基于docker搭建conda深度学习环境(支持GPU加速)
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于docker搭建conda深度学习环境(支持GPU加速)相关的知识,希望对你有一定的参考价值。
前言
在Ubuntu系统,创建一个docker,然后搭建conda深度学习环境,这样可以用conda或pip安装相关的依赖库了。
一、创建一个docker
为了方便开发,在Docker Hub官方中选择一个合适的conda docker镜像,然后下载到本地。
我选择了“docker-anaconda”,地址是:Docker Hub
下载命令如下:
docker pull continuumio/anaconda3二、进入docker
通常使用 docker run 命令进入docker镜像,例如:
docker run -i -t continuumio/anaconda3 /bin/bash其中 -i: 以交互模式运行容器,通常与 -t 同时使用;
2.1 映射目录
平常进入了docker环境,然后创建或产生的文件,在退出docker环境后会“自动销毁”;或者想运行本地主机的某个程序,发现在docker环境中找不到。
我们可以通过映射目录的方式,把本地主机的某个目录,映射到docker环境中,这样产生的文件会保留在本地主机中。
比如:
docker run -i -t continuumio/anaconda3 -v /home/xxx/xxx/:/home/xxxx:rw /bin/bash通过-v 把本地主机目录 /home/xxx/xxx/ 映射到docker环境中的/home/xxxx 目录;其权限是rw,即能读能写。
2.2 支持GPU
默认是不把GPU加入到docker环境中的,但可以通过参数设置:
--gpus all但我发现,这样有时不能在docker里正常使用GPU;可以使用如下参数,在Pytorch中亲测有效。
--gpus all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all举个例子:
docker run -i -t continuumio/anaconda3 --gpus all -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all /bin/bash2.3 设置内存
默认分配很小的内参,在训练模型时不够用,可以通过参数设置:
--shm-size xxG比如,我电脑有32G内参,想放16G到docker中使用,设置为 --shm-size 16G,即:
docker run -i -t continuumio/anaconda3 --shm-size 16G /bin/bash2.4 综合版本
结合映射目录、支持GPU、设置内存,打开docker的命令如下:
docker run -i -t -v /home/disk1/guopu/:/home/guopu:rw --gpus all --shm-size 16G -e NVIDIA_DRIVER_CAPABILITIES=compute,utility -e NVIDIA_VISIBLE_DEVICES=all continuumio/anaconda3 /bin/bash详细的参数解析如下
-
-a stdin: 指定标准输入输出内容类型,可选 STDIN/STDOUT/STDERR 三项;
-
-d: 后台运行容器,并返回容器ID;
-
-i: 以交互模式运行容器,通常与 -t 同时使用;
-
-P: 随机端口映射,容器内部端口随机映射到主机的端口
-
-p: 指定端口映射,格式为:主机(宿主)端口:容器端口
-
-t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用;
-
--name="nginx-lb": 为容器指定一个名称;
-
--dns 8.8.8.8: 指定容器使用的DNS服务器,默认和宿主一致;
-
--dns-search example.com: 指定容器DNS搜索域名,默认和宿主一致;
-
-h "mars": 指定容器的hostname;
-
-e username="ritchie": 设置环境变量;
-
--env-file=[]: 从指定文件读入环境变量;
-
--cpuset="0-2" or --cpuset="0,1,2": 绑定容器到指定CPU运行;
-
-m :设置容器使用内存最大值;
-
--net="bridge": 指定容器的网络连接类型,支持 bridge/host/none/container: 四种类型;
-
--link=[]: 添加链接到另一个容器;
-
--expose=[]: 开放一个端口或一组端口;
-
--volume , -v: 绑定一个卷
三、检验docker
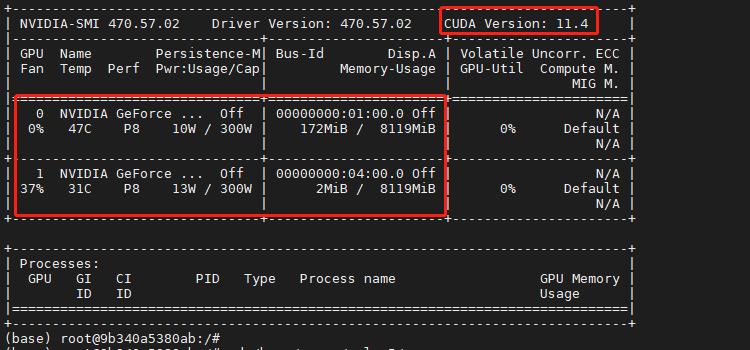
进入docker中,首先查看一下GPU,用nvidia-smi命令。正常显示CUDA版本,正常加载了显卡(这里是两张1080ti)。
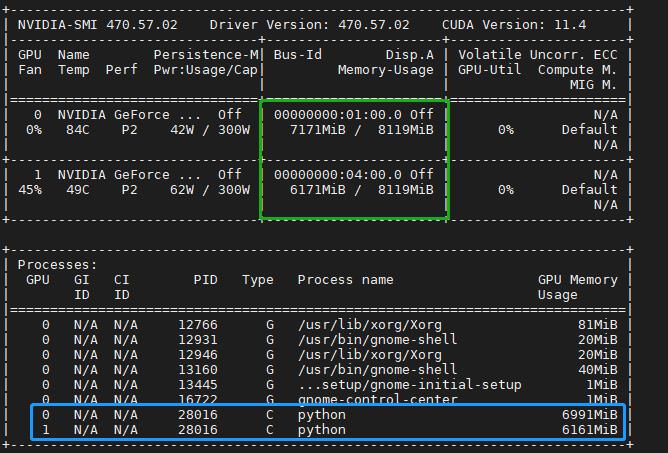
使用两张显卡训练YOLOv5时,显示正常;
参考文献
怎么在docker中使用nvidia显卡 - 思念殇千寻 - 博客园
本文只供大家参考与学习,谢谢。
以上是关于基于docker搭建conda深度学习环境(支持GPU加速)的主要内容,如果未能解决你的问题,请参考以下文章
远程服务器基于docker容器的深度学习环境配置(支持GPU)
构建docker环境能够运行自己的GPU服务,能够快速适应不同宿主机的GPU型号操作系统和驱动。linux版本nvidia驱动cudacudnn,docker+conda安装深度学习环境
Mac Apple Silicon M1/M2 homebrew miniforge conda pytorch yolov5深度学习环境搭建并简单测试MPS GPU加速