模式匹配:滚动哈希到 Rabin-Karp 算法
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模式匹配:滚动哈希到 Rabin-Karp 算法相关的知识,希望对你有一定的参考价值。
模式匹配:滚动哈希到 Rabin-Karp
暴力匹配
字符串匹配问题,从源字符串 s 中寻找目标子串 t。
- 源字符串 s :1234
- 目标子串 t :3
- 返回结果 :找到返回下标,否则返回 -1
实现一个算法,第一步是实现函数原型(函数名、输入输出、面向对象/过程)、边界判断、循环不变量、有限步骤、错误处理的编写。
函数原型:
int bruteforce(char *s, char *t)
if(strlen(s) < strlen(t)) // s 长,t 短
return -1;
算法逻辑中,最重要的是找到循环不变量:
int len_s = strlen(s);
for(int i=0; i<len_s; i++) // 在 s 中寻找 t
但其实这里还做了无用功,如果当前起始位置 i 开始,后面的字符的个数已经比 t 的个数还要少了,长度不一样,根本不可能匹配到了。
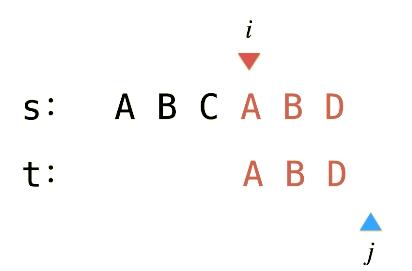
如果上图,若 s[i, i + len_t - 1] == t 说明长度符合,否则不能匹配了。
int len_s = strlen(s);
int len_t = strlen(t);
for(int i=0; i + len_t <= len_s; i++) // s[i, i + len_t - 1] == t,更新循环不变量范围,缩减不必要的部分
完整代码:
// 在 s 中寻找 t,找到返回下标,否则返回 -1
int bruteforce(char *s, char *t)
if(strlen(s) < strlen(t)) // s 长,t 短
return -1;
int len_s = strlen(s);
int len_t = strlen(t);
for(int i=0; i + len_t <= len_s; i++) // s[i, i + len_t - 1] == t ?
int j = 0;
for( ;j<len_t; j++)
if(s[i+j] != t[j])
break;
if(j == len_t)
return i;
return -1;
哈希思想
哈希是一种思想,看到字符串时,就可以想哈希。
暴力匹配,每次匹配失败,会重新扫描一遍 t:
- 比较俩个字符串相等,要 O ( n ) O(n) O(n)
- 比较俩个整型相等,要 O ( 1 ) O(1) O(1)。
通过哈希,把字符串转整型,只需要把字符串看成一个 B 进制的数字:
- h a s h ( c o d e ) = ( c ∗ B 3 + o ∗ B 2 + d ∗ B 1 + e ∗ B 0 ) % M hash(code)=(c*B^3+o*B^2+d*B^1+e*B^0)\\% M hash(code)=(c∗B3+o∗B2+d∗B1+e∗B0)%M
如果只有小写字母,也就是 a-z(26 个字母),那 B 就是 26 进制,如果是任意字符,那 B 就是 256 进制。
不过因为整型存储有限,计算过程中要防止溢出:
- h a s h ( c o d e ) = ( ( ( c ∗ B + o ) % M ∗ B + d ) % M ∗ B + e ) % M hash(code)=(((c*B+o)\\%M*B+d)\\%M*B+e)\\% M hash(code)=(((c∗B+o)%M∗B+d)%M∗B+e)%M
string s = "abcdefg";
int hash = 0;
int B = 256;
long MOD = (long)(1e9 + 7); // 素数,防止溢出
for(int i=0; i<len; i++)
hash = (hash * B + s[i]) % MOD
滚动哈希
滚动哈希 = 哈希思想 + 滑动窗口。
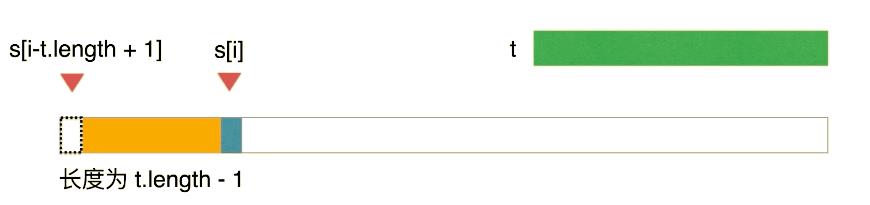
哈希思想是把字符串转整型:
- 把字符串看成一个 B 进制的数字: h a s h ( c o d e ) = ( ( ( c ∗ B + o ) % M ∗ B + d ) % M ∗ B + e ) % M hash(code)=(((c*B+o)\\%M*B+d)\\%M*B+e)\\% M hash(code)=(((c∗B+o)%M∗B+d)%M∗B+e)%M
而滑动窗口是把目标子串 t 当作一个长度为 t 的窗口,在源字符串 s 上滚动,如果相等就说明找到了。
我们发现如果把源目标串 s 当成 N 个子串,那第一个子串、第二个子串之间,相同的字符有 9 个,只有 1 个字符有区别。如下图的对比:


那字符串匹配问题,就是 t 在 s 上不断滚动匹配,我们只需要保持一个长度为 t.length() 的窗口即可。
滚动过程:第 1 个字符删除,再最后位置添加 1 个字符。

那这个过程怎么写成计算公式?
- 添加字符: h a s h = h a s h ∗ 10 + m a p [ s [ i ] ] hash = hash * 10 + map[~s[i]~] hash=hash∗10+map[ s[i] ]
- 删除字符: h a s h = h a s h − m a p [ s [ i − 9 ] ] ∗ 1 0 9 hash = hash - map[~s[i-9]~]*10^9 hash=hash−map[ s[i−9] ]∗109
如 s[i] = 2:
- 添加字符: 123412341 ∗ 10 + 2 = 1234123412 123412341 * 10 + 2 = 1234123412 123412341∗10+2=1234123412
- 删除字符: 1234123412 − 1000000000 = 234123412 1234123412 - 1000000000=234123412 1234123412−1000000000=234123412
整个过程以此类推,这种方式叫滚动哈希。
Rabin-Karp 算法
使用滚动哈希求解字符串匹配问题,对应的这个思路的算法,就叫 Rabin-Karp 算法。
class Solution
public:
vector<string> Rabin-Karp(string s, string t)
if(s.length() < 0) return s;
long thash = 0, MOD = (long)1e9 + 7, B = 256;
for(int i=0; i<t.length(); i++)
thash = (thash * B + s[i]) % MOD;
long hash = 0, P = 1;
for(int i=0; i<t.length()-1; i++)
P = P * B % MOD;
for(int i=0; i<t.length()-1; i++)
hash = (hash * B + s[i]) % MOD;
for(int i=t.length()-1; i<s.length(); i++)
hash = (hash * B + s[i]) % MOD;
if( hash == thash && equals(s, i-t.length()+1, t) )
return i - t.length() + 1;
hash = (hash - s[i - t.length() + 1] * P % MOD + MOD) % MOD;
return -1;
bool equals(string s, int l, string t)
for(int i=0; i<t.length(); i++)
if(t[i] != s[i+l]) return false;
return true;
;
1147.段式回文
滚动哈希分析链接:[1147].段式回文
1392.最长快乐前缀
滚动哈希分析链接:[1392].最长快乐前缀
187.重复的 DNA 序列
滚动哈希分析链接:[187].重复的 DNA 序列
以上是关于模式匹配:滚动哈希到 Rabin-Karp 算法的主要内容,如果未能解决你的问题,请参考以下文章