Elasticsearch 主从同步之跨集群复制
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 主从同步之跨集群复制相关的知识,希望对你有一定的参考价值。
1、什么是跨集群复制?
跨集群复制(Cross-cluster replication,简称:CCR)指的是:索引数据从一个 Elasticsearch 集群复制到另一个 Elasticsearch 集群。
对于主集群的索引数据的任何修改都会直接复制同步到从索引集群。
2、跨集群复制最早发布版本
Elasticsearch 6.7 版本。
3、跨集群复制的好处?
3.1 支持灾难恢复(DR)、确保高可用性(HA)
跨集群复制确保了不间断的服务可用性,能够承受住数据中心或区域服务中断的影响,降低了复杂性、节省了成本。
3.2 降低延迟
将数据复制到更靠近应用程序用户的集群可以最大限度地减少查询延迟。
3.3 水平可扩展性
跨多个副本集群拆分查询繁重的工作负载可提高应用程序可用性。
3.4 集中式汇报
企业客户可以将属于不同业务线的较小集群(数百个分支银行中心)中的报告不断汇总到一个中央集群(大型全球银行)中,以用于整合报告、方便可视化呈现。
PS:关于高可用,读者可能会有疑惑?
● 副本的目的是高可用,集群的快照和恢复和功能是高可用,怎么又来个跨集群复制呢?
副本主要体现在分片层面,可以看做分片的复制,一般集群至少设置一个副本,当主副本故障时,副本分片会提升为主分片。
● 快照和恢复主要体现在:集群级别和索引层面,可以全量或者增量。但,做不到实时备份和恢复。也就是说,快照会设定一个时间间隔,比如每 5 分钟备份一次。
当集群出现故障需要恢复时,极有可能会少备份最近 5 分钟的数据,
综上,才会有了跨集群复制的概念。
4、跨集群复制的核心概念
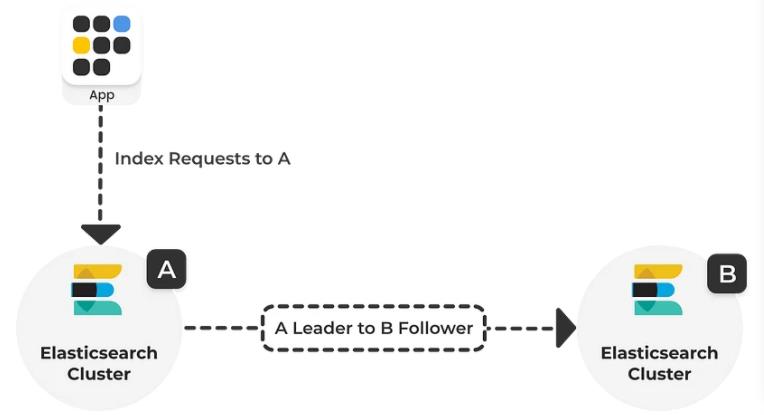
图片来源:opster.com
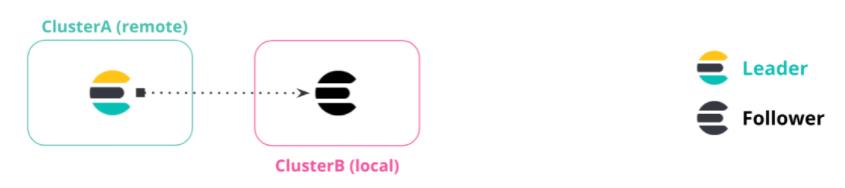
跨集群复制使用主动-被动模型(active-passive model)。
数据索引到一个领导者索引(leader index),并且数据被复制到一个或多个只读跟随者索引(read-only follower indices)。在向集群添加跟随者索引之前,必须配置包含领导者索引的远程集群。
leader-follower 模式在 kafka、zookeeper等中都有涉及,我认为翻译为:主、从模型比较契合。
核心释义解读如下:
active-passive model:主动-被动模型。
leader index:主索引或领导者索引。
read-only follower indices:从索引或跟随者索引。
5、跨集群复制的设计原则
5.1 高安全性
跨集群复制应该为所有数据流和 API 提供强大的安全控制。
5.2 准确性
跟随者索引和领导者索引的预期内容之间必须没有差异。
5.3 高性能
复制不应影响领导集群的索引率(数据写入速率)。
5.4 最终一致性
领导者和跟随者集群之间的复制延迟应该在几秒钟之内。
5.5 资源使用率低
复制应该使用最少的资源。
6、跨集群复制的实战一把
6.1 必备前置条件
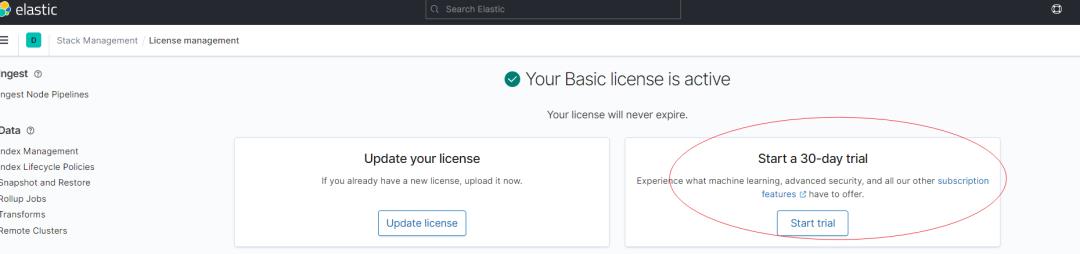
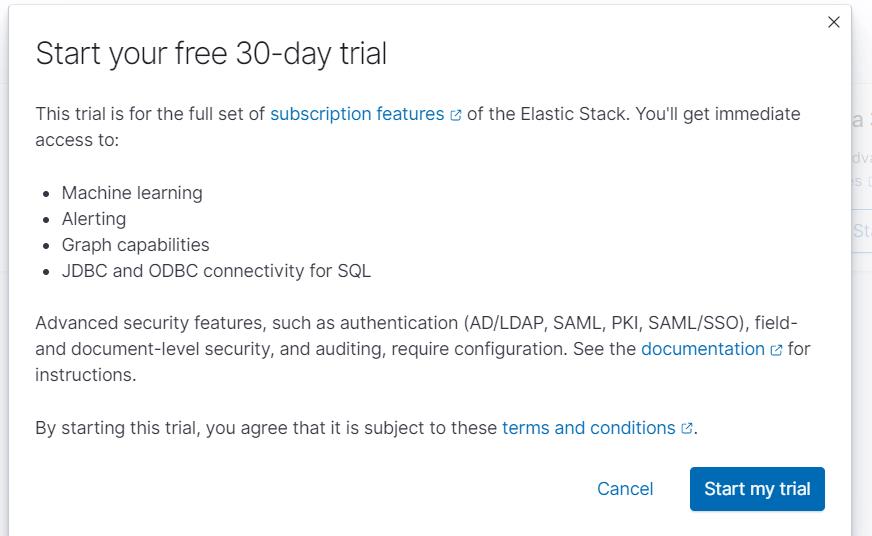
6.1.1 前置条件1:激活License
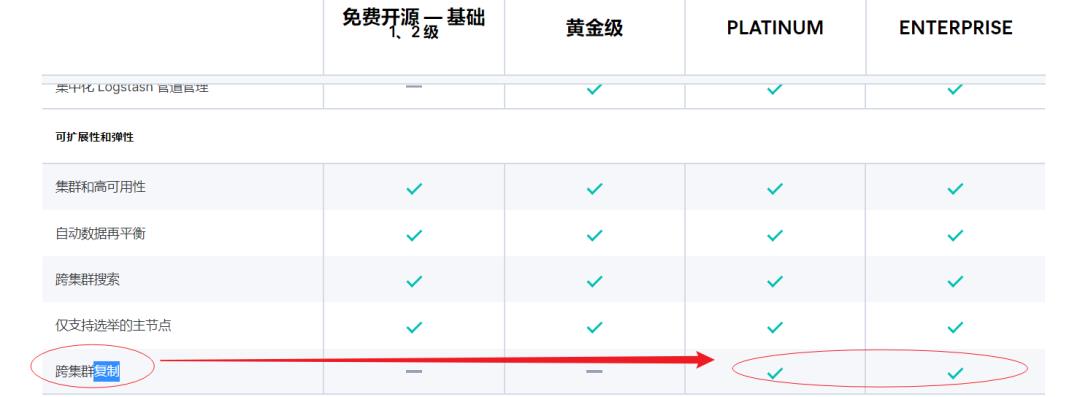
CCR 是白金版付费功能,需要激活 30 天的 License,如果仅学习了解功能,建议先试用。
6.1.2 前置条件2:备好至少 2 个集群
跨集群复制,核心是“跨”和“复制”。
“跨”体现在至少得两个集群,否则没有意义。
最简单模型如图所示,我们用一台宿主机搭建两套集群环境,如下所示:
图片来自:elastic官方文档
● 集群A:远端集群,remote cluster leader
Elasticsearch: 172.21.0.14:19203
kibana:172.21.0.14:5613
● 集群B:本地集群,local cluster follower
Elasticsearch: 172.21.0.14:19202
kibana:172.21.0.14:5612
6.1.3前置配置:开启软删除
7.0+之后版本已默认开启,无需单独配置。
早期版本,需参考官方文档进行静态配置,需要修改配置文件实现。
index.soft_deletes.enabled:true跨集群复制的工作原理是:重放对 leader 索引分片执行的单个写入操作的历史记录。
Elasticsearch 需要在 leader 分片上保留这些操作的历史记录,以便它们可以被 follower 分片任务拉取。用于保留这些操作的底层机制是软删除。
6.1.4 前置配置:xpack 设置true
因为需要配置角色、权限等,Elasitcsearch 设置了xpack,就意味着 kibana 端需要设置账号、密码。
在 elasticsearch.yml 文件中添加如下配置。
xpack.security.enabled: true通过:./elasticsearch-setup-passwords 命令行工具实现用户名和密码的设置。
auto 自动设置的结果参考如下:
Changed password for user apm_system
PASSWORD apm_system = m5ob2a8OvoKuYpPPsiRd
Changed password for user kibana_system
PASSWORD kibana_system = xwdrhpVPSsbxxY1l0b50
Changed password for user kibana
PASSWORD kibana = xwdrhpVPSsbxxY1l0b50
Changed password for user logstash_system
PASSWORD logstash_system = 1zweZhAVEnqwh1flHBkz
Changed password for user beats_system
PASSWORD beats_system = 7Fo3bvmLISshjvHXTqAY
Changed password for user remote_monitoring_user
PASSWORD remote_monitoring_user = EvB4FkFs88gsCP073YGt
Changed password for user elastic
PASSWORD elastic = c7KmLqGTm6cyl2ABJPBY否则会报错如下:
"error" :
"root_cause" : [
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
],
"type" : "exception",
"reason" : "Security must be explicitly enabled when using a [trial] license. Enable security by setting [xpack.security.enabled] to [true] in the elasticsearch.yml file and restart the node."
,
"status" : 500
6.2 跨集群复制完整设置步骤
6.2.1 步骤1:从集群设置 remote cluster
在从集群上配置包含主索引的远程集群(remote cluster)
其实看到:remote cluster,第一时间要想到:跨集群检索(CCR)也需要配置它。
从集群配置主集群 leader,参考如下:
PUT /_cluster/settings
"persistent":
"cluster":
"remote":
"leader":
"seeds": [
"172.21.0.14:19303"
]
从集群监测一下remote配置是否成功。
GET /_remote/info检测是否配置成功。
6.2.2 步骤2:配置权限
为跨集群复制配置权限。
跨集群复制用户在远程集群和本地集群上需要不同的集群和索引权限。
使用以下请求在本地和远程集群上创建单独的角色,然后创建具有所需角色的用户。
6.2.2.1 remote 集群配置权限
前置条件:设置 xpack 为 true,kibana 端配置账号和密码。
POST /_security/role/remote-replication
"cluster": [
"read_ccr"
],
"indices": [
"names": [
"kibana_sample_data_logs"
],
"privileges": [
"monitor",
"read"
]
]
6.2.2.2 local 集群配置权限
在本地集群上创建从索引。
POST /_security/role/remote-replication
"cluster": [
"manage_ccr"
],
"indices": [
"names": [
"kibana_sample_data_logs_follower"
],
"privileges": [
"monitor",
"read",
"write",
"manage_follow_index"
]
]
6.2.3 步骤3:创建自动跟踪模式以自动跟踪在远程集群中创建的索引
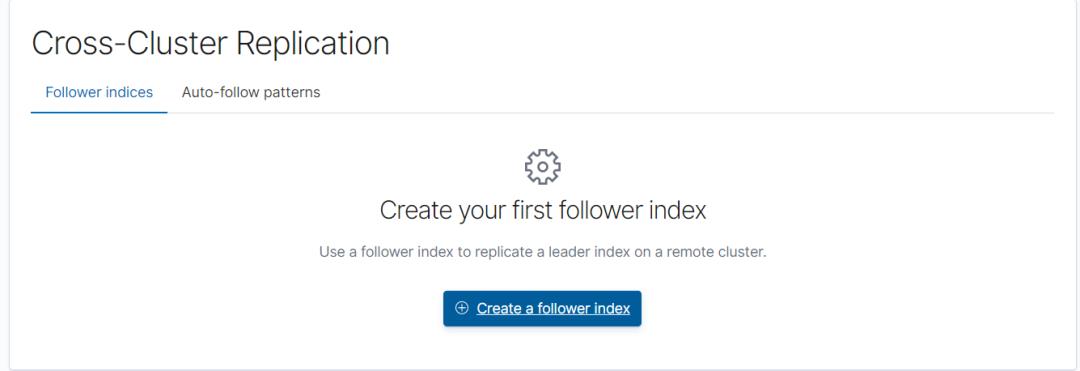
可以使用 Kibana 图形化界面配置或者命令行配置。
位置:Stack Management->Data->Cross-Cluster Replication。
步骤1:创建 follower index。
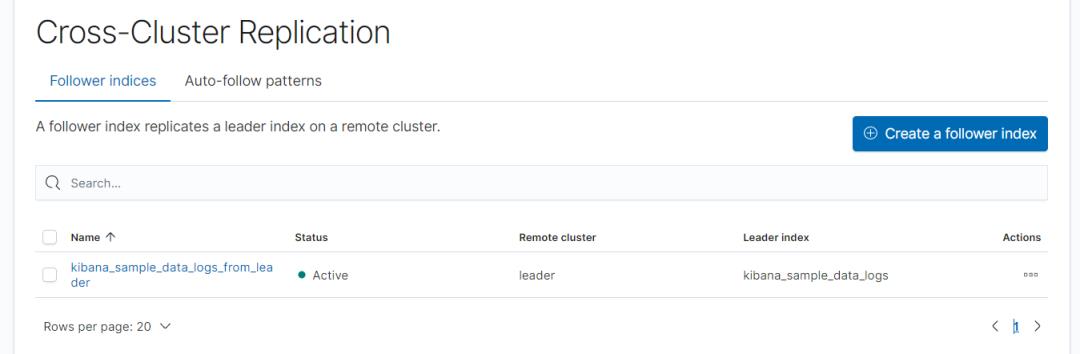
步骤2:配置 follower index。

需要设置如下:
Remote cluster, 从集群对leader 的设置。
Leader index,主集群的索引。
Follower index,从集群的索引名称,与 Leader index 是一一对应的关系,是从 Leader 索引复制过来的数据。
执行成功后截图如下:
检查是否成功:
GET /kibana_sample_data_logs_from_leader/_ccr/stats以上,跨集群同步设置成功之后,可以进一步做很多验证。
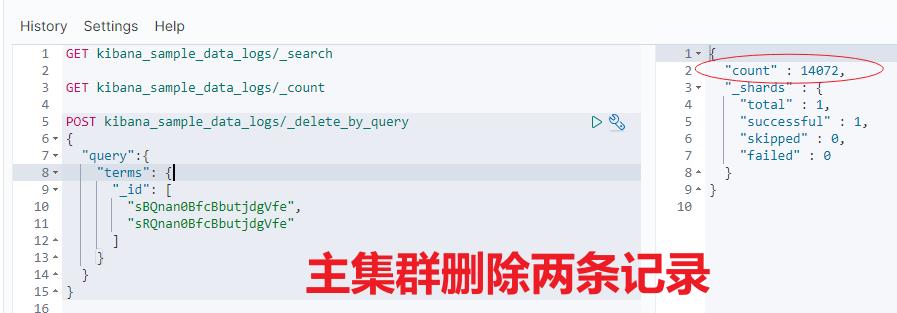
比如:主集群 leader 索引删除两条数据,从集群查看结果。对比发现,从集群也会跟着变化,这说明了跨集群复制已生效。

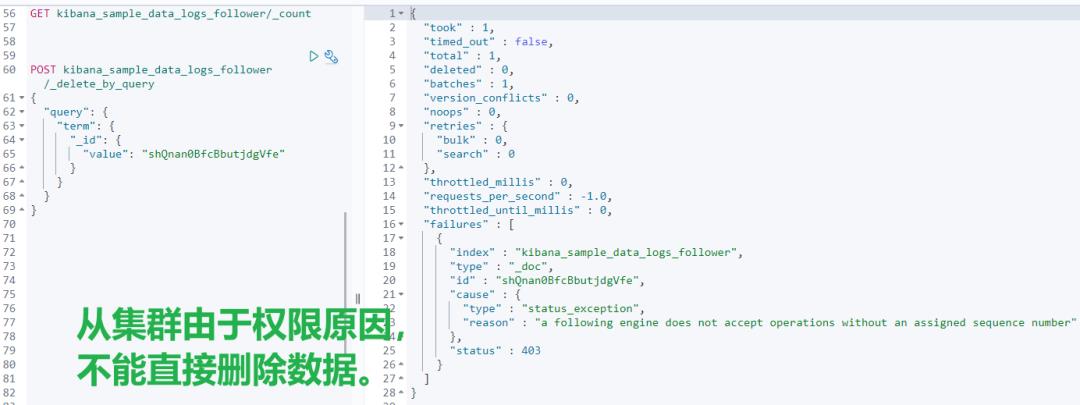
更多权限设置,推荐阅读:https://www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html
7、跨集群复制常用命令清单
包含但不限于:检查复制进度、暂停和恢复复制、重新创建跟随者索引和终止复制。
7.1 检查复制进度

GET /kibana_sample_data_logs_from_leader/_ccr/stats7.2 暂停和恢复复制

POST kibana_sample_data_logs_from_leader/_ccr/pause_follow
POST kibana_sample_data_logs_from_leader/_ccr/resume_follow
7.3 重新创建跟随者索引
分三步骤:
#暂停
POST /follower_index/_ccr/pause_follow
#关闭
POST /follower_index/_close?wait_for_active_shards=0
#重建
PUT /follower_index/_ccr/follow?wait_for_active_shards=1
"remote_cluster" : "remote_cluster",
"leader_index" : "leader_index"
7.4 终止复制
需要先暂停、然后关闭,最后终止复制。
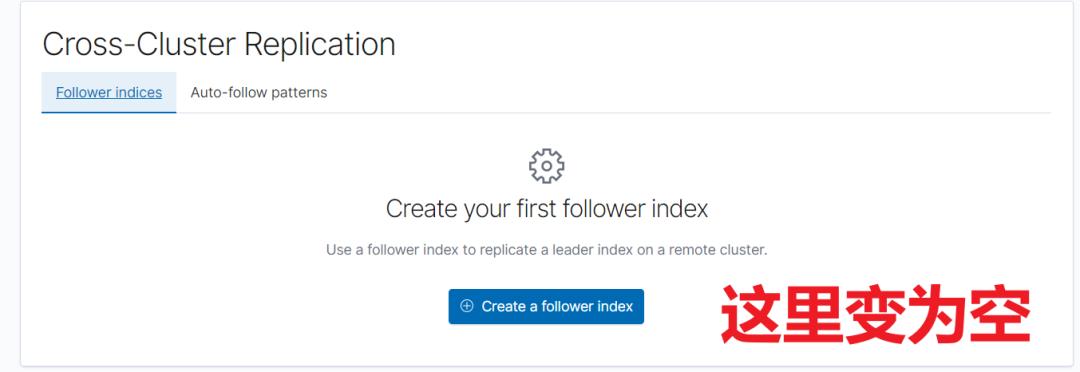
POST kibana_sample_data_logs_from_leader/_ccr/unfollow8、小结
实战出真知,由于这部分是收费功能,可能会用的少。这块一直是新知盲点,实战一把,才知道究竟!
针对data stream 数据流的处理,跨集群也是支持的,限于篇幅原因,本文没有展开,更多内容推荐阅读官方文档。
耗时12小时+,希望对你有帮助!
参考
1、https://www.elastic.co/cn/blog/follow-the-leader-an-introduction-to-cross-cluster-replication-in-elasticsearch
2、https://opendistro.github.io/for-elasticsearch/blog/releases/2021/02/announcing-ccr/
3、https://www.elastic.co/guide/en/elasticsearch/reference/current/xpack-ccr.html
4、https://www.elastic.co/cn/blog/bi-directional-replication-with-elasticsearch-cross-cluster-replication-ccr
5、https://opster.com/blogs/elasticsearch-cross-cluster-replication-overview/
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
更短时间更快习得更多干货!
已带领72位球友通过 Elastic 官方认证!
中国仅通过百余人

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 主从同步之跨集群复制的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 快照生命周期管理 (SLM) 实战指南
Elasticsearch 快照生命周期管理 (SLM) 实战指南