Hive数据仓库分桶表分区未显示分区的数据
Posted 是逍遥哥哥啊。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive数据仓库分桶表分区未显示分区的数据相关的知识,希望对你有一定的参考价值。
下面是博主运行成功步骤
创建数据库
create database 数据库名;
使用数据库
use 数据库名;
分桶就是MapReduce中的分区
1.开启 Hive 的分桶功能
set hive.enforce.bucketing=true;
2.设置 Reduce 个数
set mapreduce.job.reduces=n;
n:根据题目要求设置个数
3.创建分桶表
create table 表名 (c_id string,c_name string,t_id string) clustered by(c_id) into n buckets row format delimited fields terminated by '\\t';
//创建一个表以某个字段分为n桶,表的内容以\\t分割
桶表的数据加载,由于通标的数据加载通过hdfs dfs -put文件或者通过load data均不好使,只 能通过insert overwrite 创建普通表,并通过insert overwriter的方式将普通表的数据通过查询的方式加载到桶表当中 去.
4.创建普通表
create table 表名_re (c_id string,c_name string,t_id string) row format delimited fields terminated by '\\t';
5.普通表中加载数据
方式一: load data local inpath '本地路径(Linux)' into table 表名_re;
方式二: load data inpath ' 集群路径(hdfs)' into table 表名_re;
博主用的第二种方式
6.通过insert overwrite给桶表中加载数据
insert overwrite table 表名 select * from 表名_re cluster by(c_id);
//将查询普通表的结果加载到分桶表
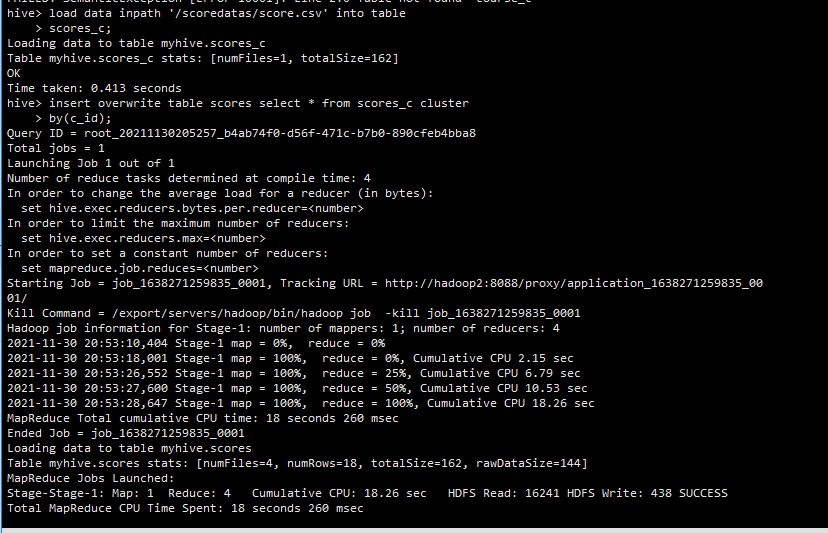
7.在集群上查看结果
在这里我们看一看见1 2 3的size都是45B.证明分区成功

/use/hive/warehouse数据仓库默认存放位置
如出现以下错误:
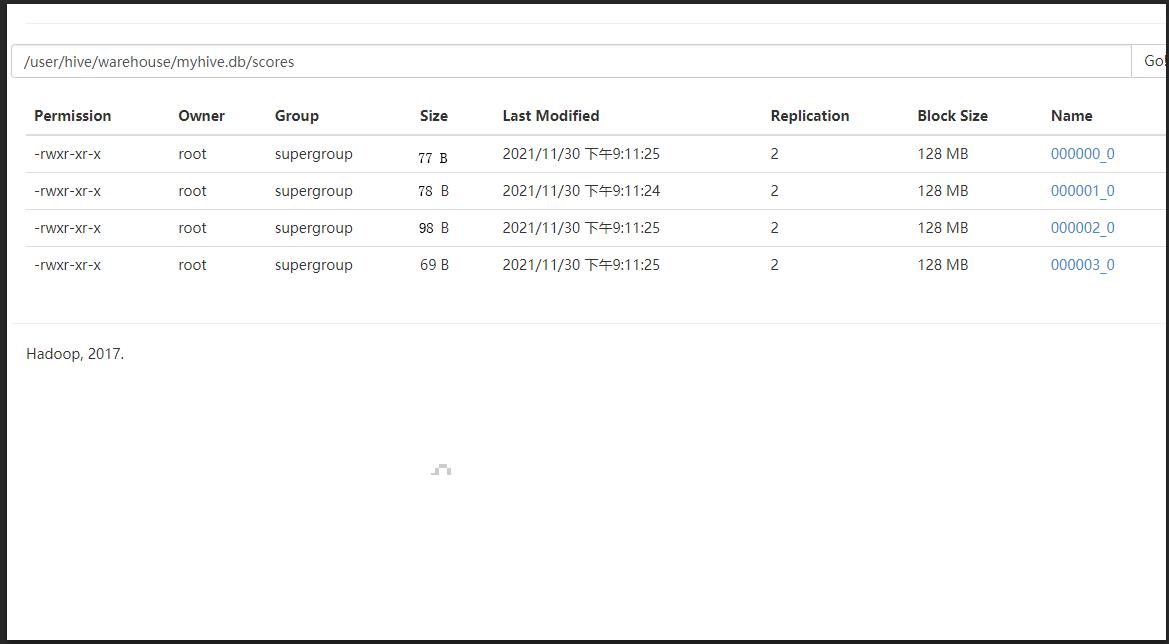
或者size为0
方法一:
暴力解法:
删除数据库,从创建数据库开始在执行一边
drop database 数据库名 cascade;
//强制删除数据库,包含数据库下面的表一起删除
drop database 数据库名;
//删除一个空数据库,如果数据库下面有数据表,那么就会报错
方法二:
删除普通表,重复4-6操作
drop table 表名;
//删除外部表,数据仓库还会显示原表,删除内部表删除所有
如果有其他错误或者解法欢迎评论
以上是关于Hive数据仓库分桶表分区未显示分区的数据的主要内容,如果未能解决你的问题,请参考以下文章