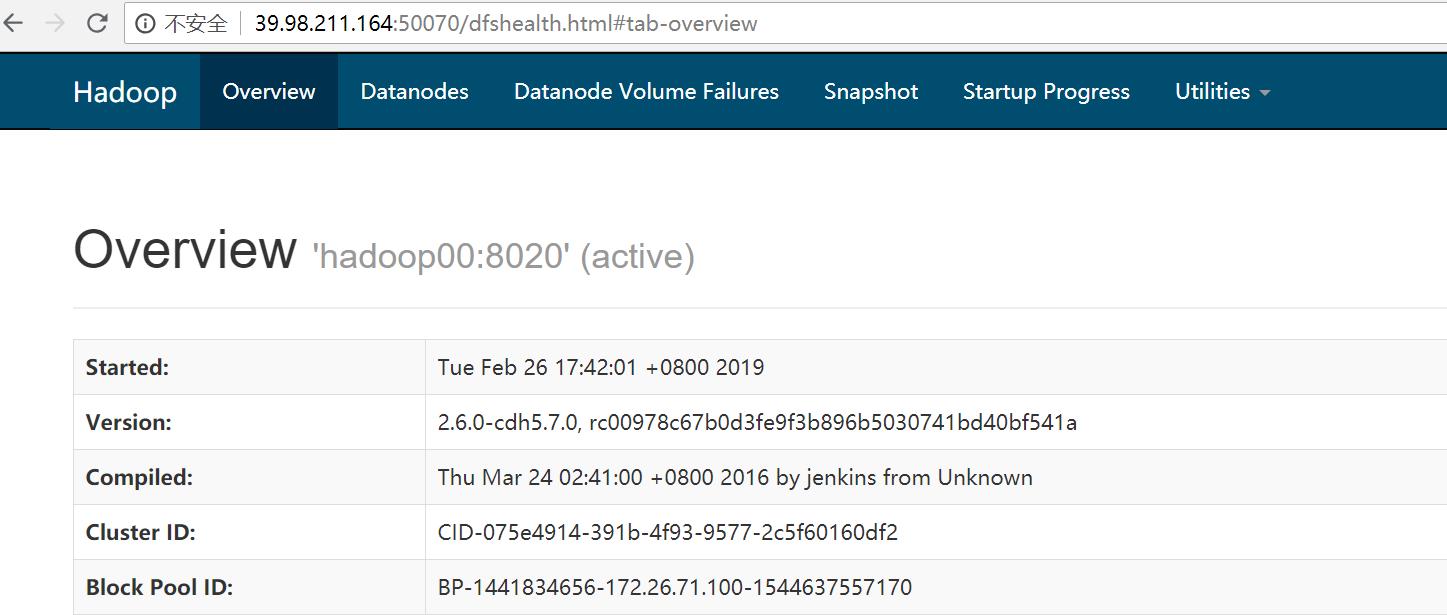
- Overview界面查看整体情况
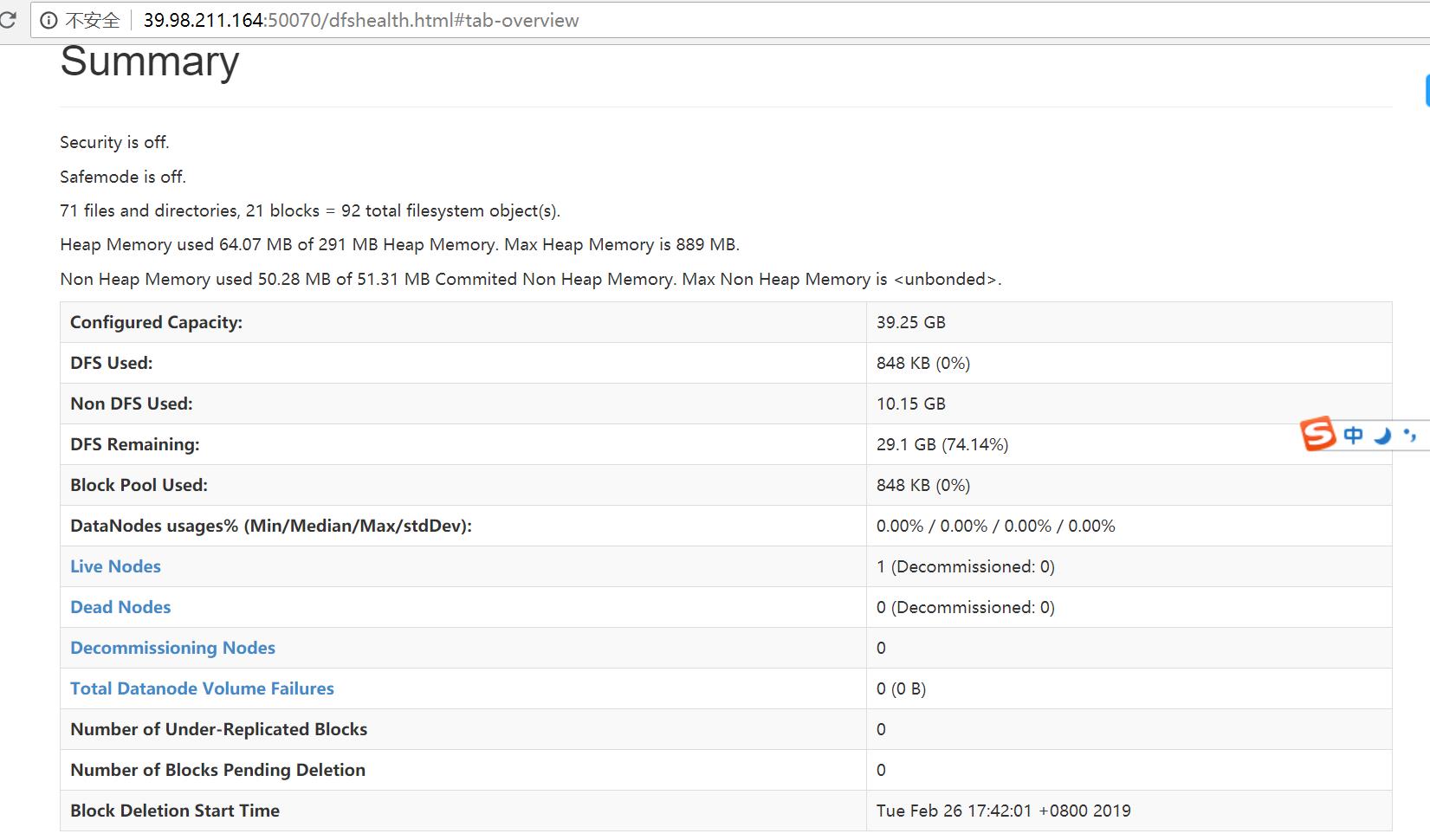
- Datanodes界面查看datanode的情况

HDFS shell操作
-
调用文件系统(FS)Shell命令应使用 bin/hadoop fs 的形式
-
ls
使用方法:hadoop fs -ls
如果是文件,则按照如下格式返回文件信息:
文件名 <副本数> 文件大小 修改日期 修改时间 权限 用户ID 组ID
如果是目录,则返回它直接子文件的一个列表,就像在Unix中一样。目录返回列表的信息如下:
目录名修改日期 修改时间 权限 用户ID 组ID
示例:
hadoop fs -ls /user/hadoop/file1 /user/hadoop/file2 hdfs://host:port/user/hadoop/dir1 /nonexistentfile
返回值:
成功返回0,失败返回-1。 -
text
使用方法:hadoop fs -text
将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
-
mv
使用方法:hadoop fs -mv URI [URI …]
将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
示例:- hadoop fs -mv /user/hadoop/file1 /user/hadoop/file2
- hadoop fs -mv hdfs://host:port/file1 hdfs://host:port/file2 hdfs://host:port/file3 hdfs://host:port/dir1
返回值:
成功返回0,失败返回-1。
-
put
使用方法:hadoop fs -put …
从本地文件系统中复制单个或多个源路径到目标文件系统。也支持从标准输入中读取输入写入目标文件系统。
- hadoop fs -put localfile /user/hadoop/hadoopfile
- hadoop fs -put localfile1 localfile2 /user/hadoop/hadoopdir
- hadoop fs -put localfile hdfs://host:port/hadoop/hadoopfile
- hadoop fs -put - hdfs://host:port/hadoop/hadoopfile
从标准输入中读取输入。
返回值:
成功返回0,失败返回-1。
-
rm
使用方法:hadoop fs -rm URI [URI …]
删除指定的文件。只删除非空目录和文件。请参考rmr命令了解递归删除。
示例:- hadoop fs -rm hdfs://host:port/file /user/hadoop/emptydir
返回值:
成功返回0,失败返回-1。
-
-
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
HDFS shell操作练习
-
在centos 中创建 test.txt
touch test.txt -
在centos中为test.txt 添加文本内容
vi test.txt -
在HDFS中创建 hadoop001/test 文件夹
hadoop fs -mkdir -p /hadoop001/test -
把text.txt文件上传到HDFS中
hadoop fs -put test.txt /hadoop001/test/ -
查看hdfs中 hadoop001/test/test.txt 文件内容
hadoop fs -cat /hadoop001/test/test.txt -
将hdfs中 hadoop001/test/test.txt文件下载到centos
hadoop fs -get /hadoop001/test/test.txt test.txt -
删除HDFS中 hadoop001/test/
hadoop fs -rm -r /hadoop001
HDFS设计思路
- 分布式文件系统的设计思路:

- HDFS的设计目标
- 适合运行在通用硬件(commodity hardware)上的分布式文件系统
- 高度容错性的系统,适合部署在廉价的机器上
- HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用
- 容易扩展,为用户提供性能不错的文件存储服务
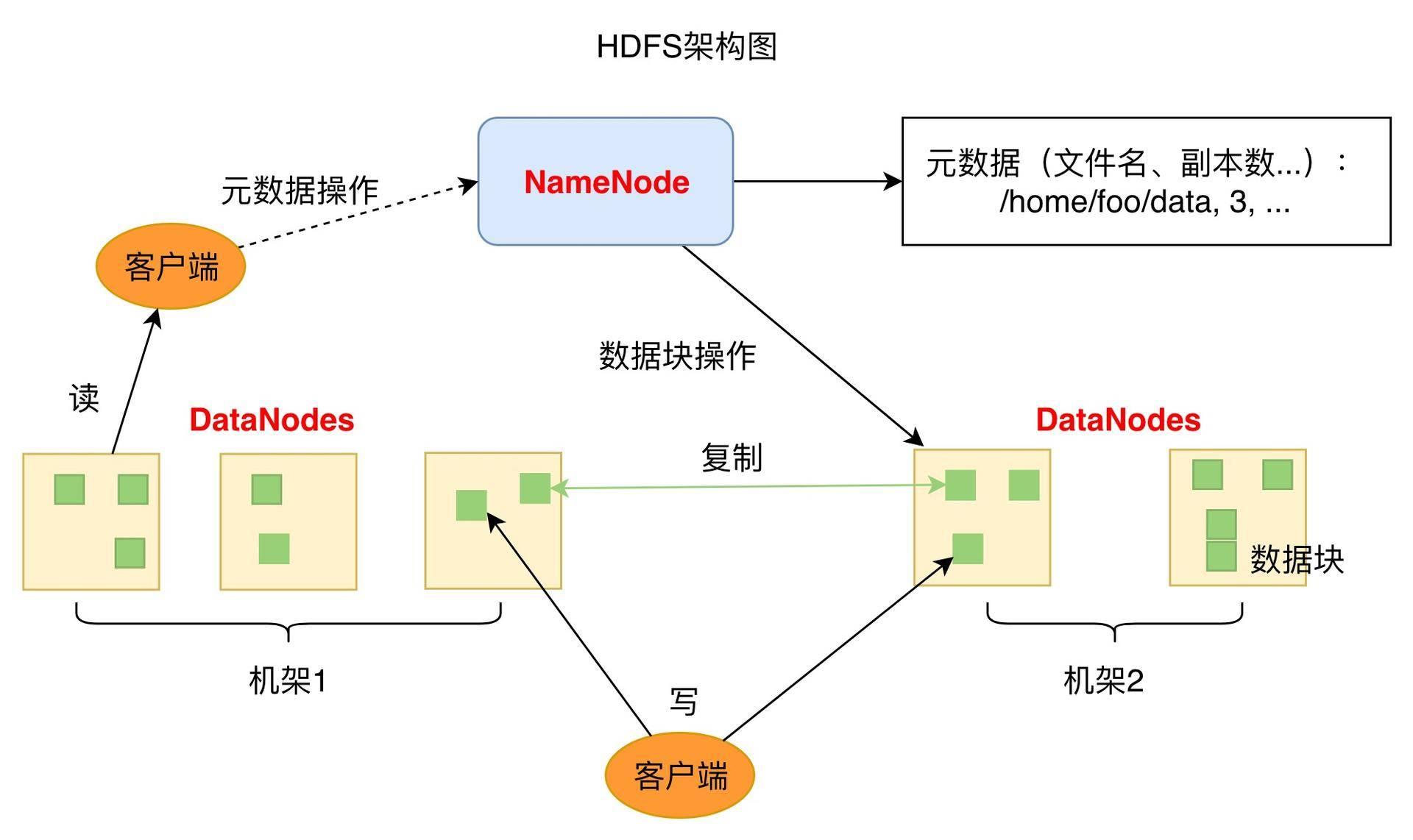
HDFS架构
- 1个NameNode/NN(Master) 带 DataNode/DN(Slaves) (Master-Slave结构)
- 1个文件会被拆分成多个Block
- NameNode(NN)
- 负责客户端请求的响应
- 负责元数据(文件的名称、副本系数、Block存放的DN)的管理
- 元数据 MetaData 描述数据的数据
- 监控DataNode健康状况 10分钟没有收到DataNode报告认为Datanode死掉了
- DataNode(DN)
- 存储用户的文件对应的数据块(Block)
- 要定期向NN发送心跳信息,汇报本身及其所有的block信息,健康状况
- 分布式集群NameNode和DataNode部署在不同机器上
- HDFS优缺点
- 优点
- 数据冗余 硬件容错
- 适合存储大文件
- 处理流式数据
- 可构建在廉价机器上
- 缺点
- 低延迟的数据访问
- 小文件存储
- 优点
HDFS环境搭建
-
下载jdk 和 hadoop 放到 ~/software目录下 然后解压到 ~/app目录下
tar -zxvf 压缩包名字 -C ~/app/ -
配置环境变量
vi ~/.bash_profile export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91 export PATH=$JAVA_HOME/bin:$PATH export HADOOP_HOME=/home/hadoop/app/hadoop...... export PATH=$HADOOP_HOME/bin:$PATH #保存退出后 source ~/.bash_profile -
进入到解压后的hadoop目录 修改配置文件
-
配置文件作用
- core-site.xml 指定hdfs的访问方式
- hdfs-site.xml 指定namenode 和 datanode 的数据存储位置
- mapred-site.xml 配置mapreduce
- yarn-site.xml 配置yarn
-
修改hadoop-env.sh
cd etc/hadoop vi hadoop-env.sh #找到下面内容添加java home export_JAVA_HOME=/home/hadoop/app/jdk1.8.0_91- 修改 core-site.xml 在 节点中添加
<property> <name>fs.default.name</name> <value>hdfs://hadoop000:8020</value> </property>- 修改hdfs-site.xml 在 configuration节点中添加
<property> <name>dfs.namenode.name.dir</name> <value>/home/hadoop/app/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hadoop/app/tmp/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>1</value> </property>- 修改 mapred-site.xml
- 默认没有这个 从模板文件复制
cp mapred-site.xml.template mapred-site.xml 在mapred-site.xml 的configuration 节点中添加
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>- 修改yarn-site.xml configuration 节点中添加
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
-
来到hadoop的bin目录
./hadoop namenode -format (这个命令只运行一次) -
启动hdfs 进入到 sbin
./start-dfs.sh -
启动启动yarn 在sbin中
加油!
感谢!
努力!
以上是关于分布式文件系统 HDFS的主要内容,如果未能解决你的问题,请参考以下文章