优化预测基于matlab萤火虫算法优化BP神经网络预测含Matlab源码 1313期
Posted 紫极神光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化预测基于matlab萤火虫算法优化BP神经网络预测含Matlab源码 1313期相关的知识,希望对你有一定的参考价值。
一、萤火虫优化算法(FA)简介
1 介绍
萤火虫(firefly)种类繁多,主要分布在热带地区。大多数萤火虫在短时间内产生有节奏的闪光。这种闪光是由于生物发光的一种化学反应,萤火虫的闪光模式因种类而异。萤火虫算法(FA)是基于萤火虫的闪光行为,它是一种用于全局优化问题的智能随机算法,由Yang Xin-She(2009)[1]提出。萤火虫通过下腹的一种化学反应-生物发(bioluminescence)发光。这种生物发光是萤火虫求偶仪式的重要组成部分,也是雄性萤火虫和雌性萤火虫交流的主要媒介,发出光也可用来引诱配偶或猎物,同时这种闪光也有助于保护萤火虫的领地,并警告捕食者远离栖息地。在FA中,认为所有的萤火虫都是雌雄同体的,无论性别如何,它们都互相吸引。该算法的建立基于两个关键的概念:发出的光的强度和两个萤火虫之间产生的吸引力的程度。
2 天然萤火虫的行为
天然萤火虫在寻找猎物、吸引配偶和保护领地时表现出惊人的闪光行为,萤火虫大多生活在热带环境中。一般来说,它们产生冷光,如绿色、黄色或淡红色。萤火虫的吸引力取决于它的光照强度,对于任何一对萤火虫来说,较亮的萤火虫会吸引另一只萤火虫。所以,亮度较低的个体移向较亮的个体,同时光的亮度随着距离的增加而降低。萤火虫的闪光模式可能因物种而异,在一些萤火虫物种中,雌性会利用这种现象猎食其他物种;有些萤火虫在一大群萤火虫中表现出同步闪光的行为来吸引猎物,雌萤火虫从静止的位置观察雄萤火虫发出的闪光,在发现一个感兴趣趣的闪光后,雌性萤火虫会做出反应,发出闪光,求偶仪式就这样开始了。一些雌性萤火虫会产生其他种类萤火虫的闪光模式,来诱捕雄性萤火虫并吃掉它们。
3 萤火虫算法
萤火虫算法模拟了萤火虫的自然现象。真实的萤火虫自然地呈现出一种离散的闪烁模式,而萤火虫算法假设它们总是在发光。为了模拟萤火虫的这种闪烁行为,Yang Xin-She提出了了三条规则(Yang,2009):
(1)假设所有萤火虫都是雌雄同体的,因此一只萤火虫可能会被其他任何萤火虫吸引。
(2)萤火虫的亮度决定其吸引力的大小,较亮的萤火虫吸引较暗的萤火虫。如果没有萤火虫比被考虑的萤火虫更亮,它就会随机移动。
(3)函数的最优值与萤火虫的亮度成正比。
光强(I)与光源距离(r)服从平方反比定律,因此由于空气的吸收,光的强度(I)随着与光源距离的增加而减小,这种现象将萤火虫的可见性限定在了非常有限的半径内:

萤火虫算法的主要实现步骤如下:

其中I0为距离r=0时的光强(最亮),即自身亮度,与目标函数值有关,目标值越优,亮度越亮;γ为吸收系数,因为荧光会随着距离的增加和传播媒介的吸收逐渐减弱,所以设置光强吸收系数以体现此特性,可设置为常数;r表示两个萤火虫之间的距离。有时也使用单调递减函数,如下式所示。

第二步为种群初始化:

其中t表示代数,xt表示个体的当前位置,β0exp(-γr2)是吸引度,αε是随机项。下一步将会计算萤火虫之间的吸引度:

其中β0表示r=0时的最大吸引度。
下一步,低亮度萤火虫向较亮萤火虫运动:
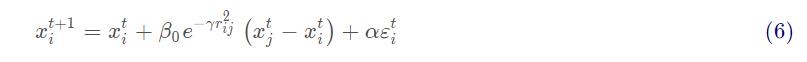
最后一个阶段,更新光照强度,并对所有萤火虫进行排序,以确定当前的最佳解决方案。萤火虫算法的主要步骤如下所示。
Begin
初始化算法基本参数:设置萤火虫数目n,最大吸引度β0,光强吸收系数γ,步长因子α,最大迭代次数MaxGeneration或搜索精度ε;
初始化:随机初始化萤火虫的位置,计算萤火虫的目标函数值作为各自最大荧光亮度I0;
t=1
while(t<=MaxGeneration || 精度>ε)
计算群体中萤火虫的相对亮度I(式2)和吸引度β(式5),根据相对亮度决定萤火虫的移动方向;
更新萤火虫的空间位置,对处在最佳位置的萤火虫进行随机移动(式6);
根据更新后萤火虫的位置,重新计算萤火虫的亮度I0;
t=t+1
end while
输出全局极值点和最优个体值。
end
萤火虫算法与粒子群算法(PSO)和细菌觅食算法(BFA)有相似之处。在位置更新方程中,FA和PSO都有两个主要分量:一个是确定性的,另一个是随机性的。在FA中,吸引力由两个组成部分决定:目标函数和距离,而在BFA中,细菌之间的吸引力也有两个组成部分:适应度和距离。萤火虫算法实现时,整个种群(如n)需要两个内循环,特定迭代需要一个外循环(如I),因此最坏情况下FA的计算复杂度为O(n2I)。
二、BP神经网络简介
1 BP神经网络概述
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature上的论文 Learning representations by back-propagating errors 。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的 输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断 调整网络的权值和阈值,使网络的误差平方和最小。
2 BP算法的基本思想
上一次我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这两个过程的具体流程会在后文介绍。
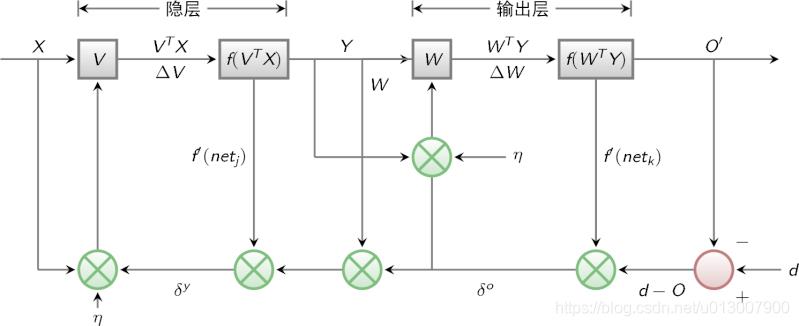
BP算法的信号流向图如下图所示
3 BP网络特性分析——BP三要素
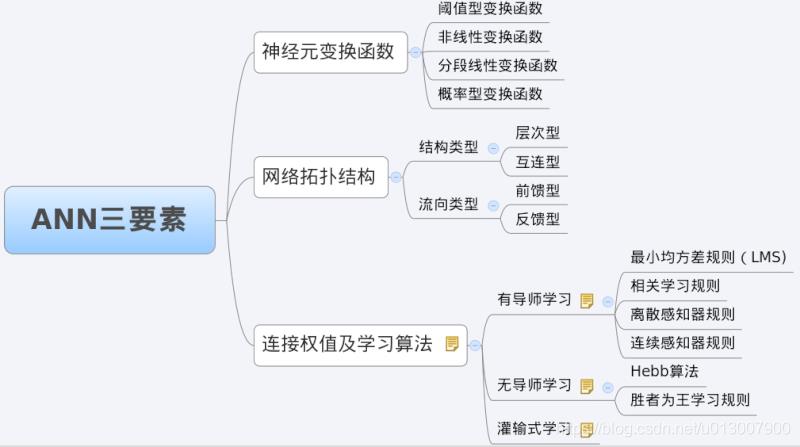
我们分析一个ANN时,通常都是从它的三要素入手,即
1)网络拓扑结构;
2)传递函数;
3)学习算法。
每一个要素的特性加起来就决定了这个ANN的功能特性。所以,我们也从这三要素入手对BP网络的研究。
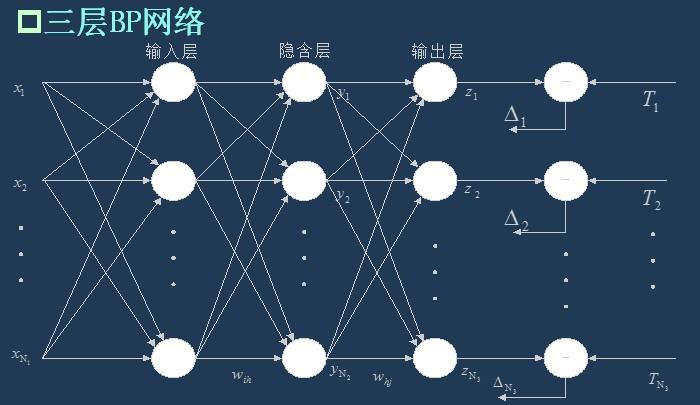
3.1 BP网络的拓扑结构
上一次已经说了,BP网络实际上就是多层感知器,因此它的拓扑结构和多层感知器的拓扑结构相同。由于单隐层(三层)感知器已经能够解决简单的非线性问题,因此应用最为普遍。三层感知器的拓扑结构如下图所示。
一个最简单的三层BP:
3.2 BP网络的传递函数
BP网络采用的传递函数是非线性变换函数——Sigmoid函数(又称S函数)。其特点是函数本身及其导数都是连续的,因而在处理上十分方便。为什么要选择这个函数,等下在介绍BP网络的学习算法的时候会进行进一步的介绍。
单极性S型函数曲线如下图所示。
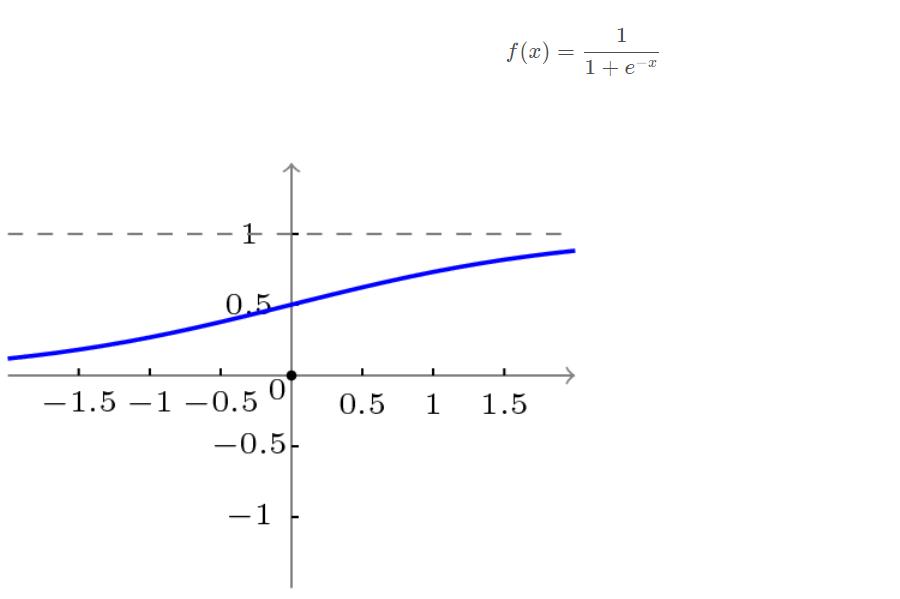
双极性S型函数曲线如下图所示。
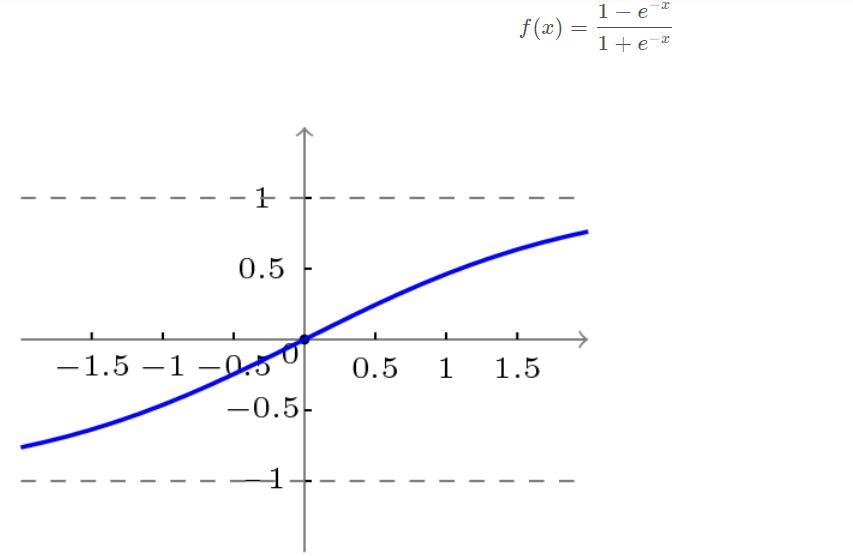
3.3 BP网络的学习算法
BP网络的学习算法就是BP算法,又叫 δ 算法(在ANN的学习过程中我们会发现不少具有多个名称的术语), 以三层感知器为例,当网络输出与期望输出不等时,存在输出误差 E ,定义如下



下面我们会介绍BP网络的学习训练的具体过程。
4 BP网络的训练分解
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
前向传输,逐层波浪式的传递输出值;
逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
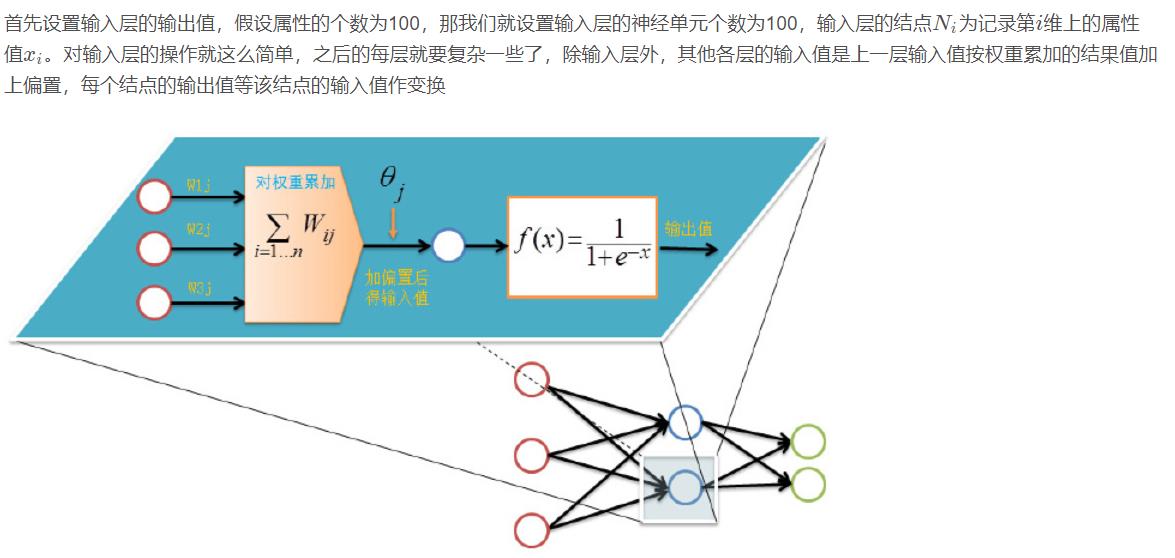
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[ − 1 , 1 ] [-1,1][−1,1]的一个随机实数,每一个偏置取[ 0 , 1 ] [0,1][0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
while 终止条件未满足:
for record:dataset:
trainModel(record)

4.1 逆向反馈(Backpropagation)


4.2 训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
设置最大迭代次数,比如使用数据集迭代100次后停止训练
计算训练集在网络上的预测准确率,达到一定门限值后停止训练
5 BP网络运行的具体流程
5.1 网络结构
输入层有n nn个神经元,隐含层有p pp个神经元,输出层有q qq个神经元。
5.2 变量定义


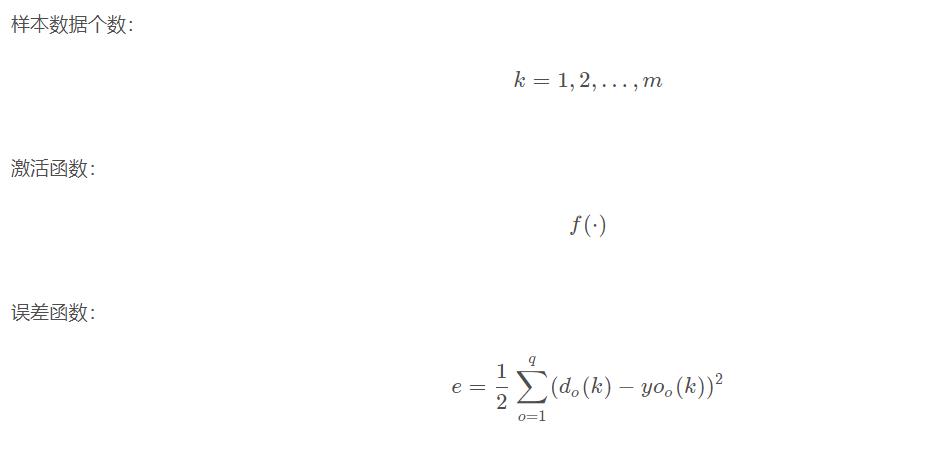


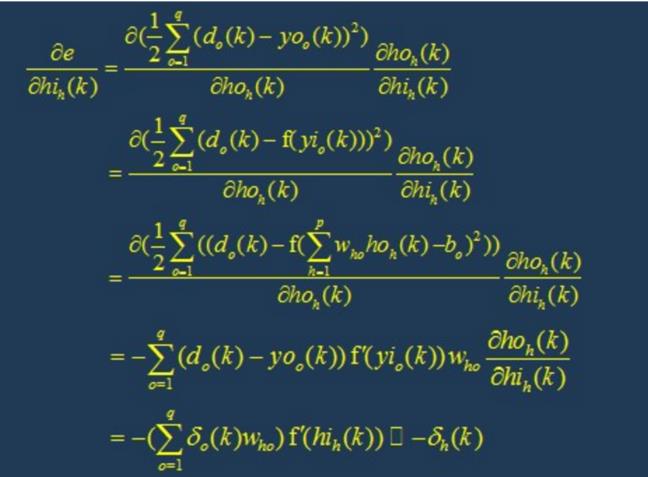


第九步:判断模型合理性
判断网络误差是否满足要求。
当误差达到预设精度或者学习次数大于设计的最大次数,则结束算法。
否则,选取下一个学习样本以及对应的输出期望,返回第三部,进入下一轮学习。
6 BP网络的设计
在进行BP网络的设计是,一般应从网络的层数、每层中的神经元个数和激活函数、初始值以及学习速率等几个方面来进行考虑,下面是一些选取的原则。
6.1 网络的层数
理论已经证明,具有偏差和至少一个S型隐层加上一个线性输出层的网络,能够逼近任何有理函数,增加层数可以进一步降低误差,提高精度,但同时也是网络 复杂化。另外不能用仅具有非线性激活函数的单层网络来解决问题,因为能用单层网络解决的问题,用自适应线性网络也一定能解决,而且自适应线性网络的 运算速度更快,而对于只能用非线性函数解决的问题,单层精度又不够高,也只有增加层数才能达到期望的结果。
6.2 隐层神经元的个数
网络训练精度的提高,可以通过采用一个隐含层,而增加其神经元个数的方法来获得,这在结构实现上要比增加网络层数简单得多。一般而言,我们用精度和 训练网络的时间来恒量一个神经网络设计的好坏:
(1)神经元数太少时,网络不能很好的学习,训练迭代的次数也比较多,训练精度也不高。
(2)神经元数太多时,网络的功能越强大,精确度也更高,训练迭代的次数也大,可能会出现过拟合(over fitting)现象。
由此,我们得到神经网络隐层神经元个数的选取原则是:在能够解决问题的前提下,再加上一两个神经元,以加快误差下降速度即可。
6.3 初始权值的选取
一般初始权值是取值在(−1,1)之间的随机数。另外威得罗等人在分析了两层网络是如何对一个函数进行训练后,提出选择初始权值量级为s√r的策略, 其中r为输入个数,s为第一层神经元个数。
6.4 学习速率
学习速率一般选取为0.01−0.8,大的学习速率可能导致系统的不稳定,但小的学习速率导致收敛太慢,需要较长的训练时间。对于较复杂的网络, 在误差曲面的不同位置可能需要不同的学习速率,为了减少寻找学习速率的训练次数及时间,比较合适的方法是采用变化的自适应学习速率,使网络在 不同的阶段设置不同大小的学习速率。
6.5 期望误差的选取
在设计网络的过程中,期望误差值也应当通过对比训练后确定一个合适的值,这个合适的值是相对于所需要的隐层节点数来确定的。一般情况下,可以同时对两个不同 的期望误差值的网络进行训练,最后通过综合因素来确定其中一个网络。
7 BP网络的局限性
BP网络具有以下的几个问题:
(1)需要较长的训练时间:这主要是由于学习速率太小所造成的,可采用变化的或自适应的学习速率来加以改进。
(2)完全不能训练:这主要表现在网络的麻痹上,通常为了避免这种情况的产生,一是选取较小的初始权值,而是采用较小的学习速率。
(3)局部最小值:这里采用的梯度下降法可能收敛到局部最小值,采用多层网络或较多的神经元,有可能得到更好的结果。
8 BP网络的改进
P算法改进的主要目标是加快训练速度,避免陷入局部极小值等,常见的改进方法有带动量因子算法、自适应学习速率、变化的学习速率以及作用函数后缩法等。 动量因子法的基本思想是在反向传播的基础上,在每一个权值的变化上加上一项正比于前次权值变化的值,并根据反向传播法来产生新的权值变化。而自适应学习 速率的方法则是针对一些特定的问题的。改变学习速率的方法的原则是,若连续几次迭代中,若目标函数对某个权倒数的符号相同,则这个权的学习速率增加, 反之若符号相反则减小它的学习速率。而作用函数后缩法则是将作用函数进行平移,即加上一个常数。
三、部分源代码
%% 清空环境
clc
clear
%读取数据
load data
z=data';
n=length(z);
for i=1:6;
sample(i,:)=z(i:i+n-6);
end
%训练数据和预测数据
input_train=sample(1:5,1:1400);
output_train=sample(6,1:1400);
input_test=sample(1:5,1401:1483);
output_test=sample(6,1401:1483);
%节点个数
inputnum=5;
hiddennum=3;
outputnum=1;
%构建网络
net=newff(inputn,outputn,hiddennum);
d=22;
%% 把最优初始阀值权值赋予网络预测
% %用遗传算法优化的BP网络进行值预测
dennum+hiddennum+hiddennum*outputnum);
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
net.iw1,1=reshape(w1,hiddennum,inputnum);
net.lw2,1=reshape(w2,outputnum,hiddennum);
net.b1=reshape(B1,hiddennum,1);
net.b2=B2;
%% BP网络训练
%网络进化参数
net.trainParam.epochs=100;
net.trainParam.lr=0.1;
%net.trainParam.goal=0.00001;
%网络训练
[net,per2]=train(net,inputn,outputn);
%% BP网络预测
%数据归一化
inputn_test=mapminmax('apply',input_test,inputps);
an=sim(net,inputn_test);
test_simu=mapminmax('reverse',an,outputps);
error=test_simu-output_test;
E=mean(abs(error./output_test))
plot(output_test,'b*')
hold on;
plot(test_simu,'-o')
title('结果','fontsize',12)
legend('实际值','预测值')
xlabel('时间')
ylabel('比较')
%% Cost or Objective function
function [nbest,fbest,NumEval]=ffa_mincon(u0,Lb,Ub,para,inputnum,hiddennum,outputnum,net,inputn,outputn) % para=[20 500 0.5 0.2 1];
% Check input parameters (otherwise set as default values)
if nargin<5, para=[20 50 0.25 0.20 1]; end
if nargin<4, Ub=[]; end
if nargin<3, Lb=[]; end
if nargin<2,
disp('Usuage: FA_mincon(@cost,u0,Lb,Ub,para)');
end
% n=number of fireflies
% MaxGeneration=number of pseudo time steps
% ------------------------------------------------
% alpha=0.25; % Randomness 0--1 (highly random)
% betamn=0.20; % minimum value of beta
% gamma=1; % Absorption coefficient
% ------------------------------------------------
n=para(1);
MaxGeneration=para(2); %MaxGeneration
alpha=para(3);
betamin=para(4);
gamma=para(5);
NumEval=n*MaxGeneration;
% Check if the upper bound & lower bound are the same size
if length(Lb) ~=length(Ub),
disp('Simple bounds/limits are improper!');
return
end
% Calcualte dimension
d=length(u0); %
% Initial values of an array
zn=ones(n,1)*10^100;
% ------------------------------------------------
% generating the initial locations of n fireflies
[ns,Lightn]=init_ffa(n,d,Lb,Ub,u0); %
% Iterations or pseudo time marching
for k=1:MaxGeneration, %%%%% start iterations
% This line of reducing alpha is optional
alpha=alpha_new(alpha,MaxGeneration);
% Evaluate new solutions (for all n fireflies)
for i=1:n,
zn(i)=fun(ns(i,:),inputnum,hiddennum,outputnum,net,inputn,outputn);
Lightn(i)=zn(i);
end
function error = fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn)
%该函数用来计算适应度值
%x input 个体
%inputnum input 输入层节点数
%outputnum input 隐含层节点数
%net input 网络
%inputn input 训练输入数据
%outputn input 训练输出数据
%error output 个体适应度值
%提取
w1=x(1:inputnum*hiddennum);%十个权值
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);%五个阈值
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);%五个权值
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);%一个阈值
%网络进化参数
net.trainParam.epochs=20;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
net.trainParam.show=100;
net.trainParam.showWindow=false;
%网络权值赋值
net.iw1,1=reshape(w1,hiddennum,inputnum);
net.lw2,1=reshape(w2,outputnum,hiddennum);
net.b1=reshape(B1,hiddennum,1);
net.b2=B2;
%应该是net是个结构体,然后第一个net.IW1,1是指第一层输入到隐藏层的权重,
%这里面第一个1代表隐藏层与此形成鲜明对比的就是第二行的代码:net.IW2,1则是说第一个隐藏层的输入矢量到输出层的权重,
%这里面的2代表输出层。理清这些,然后我们来看就很明显了:第一的赋值右边是将第一个w1矩阵变形为隐藏层个数*输入层个数。
%第二个则是从隐藏层到输出层,其中W1,W2都是权重矩阵。最后一行是对第一层(1表示出来了)的阈值赋值。
%网络训练
net=train(net,inputn,outputn);
an=sim(net,inputn);
error=sum(abs(an-outputn));
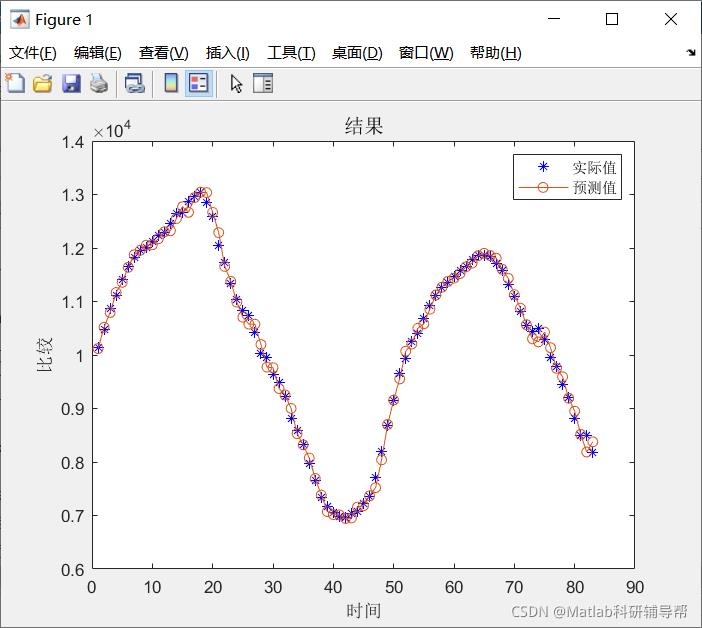
四、运行结果
五、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 包子阳,余继周,杨杉.智能优化算法及其MATLAB实例(第2版)[M].电子工业出版社,2016.
[2]张岩,吴水根.MATLAB优化算法源代码[M].清华大学出版社,2017.
[3]群体智能优化算法之萤火虫算法(Firefly Algorithm,FA)
以上是关于优化预测基于matlab萤火虫算法优化BP神经网络预测含Matlab源码 1313期的主要内容,如果未能解决你的问题,请参考以下文章
模糊回归预测基于matlab萤火虫算法优化模糊神经网络回归预测含Matlab源码 2034期
模糊回归预测基于matlab萤火虫算法优化模糊神经网络回归预测含Matlab源码 2034期
优化预测基于matlab蝙蝠算法优化BP神经网络预测含Matlab源码 1379期
优化预测基于matlab蝙蝠算法优化BP神经网络预测含Matlab源码 1379期