Python爬虫编程思想(89):如何用逆向工程分析异步加载页面
Posted 蒙娜丽宁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫编程思想(89):如何用逆向工程分析异步加载页面相关的知识,希望对你有一定的参考价值。
在上一篇文章中,我们已经模拟实现了一个异步装载的页面,本文会以这个程序为例进行分析,假设我们对这个程序的实现原理不了解,那么应该如何得知当前页面的数据是异步加载的呢?以及如何获取异步请求的URL呢?
这就和破解一个可执行程序一样,需要用二进制编辑工具一点一点跟踪,这种方式被称为“逆向工程”。
现在来分析这个异步加载的页面。首先用Chrome浏览器打开这个页面,然后在开发者工具中定位到视频列表,如图1所示。
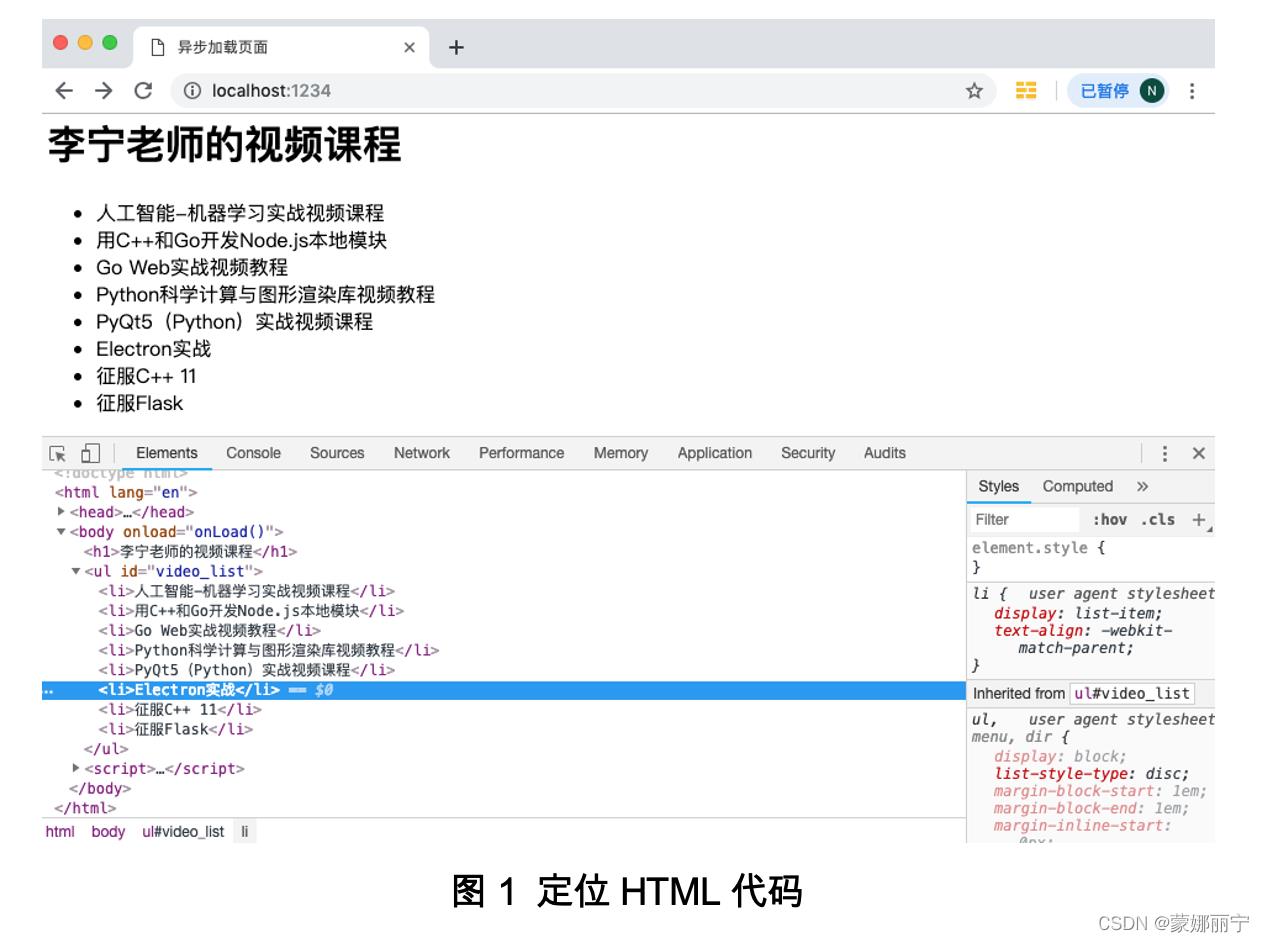
从Elements选项卡的代码会发现,所有8个列表项都实现出来了,可能初学者看到这个会欣喜若
以上是关于Python爬虫编程思想(89):如何用逆向工程分析异步加载页面的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(16):Robots协议(不了解这个就是面向监狱编程了)
Python爬虫编程思想(144):爬虫框架Scrapy的基础知识
Python爬虫编程思想(144):爬虫框架Scrapy的基础知识
Python爬虫编程思想(146):创建和使用Scrapy工程