java(13)-java进程CPU飙高排查:jstack使用案例
Posted hguisu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java(13)-java进程CPU飙高排查:jstack使用案例相关的知识,希望对你有一定的参考价值。
历史笔记总结,温故而知新。
一、背景概述
Java开发中,有时候我们会碰到下面这些问题:
OutOfMemoryError,内存不足和泄露问题:彻底深入理解和分析Java中OutOfMemoryError内存溢出退-
线程死锁、锁争用(Lock Contention)、Java进程消耗CPU过高......
要解决这些问题,需要掌握一定基础理论知识和熟悉相关工具使用如:java(5)-深入理解虚拟机JVM_、 java(9)-深入浅出GC垃圾回收机制 、java(10)-JVM性能监控和优化。最好通过透过问题看本质则是由虚到实,由表及里往深层次地挖掘问题,然后总结和反思的解决问题的过程,能形成底层技术深度加固,最后提高解决问题的能力。
由于周五团队老项目遇到了cpu使用率很高,用户反馈卡顿的现象,趁此机会把之前的草稿笔记整理发上来,也算是一次总结,也是加深底层技术的认识。由于是老项目系统,没有完善监控体系,也没有完备的日志系统,所以只能一步一步排查问题。
二、问题排查思路
针对这个问题,一般的解决思路:
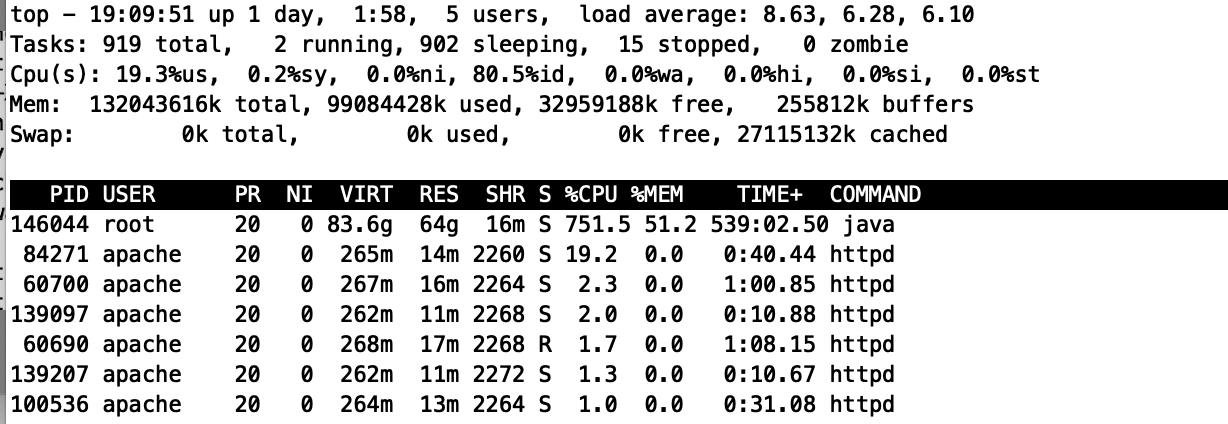
1、top查看java进程cpu使用率:
cpu使用率2500%左右(40核系统,但平时才300%左右),并确认当前系统load值是否很高,如果很高(超过cpu核数),说明当前系统出现大量线程排队现象,如果比较低但cpu。如果比较低,说明系统运行很顺畅,但是业务比较繁忙。
cpu使用率:CPU 使用的百分比。
负载load值:等待CPU的进程数。
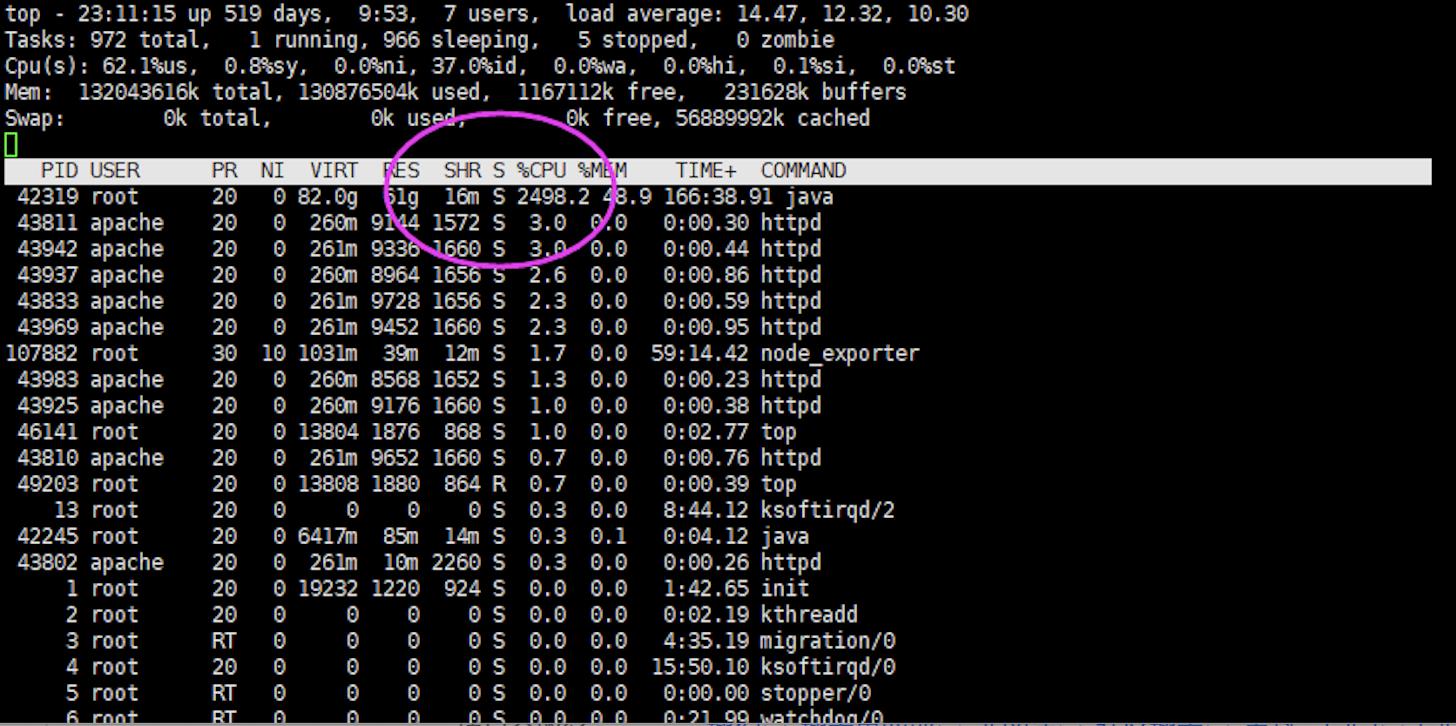
2、查看具线程的cpu使用率:top -H -pid
如果几个线程一直占用cpu接近100%,说明这个线程可能循环执行业务或者持续做fgc。
如果线程都是平均的使用cpu,说明线程在放忙执行业务引起的。
也可以通过arthas工具(mirrors / alibaba / arthas · CODE CHINA),快速的检查具体线程执行:
curl -O https://arthas.aliyun.com/arthas-boot.jar java -jar arthas-boot.jar pid
然后输入dashboard命令就可以看到具体线程执行情况:

3、检查jvm gc状况:jstat -gc pid
1、通过jstat命令监控GC情况,看到Full GC次数非常多,并且次数在不断增加。说明jvm在做fgc引起。但是fgc不足引起jvm进程占用cpu高达2500%。
我们增加堆内存:
修改堆内存 -Xmx16g -Xms16g -Xmn4G。问题没有解决,还是出现大量fgc。
修改堆内存 -Xmx32g -Xms32g -Xmn4G。问题没有解决,还是出现大量fgc。
修改堆内存 -Xmx32g -Xms32g -Xmn4G。问题没有解决,还是出现大量fgc。
修改堆内存 -Xmx60g -Xms60g -Xmn20G, fgc 降下来,但是实际问题还没有解决,cpu使用率还是很高。
可以通过查看jvm日志(jvm 参数设置打印gc信息-XX:+PrintGCDetails)就能看到gc日志信息:

4、定位业务和代码问题:
1)、第二步通过top -Hp <pid>来查看该进程中有哪些线程CPU过高(一般超过80%就是比较高的)。
2)、然后通过该线程id的十六进制表示在jstack日志中查看当前线程具体的堆栈信息。
printf "%xn" <threadid>
例如printf "%x\\n" 21742
得到21233的十六进制值为52f1,下面会用到。
3)、通过jstack pid > jstack.log 查看具体堆栈执行
grep 52f1 jstack.log -A 10
4)检查有没有lock和block:
grep BLOCK jstack.log -C 10

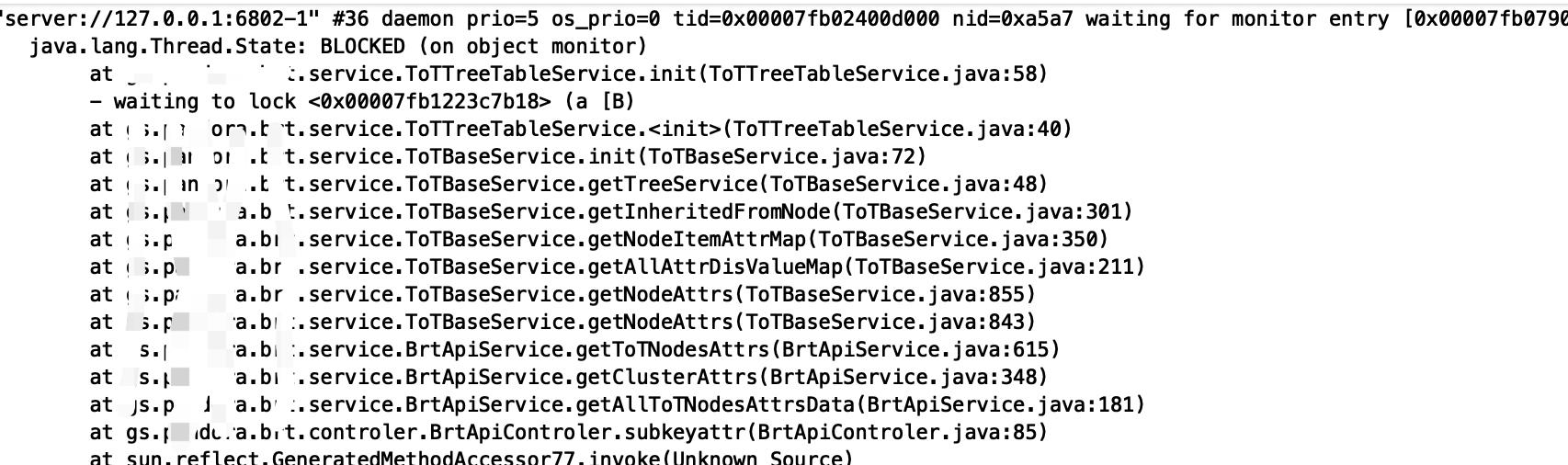 这个基本定位到哪个业务执行到哪块代码的问题。
这个基本定位到哪个业务执行到哪块代码的问题。
最后发现init方法存在synchronized锁,同时该业务功能模块最近被频繁调用,返回数据量比较大的json,造成jvm在短时间内创建大量临时对象,在并发量上来后,致使频繁触发gc,同时该业务模块执行for循环量比较大,所以cpu使用率很高。
5、最终问题解决
由于是老项目,不能临时盲目修改代码上线,这个风险是比较大。
通过修改堆内存 -Xmx60g -Xms60g -Xmn20G, fgc 降下来,但是但cpu使用率依然很高。
cpu使用率仍然在1600%,虽然业务暂时不受影响,但没有最终解决问题。
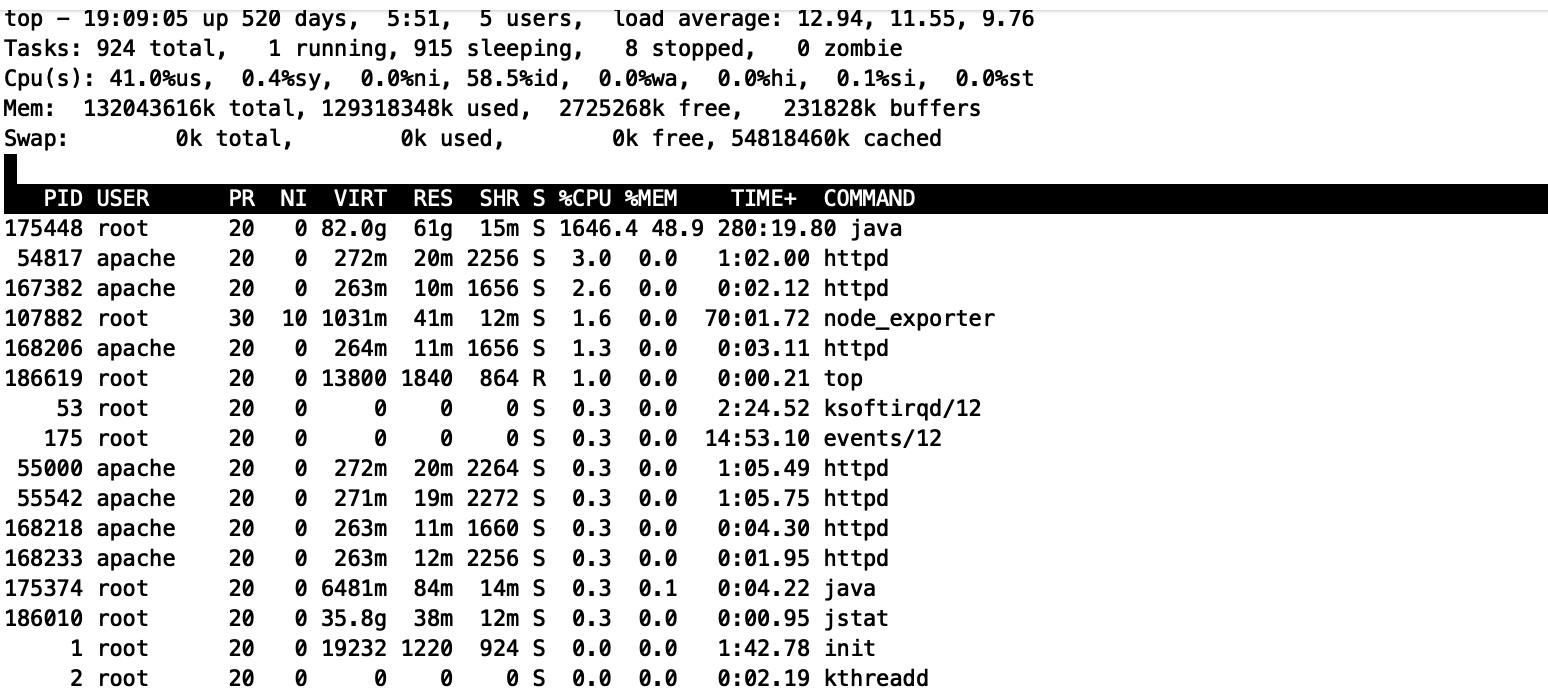
通过jstat -gc pid 检查ygc仍然很频繁,原因是我们指定了-Xmn20G,限制了年轻代的内存,导致ygc频发引起:
java年轻代默认使用ParNew收集器,ParNew GC 也会stop the world等卡顿现象:
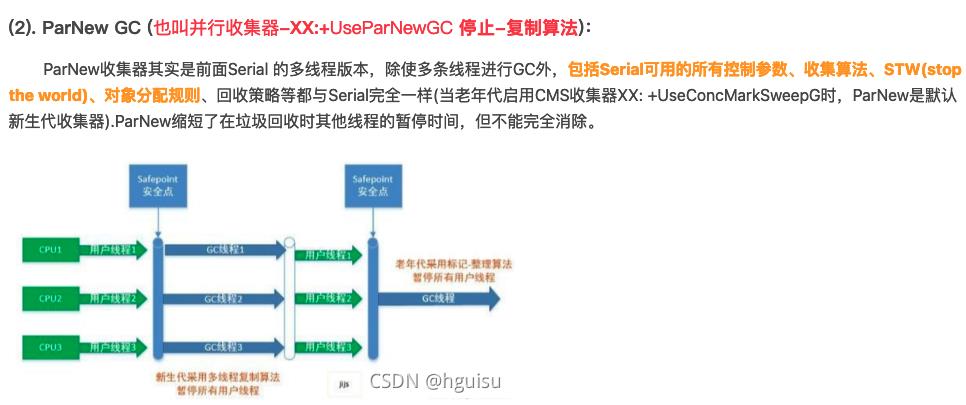
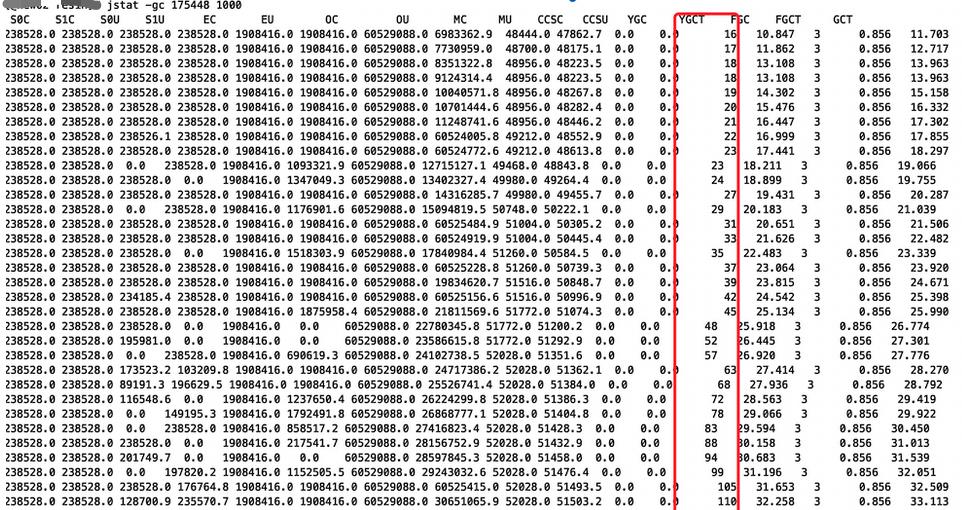
最终我们调整了垃圾收集器从CMS改为G1。
CMS虽然并发收集低停顿,但是有三个明显的缺点。
1、Mark Sweep算法会导致内存碎片比较多。
2、CMS的并发能力比较依赖于CPU资源,并发回收时垃圾收集线程可能会抢占用户线程的资源,导致用户程序性能下降。
3、并发清除阶段,用户线程依然在运行,会产生所谓的理“浮动垃圾”(Floating Garbage),本次垃圾收集无法处理浮动垃圾,必须到下一次垃圾收集才能处理。如果浮动垃圾太多,会触发新的垃圾回收,导致性能降低。如果因为内存碎片过多而导致压缩任务不得不执行,那么stop-the-world的时间要比其他任何GC类型都长,你需要考虑压缩任务的发生频率以及执行时间。
g1收集器不需要设置 -Xmn:

YGC就没有那么频繁,YGC从每秒几次到每隔几秒一次:
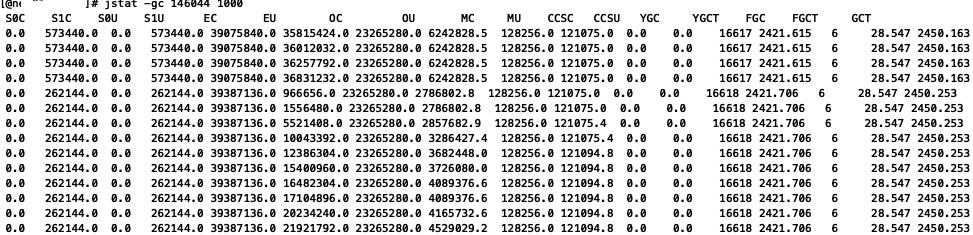
最终解决cpu使用过高的问题,cpu降到750%左右。
G1收集器的优点:
1、G1最大的好处是性能:由于它高度的并行化,因此它在应用停止时间(Stop-the-world)这个指标上比其它的GC算法都要好。他比我们在上面讨论过的任何一种GC都要快。但是在JDK 6中,他还只是一个早期试用版本。在JDK7之后才由官方正式发布。目前JDK9已经是默认收集器了。
2、G1能让用户设置应用的暂停时间: G1回收的第4步“筛选回收”,而不是整代内存来回收,这是G1跟其它GC非常不同的一点,其它GC每次回收都会回收整个Generation的内存(Eden, Old), 而回收内存所需的时间就取决于内存的大小,以及实际垃圾的多少,所以垃圾回收时间是不可控的;而G1每次并不会回收整代内存,到底回收多少内存就看用户配置的暂停时间,配置的时间短就少回收点,配置的时间长就多回收点,伸缩自如。
3、可以有效的规避内存碎片的问题:由于内存被分成了很多小块,又带来了另外好处,由于内存块比较小,进行内存压缩整理的代价都比较小,相比其它GC算法,可以有效的规避内存碎片的问题。
三、总结和反思
1、在问题中成长和深入学习。
遇到问题时最好的学习机会,通过透过问题看本质则是由虚到实,往深层次地挖掘,最后能形成底层技术深度加固。要真正的精通一门技术,最终还要通过实践来深入。问题是最好的实践。就像游泳教练,必定游泳水平好,因为这些都是实践性很强的工作。书上学来终觉浅,绝知此事要躬行。
在实践中,遇到问题,不仅只解决问题,还要对问题刨根问底,深入挖掘问题发生的根本原因,这样可以系统性地修复问题,从而使其永久消失。从问题本身着手,沿着因果关系链条,顺藤摸瓜,穿越不同的抽象层面,直至找出原有问题的根本原因.
我们中国古代以来就有“打破沙锅问到底”的习惯;“打破沙锅问到底”是一句俗语,形象表达了锲而不舍、不断探索的精神,这是人们常挂在嘴边的一句口头禅。
我们遇到问题,从外到里,逐层分析:
1、问题表象是什么
2、直接原因是什么?
3、中间原因是什么?
4、根本原因是什么?
真正的解决问题必须找出问题的根本原因,如果只解决问题,而不深入问题背后的根本原因,这门技术也是不够深入。
比如:
问题:java应用出现超时抖动?
1)解决:Java应用出现FGC. (增大 -Xmx -Xms 内存设置)
2)、直接原因:流量激增? 长时间运行? 代码问题导致占用内存对象不释放?。。。
3)、中间原因:流量没有做预警? 研发人员能力问题?
4)、根本原因:JVM虚拟机的基本原理?GC机制? JVM性能监控?......
2、理解本质
将世界万物理解为原子,将整个互联网理解成0和1,这倒的确是非常本质了,不过并不能解答任何问题。从问题看本质,实质上是一个从表层逐步深入的过程。遇到问题要打破砂锅问到底,了解最终引发问题的根本原因,最后形成高效解决问题的能力:解决问题和绕开问题。
3、善于总结、不断反思。
每一次的总结和反思,只要足够深刻、足够深入骨髓,乃至触及灵魂和价值观,都可以是一次浴火重生。总结是深刻反思的过程,总结是自我检视、自我完善的过程,由“经事”而“长智”的过程,正是“吃一堑长一智”。
比如我们上面遇到的问题,做一次总结自我(最好是更新到团队的wiki)的模版如下:
一、问题现象:
1、jvm进程占用cpu比较高,1500~2500%
2、通过jstat -gc pid查看进程,fgc比较频繁。
二、问题影响
1、用户反馈卡顿。
三、解决过程
1、修改堆内存 -Xmx16g -Xms16g -Xmn4G。问题没有解决,还是出现大量fgc。
2、修改堆内存 -Xmx32g -Xms32g -Xmn4G。问题没有解决,还是出现大量fgc。
3、修改堆内存 -Xmx32g -Xms32g -Xmn4G。问题没有解决,还是出现大量fgc。
4、修改堆内存 -Xmx60g -Xms60g -Xmn20G, fgc 降下来,但是实际问题还没有解决。
5、过jstack堆栈 找到问题的代码。
6、定位到具体出现问题的url。
7、定位到具体问题的流量源ip:10.164.32.20
8、禁用10.164.32.20访问,问题得到基本解决。
9、放开10.164.32.20访问。
10、修改app01 jvm的cms为g1,cpu使用率明显下降,从1500%降到700%左右。
11、接下来优化:检查代码创建大量对象是否合理,jvm设置60g堆内存是有点夸张。
四、问题原因
1、表象原因:10.164.32.20访问https://xxx.com/api/brt/index?act=subkexxxx&type=tot&user_id=xxxx&id=xxx流量过大,
同时处理返回json内容过大,导致在短时间内创建大量对象,造成堆内存过大,当jvm堆内存过小时候,就造成频繁gc(ygc+fgc),影响业务访问,出现卡顿现象。
2、根本原因:代码具体问题。
五、如何避免和提升
由于jstack能快速定位到代码问题,也在此顺便总结网上jstack使用案例。
四、jstack使用详解和案例
在之前的博客java(10)-JVM性能监控和优化总结过:
jstack [-l][F] pid
如果java程序崩溃生成core文件,jstack工具可以用来获得core文件的java stack和native stack的信息,从而可以轻松地知道java程序是如何崩溃和在程序何处发生问题。另外,jstack工具还可以附属到正在运行的java程序中,看到当时运行的java程序的java stack和native stack的信息, 如果现在运行的java程序呈现hung的状态,jstack是非常有用的。进程处于hung死状态可以用-F强制打出stack。
dump 文件里,值得关注的线程状态有:
死锁,Deadlock(重点关注)
执行中,Runnable
等待资源,Waiting on condition(重点关注)
等待获取监视器,Waiting on monitor entry(重点关注)
暂停,Suspended
对象等待中,Object.wait() 或 TIMED_WAITING
阻塞,Blocked(重点关注)
停止,Parked
关于线程的状态,具体博客Java(6)-java线程 总结java线程的状态和转换说明。
实例1:死锁
在多线程程序的编写中,如果不适当的运用同步机制,则有可能造成程序的死锁,经常表现为程序的停顿,或者不再响应用户的请求。比如在下面这个示例中,是个较为典型的死锁情况:
jstack输出的信息如下:
Thread-1" prio=5 tid=0x00acc490 nid=0xe50 waiting for monitor entry [0x02d3f000
..0x02d3fd68]
at deadlockthreads.TestThread.run(TestThread.java:31)
- waiting to lock <0x22c19f18> (a java.lang.Object)
- locked <0x22c19f20> (a java.lang.Object)
"Thread-0" prio=5 tid=0x00accdb0 nid=0xdec waiting for monitor entry [0x02cff000
..0x02cff9e8]
at deadlockthreads.TestThread.run(TestThread.java:31)
- waiting to lock <0x22c19f20> (a java.lang.Object)
- locked <0x22c19f18> (a java.lang.Object)
在 JAVA 5中加强了对死锁的检测。线程 Dump中可以直接报告出 Java级别的死锁,如下所示:
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x0003f334 (object 0x22c19f18, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x0003f314 (object 0x22c19f20, a java.lang.Object),
which is held by "Thread-1"
实例2:热锁
热锁,也往往是导致系统性能瓶颈的主要因素。其表现特征为,由于多个线程对临界区,或者锁的竞争,可能出现:
* 频繁的线程的上下文切换:从操作系统对线程的调度来看,当 线程在等待资源而阻塞的时候,操作系统会将之切换出来,放到等待的队列,当线程获得资源之后,调度算法会将这个线程切换进去,放到执行队列中。
* 大量的系统调用:因为线程的上下文切换,以及热锁的竞争,或 者临界区的频繁的进出,都可能导致大量的系统调用。
* 大部分 CPU开销用在 “系统态 ”:线程上下文切换,和系统调用,都会导致 CPU在 “系统态 ”运行,换而言之,虽然系统很忙碌,但是 CPU用在 “用户态 ”的比例较小,应用程序得不到充分的 CPU资源。
* 随着 CPU数目的增多,系统的性能反而下降。因为 CPU数目多,同 时运行的线程就越多,可能就会造成更频繁的线程上下文切换和系统态的 CPU开销,从而导致更糟糕的性能。
上面的描述,都是一个 scalability(可扩展性)很差的系统的表现。从整体的性能指标看,由于线程热锁的存在,程序的响应时间会变长,吞吐量会降低。< /span>
那么,怎么去了解 “热锁 ”出现在什么地方呢?一个重要的方法还是结合操作系统的各种工具观察系统资源使用状况,以及收集 Java线程的 DUMP信息,看线程都阻塞在什么方法上,了解原因,才能找到对应的解决方法。
我们曾经遇到过这样的例子,程序运行时,出现了以上指出的各种现象,通过观察操作系统的资源使用统计信息,以及线程 DUMP信息,确定了程序中热锁的存在,并发现大多数的线程状态都是 Waiting for monitor entry或者 Wait on monitor,且是阻塞在压缩和解压缩的方法上。后来采用第三方的压缩包 javalib替代 JDK自带的压缩包后,系统的性能提高了几倍。
实例3:cpu消耗过高的问题
1.第一步先找出Java进程ID: top查找出哪个进程消耗的cpu高
21125 co_ad2 18 0 1817m 776m 9712 S 3.3 4.9 12:03.24 java
5284 co_ad 21 0 3028m 2.5g 9432 S 1.0 16.3 6629:44 java
21994 mysql 15 0 449m 88m 5072 S 1.0 0.6 67582:38 mysqld
8657 co_sparr 19 0 2678m 892m 9220 S 0.3 5.7 103:06.13 java
这里我们分析21125这个java进程。
2.第二步找出该进程内最耗费CPU的线程:
可以使用ps -Lfp pid或者ps -mp pid -o THREAD, tid, time或者top -Hp pid,我这里用第三个,输出如下
top中shift+h查找出哪个线程消耗的cpu高
先输入top -p 21125,然后再按shift+h。这里意思为只查看21125的进程,并且显示线程。
21233 co_ad2 15 0 1807m 630m 9492 S 1.3 4.0 0:05.12 java
20503 co_ad2_s 15 0 1360m 560m 9176 S 0.3 3.6 0:46.72 java
21134 co_ad2 15 0 1807m 630m 9492 S 0.3 4.0 0:00.72 java
22673 co_ad2 15 0 1807m 630m 9492 S 0.3 4.0 0:03.12 java
这里我们分析21233这个线程,并且注意的是,这个线程是属于21125这个进程的。
第三步:jstack查找这个线程的信息
printf "%x\\n" 21742
得到21233的十六进制值为52f1,下面会用到。
jstack [进程]|grep -A 10 [线程的16进制]
即:
jstack 21125|grep -A 10 52f1
-A 10表示查找到所在行的后10行。21233用计算器转换为16进制52f1,注意字母是小写。
结果:
http-8081-11" daemon prio=10 tid=0x00002aab049a1800 nid=0x52f1 in Object.wait() [0x0000000042c75000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:485)
at org.apache.tomcat.util.net.JIoEndpoint$Worker.await(JIoEndpoint.java:416)
说不定可以一下子定位到出问题的代码。
实例4:Waiting to lock 和 Blocked
jstack输出的信息如下:
"RMI TCP Connection(267865)-172.16.5.25" daemon prio=10 tid=0x00007fd508371000 nid=0x55ae waiting for monitor entry [0x00007fd4f8684000]
java.lang.Thread.State: BLOCKED (on object monitor)
at org.apache.log4j.Category.callAppenders(Category.java:201)
- waiting to lock <0x00000000acf4d0c0> (a org.apache.log4j.Logger)
at org.apache.log4j.Category.forcedLog(Category.java:388)
at org.apache.log4j.Category.log(Category.java:853)
at org.apache.commons.logging.impl.Log4JLogger.warn(Log4JLogger.java:234)
at com.tuan.core.common.lang.cache.remote.SpyMemcachedClient.get(SpyMemcachedClient.java:110)
说明:
1)线程状态是 Blocked,阻塞状态。说明线程等待资源超时!
2)“ waiting to lock <0x00000000acf4d0c0>”指,线程在等待给这个 0x00000000acf4d0c0 地址上锁(英文可描述为:trying to obtain 0x00000000acf4d0c0 lock)。
3)在 dump 日志里查找字符串 0x00000000acf4d0c0,发现有大量线程都在等待给这个地址上锁。如果能在日志里找到谁获得了这个锁(如locked < 0x00000000acf4d0c0 >),就可以顺藤摸瓜了。
4)“waiting for monitor entry”说明此线程通过 synchronized(obj) …… 申请进入了临界区,从而进入了下图1中的“Entry Set”队列,但该 obj 对应的 monitor 被其他线程拥有,所以本线程在 Entry Set 队列中等待。
5)第一行里,"RMI TCP Connection(267865)-172.16.5.25"是 Thread Name 。tid指Java Thread id。nid指native线程的id。prio是线程优先级。[0x00007fd4f8684000]是线程栈起始地址。
实例5:Waiting on condition 和 TIMED_WAITING
jstack输出的信息如下:
"RMI TCP Connection(idle)" daemon prio=10 tid=0x00007fd50834e800 nid=0x56b2 waiting on condition [0x00007fd4f1a59000]
java.lang.Thread.State: TIMED_WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack)
at java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:198)
at java.util.concurrent.SynchronousQueue$TransferStack.awaitFulfill(SynchronousQueue.java:424)
at java.util.concurrent.SynchronousQueue$TransferStack.transfer(SynchronousQueue.java:323)
at java.util.concurrent.SynchronousQueue.poll(SynchronousQueue.java:874)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:945)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:907)
at java.lang.Thread.run(Thread.java:662)
说明:
1)“TIMED_WAITING (parking)”中的 timed_waiting 指等待状态,但这里指定了时间,到达指定的时间后自动退出等待状态;parking指线程处于挂起中。
2)“waiting on condition”需要与堆栈中的“parking to wait for <0x00000000acd84de8> (a java.util.concurrent.SynchronousQueue$TransferStack)”结合来看。首先,本线程肯定是在等待某个条件的发生,来把自己唤醒。其次,SynchronousQueue 并不是一个队列,只是线程之间移交信息的机制,当我们把一个元素放入到 SynchronousQueue 中时必须有另一个线程正在等待接受移交的任务,因此这就是本线程在等待的条件。
3)别的就看不出来了。
实例6:in Obejct.wait() 和 TIMED_WAITING
jstack输出的信息如下:
"RMI RenewClean-[172.16.5.19:28475]" daemon prio=10 tid=0x0000000041428800 nid=0xb09 in Object.wait() [0x00007f34f4bd0000] java.lang.Thread.State: TIMED_WAITING (on object monitor) at java.lang.Object.wait(Native Method) - waiting on <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:118) - locked <0x00000000aa672478> (a java.lang.ref.ReferenceQueue$Lock) at sun.rmi.transport.DGCClient$EndpointEntry$RenewCleanThread.run(DGCClient.java:516) at java.lang.Thread.run(Thread.java:662)
说明:
1)“TIMED_WAITING (on object monitor)”,对于本例而言,是因为本线程调用了 java.lang.Object.wait(long timeout) 而进入等待状态。
2)“Wait Set”中等待的线程状态就是“ in Object.wait() ”。当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(一般就是被 synchronized 的对象)的 wait() 方法,放弃了 Monitor,进入 “Wait Set”队列。只有当别的线程在该对象上调用了 notify() 或者 notifyAll() ,“ Wait Set”队列中线程才得到机会去竞争,但是只有一个线程获得对象的 Monitor,恢复到运行态。
3)RMI RenewClean 是 DGCClient 的一部分。DGC 指的是 Distributed GC,即分布式垃圾回收。
4)请注意,是先 locked <0x00000000aa672478>,后 waiting on <0x00000000aa672478>,之所以先锁再等同一个对象,请看下面它的代码实现:
static private class Lock ;
private Lock lock = new Lock();
public Reference<? extends T> remove(long timeout)
synchronized (lock)
Reference<? extends T> r = reallyPoll();
if (r != null) return r;
for (;;)
lock.wait(timeout);
r = reallyPoll();
……
即,线程的执行中,先用 synchronized 获得了这个对象的 Monitor(对应于 locked <0x00000000aa672478> );当执行到 lock.wait(timeout);,线程就放弃了 Monitor 的所有权,进入“Wait Set”队列(对应于 waiting on <0x00000000aa672478> )。
5)从堆栈信息看,是正在清理 remote references to remote objects ,引用的租约到了,分布式垃圾回收在逐一清理呢。
以上是关于java(13)-java进程CPU飙高排查:jstack使用案例的主要内容,如果未能解决你的问题,请参考以下文章