移动计算云分布式数据缓存服务,实现快速可靠的跨区域多活复制
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了移动计算云分布式数据缓存服务,实现快速可靠的跨区域多活复制相关的知识,希望对你有一定的参考价值。
摘要:本文介绍了一种在移动计算云中扩展分布式数据缓存服务以实现跨区域多活复制的方案。
本文分享自华为云社区《移动计算云分布式数据缓存服务,实现快速可靠的跨区域多活复制》,作者: 敏捷的小智。
本文翻译自华为加拿大研所论文,英文原文链接:https://www.sciencedirect.com/science/article/pii/S1877050921014101
第18届国际移动系统和普适计算大会(MobiSPC)
2021年8月9日至12日,比利时鲁汶
移动计算云分布式数据缓存服务,实现快速可靠的跨区域多活复制
Daniel House, Heng Kuang*, Kajaruban Surendran, Paul Chen
加拿大安大略省万锦市 华为加拿大研究院
摘要
本文介绍了一种在移动计算云中扩展分布式数据缓存服务以实现跨区域多活复制的方案。阐述如何保证网络脑裂恢复后区域间数据的一致性,提出了一种跨区域副本数据同步的方法,能够克服在严重网络脑裂下,缓存数据操作的复制无法保证因果关系顺序的情况。本文使用的是最流行的移动计算云分布式数据缓存服务——Redis内存数据库,所述方案以插件的形式进行应用(最大程度减少对缓存服务端和客户端的影响)。Redis开放了强大的扩展API,允许新的抽象数据类型与key关联,但Redis并未对增加和管理全局字典元数据提供直接支持,这在本方案得以实现。本方案使用该扩展API来增加CRDT(无冲突复制数据类型),解决来自多个区域的写入冲突。
© 2021 The Authors. Published by Elsevier B.V.
This is an open access article under the CC BY-NC-ND license (http://creativecommons.org/licenses/by-nc-nd/4.0/)
Peer-review under responsibility of the Conference Program Chairs.
关键词:云数据缓存;跨区域多活;无冲突复制数据类型CRDT;可用性
1. 引言
移动计算云应用要求即便在高峰时段也要保证最短响应时间。因此,使用分布式数据缓存服务来增强性能就显得尤为重要。实际上,数据缓存已几乎成为一项必备移动计算云服务,其中,AWS ElastiCache 缓存服务、Azure Redis 缓存服务、阿里云云数据库 Redis 版、华为分布式缓存服务(DCS),都使用Redis作为缓存引擎。
* Heng Kuang. Tel.:
E-mail address:
移动计算云中,分布式数据缓存服务依赖跨区域多活来保证全球各地的最终用户都能够使用到可靠、高性能的移动云应用。随着移动计算云中的应用数量不断增加,如今的应用需要快速响应来自各大洲的数据读写请求,响应时间可能需要比跨洋短信送达的时间还快。不管网络和组件出现什么问题,应用必须始终保持可用,始终追求快速解决一致性问题,几乎要冲破CAP定理 [10] 的束缚。这种需求场景可能出现在世界不同地区的用户需要编辑共享数据(如多人文档协同)时,需要同时点击网页、订机票时,或者某个用户需要在不同设备间保持数据统一时。还有一些场景,用户虽然感知不到数据共享或复制本身,但却能感知时延和可靠性,比如购物车应用。
单向缓存复制中,所有写请求都发送到缓存的中心实例,这个中心实例是所有副本的主节点。当主节点发生故障时,其余副本中的一个被选举为新的主节点。一旦网络脑裂发生,与主节点位于同一分区中的客户端和副本不受影响,能够继续运行,但其他分区中的客户端和副本只有两种选择:被阻塞,或是在其所在分区中选举新的主节点。如果是购物类应用,阻塞会直接影响销量,因此绝不允许阻塞发生。如果每个分区都选举出自己的主节点,则该分区中所有的主节点需要同步数据,形成单主节点的格局。但在多活复制中,没有主节点,数据统一持续进行,脑裂后恢复也并不需要额外处理。当世界各地的用户对应用数据同时进行操作(比如订机票时),如果只有单主节点处理写入请求,对于距离该节点很远的用户来说时延太大,体验很差。此时,就可以使用多活复制,实现全体用户的时延差不多。
要想设计出好的多活复制系统,就需要转变思维,因为冲突解决的结果可能并不直观。设计人员可以选择发现冲突、上报冲突然后人工解决,也可以选择自动解决冲突。即便在单向复制中依照last-writer-wins,给key赋一个简单的值,对设计人员来说也可能有新颖独特的选项,例如可以采取一键多值[5],如果多个请求需要同时对一个值进行更改或删除,可以选择哪个请求中的操作获胜。采用 [7] 中所实现的多活队列,就能对同一条数据进行多次出队。开发人员必须知晓这些选项,充分理解这种新思维,才能写出有效的代码。新思维利用得当,单向复制中处理并发的思路就能够简化。必须要保持机动灵活的思维。
与单向复制相比,多活复制需要存储和传输用于检测和解决数据冲突的元数据,所以缓存大小和复制期间的数据发送量都会增加。保证最终一致性的算法比单向复制中简单的last-writer-wins规则复杂得多,实现过程更容易出错,复制也更慢。跨区域多活要求在不同区域间快速可靠地双向同步数据,原因如下:
• 即便跨地域的网络速度慢或不稳定,复制速度也必须能赶上不同区域的并发写入速度。
• 必须保证所有区域数据的最终一致性。
• 数据写入冲突的识别和解决都必须快速完成且保证一致性。现有的冲突解决机制中,Consensus / Quorum机制的吞吐量低,Multi-Version Concurrency Control机制的系统开销大,last-writer-wins机制会造成应用间的不一致性。
• 使用元数据来解决数据变更所导致的冲突,不应影响数据在缓存实例之间的可迁移性。
• 不管是对缓存客户端还是服务端,解决以上问题的同时,性能、应用以及缓存服务的实现不能受到显著影响。
为了在实现跨区域多活的同时满足以上这些严苛的要求,越来越多的人开始关注到无冲突复制数据类型(下称CRDT)。CRDT又分为基于操作的Commutative Replicated Data Types(CmRDT),和基于状态的Convergent Replicated Data Type(CvRDT)。Redis是一种基于key与数据结构映射的开源内存数据库,可以提供跨任意距离的单向复制,是业内最受欢迎的应用于移动计算云的分布式数据缓存服务之一。本文以Redis为例,提供了一种可用于在移动计算云中构建跨区域分布式应用的关键架构。它结合CRDT和Module API(Redis用于扩展的插件机制),在尽可能减少对Redis实现及其客户端进行变更的基础上,利用Redis实现双向复制。
下文将介绍我们是如何在移动计算云中通过扩展Redis缓存服务来支持跨区域多活复制。内容将聚焦如何使用Redis及其扩展机制Redis Module,利用CRDT保证网络脑裂恢复后跨区域数据的一致性。后文结构如下:第2章节介绍CRDT在学界的理论研究和在业界的应用;第3章节概要介绍了我们提供的复制与冲突解决方案;第4章节探讨如何使用CRDT实现最终一致性;第5章节比较了本方案与业界其他方案;第6章节对本文中的方法和经验进行总结,并指出今后的工作方向。
2. 背景及相关工作
据我们所知,目前尚无移动计算云厂商提供基于CRDT跨区域多活复制的数据缓存服务。Redis公司的Redis Enterprise产品是唯一可以通过基于操作的Commutative Replicated Data Types(CmRDT)来支持该功能的内存数据库软件 [12],但也没有官方文档描述Redis Enterprise是如何、由哪个组件(proxy、syncer还是Redis Module)来处理CRDT中的数据删除部分。Roshi [13] 提供时间序列事件存储,通过LWW元素集CRDT实现,使用有限的inline garbage collection。Roshi是基于Redis的分布式无状态层,在互不通信的集群上复制数据。Roshi项目已超过5年未更新。
AntidoteDB [15] 是一个跨区域复制的key-value数据库,操作执行使用CRDT,免于同步。其跨区域复制基于ZeroMQ,支持的数据类型包括Register、Flag、Map、Set、Counter。Riak KV [16] 是一个分布式key-value数据库,它使用基于状态的Convergent Replicated Data Type(CvRDT),支持的数据类型包括Register、Flag、Map、Set、Counter、HyperLogLog。Riak KV不跟踪物理时钟,而是跟踪逻辑时钟(dotted version vectors),以识别和解决区域之间的冲突。Azure Cosmos DB是一种NoSQL数据库,其数据库引擎的核心类型系统天生支持CRDT [17],但也没有公开文档描述它支持哪些数据类型,以及是如何支持这些数据类型的。相反,Cosmos DB的文档解释了什么是last-writer-wins冲突解决策略和自定义冲突解决策略,以及如何配置这两种策略。Cosmos DB使用反熵通道将试探性写入从一个资源分区复制到同一个分区组中的其他资源分区。
多活复制和CRDT算法有着丰富悠久的历史,可以追溯到1975年 [8],比逻辑时钟还要早 [1]。目前,已经出现了许多种类的CRDT。它们的主要共同点在于,数据的远程副本可以同时更新,冲突解决可以使用本地数据,所有副本数据最终都会保持一致。要实现有效的缓存复制,就必须有丰富的CRDT支持。本文讨论的数据类型仅限于单值register和map。其他有用的CRDT还有多值register、counter、list和set。
register是一个对象,我们可以为其分配不透明数据,并从中读取数据。[9] 提到了多值register,本文仅讨论单值register。首个CRDT算法 [8] 使用物理时间戳来实现值是单值register的map。[8] 提供的算法能够满足标准增删改查操作,同时确保了强最终一致性。
单值register是基于状态的CRDT,这种CRDT非常可靠,只要消息最终能够送达,即便消息无序或多次投递也没关系。register通常通过version vector来实现。当两个version vector无法比较,就使用物理时间戳;当物理时间戳相同时,就使用更新register的节点ID。
不同CRDT需要不同的全局数据。 -state CRDT需要因果关系的上下文,Replicated Hash Tables (RHTs)[2] 要求每个key都有一个向量时钟来解决冲突和识别垃圾数据,Replicated Growable Array(RGA)[2] 则需要消息队列和last-vector-clock-processed,以确保消息投递符合因果关系顺序并识别垃圾数据。 -CRDT map非常可靠。与Roh [2]和Wuu [3] 提到的map不同, -CRDT map不依赖于向量时钟或基于因果关系的投递,也不受消息重排和多次投递的影响。在本文中,我们使用一种 -CRDT算法来处理单值register。
3. 系统架构
我们针对移动计算云中分布式数据缓存服务的跨区域多活复制方案由四个逻辑组件组成:数据缓存服务Redis的CRDT模块、Replicator、Replayer、以及Replicator和Replayer的操作日志,如图1和2所示。Replicator和Replayer的实现机制相同,但作为两种模式运行。
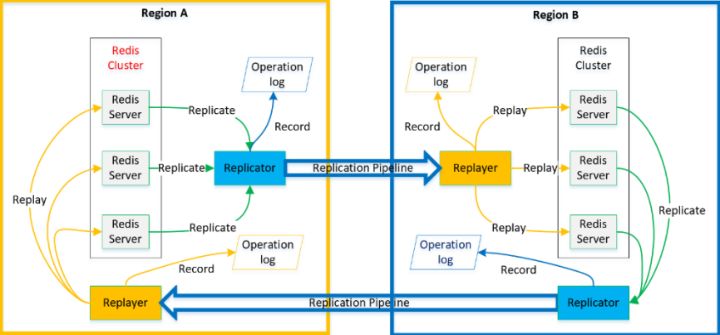
图1 系统构成
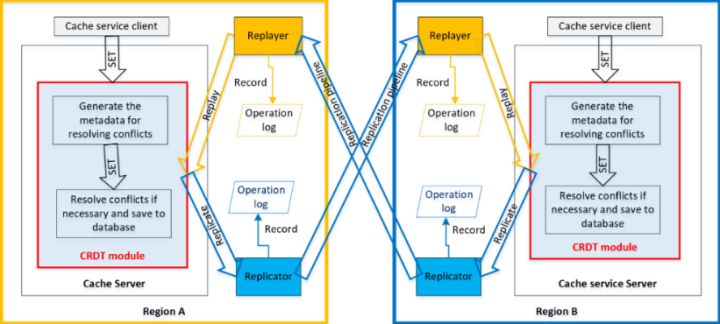
图2 CRDT模块
CRDT模块负责:
• 从缓存服务客户端或Replayer(从其他区域复制)接收缓存操作。
• 对于读操作,从缓存服务数据库获取值,并将其返回给缓存服务客户端。
• 对于写操作,生成解决潜在值冲突所需的元数据。
• 存储写操作生成的元数据。
• 通过元数据确定写操作是否与缓存服务数据库中的对应数据冲突。
• 如果不存在冲突,并且其version vector是最新的,则将值写入缓存服务数据库,然后将其复制到Replicator。
• 如果存在冲突,则根据CRDT冲突解决规则将值写入数据库。
Replicator负责:
• 作为其所在区域中缓存服务端的副本,通过沿用数据缓存服务中的主从复制机制,接收CRDT模块复制过来的成功的写操作。
• 为这些操作生成ID,作为额外的元数据,并将这些操作推送到其复制管道。
• 将操作记录在自己的操作日志中。
• 当达到触发条件(例如,每隔1秒或当复制队列的大小达到1KB),将复制队列中的操作发送给其他区域的Replayer。
• 如果区域之间存在网络脑裂,则通过比较Replayer记录的操作ID,识别操作日志中发送失败的操作,重试发送这些操作。
Replayer负责:
• 作为其他区域Replicator的副本,通过沿用数据缓存服务中的主从复制机制,接收Replicator复制过来的写操作。
• 将操作记录在自己的操作日志中。
• 作为缓存服务客户端,将操作回放到对应的缓存服务端。
• 如果Replayer与其缓存服务端之间存在网络脑裂,则利用操作ID和操作日志查找并重试尚未到达缓存服务端的操作。
Replicator的操作日志负责记录同区域CRDT模块复制过来的成功的写操作,然后在区域间网络脑裂恢复后,恢复这些操作。Replayer的操作日志负责记录其他区域Replicator复制过来的写操作,然后在它与缓存服务端间的网络脑裂恢复后,恢复这些操作。
4. 实现最终一致性
CRDT模块作为一种可动态加/卸载的共享库加载到缓存服务端,并可以直接开始拦截来自缓存服务客户端的请求,以对内部数据库执行本地操作。CRDT模块更新数据库,然后向其他区域发送请求,对那些区域的数据库进行远程操作。图2中的Replicator和Replayer相互协调,确保在没有重大故障的情况下,所有远程操作都能准确按顺序投递一次,但无法保证基于因果关系的投递。当发生重大故障时,内部数据库的全量数据将在区域之间交换。
4.1. 系统模型
通过Replicator和Replayer的协作,我们可以得到一种抽象系统模型,其中有n个节点(节点间不共享任何内存),。每个节点都有一个key-value存储和一个控制存储。每对节点(和),都有一个单向通信管道,延迟很大([10] 中的报告显示,洲际延迟可能高达0.25秒。)通信管道可能处于活跃状态或中断状态。处于活跃状态时,消息能够按顺序可靠地传递,不会重复。当管道中断,其间发送的消息永远不会送达。每当管道从中断转变到活跃时,节点就会使用该管道,将其数据库的全量副本传递到,之后管道将恢复发送远程操作。本地客户端生成查询(使用本地数据库进行应答,没有副作用,不会触发节点之间的任何通信,因此本文不会进一步讨论),并请求将本地操作加入本地数据库内容中。
每个节点都有一个物理时钟,用于生成物理时间戳。时钟之间不进行同步。我们假设,在时刻,观察到了包含个事件的有限序列Ei = ei0, … einit,且当j < k,则eij发生在eik之前。对于,我们假设对于从Ni发送到Nk的每一个消息M,在Ei中都有一个发送事件,在中都有一个接收事件,那么发生在之前,写入顺序为。假设副本1(R1)的日志L1包含操作o1,副本2(R2)的日志L2包含操作o2。当o1 ∉ L2且o2 ∉ L1时可以确定o1和o2是并发的,表示为o1 ∥ o2,如果在任一日志中o1出现在o2之前,则o1发生在o2之前,表示为o1 < o2。
我们首先重新定义与字符串的key相关联的数据,因为它是CRDT单值register。Redis协议允许客户端将key设置为任何二进制BLOB。基于对象的强最终一致性 [6] 可以在register删除或列表移除后回收空间。删除key时,我们需要SWOR Map(Set-Wins, Observed-Remove)语义。由于Redis协议仅允许存在单值字符串,因此我们使用单值register。RGA中key的SWOR Map语义可以理解为:当RGA上所有条目都已删除并且最后一个tombstone已被GC进程回收,该key将被隐式删除。如果在此之前删除该key,可能会导致并发的list-add-right操作出现问题。RGA中的本地key删除操作可以简单扩展为一组列表移除操作。一个map可以在不同的时间包含不同的key。我们的目标是让key表示CRDT值。随着map的演进,key可以被删除,可能很久之后key再重新创建出来。你可以为CRDT值设置一个基础值或重置值,这种方法简单、可用,但其弊端在于key必须持续存在才能表示基础值。
4.2. 简单的CRDT register
基于向量时钟的register依赖全局向量时钟。每当register创建时,都会获得新的向量时钟。如果register每次都以“基础”向量时钟重新开始,则可能导致错误的值获胜。基于dots的register依赖全局因果关系。如果并发集足够少(与节点数量相比),空间占用就能比基于向量时钟的方法更少。
每个副本都有自己的严格有序的事件历史。为保障最终一致性,整个事件历史都将随每一条消息一起发送。接收消息时,副本必须合并两份事件历史,才能获得一份新的严格有序的事件历史。要确保一致性,这种合并操作必须具备可结合及可交换性。获得全序后,register的值来自最后一次操作。我们用⊥来表示无值,这个值是当历史为空且全序中最后一个操作为时register的值。我们可以定义不同的合并操作来获得不同的语义,如last-writer-wins或set-wins。发送整个事件历史的代价很大,因此需要想办法减少发送的数据量。
5. 其他方案的比较
本节我们将评估和对比其他声称能够在内存数据库云服务或软件中实现跨区域多活复制的方案。
5.1. 阿里云ApsaraDB for Redis
阿里云的ApsaraDB for Redis不支持CRDT,而是要求用户的应用程序在使用跨区域多活复制功能时自行保障数据一致性 [11]。因此,用户的应用程序在实现时必须保证以下几点:
• 避免从不同区域同时写入相同key(这很难控制)。
• 对Redis数据库进行分区,使不同区域的用户的应用程序只能写入分配给该区域的可写分区,同时从其他区域复制只读分区(这将影响用户的应用程序使用此功能的透明性,并使应用程序的实现更加复杂)。
如果无法做到以上几点,相关区域中的数据就将变得不一致。例如,当一个key的value变更在两个区域间同步后,可能导致两个区域间的key value互换 [11];如果两个区域中,一个key变更为不同的数据类型,也可能导致同步失败 [11]。
5.2. KeyDB
KeyDB是Redis的分支,已经成为Redis的一个直接替代方案,支持多活副本和其他高级功能。当启用多活复制时,KeyDB允许两个主节点之间的循环连接,因此它还可以沿用Redis的主从复制机制。KeyDB使用last-writer-wins来解决主节点之间的冲突 [18]。每个写操作都有时间戳,最新的写操作获胜。
但是,仅使用时间戳并不是一种可靠的冲突解决方案,因为可能会导致数据丢失,并且对许多数据类型(例如用于全球统计点赞数或关注数的计数器)还不够用。“最后写入”并不能得到保障,因为即使不同区域的服务端系统时钟可以在一定的间隔内与全局原子时钟同步,但时间还是会漂移,每个服务端还是根据自己的系统时钟来判断写操作的顺序。此外,将系统时钟回拨将导致意外的冲突解决。
5.3. Redis Enterprise
Redis Enterprise是开源Redis之上的增强版,提供了许多企业级功能,跨区域多活复制就是最重要的功能之一。Redis Enterprise中的CRDB(无冲突复制数据库)是跨区域的多个Redis集群的数据库。每个集群中的数据库都是一个CRDB实例,使用Syncer将Redis操作复制到其他CRDB实例。Syncer没有沿用Redis的复制机制,而是使用一种新的复制机制(从远程主节点请求复制)。一个Redis Enterprise集群包含Redis Shard(分片)、Proxy(代理)、Cluster Manager(集群管理器)和REST API。
Redis Enterprise使用基于操作的CRDT,需要通过Syncer和Proxy复制额外的“effect”数据到所有CRDB实例。这些“effect”数据由使用Redis模块数据类型API [12] 构建的CRDT模块生成。但是,Redis Enterprise没有明确说明“effect”数据中究竟包含什么信息,由谁(Syncer、Proxy还是Redis Module)以及如何将其应用于冲突解决。每个CRDB实例为每个数据库条目和子条目维护一个向量时钟,才能识别和解决区域之间的数据冲突 [12]。
5.4. 我们的方案
我们对单值register map实现了跨区域多活复制,使用向量时钟来识别并发的数据更改,并对非并发更改进行正确排序。
Redis Enterprise是唯一可以使用基于操作的CRDT来支持跨区域多活复制的内存数据库软件,与之相比,我们的方案具有以下优势:
• 结合基于状态的CRDT和Redis模块数据类型API,避免将“effect”数据与数据库条目分开存储和复制,从而使这些条目的迁移更安全、更方便。
• 无需等待外部组件(Syncer或Proxy),能够在CRDT模块中直接解决数据冲突,使冲突解决速度更快。
• 不需要代理(减少一次跳转),从而对缓存服务端和跨区域复制的性能影响降至最低。
• 沿用Redis数据缓存服务的主从复制机制,可最大限度地提高区域内和跨区域复制的性能。
为证明本方案(基于华为DCS)的优势,我们做了一个实验,并在性能和CPU利用率维度与Redis Enterprise进行了比较,见以下步骤和图3。
1. 在3台主机上启动3个华为DCS集群(每个集群中有3个Redis server,每个Redis server都加载CRDT模块),模拟3个区域中的3个多活Redis集群。
2. 在每台主机上启动一组Replicator和Replayer(将它们连接到该主机上的3个Redis server)。
3. 运行3个memtier-benchmark,分别向这3个集群发送具有相同key范围的写请求,模拟对多活集群的并发写操作。使用工具断开/重连不同主机上的Replicator与Replayer,模拟不同区域之间的网络脑裂。
4. 收集实验数据,再对Redis Enterprise进行相同的实验。以下是观察结果:
1) 本方案即使在网络脑裂情况下,也实现了3个多活集群之间的最终一致性。
2) 本方案比Redis Enterprise性能更好(写/读请求比为1:0时,性能是Redis Enterprise的200%),CPU利用率更低(写/读请求比为0:1时是Redis Enterprise的20%)。

图3 与Redis Enterprise的性能和CPU利用率对比
6. 结论和今后方向
通过扩展缓存服务的实现,我们学到了一些重要的经验教训。首先,在任何实际的CRDT应用中,如果CRDT实例能被删除,都必须同时设计顶层map和map中的CRDT对象。map和对象必须共享某些信息。比如,我们的单值register就需要访问map中的因果关系。我们还发现,实现CRDT算法需要仔细对比实际的消息传送环境与制定CRDT算法时做出的理论假设。由于两个区域之间的通信管道时而中断,我们的CRDT算法需要能够在区域之间执行全量同步,因此完全基于操作的CRDT算法就不合适。
本次概念验证将CRDT map与单值register相结合,用于移动计算云中的分布式数据缓存服务。我们希望进一步延展本次概念验证,将Younes [4] 的可重置计数器和Almeida [5] 的集合也包含进来。如果要将Roh [2] 的RGA与CRDT map相结合,需要符合因果顺序的消息投递。我们还希望通过基于因果关系的广播协议 [6] 探索如何能实现数据缓存服务中可行的RGA故障模式。
冲突解决要求每个key最终在每个节点中的类型相同。数据类型的单向优先顺序虽然可以工作,但它只能是无规则的,而且我们到目前为止调研的类型晋级模式只能做到覆盖与一个key关联的所有先前的数据。完整的类型晋级网格可能并不存在,但仍然有可能存在一种类型冲突解决方案,既直观,又能在冲突解决过程中保留尽可能多的数据。
参考文献
[1] Leslie Lamport. 1978. Time, clocks, and the ordering of events in a distributed system. Communications of the ACM. 21, 7 (July 1978), 558-565. DOI: https://doi.org/10.1145/359545.359563
[2] Hyun-Gul Roh, Myeongjae Jeon, Jin-Soo Kim, and Joonwon Lee. 2011. Replicated abstract data types: Building blocks for collaborative applications. Journal of Parallel and Distributed Computing. 71, 3 (March 2011), 354-368. DOI: https://doi.org/10.1016/j.jpdc.2010.12.006
[3] Gene T.J. Wuu and Arthur J. Bernstein. 1984. Efficient Solutions to the Replicated Log and Dictionary Problems. In Proceedings of the third annual ACM symposium on Principles of distributed computing (PODC’84). ACM Press, New York, NY, USA, 233-242. DOI: https://doi.org/10.1145/800222.806750
[4] Georges Younes, Paulo Sérgio Almeida, and Carlos Baquero. 2017. Compact Resettable Counters through Causal Stability. In Proceedings of the 3rd International Workshop on Principles and Practice of Consistency for Distributed Data (PaPoC’17). ACM Press, New York, NY, USA, 1-3. DOI: https://doi.org/10.1145/3064889.3064892
[5] Paulo Sergio Almeida, Ali Shoker, and Carlos Baquero. 2018. Delta State Replicated Data Types. Journal of Parallel and Distributed Computing. 111 (January 2018), 162-173. DOI: https://doi.org/10.1016/j.jpdc.2017.08.003
[6] Kenneth Birman, Andre Schiper, and Pat Stephenson. 1991. Lightweight causal and atomic group multicast. ACM Transactions on Computer Systems. 9, 3 (August 1991), 272-314. DOI: https://doi.org/10.1145/128738.128742
[7] Redis Labs. 2020. Developing with Lists in an Active-Active Database. Redis Labs. Retrieved November 1, 2020 from: https://docs.redislabs.com/latest/rs/references/developing-for-active-active/developing-lists-active-active/
[8] Paul R. Johnson and Robert H. Thomas. 1976. The maintenance of duplicate databases. Internet Request for Comments RFC 677. (January 1976) Information Sciences Institute
[9] Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. 2007. Dynamo: Amazon’s highly available key-value store. ACM SIGOPS Operating Systems Review. 41, 6 (October 2007), 205-220. DOI: https://doi.org/10.1145/1323293.1294281
[10] Seth Gilbert and Nancy Lynch. 2002. Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services. ACM SIGACT News. 33, 2 (June 2002), 51-59. DOI: https://doi.org/10.1145/564585.564601
[11] Alibaba 2020. Constraints on using the active-active geo-replication of ApsaraDB for Redis. Alibaba. Retrieved November 1, 2020 from: https://help.aliyun.com/document_detail/71883.html?spm=a2c4g.11186623.2.15.240c4c07jsXWWr#concept-cbs-dfk-zdb
[12] Redis Labs. 2020. Active-Active Geo-Distribution (CRDTs-Based). Redis Labs. Retrieved November 1, 2020 from: https://redislabs.com/redis-enterprise/technology/active-active-geo-distribution/
[13] SoundCloud 2020. Roshi. SoundCloud. Retrieved November 1, 2020 from: https://github.com/soundcloud/roshi
[14] Marc Shapiro, Nuno Preguica, Carlos Baquero, Marek Zawir ski. 2011. A comprehensive study of convergent and commutative replicated data types. Technical Report. (January 2011)
[15] AntidotDB 2020. AntidotDB. AntidotDB. Retrieved November 1, 2020 from: https://github.com/AntidoteDB/antidote
[16] Riak 2020. Riak KV. Riak. Retrieved November 1, 2020 from: https://riak.com/products/riak-kv/index.html
[17] Microsoft 2020. Azure Cosmos DB: Pushing the frontier of globally distributed databases. Microsoft. Retrieved November 1, 2020 from: https://azure.microsoft.com/en-us/blog/azure-cosmos-db-pushing-the-frontier-of-globally-distributed-databases/
[18] EQ Alpha 2020. Active Replica Setup. EQ Alpha. Retrieved November 1, 2020 from: https://docs.keydb.dev/docs/active-rep/
[19] Redis Labs. 2020. Redis Enterprise Cluster Architecture. Redis Labs. Retrieved November 1, 2020 from: https://redislabs.com/redis-enterprise/technology/redis-enterprise-cluster-architecture/
以上是关于移动计算云分布式数据缓存服务,实现快速可靠的跨区域多活复制的主要内容,如果未能解决你的问题,请参考以下文章