强化学习强化学习/增强学习/再励学习介绍
Posted 产业智能官
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习强化学习/增强学习/再励学习介绍相关的知识,希望对你有一定的参考价值。
Deepmind团队在17年12月5日发布的最新Alpha Zero中,非常重要的一种方法就是强化学习(reinforcement learning),又称再励学习、评价学习,是一种重要的机器学习方法,靠自身的经历进行学习。通过这种方式,RLS在行动-评价的环境中获得知识,改进行动方案以适应环境。正因为可以在小数据量的情况下靠自身的行动获得经验,所以Alpha Zero可以通过自我对弈进行学习提高。深度学习的一种分类方式:监督学习、无监督学习、半监督学习、强化学习。
基本原理
强化学习是从动物学习、参数扰动自适应控制等理论发展而来,其基本原理是:如果Agent的某个行为策略导致环境正的奖赏(强化信号),那么Agent以后产生这个行为策略的趋势便会加强。Agent的目标是在每个离散状态发现最优策略以使期望的折扣奖赏和最大。强化学习把学习看作试探评价过程,Agent选择一个动作用于环境,环境接受该动作后状态发生变化,同时产生一个强化信号(奖或惩)反馈给Agent,Agent根据强化信号和环境当前状态再选择下一个动作,选择的原则是使受到正强化(奖)的概率增大。选择的动作不仅影响立即强化值,而且影响环境下一时刻的状态及最终的强化值。如图所示。

简单来说就是给你一只小白鼠在迷宫里面,目的是找到出口,如果他走出了正确的步子,就会给它正反馈(糖),否则给出负反馈(点击),那么,当它走完所有的道路后。无论比把它放到哪儿,它都能通过以往的学习找到通往出口最正确的道路。
RL最重要的3个特点在于:(1)基本是以一种闭环的形式;(2)不会直接指示选择哪种行动(actions);(3)一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
总的来说,RL与其他机器学习算法不同的地方在于:其中没有监督者,只有一个reward信号;反馈是延迟的,不是立即生成的;时间在RL中具有重要的意义;agent的行为会影响之后一系列的data。
模型设计
一种RL(reinforcement learning) 的框架:
--------------------------------
for
1. 观测到数据
2. 选择action
3. 得到损失
目标是最小化损失
--------------------------------

以吃豆子游戏为例,解释一下模型设计的主要元素,输入输出如下所示:
输入:
状态(State)=环境,例如迷宫中的每一格是一个state,例如(1,3)
动作(Action)=在每个状态下,有什么行动是容许的,例如{上、下、左、右}
奖励(Rewards)=进入每个状态时,能带来正面或负面的价值,迷宫中的那格可能有食物(+1),也可能有怪兽(-100)
输出:方案(Policy)=在每个状态下,你会选择哪个行动?
以上四个元素(S A R P)就构成了一个强化学习系统。
AlphaZero的设计中的主要算法之一就是强化学习,原文如下:

在RL问题中,有四个非常重要的概念:
(1)规则(policy)
Policy定义了agents在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射,常用 π来表示。policy可以分为两类:
确定性的policy(Deterministic policy): a=π(s)
随机性的policy(Stochastic policy): π(a|s)=P[At=a|St=t]
其中,t是时间点,t=0,1,2,3,……
St∈S,S是环境状态的集合,St代表时刻t的状态,s代表其中某个特定的状态;
At∈A(St),A(St)是在状态St下的actions的集合,At代表时刻t的行为,a代表其中某个特定的行为。
(2)奖励信号(a reward signal)
Reward就是一个标量值,是每个time step中环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用R来表示。
(3)值函数(value function)
Reward定义的是立即的收益,而value function定义的是长期的收益,它可以看作是累计的reward,常用v来表示。
(4)环境模型(a model of the environment)
整个Agent和Environment交互的过程可以用下图来表示:
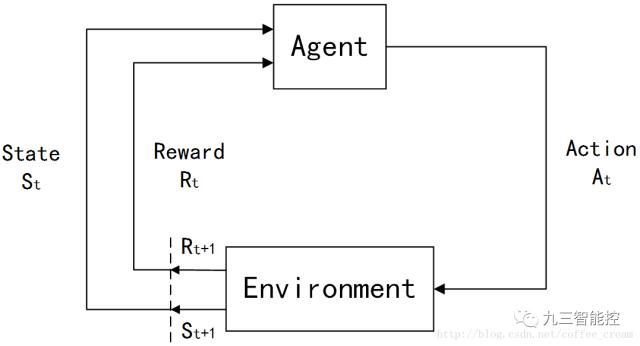
其中,t是时间点,t=0,1,2,3,……
St∈S,S是环境状态的集合;
At∈A(St),A(St)是在状态St下的actions的集合;
Rt∈R∈R 是数值型的reward。
强化学习主要方法简介
强化学习的方法可以从不同维度进行分类:
是否需要对环境理解:model free和model-based
基于概率(Policy-based)和基于价值(Value-based)的RL
回合更新(monte-carlo update)和单步更新(temporal-difference update)的RL
在线学习(on-policy)和离线学习(off-policy)
无论从哪个角度分类,主要的方法有: policy gradients、q learning、sarsa 、 actor-critic、Monte-carlo learning、 Deep-Q-Network
这里强烈推荐一个简洁清晰的介绍视频,6分钟直接明了的说明各种方法的特点:
莫烦python:http://v.youku.com/v_show/id_XMTkyMDY5MTk2OA==.html
应用案例及python代码
有很多种场景应用的都是强化学习,AlphaZero最为出名,其他还有直升机特技飞行、机器人行走、玩游戏比人类还要好等等。
举个栗子:我们想要实现的,就是一个这样的小车。小车有两个动作,在任何一个时刻可以向左运动,也可以向右运动,我们的目标是上小车走上山顶。一开始小车只能随机地左右运动,在训练了一段时间之后就可以很好地完成我们设定的目标了 。
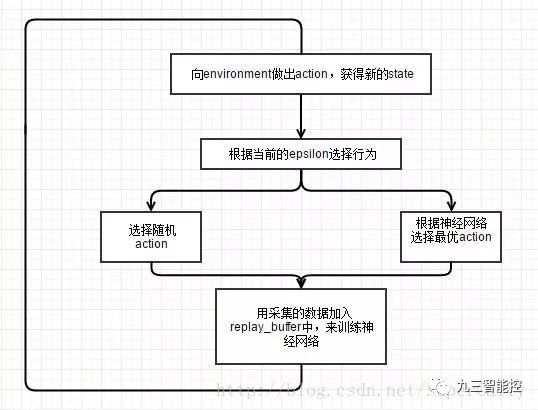
我们使用的算法就是最简单的Deep Q Learning算法,算法的流程如下图所示。
完整代码如下:
import tensorflow as tf
import numpy as np
import gym
import randomfrom collections
import deque
EPISDOE = 10000STEP = 10000ENV_NAME = 'MountainCar-v0'BATCH_SIZE = 32INIT_EPSILON = 1.0FINAL_EPSILON = 0.1REPLAY_SIZE = 50000TRAIN_START_SIZE = 200GAMMA = 0.9def get_weights(shape):
weights = tf.truncated_normal( shape = shape, stddev= 0.01 ) return tf.Variable(weights)def get_bias(shape):
bias = tf.constant( 0.01, shape = shape ) return tf.Variable(bias)class DQN():
def __init__(self,env):
self.epsilon_step = ( INIT_EPSILON - FINAL_EPSILON ) / 10000
self.action_dim = env.action_space.n
print( env.observation_space )
self.state_dim = env.observation_space.shape[0]
self.neuron_num = 100
self.replay_buffer = deque()
self.epsilon = INIT_EPSILON
self.sess = tf.InteractiveSession()
self.init_network()
self.sess.run( tf.initialize_all_variables() ) def init_network(self):
self.input_layer = tf.placeholder( tf.float32, [ None, self.state_dim ] )
self.action_input = tf.placeholder( tf.float32, [None, self.action_dim] )
self.y_input = tf.placeholder( tf.float32, [None] )
w1 = get_weights( [self.state_dim, self.neuron_num] )
b1 = get_bias([self.neuron_num])
hidden_layer = tf.nn.relu( tf.matmul( self.input_layer, w1 ) + b1 )
w2 = get_weights( [ self.neuron_num, self.action_dim ] )
b2 = get_bias( [ self.action_dim ] )
self.Q_value = tf.matmul( hidden_layer, w2 ) + b2
value = tf.reduce_sum( tf.mul( self.Q_value, self.action_input ), reduction_indices = 1 )
self.cost = tf.reduce_mean( tf.square( value - self.y_input ) )
self.optimizer = tf.train.RMSPropOptimizer(0.00025,0.99,0.0,1e-6).minimize(self.cost) return
def percieve(self, state, action, reward, next_state, done):
one_hot_action = np.zeros( [ self.action_dim ] )
one_hot_action[ action ] = 1
self.replay_buffer.append( [ state, one_hot_action, reward, next_state, done ] ) if len( self.replay_buffer ) > REPLAY_SIZE:
self.replay_buffer.popleft() if len( self.replay_buffer ) > TRAIN_START_SIZE:
self.train() def train(self):
mini_batch = random.sample( self.replay_buffer, BATCH_SIZE )
state_batch = [data[0] for data in mini_batch]
action_batch = [data[1] for data in mini_batch]
reward_batch = [ data[2] for data in mini_batch ]
next_state_batch = [ data[3] for data in mini_batch ]
done_batch = [ data[4] for data in mini_batch ]
y_batch = []
next_state_reward = self.Q_value.eval( feed_dict = self.input_layer : next_state_batch ) for i in range( BATCH_SIZE ): if done_batch[ i ]:
y_batch.append( reward_batch[ i ] ) else:
y_batch.append( reward_batch[ i ] + GAMMA * np.max( next_state_reward[i] ) )
self.optimizer.run(
feed_dict =
self.input_layer:state_batch,
self.action_input:action_batch,
self.y_input:y_batch
) return
def get_greedy_action(self, state):
value = self.Q_value.eval( feed_dict = self.input_layer : [state] )[ 0 ] return np.argmax( value ) def get_action(self, state):
if self.epsilon > FINAL_EPSILON:
self.epsilon -= self.epsilon_step if random.random() < self.epsilon: return random.randint( 0, self.action_dim - 1 ) else: return self.get_greedy_action(state)def main():
env = gym.make(ENV_NAME)
agent = DQN( env ) for episode in range(EPISDOE):
total_reward = 0
state = env.reset() for step in range(STEP):
env.render()
action = agent.get_action( state )
next_state, reward, done, _ = env.step( action )
total_reward += reward
agent.percieve( state, action, reward, next_state, done ) if done: break
state = next_state print 'total reward this episode is: ', total_rewardif __name__ == "__main__":
main()如想了解算法关键设定,请参考CSDN杨思达zzz:http://blog.csdn.net/supercally/article/details/54767499
学习资源
授人以渔,分享以下强化学习的相关学习资源:
1. Udacity课程1:Machine Learning: Reinforcement Learning,以及更深入的Udacity课程2:Reinforcement Learning
2. 经典教科书:Sutton & Barto Textbook: Reinforcement Learning: An Introduction 网页中可免费下载新版(第二版)初稿
3. UC Berkeley开发的经典的入门课程作业-编程玩“吃豆人”游戏:Berkeley Pac-Man Project (CS188 Intro to AI)
4. Stanford开发的入门课程作业-简化版无人车驾驶:Car Tracking (CS221 AI: Principles and Techniques)
5.CS 294: Deep Reinforcement Learning, Fall 2015 CS 294 Deep Reinforcement Learning, Fall 2015。课程安排和资料很好。推荐最为RL进阶学习。
注:以上Berkeley和Stanford的课程项目都是精心开发的课程作业,已经搭建好了基础代码,学习者可专注于实现核心算法,并且有自动评分程序(auto-grader)可以自测。
参考资料: