Google华人博士在ICCV 2021发布新模型!机器学习都能预测未来了!
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Google华人博士在ICCV 2021发布新模型!机器学习都能预测未来了!相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
预测未来一直是人类梦寐以求的事,而刚好机器学习模型正好擅于预测。最近Google、布朗大学的华人博士在ICCV 2021发表了他的新工作,在菜谱视频数据集中可以合理预测未来,还不受时间限制,打个鸡蛋就知道你要做煎饼!
随着机器学习的模型在现实世界中的应用和部署越来越多,AI 的决策也能够用于帮助人们在日常生活中做出决策。
在计算机视觉领域的决策过程中,预测(Prediction)一直都是一个核心问题。
如何在不同的时间尺度上对未来作出合理的预测也是这些机器模型的重要的能力之一,这种能力可以让模型预测出周围世界的变化,包括其他模型的行为,并计划下一步如何行动与决策。

更重要的是,成功的未来预测(future prediction)既需要捕捉环境中的有意义的物体变化,也需要了解环境如何随着时间的推移进行变化,以便作出决策和预测。
计算机视觉中关于未来预测的工作主要受限于其输出的形式,输出可能是图像的像素或者是人工预定义的一些标签(例如预测某人是否会继续行走、坐下等)。
这些预测内容都太过详细以至于难以完全预测成功,并且对现实世界信息的丰富性也缺乏有效利用。也就是说,如果一个模型在预测「跳跃行为」时,并不知道为什么他们会跳跃,或者他们在跳什么等等,那就没办法预测成功,结果基本等于乱猜。
此外,除了极少数例外,之前的模型被设计成对未来进行固定偏移(offset)的预测,无法进行动态时间间隔的预测,虽然这是一个限制性的假设,因为我们很少知道何时会出现有意义的未来状态。

在一个制作冰淇淋的视频中,从cream到ice cream在视频中的时间间隔为35 秒,因此预测这种变化的模型需要提前35秒来预判。但这一间隔在不同的行为和视频中变化很大,例如有的博主可能用了更详细、更长时间来制作冰淇淋,也就是说在未来的任何时间都有可能制作完成冰淇淋。
此外,可以大规模、数以百万计收集此类视频逐帧标注,许多教学视频都有语音转换记录,通常在整个视频中提供简明、一般的描述。这种数据源可以引导模型关注视频中的重要部分,而无需手动标注就能够对未来事件进行灵活的数据驱动预测。
基于这个思路,Google在ICCV 2021上发表了一篇文章,提出了一种自监督的方法,使用了一个大型、未标记的人类活动数据集。所建立的模型具有高度的抽象性,可以任意时间间隔对未来进行远距离预测,并能够根据上下文选择对未来的远期预测。

模型具有多模态周期一致性(Multi-Modal Cycle Consistency,MMCC)的目标函数,能够利用叙事教学视频来学习一个强大的未来预测模型。研究人员在文中还展示了如何在不进行微调的情况下,将MMCC应用于各种具有挑战性的任务,并对其预测进行了量化测试实验。
文章的作者Chen Sun来自Google和布朗大学,目前是布朗大学计算机科学助理教授,研究计算机视觉、机器学习和人工智能,也是谷歌研究所的一名研究科学家。
他在2016年博士毕业于南加州大学,导师是Ram Nevatia教授,于2011年完成清华大学计算机科学学士学位。
正在进行的研究项目包括从无标签视频中学习多模式表示和视觉交流,识别人类活动、对象及其随时间的相互作用,并将表示转移到embodied agents。

研究中主要解决了未来预测的三个核心问题:
1. 手动标注视频中的时间关系是非常耗时耗力的,而且很难定义标签的正确性。所以模型应当能够从大量未标记的数据中自主学习和发现事件的变换,从而实现实际应用。
2. 对现实世界中复杂的长期事件变换进行编码需要学习更高层次的概念,这些概念通常在抽象的潜在表示中可以找到,而非只是图像中的像素。
3. 时序的事件变换非常依赖于上下文,所以模型必须能够在可变时间间隔下预测未来。
为了满足这些需求,研究人员引入了一个新的自监督训练目标函数MMCC以及一个学习表达式来解决这一问题的模型。
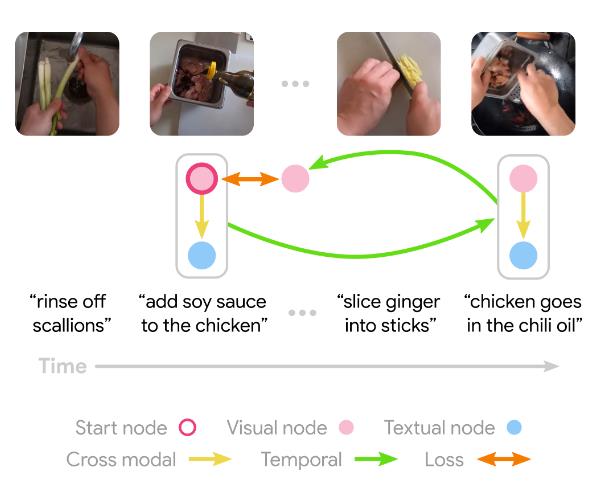
模型从叙事视频中的一个样本帧开始,学习如何在所有叙事文本中找到相关的语言表述。结合视觉和文本这两种模式,该模型能够用到整个视频来学习到如何预测潜在未来的事件,并估计该帧的相应语言描述,并以类似的方式学习预测过去帧的函数。
循环约束(cycle constraint)要求最终模型预测等于起始帧。
另一方面,由于该模型不知道其输入数据来自哪个模式,因此必须在视觉和语言上共同运作,因此无法选择较低级别的未来预测框架。
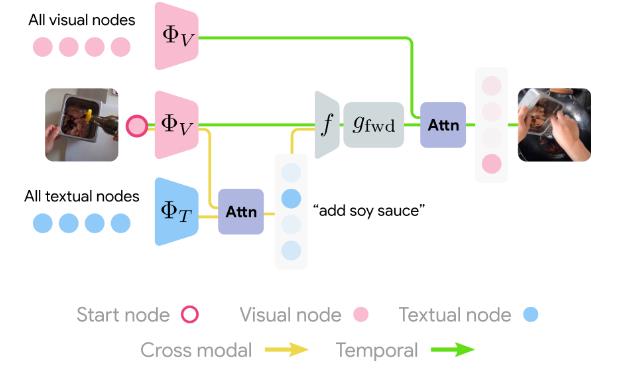
模型学习嵌入所有视觉和文本节点,然后在其他模式下仔细计算与起始节点对应的跨模式节点。这两个节点的表示都被转换为全连接层,预测了在初始模态下使用注意力的未来帧。然后重复backward过程,模型损失是通过预测起始节点来训练模型的最终输出来结束循环(cycle)。
在实验部分,由于大多数先前的benchmark侧重于具有固定类别和时间偏移的有监督行为预测,这篇论文中研究人员设计了一系列新的定性和定量实验来评估不同的方法。
首先是数据,研究人员在无约束的真实世界视频数据上训练模型。使用HowTo100M数据集的子集,其中包含大约123万个视频及其自动提取的音频脚本。此数据集中的视频大致按主题区域分类,并且只使用分类为 Recipe 的视频,大约是数据集中的四分之一。
在338033个Recipe视频中,80% 为训练集,15%在验证集,5%在测试集。Recipe视频包含了丰富的复杂对象、操作和状态转换,并且该子集能够让开发者更快地训练模型。
为了进行更多的控制测试(controlled test),研究人员使用CrossTask数据集,包含相似的视频以及特定于任务的标注。
所有视频都与任务相关,例如制作煎饼等,其中每个任务都有一个预先定义的高级别子任务序列,这些子任务具有丰富的长时间的相互依赖性,例如,要先把糊弄到碗里,然后才能把鸡蛋打成碗,再加入糖浆等等。

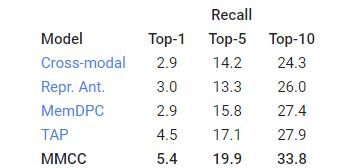
使用TOP-K召回指标评估模型预测行动的能力来衡量了模型预测正确未来的能力(越高越好)。
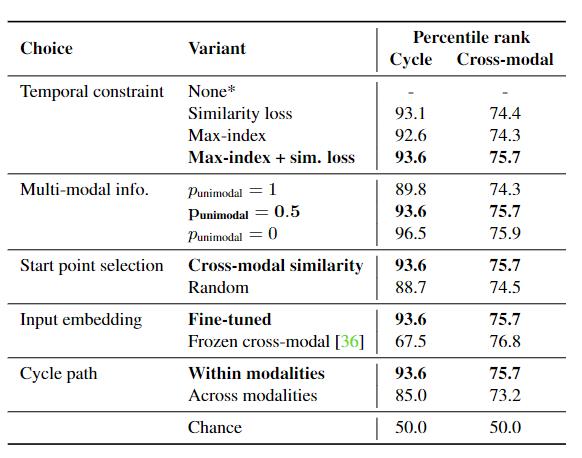
对于MMCC,为了确定整个视频中有意义的随时间推移的事件变化,研究人员根据模型的预测,为视频中的每个帧对(pair)定义了一个可能的过渡分数,预测的帧越接近实际帧,则分数越高。
参考资料:
https://ai.googleblog.com/2021/11/making-better-future-predictions-by.html
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于Google华人博士在ICCV 2021发布新模型!机器学习都能预测未来了!的主要内容,如果未能解决你的问题,请参考以下文章
不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍
不用亲手搭建型了!华人博士提出few-shot NAS,效率提升10倍
中科大刘泽博士一作斩获 ICCV 2021 最佳论文奖!中国学者占「半壁江山」
中科大刘泽博士一作斩获 ICCV 2021 最佳论文奖!中国学者占「半壁江山」