使用哪些工具,可以提升 Python 项目质量?
Posted Python猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用哪些工具,可以提升 Python 项目质量?相关的知识,希望对你有一定的参考价值。

作者:so1n;来源:博海拾贝diary
前记
在编写项目时,都会对代码质量有一定的追求, 比如代码艺术、设计模式、 重构设计等等。但是一个良好 Python 项目除了程序员本身的代码质量能力之外, 还有系统设计和代码质量工具等等。不过由于每个系统的设计都会有一些不同, 系统设计需要程序员一定的经验, 需要跟着项目去一起成长。
代码质量工具可以都抽离出来,应用到每个项目中, 本文则是我对这些代码质量工具的简要使用总结。
原文连接:https://so1n.me/2021/08/10/%E4%BF%9D%E9%9A%9CPython%E9%A1%B9%E7%9B%AE%E8%B4%A8%E9%87%8F%E7%9A%84%E5%B7%A5%E5%85%B7
0.提交代码规范
每个团队或个人, 都必须要有一套自己的分支管理和提交代码规范, 对于分支管理, 一般会选用git flow, 如果不太会使用, 前期可以使用git flow 备忘清单(https://danielkummer.github.io/git-flow-cheatsheet/index.zh_CN.html), 并且对于master, develop等分支设置一些权权限。另外提交的信息也要有对应的规范, 比如本次提交属于哪种类型, 本次提交的功能是什么等等, 但是这个提交规范往往都没有一个标准, 只要团队和个人用的顺心, 能通过这些规范来减少开发矛盾, 复盘代码等等即可。我常使用的是:
git commit -m"<issue_id>:<file change>:<operating>:<info>"其中每个字段代表的含义如下:
issue_id: 代表一个issue的id, 在准备写功能或者修复一个bug时,都应该先提一个issue, 这个issue要详细的写明要修改什么,达到什么目的,然后再针对这个issue提交代码
file change: 代表文件的变化, 如增加, 删除, 修改;也有人使用
+,-,*来分别代表增加, 删除, 修改operating: 代表本次代码变化, 具体有如下几种
feat:新功能
fix:修复bug
doc:文档改变
style:代码格式改变
refactor:某个已有功能重构
perf:性能优化
test:增加测试
build:改变了build工具 如 grunt换成了 npm
revert:撤销上一次的commit
info: 简要的说明本次提交信息
1.项目环境管理-Poetry
一个项目最重要的就是跑起来, 而大家基本会同时在本地开发多个项目, 每个项目用到的环境都是不一样的, 所以就需要用到虚拟环境隔离。在Python中提供了一个叫venv的虚拟环境管理包,他非常稳定, 同时功能也不是很多, 一般只用在服务器上, 对于本地开发来说, 都会想要更多的功能, 更加方便的对虚拟环境, 依赖包进行管理, Python包管理领域相关工具很多, 包括争议很大的Pipenv, 我在经过多种尝试后, 觉得Poetry比较好用, 坑也比较少。
Poetry(https://python-poetry.org/)官网的简介就是让Python包安装和依赖管理变得容易, 我觉得Poetry是最好用的, 他不止对包管理有很多的支持, 还有其他的拓展功能, 如方便的打包和发布, 脚本简写等等。
在第一次大多数的Python项目编写中, 基本上都是按以下流程进行:
1.安装对应的Python版本
2.通过
python -m venv <name>的方式在项目创建venv的虚拟环境3.在使用的过程中通过
python -m pip install <name>的方式安装依赖4.在代码编写完毕后通过
python -m pip freeze > requirements.txt生成依赖文件
而Poetry则十分简单, 以下是poetry的创建流程:
1.1.创建项目
通过命令poetry new就可以创建一个项目手脚架
➜ poetry new example
➜ tree
.
└── example
├── example
│ └── __init__.py
├── pyproject.toml
├── README.rst
└── tests
├── __init__.py
└── test_example.py
3 directories, 5 files可以看到Poetry创建了一个example的项目, 生成了对应的文件夹以及包括项目信息的pyproject.toml。如果在已有项目, 则通过命令poetry init来初始化:
➜ example poetry init
This command will guide you through creating your pyproject.toml config.
# 交互bash, 通过该交互bash填写项目信息。
Package name [example]: example
Version [0.1.0]: 0.0.8
Description []: example project
Author [so1n <qaz6803609@163.com>, n to skip]: n
License []:
Compatible Python versions [^3.7]:
Would you like to define your main dependencies interactively? (yes/no) [yes] no
Would you like to define your development dependencies interactively? (yes/no) [yes] no
Generated file
# 填写完项目信息后会生成以下内容, 之后会在刚才的路径创建pyproject.toml文件, 并写入。
[tool.poetry]
name = "example"
version = "0.0.8"
description = "example project"
authors = ["Your Name <you@example.com>"]
[tool.poetry.dependencies]
python = "^3.7"
[tool.poetry.dev-dependencies]
[build-system]
requires = ["poetry-core>=1.0.0"]
build-backend = "poetry.core.masonry.api"
Do you confirm generation? (yes/no) [yes] yes1.2.创建虚拟环境
Poetry默认使用系统默认的Python环境, 不过可以通过poetry env use <python version>来指定Python版本, 之后就创建了一个虚拟环境了。默认的虚拟环境配置是存放在/home/user/.cache/pypoetry目录的, 可以直接查看配置了解:
➜ poetry config --list
# poetry使用的缓存目录的路径
cache-dir = "/home/so1n/.cache/pypoetry"
experimental.new-installer = true
installer.parallel = true
# 默认值为true,如果执行 poetry install/poetry add时没有虚拟环境,就自动创建一个虚拟环境,设置为false的话,当虚拟环境不存在时,会将包安装到系统环境
virtualenvs.create = true
# 默认值为false,设置为true的话,会在当前项目目录下创建虚拟环境
virtualenvs.in-project = false
# 虚拟环境的路径,默认路径 cache-dir\\virtualenvs
virtualenvs.path = "cache-dir/virtualenvs" # /home/so1n/.cache/pypoetry/virtualenvs而默认的使用习惯(包括一些第三方包) 都是认为venv是创建在项目路径下的, 同时这也方便管理。poetry可以通过如下命令进行更改后再创建虚拟环境,达到在项目路径下创建虚拟环境的效果:
# 更改配置
➜ poetry config virtualenvs.in-project true在虚拟环境创建好后可以通过
➜ poetry run <commod>来执行想要运行的命令或者调用Python包, 也可以通过poetry shell启动一个被虚拟环境包裹的交互shell.
1.3.安装依赖
虚拟环境创建好后, 就可以安装依赖了, 可以直接使用poetry的add命令安装依赖, 其中带有--dev表示他是开发环境依赖包(开发环境依赖包和生成环境依赖包区分是很有益的):
➜ poetry add flask
➜ poetry add pytest --dev安装依赖后可以看到pyproject.toml文件发生变动:
...
[tool.poetry.dependencies]
python = "^3.7"
Flask = "^1.1.2"
[tool.poetry.dev-dependencies]
pytest = "^6.2.4"
...文件中多了刚刚安装的flask依赖和pytest依赖, 且pytest依赖是属于dev依赖。在后面还可以通过poetry的命令生成对应的生产环境依赖文件requirement.txt和测试环境依赖文件requirements-dev.txt:
# 生产环境
poetry export -o requirements.txt --without-hashes --with-credentials
# 测试环境
poetry export -o requirements-dev.txt --without-hashes --with-credentials --dev这样区分测试环境和生产环境的依赖可以尽量的减少测试需要的依赖包对生成环境造成影响。
除了增加依赖外, poetry还支持很多种依赖操作方法, 具体如下:
# 查看依赖
poetry show
# 以树形结构查看依赖
poetry show -t
# 更新所有锁定版本的依赖
poetry update
# 更新指定的依赖
poetry update flask
# 删除依赖
poetry remove flask1.4.其他
对于一般的自用Python项目来说, 上面的poetry操作已经够了, 如果需要发布自己的包到pypi, 或者安装github最新的并未发布的包则可以使用他的其他拓展命令, 具体可以见文档(https://python-poetry.org/docs/)。个人觉得poetry已经非常优秀了, 但是由于缺少一个稳定的维护团队, 所以难免有bug, 这时候可以采用降级的方法解决, 比如安装依赖失败, 则可以使用poetry run pip install安装包, 再手动补上pyproject.yml文件。
2.代码质量工具
在大型的项目中, 一般都不追求花哨的代码, 而是追求稳定, 容易理解, 复杂度低的代码, 最完美的代码应该是入行的人一看就能理解, 又能完美的解决需求。但是人无完人, 很多时候在写代码可能会出现一些小问题, 而这些小问题靠人来检查是费时费力的, 同时又很难排查出来,这时就需要代码检查工具了。一般代码检查工具分为三类, 一类是检查代码风格, 并把不标准的代码风格格式化为标准的代码风格;另一类则是代码逻辑检查,他会检查代码逻辑, 代码复杂度, 引用的包是否有问题等等, 最后一类是代码安全检查, 比如是否在代码中引入密钥, 或者像在Python代码中写eval函数等。
2.1.flake8
Flake8 是由Python官方发布的一款辅助检测Python代码是否规范的工具,相对于目前热度比较高的Pylint来说,Flake8检查规则灵活,支持集成额外插件,扩展性强。Flake8是对下面三个工具的封装:
1.PyFlakes:静态检查Python代码逻辑错误的工具。
2.Pep8:静态检查PEP8编码风格的工具。
3.NedBatchelder’s McCabe :静态分析Python代码复杂度的工具。
Flake8除了支持上面3种功能外, 还支持通过插件的方式引入其他功能, 比如使用flake8-docstrings强制要求编写函数docstring等。
在项目中可以通过poetry add flake8 --dev引入flake8到dev依赖, 然后通过在根目录增加.flake8文件:
[flake8]
# 适当提高最大行长度
max-line-length = 120
# 设置最大复杂度
max-complexity = 24
# 忽略这些错误类型
ignore = F401, W503, E203
# 忽略以下文件
exclude =
.git,
.venv,
__pycache__,
scripts,
logs,
upload,
build,
dist,
docs,
migrations,指定Flke8该如何执行, 最后调用命令poetry run flake8.即可。
2.2.mypy
毫无疑问, Python的语法让人能简洁的写出代码, 但是他的动态语言特性会使大型项目变得不牢固, 而mypy的出现恰好能解决这一问题。mypy是一个静态类型检查工具,它可以帮助我们像静态语言一样在运行代码之前就捕获到某些错误, 但是我们在写Python代码时, 要像静态语言一样, 会参数写上他的类型, 这就是Type Hints, 通过mypy和Type Hints的结合, 虽然会增加我们的代码量, 但它可以引入如下好处:
1.可以使
IDE通过类型推断提供更好的代码补全和提示功能, 方便项目重构以及提前检查出错误。2.强制你去思考动态语言程序的类型可能会帮助你构建更清晰的代码架构。
比如有如下一个函数:
def foo(a, b):
return a + b一般来说无法知道这个函数要传什么类型的参数进去, 也许一开始是传int变量, 后面变为str变量, 而通过Type Hints则可以指定这个变量的类型是什么, 以及返回的类型是什么, 经过改造后将会变为:
def foo(a: int, b: int) -> int:
return a + b这个函数的a, b参数以及返回的值类型都被标注为int类型, 这时候假如在程序内有两个调用:
foo(1, 2)
foo("a", "b")他们虽然都能运行, 但是可以通过mypy检查出第二种调用方式是错误的。虽然这种示例简简单单, 看不出什么痛点, 但是在复杂的逻辑中, 他的优势就非常明显了。
在项目中可以通过poetry add mypy --dev安装依赖包, 然后通过在根目录增加mypy.ini文件:
# mypy的核心配置
[mypy]
# 指明函数的值类型也要检查
disallow_untyped_defs = True
# 忽略一些import的错误, 有些旧包架构可能不符合mypy的要求
ignore_missing_imports = True
# 指明针对根目录tests的配置
[mypy-tests.*]
# 指明忽略对这个范围的检查
ignore_errors = True指定mypy该如何执行, 最后调用poetry run mypy .即可
2.3.自动格式化代码
Python是一个动态语言, 而且不会对代码风格做强要求, 这就会导致一千个人一千种Python代码风格, 这同样在大型项目中非常糟糕的...好在Python生态中有很多自动格式化的工具, 但这里并不会详细对比他们的差异, 只是简要介绍下我在试用了多种后保留了以下3个工具(适不适合自己团队, 还是得自己试试才知道):
1.autopep8, 这个工具主要用来移除没有使用到的import语句, 这个功能在需要开源的工具包中, autopep8是做得最好的, 但部分场景下可能没有
Pycharm好用,可惜Pycharm只能手动按快捷键一个文件一个文件的格式化... autopep8可以通过poetry add autopep8 --dev进行安装, 它的配置参数十分简单, 所以只提供命令, 没有配置文件, 他的主要命令对应用途如下:--in-place: 直接对文件进行更改, 而不是把差异打印出来(用它就要相信他)--exclude: 排除哪些文件/文件夹不进行格式化--recursive: 递归的遍历文件--remove-all-unused-imports: 删除所有未导入的依赖包--ignore-init-module-imports: 删除所有未导入的包时排除__init__.py文件--remove-unused-variables:删除未使用的变量
2.isort, 这个工具主要是用来给import语句进行格式化, 比如语句超出文件允许最大长度自动换行, 以及对import语句进行自动排序(这个功能对强迫症来说爽飞了)。isort可以通过
poetry add isort --dev进行安装, isort支持pyproject.toml文件配置, 以下是我的一个常用配置:[tool.isort] # 兼容black模式, 因为使用到了black进行自动格式化 profile = "black" # 当import包过多超过文件长度后需要换行时, 采用哪种模式 multi_line_output = 3 include_trailing_comma = true force_grid_wrap = 0 use_parentheses = true ensure_newline_before_comments = true # 每行的最长长度 line_length = 120 # 忽略的文件夹 skip_glob = "tests"3.black, 号称不妥协的自动格式化工具, 只要它认为不合适的, 就自动格式化, 没有选择的余地, 如果与团队标准不一样的请慎用, 我是挺接受他的自动格式化风格的...。black可以通过
poetry add black --dev进行安装, mypy同样支持pyprojrct.toml文件配置, 以下是我的一个常用配置(black的配置项不多):[tool.black] # 每行的最长长度 line-length = 120 # 当前是哪个Python版本 target-version = ['py37']
3.pre-commit
自动格式化的工具引入到项目没多久后就会开始寻求自动化了, 因为每次提交之前都要手动跑一些自动格式化的脚本, 实在是太麻烦了, 好在有pre-commit这个专门为git hooks而生的工具。
pre-commit 是一个用于管理和维护多种语言的 git pre-commit hooks 框架,就像Python的包管理器 pip 一样,可以通过 pre-commit 将他人创建并分享的 pre-commit hooks 安装到自己的项目仓库中。pre-commit 的出现大大减少了我们使用 git hooks 的难度,只需要在配置文件中指定想要的 hooks,它会替你安装任意语言编写的 hooks 并解决环境依赖问题,然后在每次提交前执行hooks。
3.1.安装
一般来说, 通过pip install pre-commit就可以安装了, 但是为了环境隔离, 需要使用 poetry add pre-commit --dev安装, 安装完后就可以在项目根目录创建文件.pre-commit-config.yaml, 以下是我的配置, 除了上面提到的几个工具外, 还有一些其他脚本的校验工具:
repos:
- repo: https://github.com/pre-commit/mirrors-mypy
rev: v0.910
hooks:
- id: mypy
- repo: https://github.com/PyCQA/isort
rev: 5.9.3
hooks:
- id: isort
- repo: https://github.com/psf/black
rev: 21.7b0
hooks:
- id: black
- repo: https://github.com/PyCQA/flake8
rev: 3.9.2
hooks:
- id: flake8
- repo: https://github.com/myint/autoflake
rev: v1.4
hooks:
- id: autoflake
args: ['--recursive', '--in-place', '--remove-all-unused-imports', '--remove-unused-variable']
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: check-ast
- id: check-byte-order-marker
- id: check-case-conflict
- id: check-docstring-first
- id: check-executables-have-shebangs
- id: check-json
- id: check-yaml
- id: debug-statements
- id: detect-private-key
- id: end-of-file-fixer
- id: trailing-whitespace
- id: mixed-line-ending文件中的内容很简单, 它指明使用了哪些工具, 工具是哪个版本, 以及使用哪些hook(一个仓库可能有多个hook), 每个参数的解释如下:
repo: 仓库url, pre-commit通过git来安装存在于github的工具
rev: 每个工具的版本, 这里是利用到git的tag属性
hooks/id: 每个仓库会有很多个hook, 通过hooks-id来选择要使用的hooks
hook/id/args: 每个hook都支持一些参数, args就是配置hook的参数
这些工具都会读取根目录的配置文件, 而autoflake我找不到他的pyproject.toml配置说明, 所以直接通过的args参数配置参数。之后就可以直接调用hook脚本, 如果是第一次引入已有项目则应该先手动调用poetry run pre-commit run --all-files, 他会调用所有hook对项目进行检查, 然后再根据检查结果对代码和配置进行调整。调整完毕之后可以调用poetry run pre-commit install把hook脚本进行安装,它会自动安装在.git/hooks/pre-commit。安装后, 每执行次git commit时, 都会通过git hooks机制自动执行脚本, 自动对代码进行检查和格式化。
上面的配置文件是我的常用配置, pre-commit的hook有很多, 不止这些, 如有兴趣可以到pre-commit hook合集(https://pre-commit.com/hooks.html)查阅所有hook
4.远程仓库自动执行
本地的hook只针对本地提交者, 而在团队协作中, 其他人员可以暂时屏蔽或者删除hook文件, 导致本地hook没办法达到强制的作用, 所以团队一般会在Github&Gitlab中的pre-recevice阶段配置一个自己的脚本, 用来跑上面的代码检测工具, 虽然两种的做法有点不同, 但核心步骤都是一样:
1.先拉取最新的代码到容器里
2.安装阶段, 这时候会向容器安装Python版本以及类似
Redis容器等等3.代码检查, 这时候会运行代码质量检测工具, 如果有一个检测错误, 那么就拒绝提交, 并显示哪里错误了, 如果没有问题就走下一步。
4.测试阶段, 该阶段会运行测试用例,检测测试代码覆盖率是否合格, 同样的, 如果检测不合格就会拒绝提交, 成功就进入下一步。
4.风格统一, 使用风格统一插件, 如Python中的
isort,black等, 把项目的代码进行格式化。
一般每个公司都有自己的一套标准CI/CD, 而他们的使用方法可能都会有些差别, 但核心原理也差不多, 以下会以开源项目为例介绍如何使用Github的action(这个功能是免费的!!!).
Gitlab的CI/CD相关文章比较多, 可以查阅网络或查阅书籍《持续交付》(https://book.douban.com/subject/6862062/), 也可以查看文章:https://www.mindtheproduct.com/what-the-hell-are-ci-cd-and-devops-a-cheatsheet-for-the-rest-of-us/, 如果对Gitlab hook有兴趣可以查阅Gitlab pre-receive webook 的添加与使用(treesir.pub/post/gitlab-pre-receive-webhook)
该例子来自于我的项目rap。首先在项目目录创建script目录, 这里面的目录可以被本地调用, 但主要还是用于Github action, 首先创建一个install的脚本, 这个脚本用于安装依赖包:
#!/bin/sh -e
# Use the Python executable provided from the `-p` option, or a default.
[ "$1" = "-p" ] && PYTHON=$2 || PYTHON="python3"
REQUIREMENTS="requirements-dev.txt"
VENV="venv"
set -x
if [ -z "$GITHUB_ACTIONS" ]; then
"$PYTHON" -m venv "$VENV"
PIP="$VENV/bin/pip"
else
PIP="pip"
fi
"$PIP" install -r "$REQUIREMENTS"注意这里是以venv为虚拟环境依赖的, 而不是我上面提到的poetry. 使用venv的原因是线上一般是一个机器跑一个项目, 同时生产的机器都追求稳定, 这时候venv简单而稳定的好处就体现出来了, 所以比较推荐在线上使用venv。上面这个脚本就是创建一个虚拟环境, 然后根据requirements-dev.txt安装测试环境依赖。
依赖部分搞定了, 接下来就是告诉Github action该如何进行代码质量检查了, 于是编写一个check的脚本:
#!/bin/sh -e
export PREFIX=""
if [ -d 'venv' ] ; then
export PREFIX="venv/bin/"
fi
set -x
echo 'use venv path:' $PREFIX
$PREFIXmypy .
$PREFIXflake8
$PREFIXisort .
$PREFIXblack .
$PREFIXautoflake --in-place --remove-unused-variables --recursive .这个脚本就是简单的调用各个命令, 命令的顺序就如同上面一样, 先进行代码检查, 再跑测试用例, 最后进行代码格式化。这里的命令没有写各个的配置, 因为他们都会自动读取项目下的配置文件, 与我们的本地hook保持一致。
给Github action调用的脚本创建好后, 就开始创建真正的Github action文件了。首先在项目创建.github/workflows目录, 并在.github/workflows目录创建test-suite.yml文件(文件的更多说明见官方文档(https://docs.github.com/cn/actions/learn-github-actions/introduction-to-github-actions)):
---
# 指定workflows名称
name: Test Suite
# 指定操作push到master, 或者提pr到master时才执行
on:
push:
branches: ["master"]
pull_request:
branches: ["master"]
jobs:
tests:
# 设置任务名
name: "Python $ matrix.python-version "
# 选择跑在哪种容器类型
runs-on: "ubuntu-latest"
# 设置变量, 这里设置多个Python版本表示会对每个Python版本都运行一次
strategy:
matrix:
python-version: ["3.6", "3.7", "3.8", "3.9", "3.10.0-beta.3"]
steps:
# 调用官方的检查和安装python版本
- uses: "actions/checkout@v2"
- uses: "actions/setup-python@v2"
with:
python-version: "$ matrix.python-version "
# 更改脚本权限
- name: "Change permissions"
run: |
chmod +x scripts/install
chmod +x scripts/check
# 安装依赖
- name: "Install dependencies"
run: "scripts/install"
# 进行检查
- name: "Run linting checks"
run: "scripts/check"文件编写完毕后就可以推送代码到远程了, 然后就可以到Github对应的项目地址查看action执行情况, 一般成功结果如下(这里只测一个Python3.7, 如果失败了, 你还会收到邮件提醒):
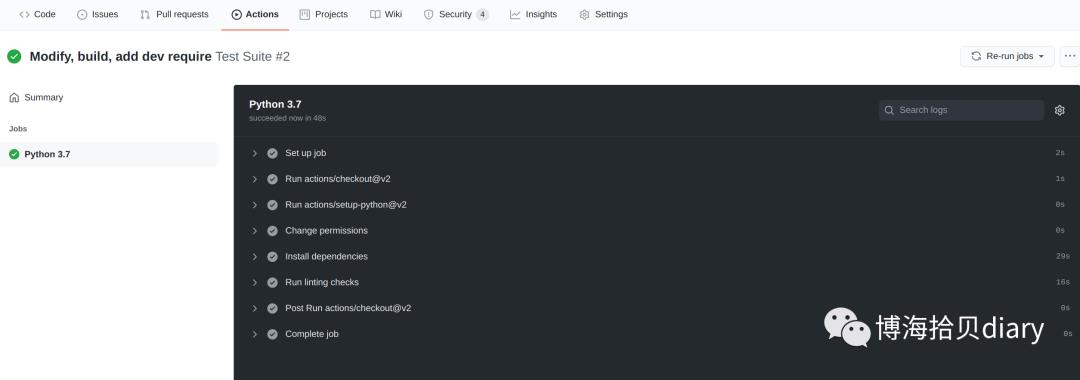
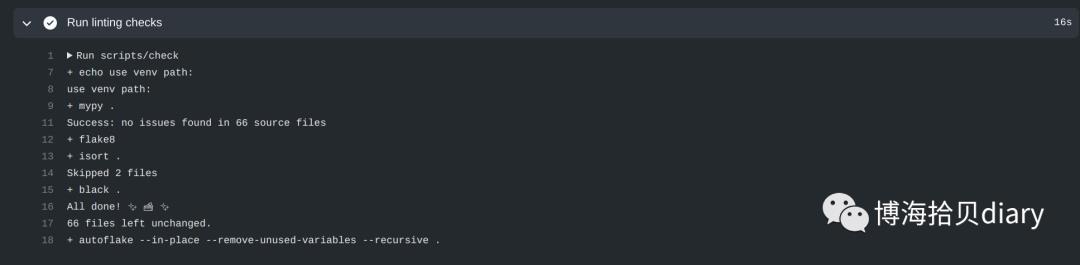
也可以点开查看某个步骤的详情, 比如检查代码的详情:
5.总结
这些工具都是我慢慢实践和整合后找到最符合自己的构建 Python 项目质量的工具集了, 但是这些工具只能检查表面情况, 而其他情况如代码逻辑是否有问题, 则需要编写测试用例后再运行才能知道。
而有些团队甚至会采用压力测试, 线上仿真测试等等, 这些工具/系统的引入和使用初期会带来很大的学习和时间成本, 但它们却能让项目一直保持茁壮成长, 减少线上项目Bug出现的次数(当然这些工具还有测试用例等等也要一起跟着维护)。

Python猫技术交流群开放啦!群里既有国内一二线大厂在职员工,也有国内外高校在读学生,既有十多年码龄的编程老鸟,也有中小学刚刚入门的新人,学习氛围良好!想入群的同学,请在公号内回复『交流群』,获取猫哥的微信(谢绝广告党,非诚勿扰!)~
还不过瘾?试试它们
如果你觉得本文有帮助
请慷慨分享和点赞,感谢啦!
以上是关于使用哪些工具,可以提升 Python 项目质量?的主要内容,如果未能解决你的问题,请参考以下文章