渗透信息收集(笔记)
Posted Polar Peak
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了渗透信息收集(笔记)相关的知识,希望对你有一定的参考价值。
记录自京东安全小课堂
SRC信息收集为了确定攻击面,也就是确定渗透测试目标。信息收集越充分,攻击的成功率也就越高。但是如果信息收集多而杂,信息利用过程中就很难找到有价值信息。
高价值点的信息:
- 厂商组织架构
- 域名
- IP 段
- 业务信息
厂商的组织架构
首先将公司架构吧,我们就以京东为例吧
企业的组织架构信息可通过开源信息获取。
常用的方法,通过维基百科,百度百科等确定企业的大体组织架构;
zh.wikipedia.org
baike.baidu.com
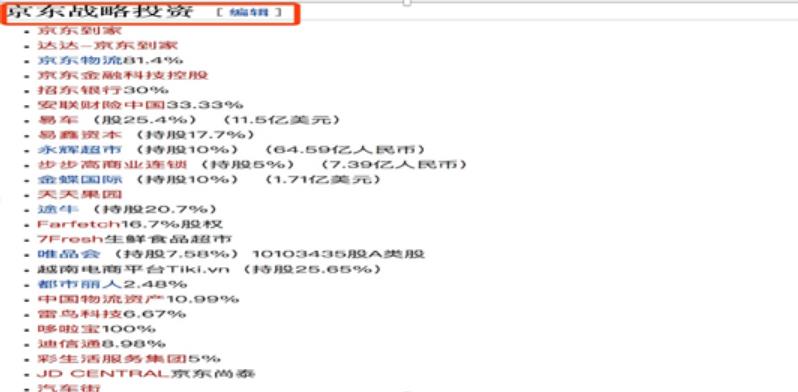
通过以上信息我们可以确定集团下的各个子公司。
如:京东到家,京东物流,京东金融科技等等。
这些子公司都是我们的目标
公司架构确定完成后,我们开始被动信息的收集
被动信息收集(域名)
被动信息收集是指不与目标直接交互,通过公开的渠道获取获取目标信息。
可从以下几点展开,DNS信息收集,https证书信息,搜索引擎,网络空间安全搜索引擎,基于备案资料信息收集。
DNS信息收集
国外常用的whois查询站点:
WHOIS Search, Domain Name, Website, and IP Tools - Who.is
Team Cymru IP to ASN Lookup v1.0
https://whois.arin.net/ui/query.do
国内常用的whois查询站点:
通过whois查询确定注册者,然后关联同一注册者的其他站点信息。
Reverse Whois Lookup - ViewDNS.info
curl https://api.recon.dev/search?domain=domain.com -s | jq -r '.[].domain' | sort -u | cut -d : -f 1,2https证书信息
即通过https证书进行信息收集,可通过采用以下几种方式
基于证书透明度两个站点:
https://certspotter.com/api/v0/certs
为方便信息处理,可编写脚本处理:
crtFetch -d example.com
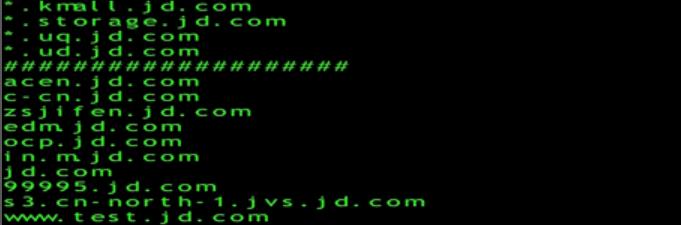
我们看到就可以梳理出一部分子域名信息了
脚本位置:personalTools/crtFetch.py at master · 3stoneBrother/personalTools · GitHub
该脚本对在线站点获取的域名进行清洗,可获取到单域名SSL证书和通配符SSL证书两类。
有时候我们可能忽略的地方,有些企业的https证书中的相关域名可在浏览器证书中点击查看;
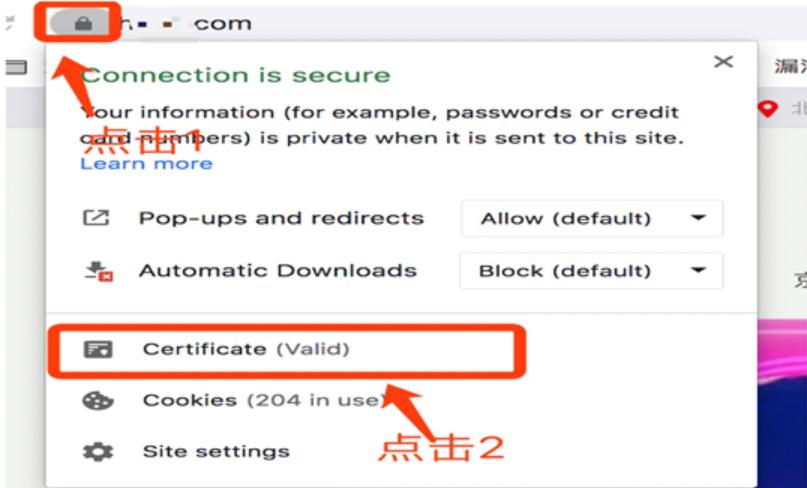
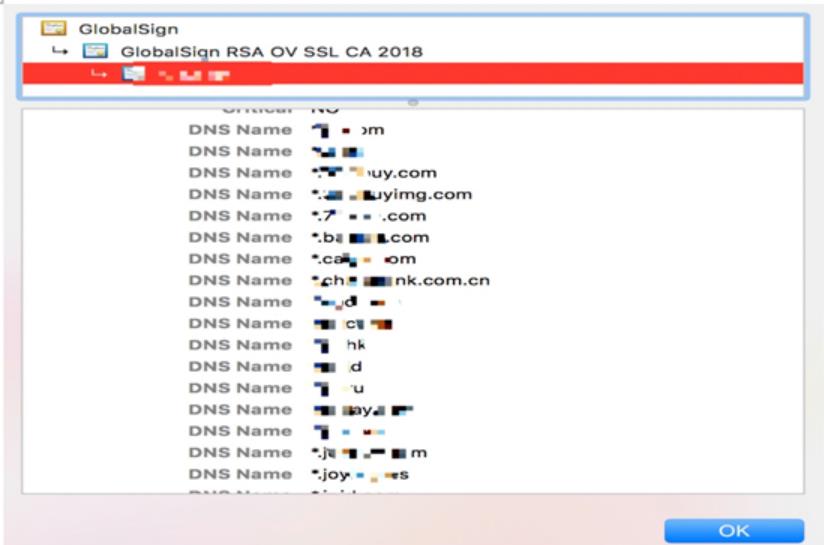
浏览一个站点可查看到该公司的其他域名
分享一个脚本。personalTools/sslinfo.py at master · 3stoneBrother/personalTools · GitHub
脚本:python sslinfo.py -d "jd.com"搜索引擎技术
基于goolge hack技术可以查询到很多敏感信息。
更详细的用法可在这里查询:
Google Hacking Database (GHDB) - Google Dorks, OSINT, Recon
我们常用关键字查询:
site:搜索域名的范围
inurl:URL格式
intitle:搜索的网页标题
intext:搜索包含其中文字的网页
filetype:搜索文件的后缀或者扩展名
cache:搜索搜索引擎里关于某些内容的缓存,可能会在过期内容中发现有价值的信息
link:搜索某个网站的链接
info:查找指定站点的一些基本信息
【查找敏感目录地址】
site:xxx.com inurl:login|admin|manage|admin_login|system|user|auth|dev|testsite:xxx.com intitle:后台|管理|内部|登录|系统【查找敏感文件】
site:xxx.com (filetype:doc OR filetype:ppt OR filetype:pps OR filetype:xls OR filetype:docx OR filetype:pptx OR filetype:ppsx OR filetype:xlsx OR filetype:odt OR filetype:ods OR filetype:odg OR filetype:odp OR filetype:pdf OR filetype:wpd OR filetype:svg OR filetype:svgz OR filetype:indd OR filetype:rdp OR filetype:sql OR filetype:xml OR filetype:db OR filetype:mdb OR filetype:sqlite)这个语法就比较长了,主要查找公司的一些敏感信息
后台:site:xxx.xxx admin|login|system|管理|登录|内部|系统|邮件|email|mail|qq|群|微信|腾讯|这些信息,在社工的时候以下可能会用到。但是在SRC中渗透中一定要遵从行业测试规范。除特别批准外,严禁与漏洞无关的社工。还有其他的一些注意事项小伙伴们也一定要注意以下。
google hack
以下可能是我们会忽略的几个关键字查询语句:
基于备案号,copyright信息查询
intext:"Tesla ©2020"
intext:"京ICP备11041704号-15"
这些也可以帮我们查找一些站点信息
## 可以正则的形式
site:dev.*.*/signin
site:*/recover-pass
site:smtp.*.*/login
site:/com:*
site:/216.75.*.*
基于端口或者端口范围查询
site:/com:8443/
site:/com:* 8000...9000
网络空间安全搜索引擎
常用的搜索引擎,有以下几个:
ZoomEye - Cyberspace Search Engine
网络空间测绘,网络空间安全搜索引擎,网络空间搜索引擎,安全态势感知 - FOFA网络空间测绘系统
利用如下常用语法,我们可以收取更多的信息:
org:"Tesla"
ssl:"Tesla"
http.component:"Drupal"
http.title:"Login"
http.favicon.hash:81586312
os:"windows" port:"3389" net:"107.160.1.0/24"
Apache city:"Hong Kong" port:"8080" product:"Apache Tomcat/Coyote JSP engine"
这些常用语法,可以帮助我们找到一些目标信息
基于备案资料信息收集
通过企业组织架构查询到的关键词,利用备案信息可以大致确定各个站点的域名信息。
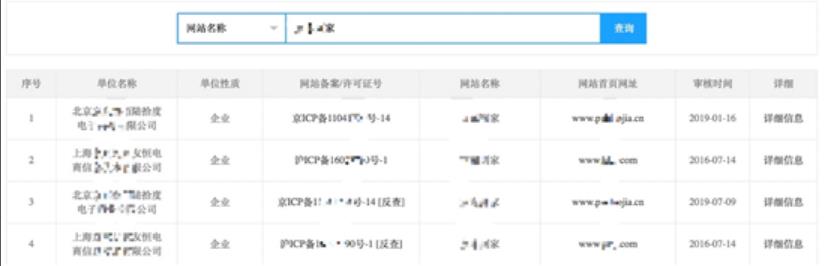
基于关键词就可以查找到域名信息
点击反查,可看到该公司的其他备案域名信息:
http://www.beianbeian.com/search-1/example.html
基于网页信息做一个正则过滤,便于批量处理
curl http://www.beianbeian.com/search-1/example.html | grep "</a><br></td>" | grep -o "www\\.\\\\w*\\.\\\\w*" | sort | uniq | sed "s/www.//g"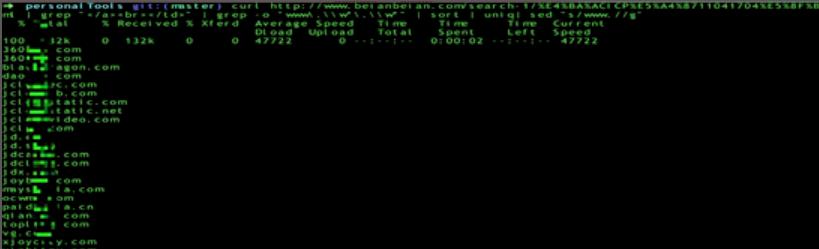
不断的根据网络备案/许可证号进行反查,即可梳理更多的资产信息。
确定企业的IP段
可基于https://bgp.he.net/站点进行收集。
输入公司名称可查询该公司的IP资产信息,然后正则匹配IP段:
cat aa.txt| grep -Eo "\\<td\\>.*?td\\>"| grep "href"| grep -Eo "([0-9]1,3[\\.])3[0-9]1,3\\/*[0-9]0,2" 就可以得到公司的IP段信息了
基于APP、H5、公众号、小程序(业务)
以公众号信息为例进行说明:
基于公众号信息,我们可以挖掘到很多的厂商业务信息。公司的公众号信息可在sogou搜索引擎可以进行查询。
为便于快速梳理,可用脚本处理。
python gongzhonghao.py -d "目标公司"
personalTools/gongzhonghao.py at master · 3stoneBrother/personalTools · GitHub
主动信息收集
通过被动信息收集到一批域名,IP信息。
以主动信息比较容易忽略的三级域名,甚至四级域名为例进行说明。通配符SSL证书往往是三级、四级域名高效爆破的目标,为批量处理,在crtFetch脚本中提取了需要进一步爆破的三级、四级域名。
就是刚才的那个脚本 以上的部分
然后进行域名爆破,爆破工具有很多,以gobuster为例进行演示:
gobuster dns -t 30 -w sub_name.txt -i -q –wildcard -d api.example.com| tee domains-active.txt 这些三级四级域名,防护往往会薄弱一些
这些三级四级域名,防护往往会薄弱一些
域名是否存活可利用httprobe工具确定。
cat domain.txt | httprobe > domain-alive.txt 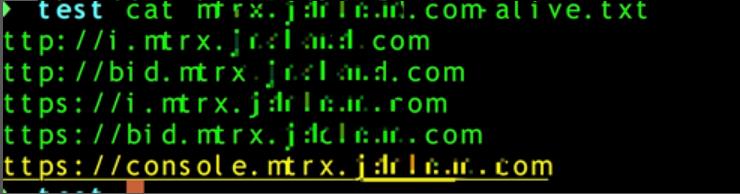
也可通过whatweb查看链接的服务器版本,标题等信息,处理结果如下图所示

为便于批量查看URL内容,我们可通过屏幕截图工具webscreenshot进行处理。
具体方法如下:首先将存活的站点截图到screenshots文件夹下面:
webscreenshot -i alive.txt -o screenshots -w 20 -m -a "X-FORWARDED-FOR:127.0.0.1"为便于浏览,我们将截图生成一个html文件便于在浏览器查看:
for I in $(ls -S); do echo "$I" >> index.html;echo "<img src=$I><br>" >> index.html; done这样就按照图片大小在浏览器显示了, 在浏览器中打开 index.html文件,就可看到所有的网页截图了。效果如下图,所有存活站点都在一个页面展现出来。可根据站点内容做进一步的渗透测试。

为高效的发现新上线的业务,结合主动信息和被动信息收集,做一个监控工具,一旦有新的业务上线,第一时间感知。
这是我的域名监控系统,每当有新的站点上线,会有slack消息通知。
以上是关于渗透信息收集(笔记)的主要内容,如果未能解决你的问题,请参考以下文章