大数据离线处理数据项目 网站日志文件数据采集 日志拆分 数据采集到HDFS并进行预处理
Posted '一生所爱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据离线处理数据项目 网站日志文件数据采集 日志拆分 数据采集到HDFS并进行预处理相关的知识,希望对你有一定的参考价值。
简介:
这篇写的是大数据离线处理数据项目的第一个流程:数据采集
主要内容:
1)利用flume采集网站日志文件数据到access.log
2)编写shell脚本:把采集到的日志数据文件拆分(否则access.log文件太大)、重命名为access_年月日时分.log。 此脚本执行周期为一分钟
3)把采集到并且拆分、重命名的日志数据文件采集到HDFS上
4)将HDFS上的日志数据文件转移到HDFS上的预处理工作目录
1、采集日志数据文件并拆分日志文件
安装crontab(文章最后有crontab操作指令),需要切换到root用户操作:
yum install crontabs编写拆解日志文件脚本
#!/bin/sh
logs_path="/home/hadoop/nginx/logs/"
pid_path="/home/hadoop/nginx/logs/nginx.pid"
filepath=$logs_path"access.log"
echo $filepath
mv $logs_pathaccess.log $logs_pathaccess_$(date -d '-1 day' '+%Y-%m-%d-%H-%M').log
kill -USR1 `cat $pid_path`其中:
logs_path是拆分后的日志文件存放的路径
pid_path是指向nginx运行的进程文件(存放了nginx的进程id)
filepath表示想要进行拆分的日志文件的路径
注意:重命名中这里的-1是因为:这里是离线处理,即今天处理的是昨天的数据,所以名称就需要日期-1
输入crontab配置指令(1表示每分钟)
*/1 * * * * sh /home/hadoop/bigdatasoftware/project1/nginx_log.sh重新启动crontab服务:
service crond restart重新载入配置使定时任务生效:
service crond reload启动nginx,并访问nginx下的网页a.html和b.html


此时日志数据不断产生,并且存放在access.log文件中,然后进行拆分
成功采集到日志数据并成功拆分、重命名:

注意被拆分后的access.log是空的:
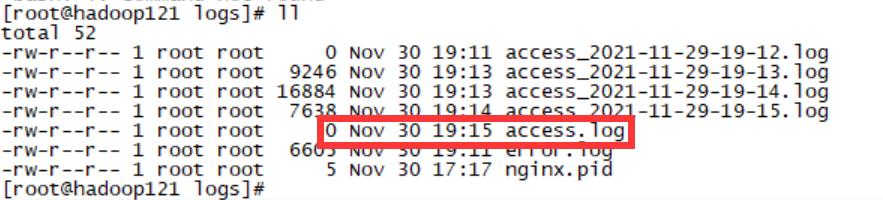
2、 把拆分成功的日志文件采集到HDFS
在flume/job目录下新建配置文件
touch job/TaildirSource-hdfs.conf编写flume配置文件:
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
#监控一个目录下的多个文件新增的内容
agent1.sources.source1.type = TAILDIR
#通过 json 格式存下每个文件消费的偏移量,避免从头消费
agent1.sources.source1.positionFile = /home/hadoop/taildir_position.json
agent1.sources.source1.filegroups = f1
agent1.sources.source1.filegroups.f1 = /home/hadoop/nginx/logs/access_*.log
agent1.sources.source1.interceptors = i1
agent1.sources.source1.interceptors.i1.type = host
agent1.sources.source1.interceptors.i1.hostHeader = hostname
#配置sink组件为hdfs
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path=hdfs://hadoop121:8020/weblog/flume-collection/%Y-%m-%d/%H-%M_%hostname
#指定文件名前缀
agent1.sinks.sink1.hdfs.filePrefix = access_log
#指定每批下沉数据的记录条数
agent1.sinks.sink1.hdfs.batchSize= 100
agent1.sinks.sink1.hdfs.fileType = DataStream
agent1.sinks.sink1.hdfs.writeFormat =Text
#指定下沉文件按1MB大小滚动
agent1.sinks.sink1.hdfs.rollSize = 1048576
#指定下沉文件按1000000条数滚动
agent1.sinks.sink1.hdfs.rollCount = 1000000
#指定下沉文件按30分钟滚动
agent1.sinks.sink1.hdfs.rollInterval = 30
#agent1.sinks.sink1.hdfs.round = true
#agent1.sinks.sink1.hdfs.roundValue = 10
#agent1.sinks.sink1.hdfs.roundUnit = minute
agent1.sinks.sink1.hdfs.useLocalTimeStamp = true
#使用memory类型channel
agent1.channels.channel1.type = memory
agent1.channels.channel1.capacity = 500000
agent1.channels.channel1.transactionCapacity = 600
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1在flume目录下启动程序:
bin/flume-ng agent --conf conf/ --name agent1 --conf-file job/TaildirSource-hdfs.conf -Dflume.root.logger=INFO,console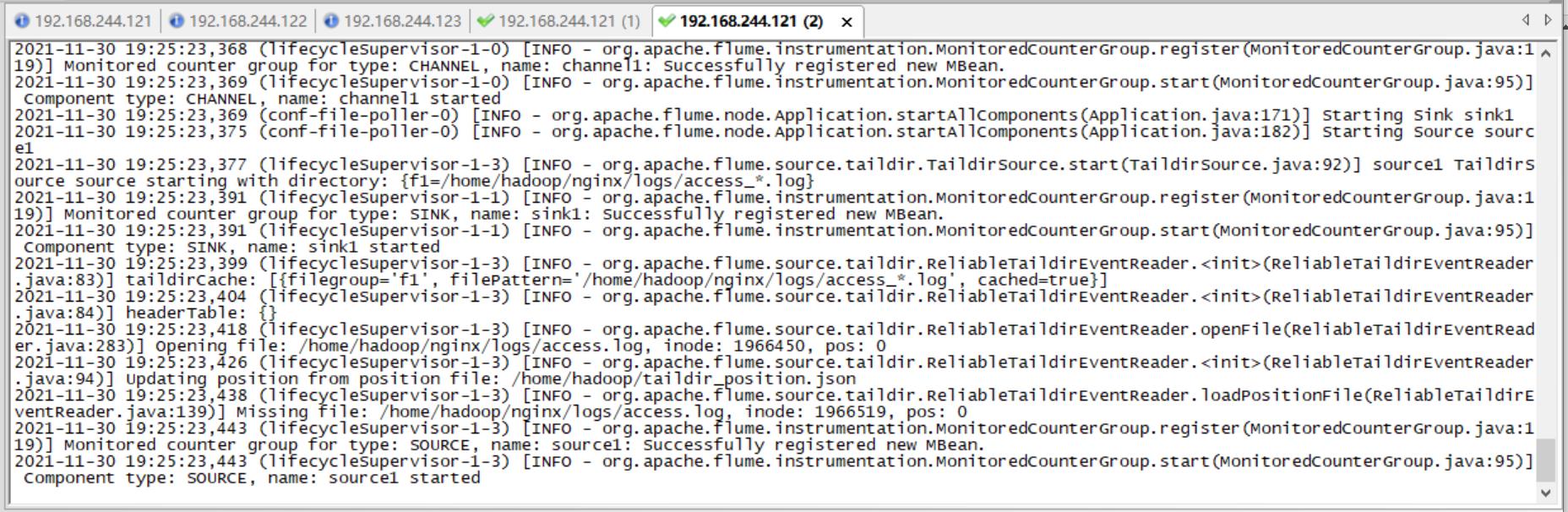
然后再疯狂访问a.html、b.html就完事啦
查看最终结果如下:

3、将日志数据文件转移到预处理工作文件目录中
在/home/hadoop/bigdatasoftware/project1目录下新建脚本文件:movetopreworkdir.sh

编写脚本:
#!/bin/bash
#
# ===========================================================================
# 程序名称:
# 功能描述: 移动文件到预处理工作目录
# 输入参数: 运行日期
# 目标路径: /data/weblog/preprocess/input
# 数据源 : flume采集数据所存放的路径: /weblog/flume-collection
# 代码审核:
# 修改人名:
# 修改日期:
# 修改原因:
# 修改列表:
# ===========================================================================
#flume采集生成的日志文件存放的目录
log_flume_dir=/weblog/flume-collection
#预处理程序的工作目录
log_pre_input=/data/weblog/preprocess/input
#获取时间信息
day_01="2013-09-18"
day_01=`date -d'-1 day' +%Y-%m-%d`
syear=`date --date=$day_01 +%Y`
smonth=`date --date=$day_01 +%m`
sday=`date --date=$day_01 +%d`
#读取日志文件的目录,判断是否有需要上传的文件
files=`hadoop fs -ls $log_flume_dir | grep $day_01 | wc -l`
if [ $files -gt 0 ]; then
hadoop fs -mv $log_flume_dir/$day_01 $log_pre_input
echo "success moved $log_flume_dir/$day_01 to $log_pre_input ....."
fi
执行前:
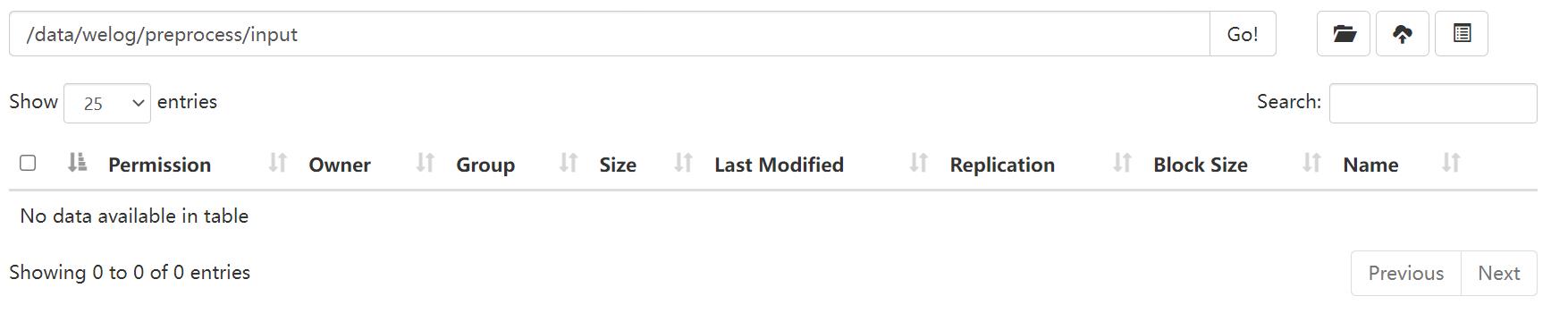
执行脚本:

运行成功并查看结果:
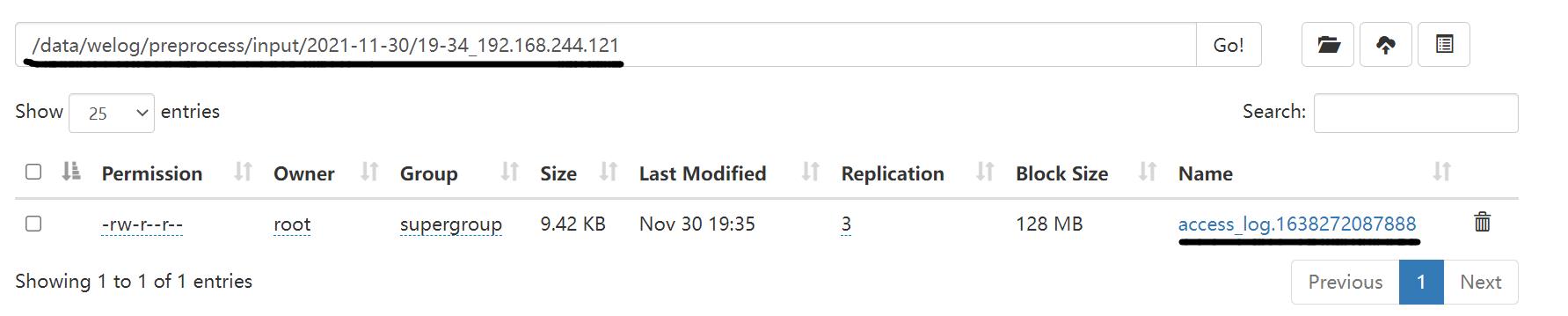
自此完成!~
crontab服务操作
启动服务:service crond start
关闭服务:service crond stop
重启服务:service crond restart
重新载入配置:service crond reload
查看crontab服务状态:service crond status
手动启动crontab服务:service crond start
查看crondtab服务是否已设置为开机启动,执行命令:chkconfig --list
加入开机自启动:chkconfig --level 35 crond on
进入编辑命令:crontabs -e
进入查看运行指令:crontabs -l
删除指令:crontabs -r
配置说明
基本格式:
* * * * * command
分 时 日 月 周 命令
第1列表示分钟1~59 每分钟用*或者 */1表示
第2列表示小时0~23(0表示0点) 7-9表示:8点到10点之间
第3列表示日期1~31
第4列表示月份1~12
第5列标识号星期0~6(0表示星期天)
第6列要运行的命令
以上是关于大数据离线处理数据项目 网站日志文件数据采集 日志拆分 数据采集到HDFS并进行预处理的主要内容,如果未能解决你的问题,请参考以下文章