ClickHouse为什么这么快?Hyperscan 超扫描算法:用于现代CPU的“快速-多模式”正则表达式匹配器...
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse为什么这么快?Hyperscan 超扫描算法:用于现代CPU的“快速-多模式”正则表达式匹配器...相关的知识,希望对你有一定的参考价值。
A SIMD instruction executes the same operation on multiple data in parallel.

A SIMD Operation
A SIMD operation is performed on multiple lanes of two SIMD registers independently, and the results are stored in the third register. Modern CPU supports a number of SIMD instructions that can work on specialized vector registers (SSE, AVX, etc.). The latest AVX512 instructions support up to 512-bit operations simultaneously.
一次 SIMD 操作是对两个 SIMD 寄存器的多个通道独立进行,然后结果存储在第三个寄存器中。现代 CPU 支持可以在专用向量寄存器(SSE、AVX 等)上运行的 SIMD 指令。最新的 AVX512 指令最多可同时支持 512 位操作。
Hyperscan 超扫描算法:用于现代CPU的“快速-多模式”正则表达式匹配器
Hyperscan: A Fast Multi-pattern Regex Matcher for Modern CPUs
Regular expression matching serves as a key functionality of modern network security applications. Unfortunately, it often becomes the performance bottleneck as it involves
compute-intensive scan of every byte of packet payload. With trends towards increasing network bandwidth and a large ruleset of complex patterns, the performance re-quirement gets ever more demanding. In this paper, we present Hyperscan, a high performance regular expression matcher for commodity server machines.
Hyperscan employs two core techniques for efficient pattern matching.
- First, it exploits graph decomposition that translates regular expression matching into a series of string and finite automata matching. Unlike existing solutions, string matching becomes a part of regular expression matching, eliminating duplicate operations. Decomposed regular expression components also increase the chance of fast DFA matching as they tend to be smaller than the original pattern.
- Second, Hyperscan accelerates both string and finite automata matching using SIMD operations, which brings substantial through-put improvement.
Our evaluation shows that Hyperscan improves the performance of Snort by a factor of 8.7 for a real traffic trace.
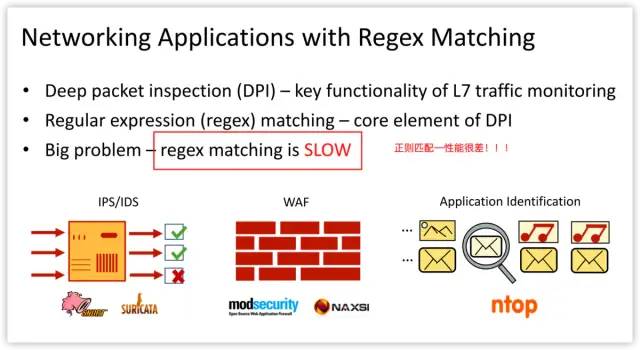
Deep packet inspection (DPI) provides the fundamental functionality for many middlebox applications that deal with L7 protocols, such as intrusion detection systems (IDS)。

Despite continued efforts, the performance of regex matching on a commodity server still remains impractical to directly serve today’s large network bandwidth. Instead, the de-facto best practice of high-performance DPI generally employs multi-string pattern matching as a pre-condition for expensive regex matching.
This hybrid approach (or prefiltering) is attractive as multi-string matching is known to outperform multi-regex matching by two orders of magnitude , and most input traffic is innocent, making it more efficient to defer a rigorous check. For example, popular IDSes like Snort and Suricata specify a string pattern per each regex for prefiltering, and launch the corresponding regex matching only if the string is found in the input stream.
尽管一直在努力,商品服务器上的正则表达式匹配的性能仍然不适合直接服务于当今的大网络带宽。相反,高性能DPI的实际最佳实践,通常采用多字符串模式匹配作为昂贵的正则表达式匹配的先决条件。
这种混合方法(或预过滤)很有吸引力,因为众所周知,多字符串匹配的性能比多正则表达式匹配高出两个数量级,而且大多数输入流量都是无辜的,这使得推迟严格检查更加有效。例如,像Snort和Suricata这样的流行IDSes,为每个正则表达式指定一个用于预过滤的字符串模式,并且,只有在输入流中找到字符串时,才启动相应的正则表达式匹配。
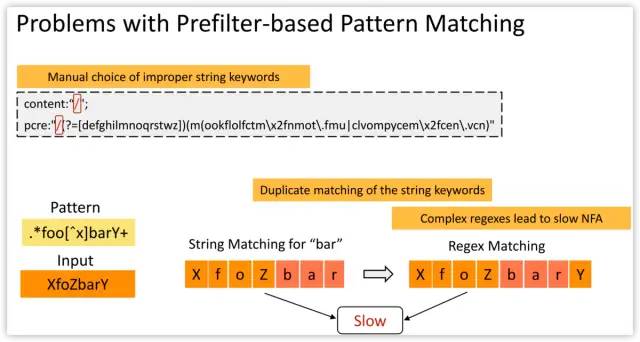
However, the current prefilter-based matching has a number of limitations.
First, string keywords are often defined manually by humans. Manual choice does not scale as the ruleset expands over time, and improper keywords would waste CPU cycles on redundant regex matching.
Second, string matching and regex matching are executed as two separate tasks, with the former leveraged only as a trigger for the latter. This results in duplicate matching of the string keywords when the corresponding regex matching is executed.
Third, current regex matching typically translates an entire regex into a single finite automaton (FA). If the number of deterministic finite automaton (DFA) states becomes too large, one must resort to a slower non-deterministic finite automaton (NFA) for matching of the whole regex.
然而,当前基于前置滤波器的匹配有许多限制。
首先,字符串关键字,通常由人手工定义。手动选择不会随着规则集随着时间的推移而扩展,不正确的关键字,会在冗余的正则表达式匹配上浪费CPU周期。
其次,字符串匹配和正则表达式匹配,作为两个独立的任务执行,前者仅作为后者的触发器。当执行相应的正则表达式匹配时,这会导致字符串关键字的重复匹配。
第三,当前正则表达式匹配,通常将整个正则表达式转换为单个有限自动机(FA)。如果确定型有穷自动机(DFA)状态的数目过大,则必须使用较慢的非确定型有穷自动机(NFA)来匹配整个正则表达式。

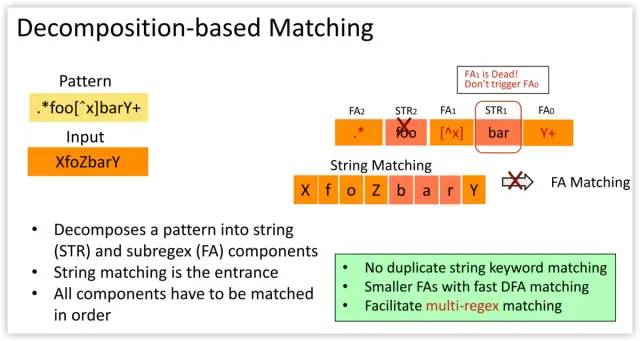
Hyperscan, a high performance regex matching system that exploits regex decomposition as the first principle. Regex decomposition splits a regex pattern into a series of disjoint string and FA components。
This translates regex matching into a sequence of decomposed subregex matching whose execution and matching order is controlled by fast string matching.
超扫描,一个高性能正则表达式匹配系统,利用正则表达式分解作为第一原则。正则表达式分解将正则表达式模式拆分为一系列不相交的字符串和FA组件。
这将正则表达式匹配转换为分解的子正则表达式匹配序列,其执行和匹配顺序由快速字符串匹配控制。
This design brings a number of benefits.
First, our regex decomposition identifies string components automatically by performing rigorous structural analyses on the NFA graph of a regex. Our algorithm ensures that the extracted strings are pre-requisite for the rest of regex matching.
Second, string matching is run as a part of regex matching rather than being employed only as a trigger. Unlike the prefilter-based design, Hyperscan keeps track of the state of string matching throughout regex matching and avoids any redundant operations.
Third, FA component matching is executed only when all relevant string and FA components are matched. This eliminates unnecessary FA component matching, which allows efficient CPU utilization.
Finally, most decomposed FA components tend to be small, so they are more likely to be able to be converted to a DFA and benefit from fast DFA matching.
这种设计带来了许多好处。
首先,正则表达式分解,通过对正则表达式的NFA图,执行严格的结构分析,来自动识别字符串组件。算法确保提取的字符串是正则表达式匹配其余部分的先决条件。
其次,字符串匹配,作为正则表达式匹配的一部分运行,而不是仅作为触发器使用。与基于前置过滤器的设计不同,Hypercan在整个正则表达式匹配过程中,跟踪字符串匹配的状态,并避免任何冗余操作。
第三,FA组件匹配,仅在匹配所有相关字符串和FA组件时执行。这消除了不必要的FA组件匹配,从而允许高效的CPU利用率。
最后,大多数分解的FA组件往往很小,因此它们更有可能转换为DFA,并受益于快速的DFA匹配。


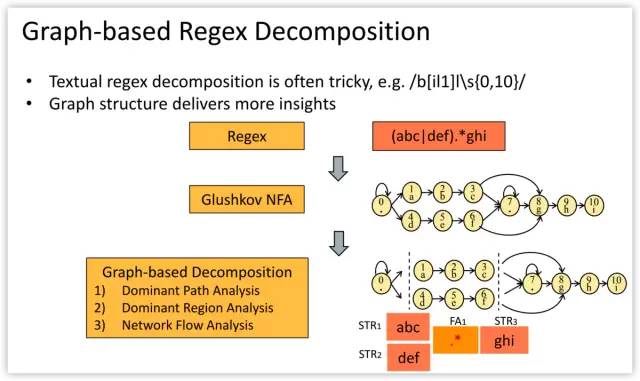
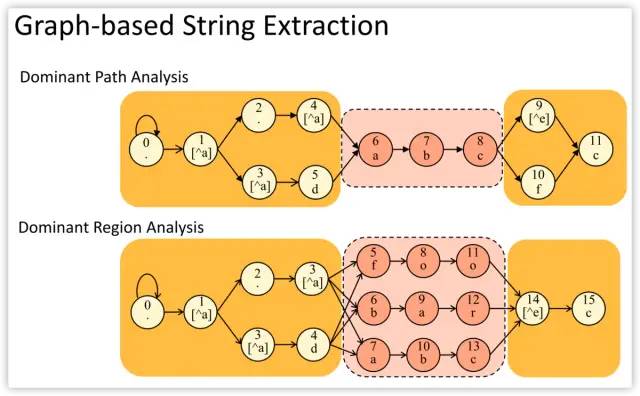
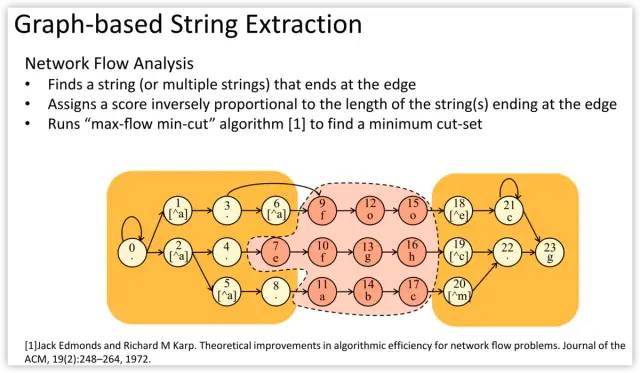

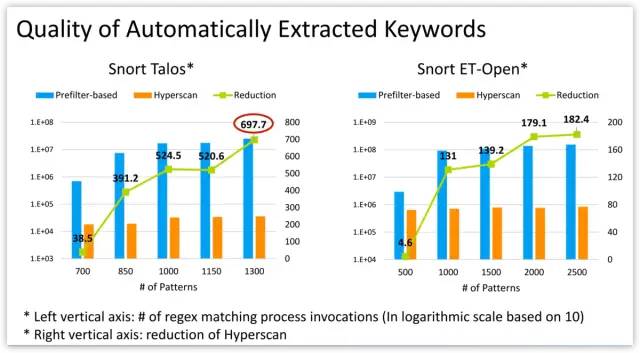

Beyond the benefits of regex decomposition, Hyperscan also brings a significant performance boost with single-instruction-multiple-data (SIMD) accelerated pattern matching algorithms.

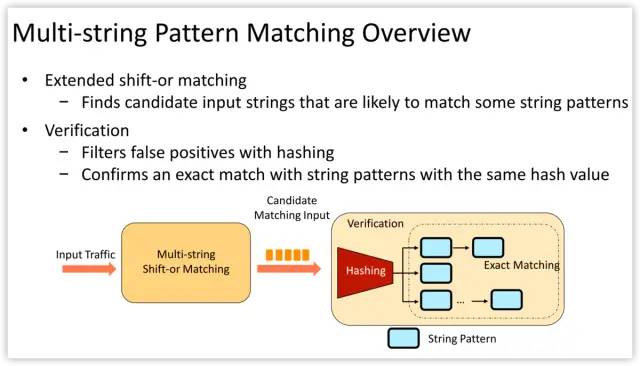
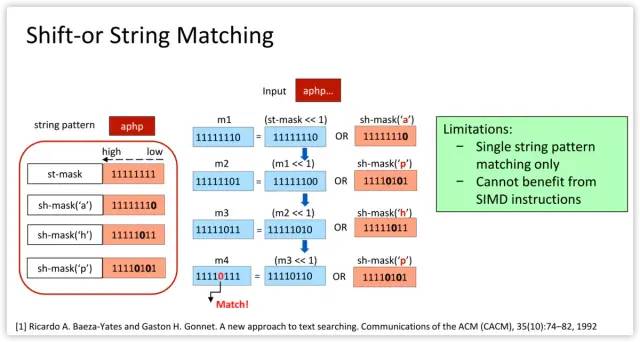
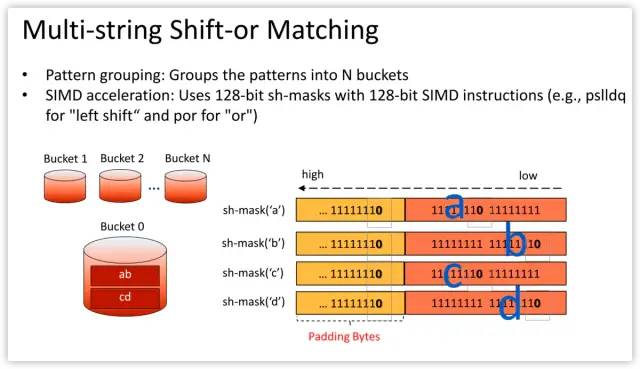

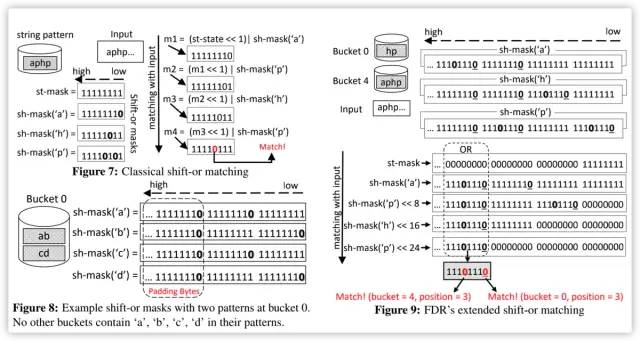
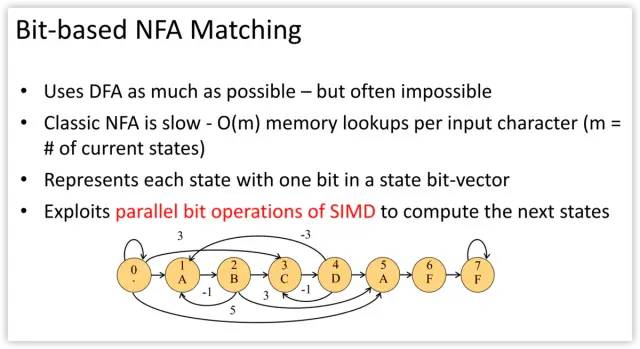
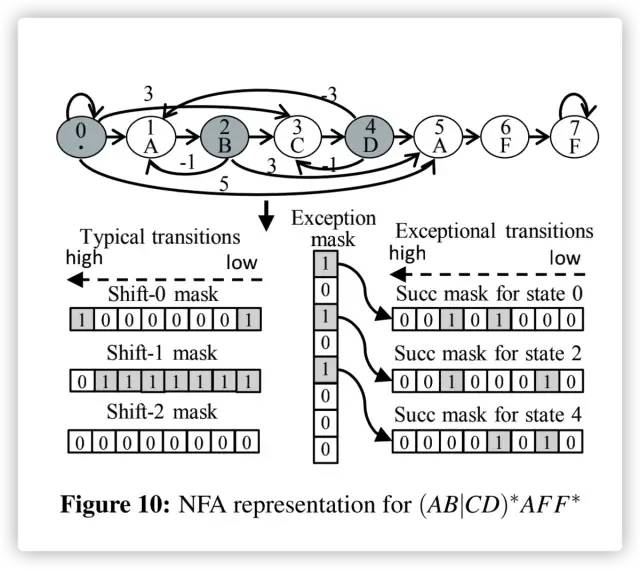


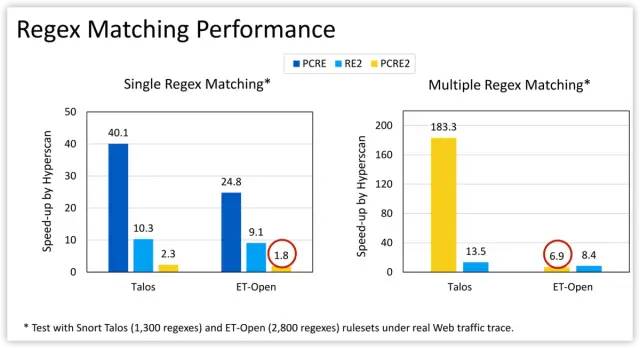
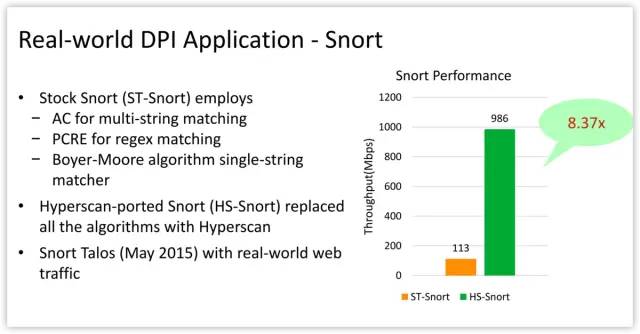

Source code at https://github.com/intel/hyperscan
参考资料:
https://github.com/intel/hyperscan
Hyperscan is a high-performance multiple regex matching library. It follows the regular expression syntax of the commonly-used libpcre library, but is a standalone library with its own C API.
Hyperscan uses hybrid automata techniques to allow simultaneous matching of large numbers (up to tens of thousands) of regular expressions and for the matching of regular expressions across streams of data.
Hyperscan is typically used in a DPI library stack.
https://www.usenix.org/sites/default/files/conference/protected-files/nsdi19_slides_wang_xiang.pdf
https://www.youtube.com/watch?v=Le67mP-jIa8
https://www.usenix.org/conference/nsdi19/presentation/wang-xiang
https://www.usenix.org/system/files/nsdi19-wang-xiang.pdf
http://intel.github.io/hyperscan/dev-reference/getting_started.html#very-quick-start
以上是关于ClickHouse为什么这么快?Hyperscan 超扫描算法:用于现代CPU的“快速-多模式”正则表达式匹配器...的主要内容,如果未能解决你的问题,请参考以下文章