Hadoop伪分布构建(保姆式教程)
Posted 小镭敲代码
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop伪分布构建(保姆式教程)相关的知识,希望对你有一定的参考价值。
1、新建一个虚拟机,可参考这篇,有详细的过程
(92条消息) Hadoop 新建一个虚拟机详细步骤(保姆式教程)_小镭敲代码的博客-CSDN博客
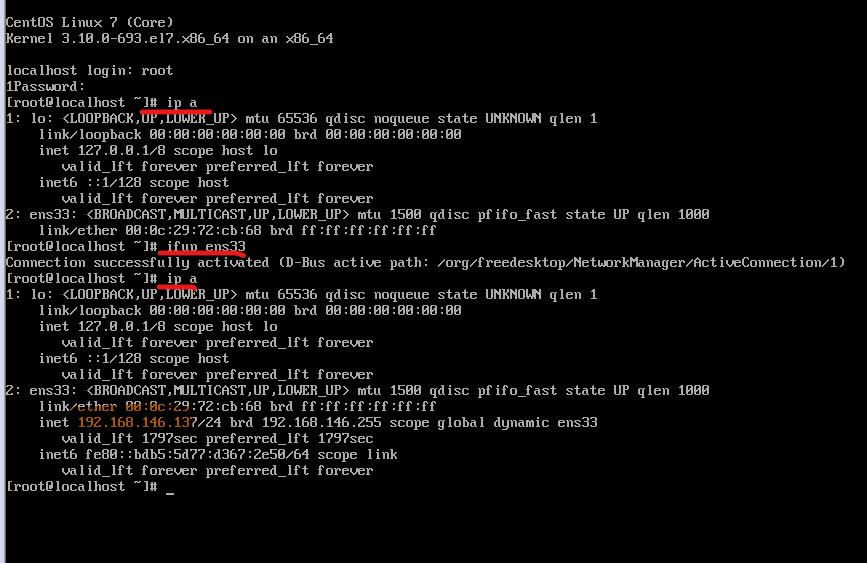
2、 查看虚拟机的IP地址
ip a
ifup ens33
ip a
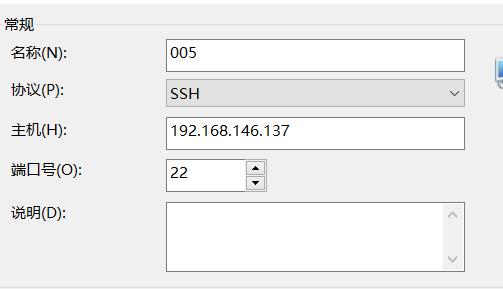
在Xshell里面新建一个会话
3、配置java环境
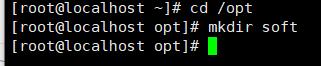
现在/opt里创建一个soft文件
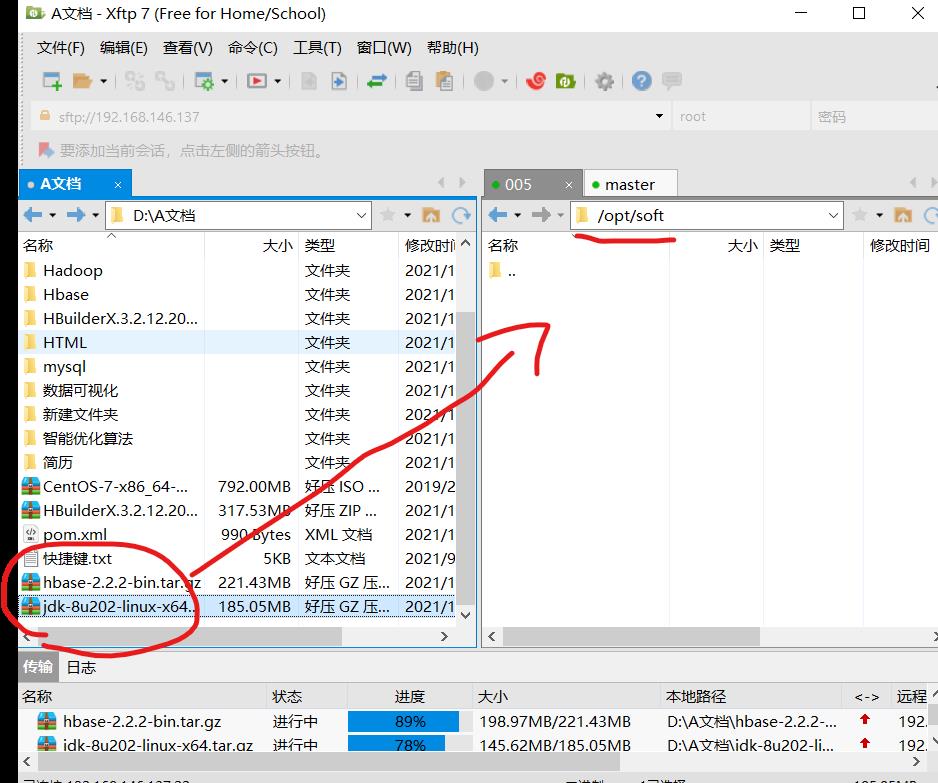
(1)上传 jdk 压缩文件到 soft 目录。
(2)解压 jdk 压缩文件到 opt 目录,并将 jdk1.8.0_112 目录变为 jdk。
cd /opt
tar -zxvf soft/jdk-8u112-linux- x64.tar.gzmv jdk1.8.0_112/ jdk


(3)在 hadoop-eco.sh 中添加相关内容后,保存并退出。
输入:vi /etc/profile.d/hadoop-eco.sh
JAVA_HOME=/opt/jdk
PATH=$JAVA_HOME/bin:$PATH
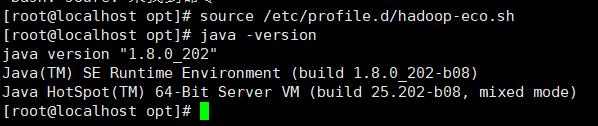
输入:source /etc/profile.d/hadoop-eco.sh (保存并使环境生效)
输入:java -version(查看java是否配置成功)
4、配置hadoop环境(前部分大致和配置java环境一样)
1)上传 Hadoop 压缩文件到 soft 目录
2)解压 Hadoop 压缩文件到 opt 目录,并将Hadoop.2.7.1 目录变为 Hadoop
cd /opt
tar –zxvf soft/hadoop.2.7.1.tar.gz
mv hadoop.2.7.1/ hadoop
配置hadoop环境变量
(3)输入:vi /etc/profile.d/hadoop-eco.sh
在 hadoop-eco.sh 中追加相关内容后,保存并退出。追加的内容如下:
HADOOP_HOME=/opt/hadoop
PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(4)输入:source /etc/profile.d/hadoop-eco.sh

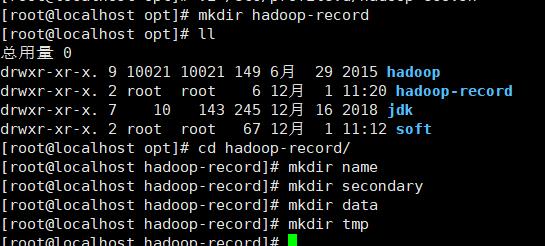
(5) 在创建分布式时,需先手动创建 Hadoop 工作需要的目录
(a)NameNode 数据存放目录为 /opt/hadoop-record/name。
(b)SecondaryNameNode 数据存放目录为 /opt/hadoop-record/secondary。
(c)DataNode 数据存放目录为 /opt/hadoop-record/data。
(d)临时数据存放目录为 /opt/hadoop-record/tmp。
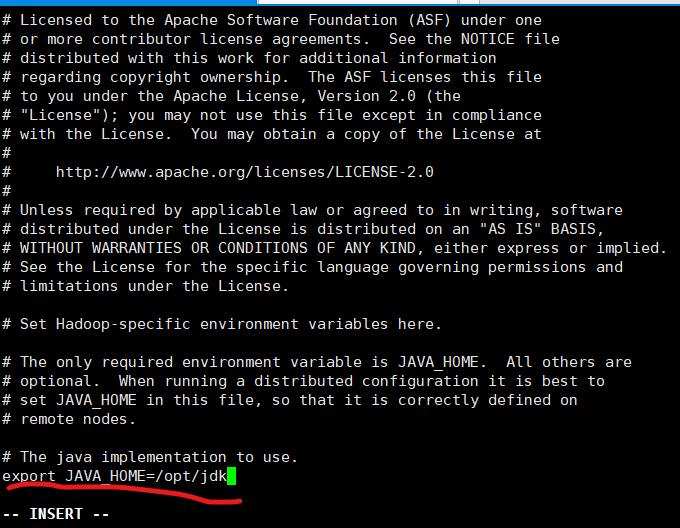
(6)hadoop-env.sh 的配置:
修改 JAVA_HOME 的地址为 exprot JAVA_HOME=/opt/jdk
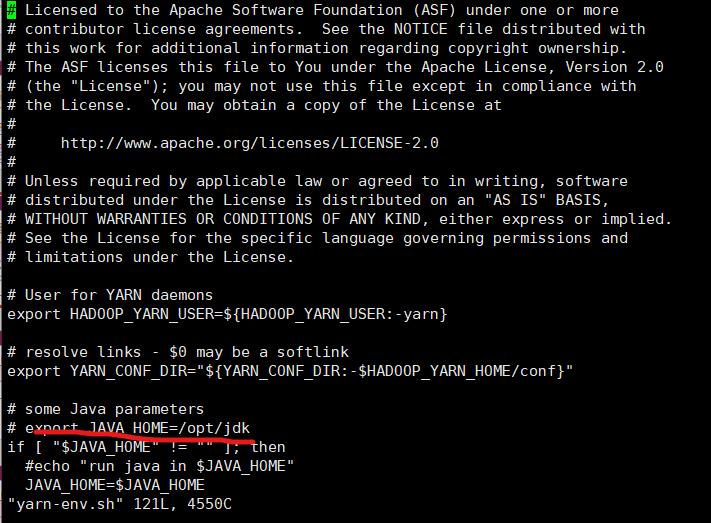
(7)yarn-env.sh 的配置:
修改 JAVA_HOME 的地址为 exprot JAVA_HOME=/opt/jdk
(8)core-site.xml 的配置:
<configuration>
<!--NameNode 结点的 URI-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>file:///opt/hadoop-record/tmp</value>
</property>
</configuration>(9)mapred-site.xml的配置:
<configuration>
<property>
<!--mapreduce 运行的平台,默认 Local-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(10)hdfs-site.xml 的配置
<configuration>
<property>
<!-- 数据副本数量 -->
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<!-- namenode 数据存放地址 -->
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop-record/name</value>
</property>
<property>
<!-- datanode 数据存放地址 -->
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop-record/data</value>
</property>
</configuration>(11)yarn-site.xml 的配置
<configuration>
<property>
<!--resourcemanager 所在的机器 -->
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<!-- 所需要的服务 -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
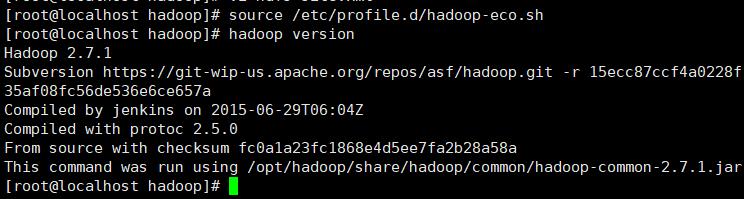
</configuration>(12)查看hadoop安装成功
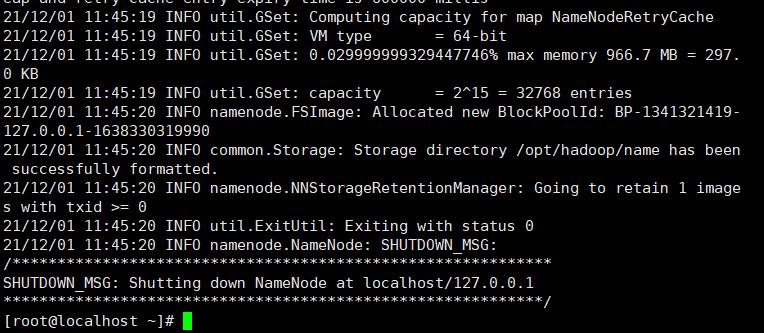
5、启动hadoop
格式化 NameNode——hdfs namenode -format
启动 HDFS——start-dfs.sh
移动YARN——start-yarn.sh
浏览器IP——50070

6、配置免密
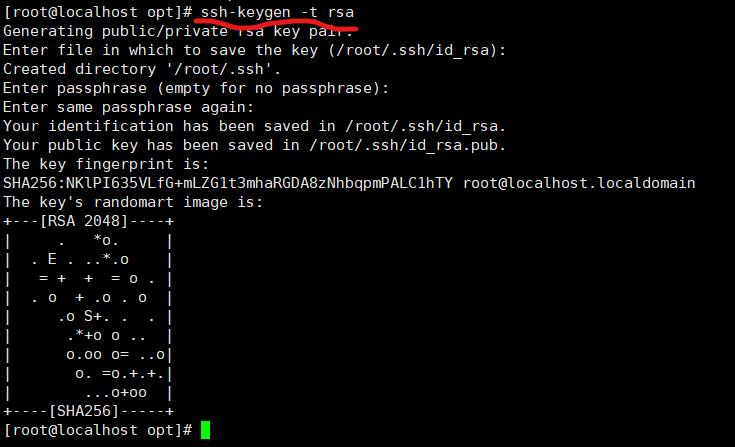
生成密钥
ssh-keygen -t rsa
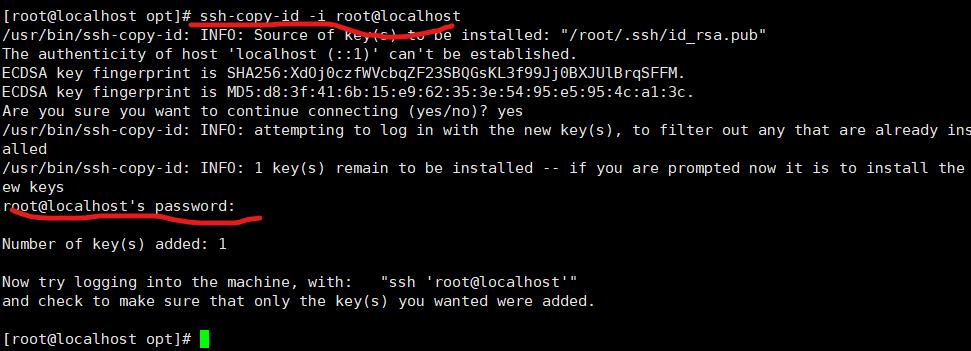
将本机的公钥拷贝本机
ssh-copy-id -i root@localhost
以上是关于Hadoop伪分布构建(保姆式教程)的主要内容,如果未能解决你的问题,请参考以下文章