Hadoop实战——MapReduce实现主播的播放量等数据的统计及TopN排序(第二篇)
Posted Yuan-Programmer
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop实战——MapReduce实现主播的播放量等数据的统计及TopN排序(第二篇)相关的知识,希望对你有一定的参考价值。
本次实战项目一共分三篇教学(第三篇下周更新)
第一篇:对主播文本数据的清洗,从大量数据中获取我们所需要的数据(如播放量,时长等)
第二篇:对清洗后的数据进行统计求和处理操作,按照主播id号依次整齐显示
第三篇:对统计好的数据进行TopN展示的操作,排序规则可自定义(如播放量,粉丝数量),N的大小也可以自定义
目录
前言:
在第一篇教学我们已经将主播的数据进行了初步的提取,但是数据看起来杂乱无章,这篇文章教大家如何对提取出来的数据进一步处理
一、流程简介
第一篇提取好的数据如下:
通过文本数据我们可以发现一个主播的id号有多条数据记录,那么我们要做的就是要把这些相同的id将他对应数据进行累计求和处理操作,同时对id进行一个升序操作,看起来更加整洁
这次涉及到统计求和、排序等操作,用到了Reduce,整体项目流程如下:
二、创建Maven工程项目
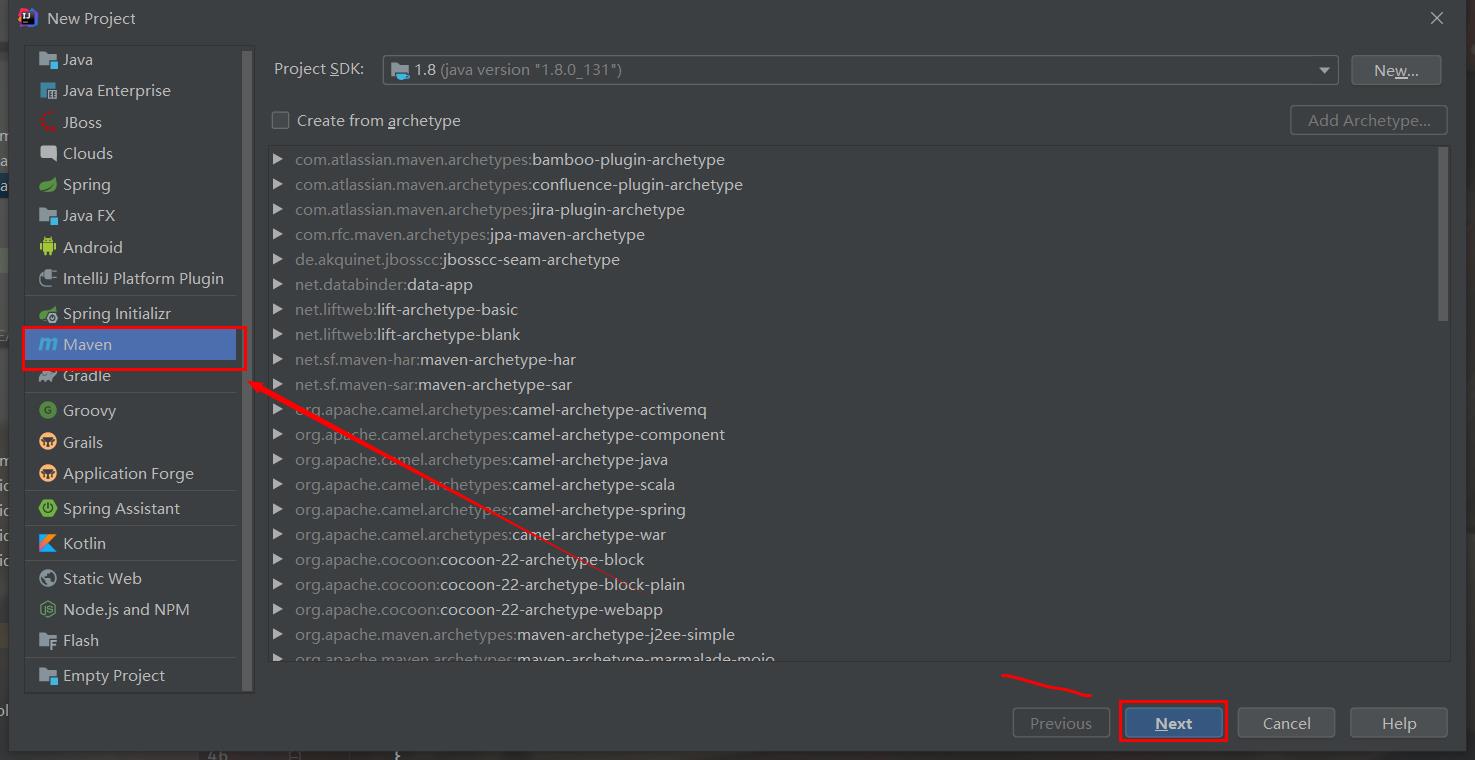
(1)新建maven
打开IDEA,新建一个项目,,在左侧一栏选择maven工程,点击下一步
添加项目名称,点击完成
创建之后,右下角会弹出提示,选择Auto自动导入依赖(没有也没关系,待会添加依赖也会弹出)
(2)添加依赖
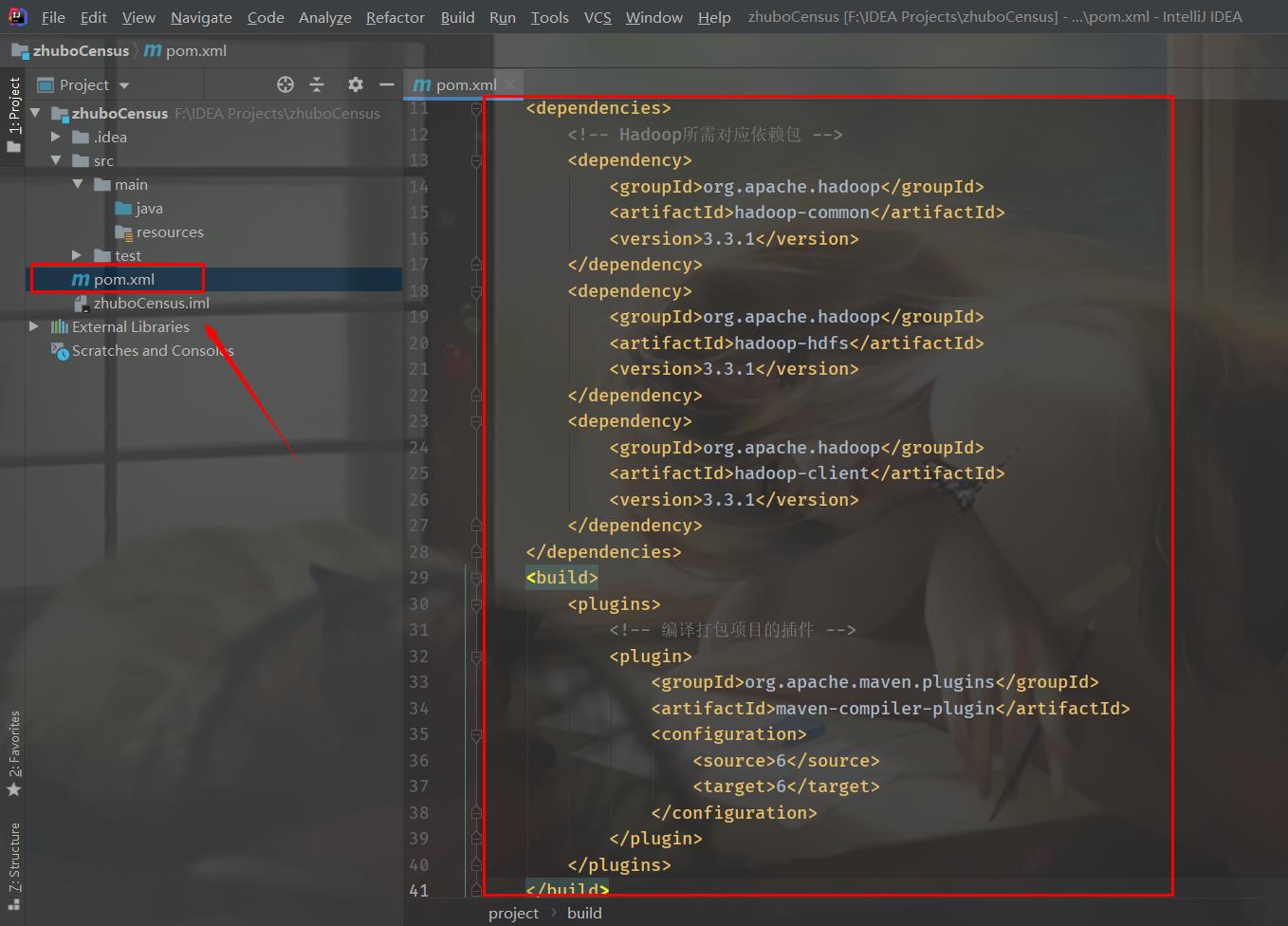
展开项目目录,编辑pom.xml配置文件,添加如下依赖
<dependencies> <!-- Hadoop所需对应依赖包 --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>3.3.1</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.1</version> </dependency> </dependencies> <build> <plugins> <!-- 编译打包项目的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>6</source> <target>6</target> </configuration> </plugin> </plugins> </build>
项目创建完毕
三、编写MapReduce程序
如果对Map和Reduce对应阶段的任务和处理结果不熟悉的可以看我之前那一篇 单词统计排序教程,有详细介绍
(1)自定义数据类
该类的作用:方便统计主播的指标数据,需要把这些字段整合到一个对象中,以便日后维护
新建一个VideoInfoWritable类继承Writable类,设置四个属性,自己补上get()和set()方法
public class VideoInfoWritable extends Writable private long gold; //金币 private long watchnumpv; //观看时长 private long follower; //粉丝数量 private long length; //总播放时长复写Writable类的两个方法,一个readFileds输入数据,一个write输出数据
@Override public void readFields(DataInput dataInput) throws IOException this.gold = dataInput.readLong(); this.watchnumpv = dataInput.readLong(); this.follower = dataInput.readLong(); this.length = dataInput.readLong(); @Override public void write(DataOutput dataOutput) throws IOException dataOutput.writeLong(gold); dataOutput.writeLong(watchnumpv); dataOutput.writeLong(follower); dataOutput.writeLong(length);(2)Mapper类
该类的作用:对数据进行按行读取,切割获取对应字段数据,封装字段数据到(1)自定义的类对象中
新建一个videoInfoMap类继承Mapper类,复写mapper方法
public class VideoInfoMap extends Mapper<LongWritable, Text, Text, VideoInfoWritable> @Override public void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException String line = v1.toString(); //读取清先之后的每一行数据 String[] fields = line.split("\\t"); //通过"\\t"对数据进行切割 String id = fields[0]; //获取主播的id /** * 获取主播的其他数据 * gold-------->>金币 * watchnumpv-->>播放量 * follower---->>粉丝 * length------>>开播时长 */ long gold = Long.parseLong(fields[1]); long watchnumpv = Long.parseLong(fields[2]); long follower = Long.parseLong(fields[3]); long length = Long.parseLong(fields[4]); Text k2 = new Text(); k2.set(id); // 封装到自定义的VideoInfoWritable类对象中 VideoInfoWritable v2 = new VideoInfoWritable(); v2.set(gold, watchnumpv, follower, length); context.write(k2, v2);(3)Reduce类
该类的作用:遍历具有相同主播id的VideoInfoWritable类对象,获取对应的四个字段值,进行求和
新建一个videoInfoReduce类,继承Reduce类,复写reduce方法
public class VideoInfoReduce extends Reducer<Text,VideoInfoWritable, Text,VideoInfoWritable> @Override protected void reduce(Text k2,Iterable<VideoInfoWritable> v2s,Context context) throws IOException,InterruptedException // 从v2s中把相同的k2的value取出来,进行遍历,进行累加求和。 long goldsum=0; long watchnumpvsum=0; long followersum=0; long lengthsum=0; /** * v2s:相同主播id的对应对象集合(VideoInfoWritable类对象,有四个属性) * 遍历具有相同id的对象,获取对应四个字段值,进行求和 */ for(VideoInfoWritable v2:v2s) goldsum+=v2.getGold(); watchnumpvsum+=v2.getWatchnumpv(); followersum+=v2.getFollower(); lengthsum+=v2.getLength(); // 将求和统计好的封装进来,写入context中,交由Job主类打印输出 Text k3=k2; VideoInfoWritable v3=new VideoInfoWritable(); v3.set(goldsum,watchnumpvsum,followersum,lengthsum); context.write(k3,v3);(4)主类(入口类)
这个没什么好说的了,运行jar包程序的入口类,对应代码注释我也标上了
public class VideoInfoJob public static void main(String[] args) try // 运行jar包程序指令输入错误,直接退出程序 if (args.length != 2) System.exit(100); Configuration conf = new Configuration();//job需要的配置参数 Job job = Job.getInstance(conf);//创建一个job作业 job.setJarByClass(VideoInfoJob.class);//设置入口类 FileInputFormat.setInputPaths(job, new Path(args[0]));//指定输入路径(可以是文件,也可以是目录) FileOutputFormat.setOutputPath(job, new Path(args[1]));//指定输出路径(只能是指定一个不存在的目录) // 指定Mapper阶段的相关类 job.setMapperClass(VideoInfoMap.class); // 指定K2的输出数据类型 job.setMapOutputKeyClass(Text.class); // 指定v2的输出数据类型 job.setMapOutputValueClass(VideoInfoWritable.class); // 指定Reduce阶段的相关类 job.setReducerClass(VideoInfoReduce.class); // 指定K3的输出数据类型 job.setOutputKeyClass(Text.class); // 指定V3的输出数据类型 job.setOutputValueClass(VideoInfoWritable.class); //提交作业job job.waitForCompletion(true); catch (Exception e) e.printStackTrace();四、编译打包jar上传
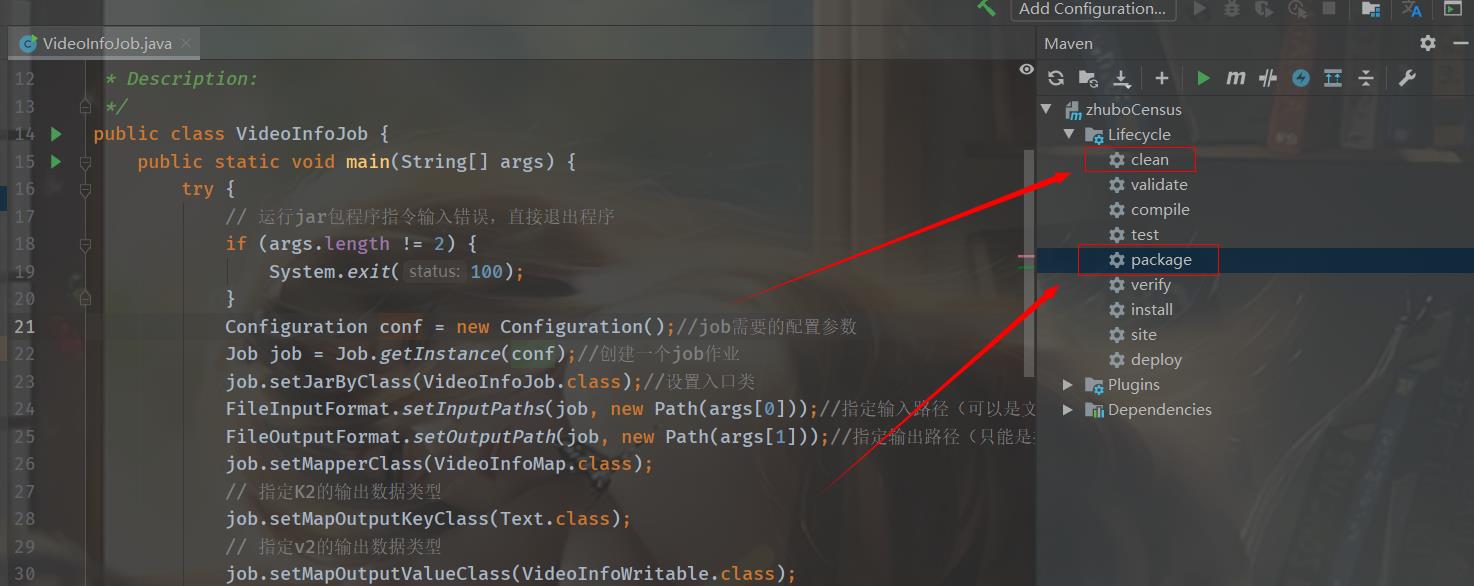
点击右侧的maven,展开Lifecycle,双击clean清理一下,再双击package生成jar包
运行结束,在项目目录会生成一个target文件夹,展开可以看到有一个jar包,右键复制jar包并且通过winscp连接虚拟机拷贝到虚拟机里 (不会的看第一篇)
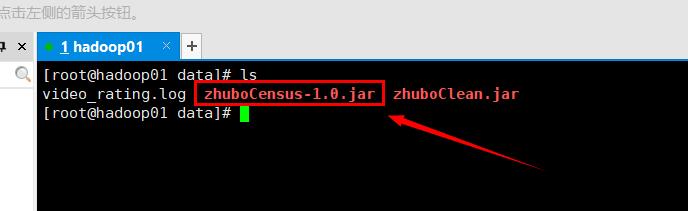
我已经成功拷贝到虚拟机了
五、拷贝数据集
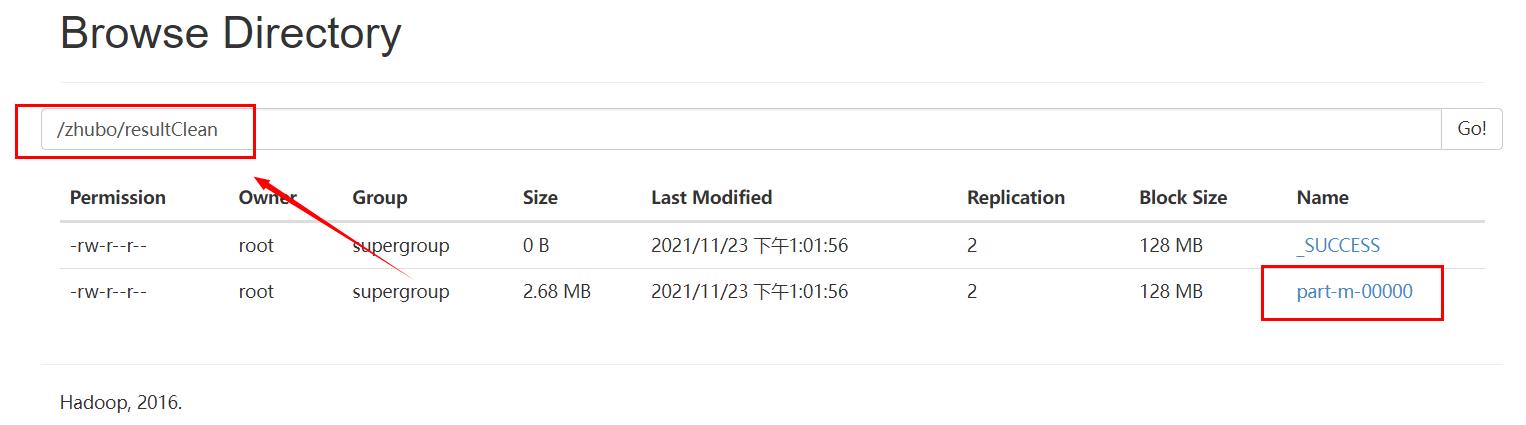
在第一篇文章里,我们已经初步处理好了数据,并且把结果数据集输出到了HDFS文件系统,现在我们将这个结果集拷贝到data目录,并且重新命名
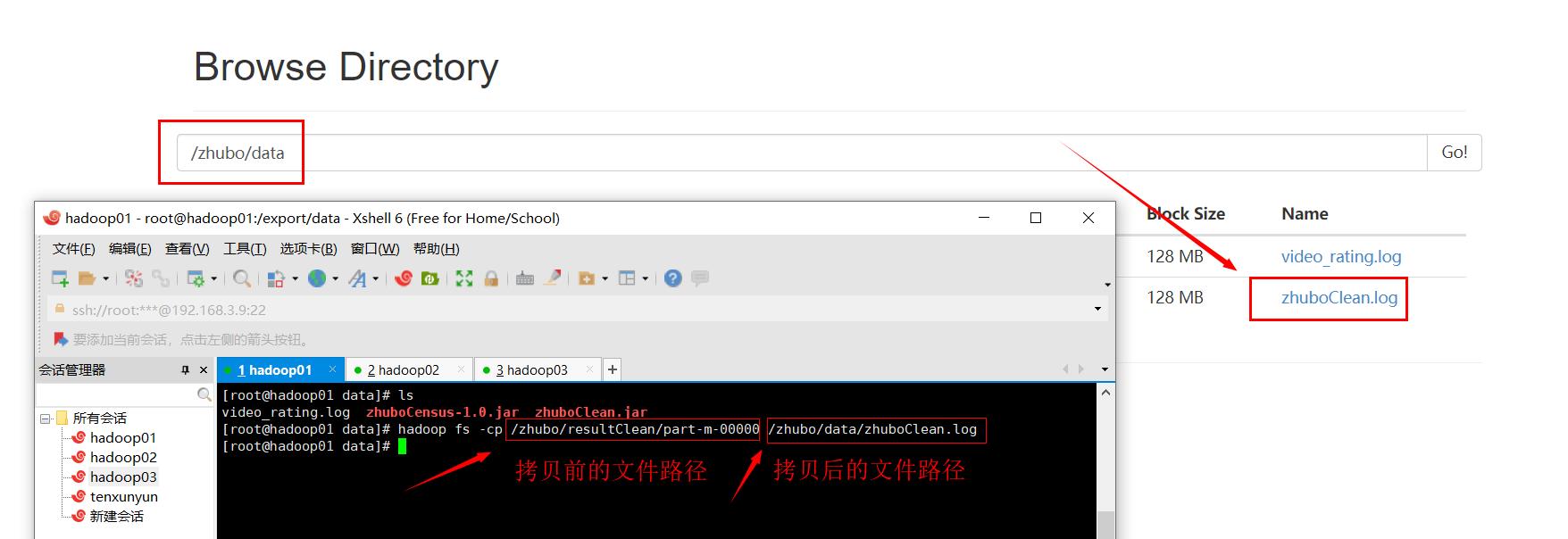
输入指令,将part-m-00000文件拷贝到/zhubo/data/文件夹下,并命名为zhuboClean.log
hadoop fs -cp /zhubo/resultClean/part-m-00000 /zhubo/data/zhuboClean.log
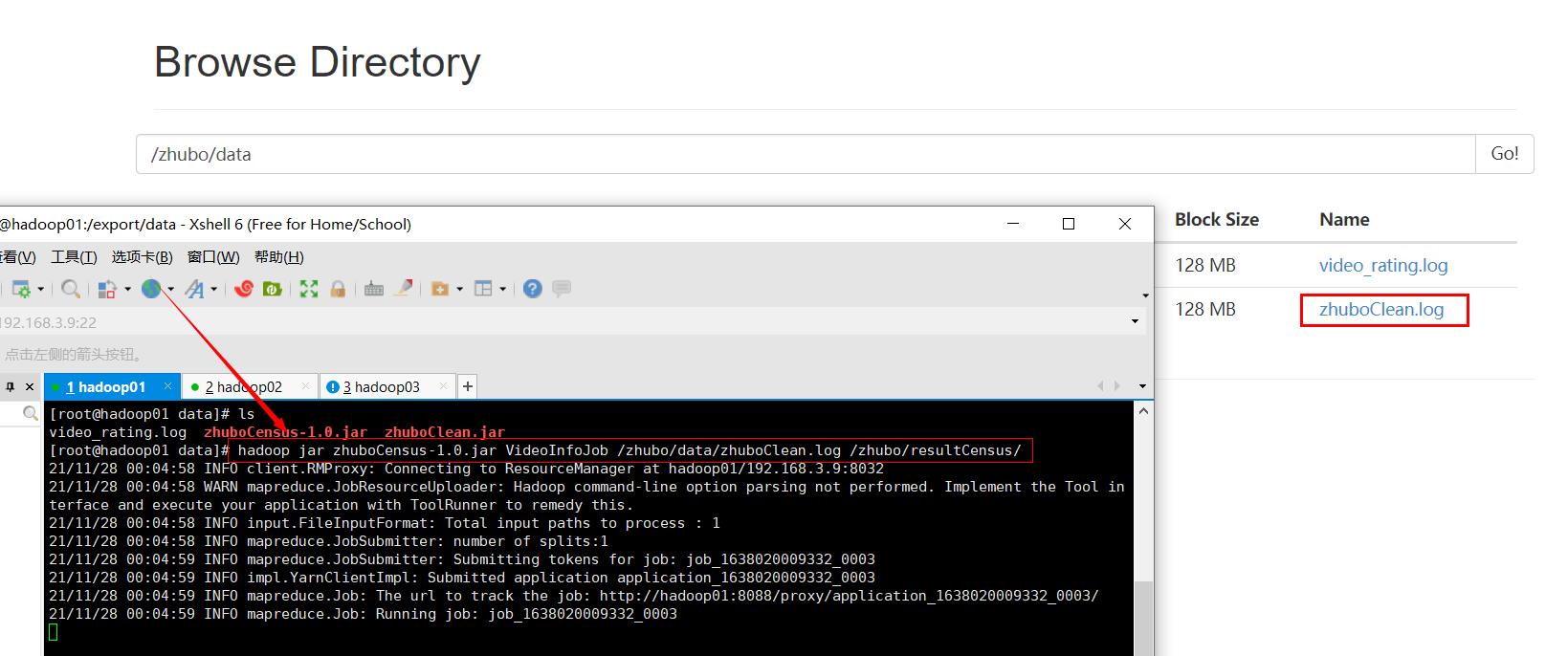
六、执行Jar包程序
最后我们执行jar包运行一下
zhuboCensus-1.0.jar 要执行的jar包名称 VideoInfoJob 主类(入口类)类名 /zhubo/data/zhuboClean.log 输入路径(数据所在位置) /zhubo/resultCensus/ 输出路径(结果输出路径,要为不存在的文件夹) hadoop jar zhuboCensus-1.0.jar VideoInfoJob /zhubo/data/zhuboClean.log /zhubo/resultCensus/
刷新浏览器,将输出的结果数据集下载下来
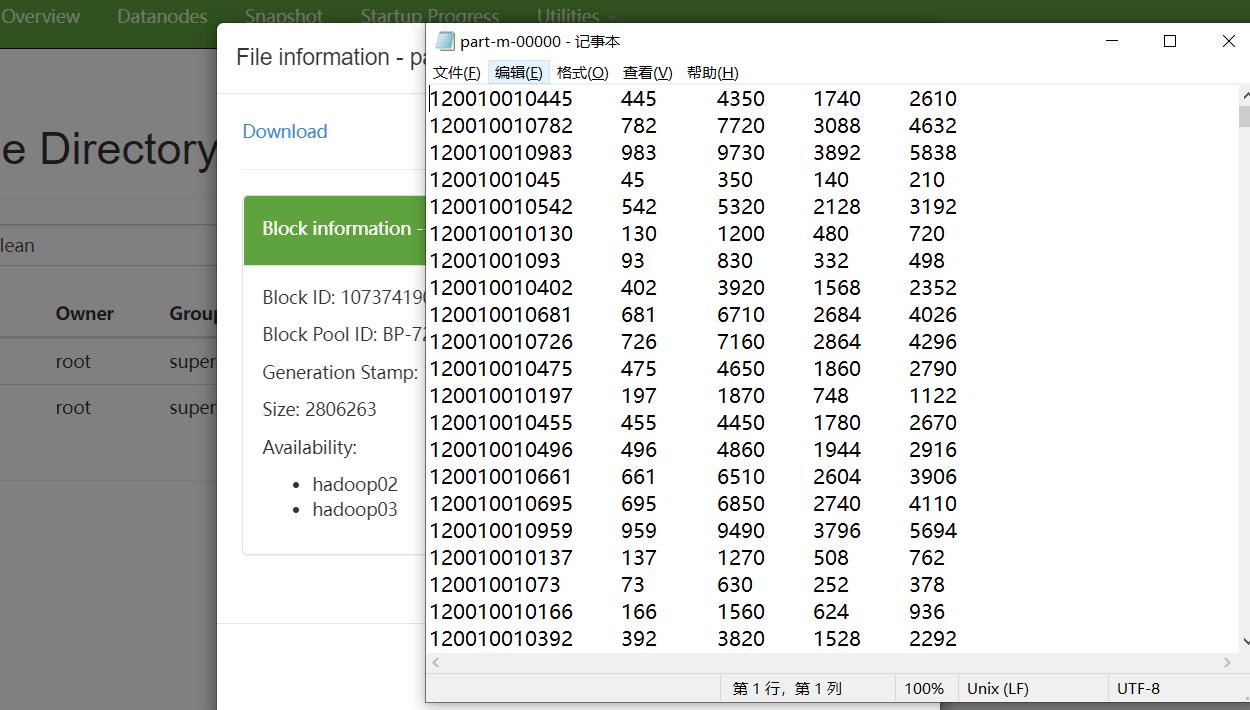
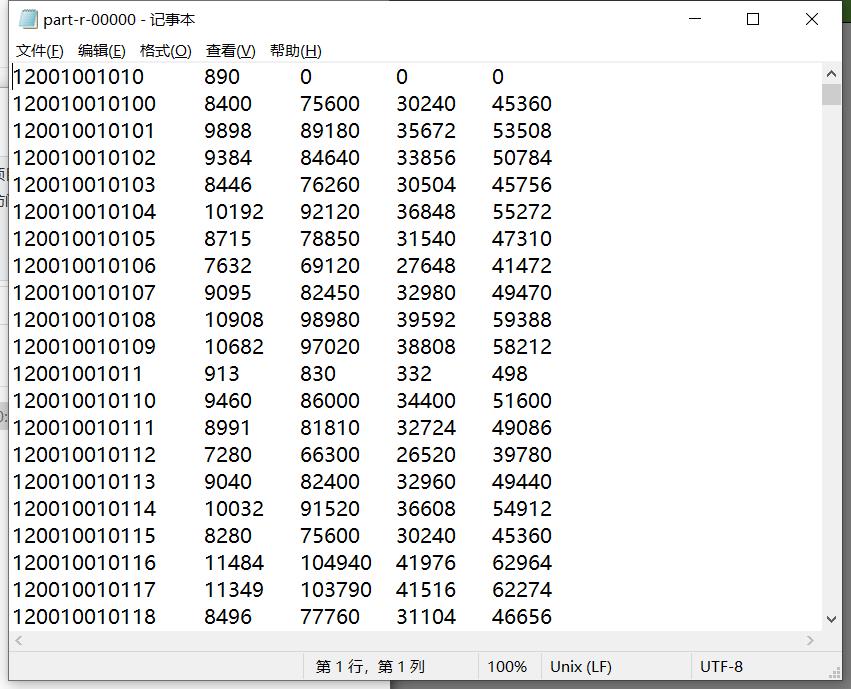
以记事本方式打开,可以看到已经统计完毕了,并且自动按照id依次显示





Gitee仓库Hadoop项目下载地址
Gitee仓库地址(Hadoop实战项目源码集合)
Hadoop实战项目源码集合: https://blog.csdn.net/weixin_47971206CSDN文章教学中的源码汇总集合
其他系列技术教学、实战开发
以上是关于Hadoop实战——MapReduce实现主播的播放量等数据的统计及TopN排序(第二篇)的主要内容,如果未能解决你的问题,请参考以下文章