Python入门自学进阶——10-线程进程
Posted kaoa000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门自学进阶——10-线程进程相关的知识,希望对你有一定的参考价值。
线程是操作系统能够进行运算调度的最小单位,包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
进程是一个资源的集合集
进程
计算机的核心是CPU,它承担了所有的计算任务,而操作系统是计算机的管理者,它负责任务的调度,资源的分配和管理,统领整个计算机硬件;应用程序是具有某种功能的程序,程序是运行于操作系统之上的。
进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,没有统一的标准定义。进程一般由程序,数据集合和进程控制块三部分组成。程序用于描述进程要完成的功能,是控制进程执行的指令集;数据集合是程序在执行时所需要的数据和工作区;程序控制块包含进程的描述信息和控制信息,是进程存在的唯一标志
进程具有的特征:
动态性:进程是程序的一次执行过程,是临时的,有生命期的,是动态产生,动态消亡的;
并发性:任何进程都可以同其他进行一起并发执行;
独立性:进程是系统进行资源分配和调度的一个独立单位;
结构性:进程由程序,数据和进程控制块三部分组成
线程
早期的操作系统中并没有线程的概念,进程是拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。
随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID,当前指令指针PC,寄存器和堆栈组成。而进程由内存空间(代码,数据,进程空间,打开的文件)和一个或多个线程组成。
进程与线程的区别
1. 线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;
2. 一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线
3. 进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段,数据集,堆等)及一些进程级的资源(如打开文件和信号等),某进程内的线程在其他进程不可见;
4. 调度和切换:线程上下文切换比进程上下文切换要快得多

一个普通的程序和有线程的:

通过上面例子的比对,有线程的例子运行时间要短。
另一个对比的例子:
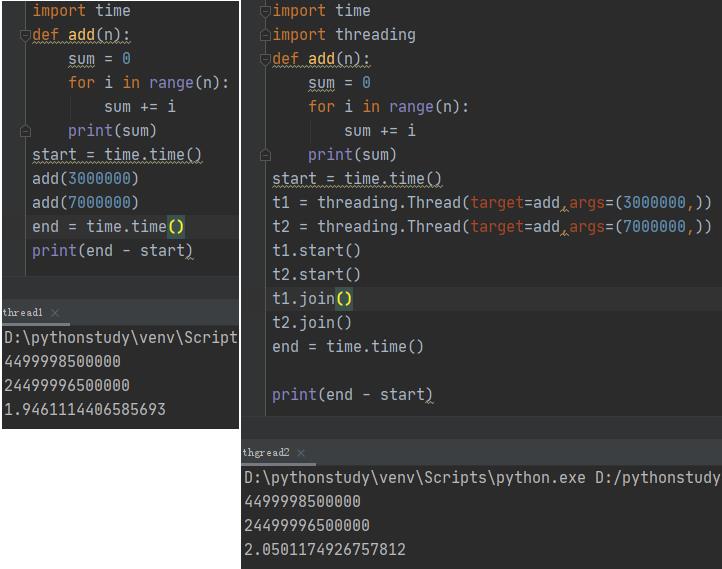
有线程的例子运行时间长。
程序,可以分为两种类型,IO密集型和计算密集型,对于IO密集型,使用线程会缩短运行时间,因为在进行IO时,CPU会进行切换,运行其他线程,从而缩短整个程序的运行时间,而计算密集型,其CPU基本一直在运行中,使用线程不能增加CPU的使用率,反而因为频繁的线程切换,导致运行时间增加。
上面的第一个例子就是IO密集型程序,第二个例子是计算密集型,所以使用线程后的表现是不一样的。
当然,上面是针对单CPU内核而言的,如果是多核或多CPU,线程会优化程序运行。
对于上面例子,运行的CPU是AMD A10CPU,是四核的,按理说对于计算密集型的也应该优化性能。之所以没有优化,是因为Python的Cpython解释器的GIL所致。
GIL——全局解释器锁(Global Interpreter Lock)
GIL 是最流程的 CPython 解释器(平常称为 Python)中的一个技术术语,中文译为全局解释器锁。GIL 的功能是:在 CPython 解释器中执行的每一个 Python 线程,都会先锁住自己,以阻止别的线程执行。当然,CPython 不可能让一个线程一直独占解释器,它会轮流执行 Python 线程。这样一来,用户看到的就是“伪”并行,即 Python 线程在交替执行,来模拟真正并行的线程。这就是为什么计算密集型任务无法优化的原因,因为每次都是一个线程在运行,也就是同一时间只有一个CPU在工作,多核的优势没有发挥出来。

Thread 1、2、3 轮流执行,每一个线程在开始执行时,都会锁住 GIL,以阻止别的线程执行;同样的,每一个线程执行完一段后,会释放 GIL,以允许别的线程开始利用资源。
CPython 中还有另一个机制,叫做间隔式检查(check_interval),意思是 CPython 解释器会去轮询检查线程 GIL 的锁住情况,每隔一段时间,Python 解释器就会强制当前线程去释放 GIL,这样别的线程才能有执行的机会。
解决的一种方法是可以使用多进程,还可以使用协程。
线程的使用:
要引入threading模块,threading.Thread(target=,args=(,))方法创建一个线程,参数target指定线程的主体,即程序中哪一部分作为线程的主体,主要就是指定一个函数,args是作为线程的函数的参数,是一个元组。启动线程使用.start()方法,.join()方法是指定子线程结束后在往下执行父线程。即调用join()方法的线程被阻塞。
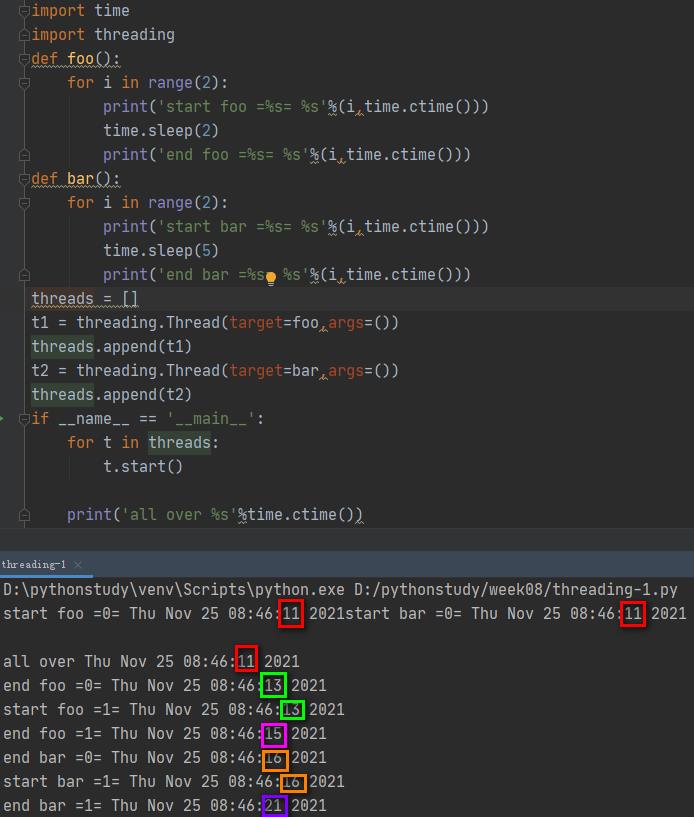
此程序结果,程序运行分为三个线程,主程序启动的是主线程,然后是t1和t2,从运行结果猜测,主线程运行循环,启动了两个子线程,然后,切换到t1,打印第一行,遇到sleep,切换到t2,打印第一行,遇到sleep,切换到主线程,主线程继续运行,打印最后一行,主线程结束。子线程继续相互切换直至结束。这里主要要确定start()方法后是否立即启动,即start后立即切换到相应的线程运行。看下面的线程运行
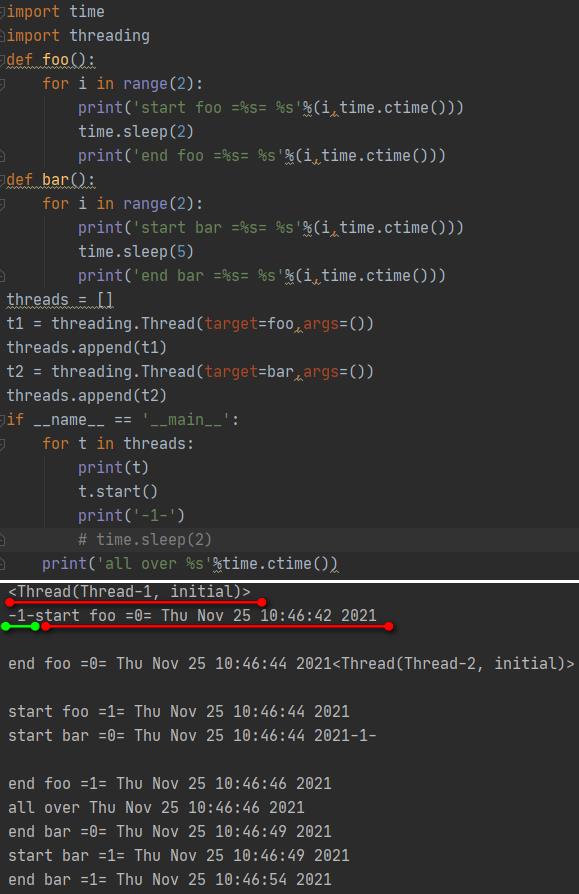
主要看绿线的-1-,说明在t1.start()后,没有立即切换,又执行了主线程的打印,然后才切换到t1线程。所以,有可能先打印all over,主线程先结束了,两个子线程还在运行。
可以在主线程中使用t1.join(),t2.join()方法,使主线程一直阻塞,直到两个线程运行完毕,才能继续接着运行,这样主线程一定会是最后运行完毕的。
修改一下:
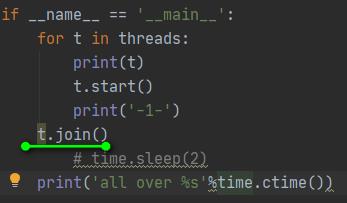
知识点,一个是测试join方法,一个是for语句不能开辟命名空间,这里t.join()是可以使用,这时的t是线程t2。
setDaemon()方法,守护线程:
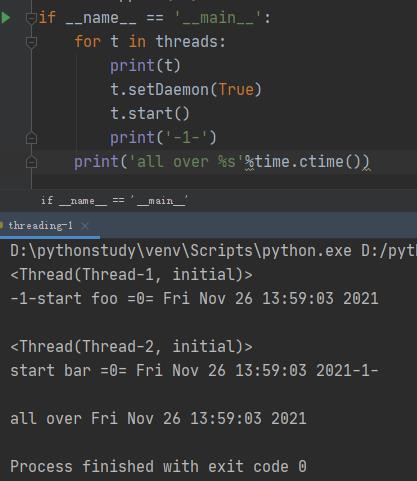
将线程设置为setDaemon(True),则在主线程结束后,被设为setDaemon(True)的线程就结束了,不再运行。
两个线程都设置为True:
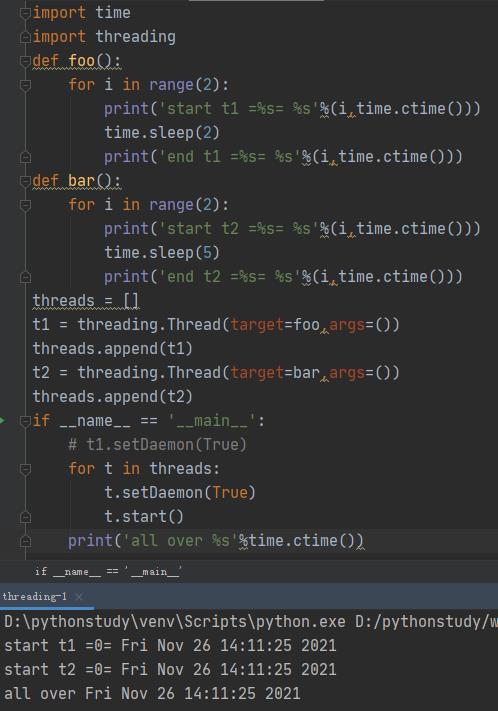
t1设置:

t2设置:
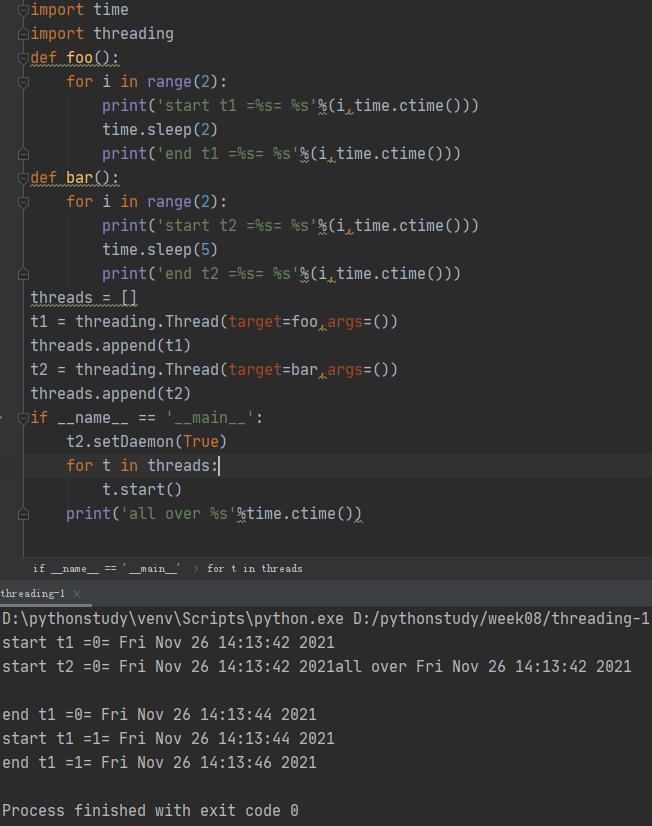
从上面的运行结果,对于设置了setDaemon为True的线程,其会监控没有设置的线程,只要所有没有设置为setDaemon(True)的线程结束,这个线程就结束。
t1和t2都设置,它们两个监控主线程,主线程结束,这两个线程结束。
t1设置,则t1监控主线程和t2子线程,因为t1时间比t2短,所以t1能够运行完,他要等t2运行完毕,这样,结果就是主线程、t1、t2都运行结束。
t2设置,则t2监控主线程和t1子线程,因为t2时间比t1和主线程的长,所以,主线程和t1先运行完毕,t1的结果打印完全,t1结束,t2跟着就结束了,所以t2没有打印完全。
这就是守护线程的作用。
可以使用类进行线程操作:
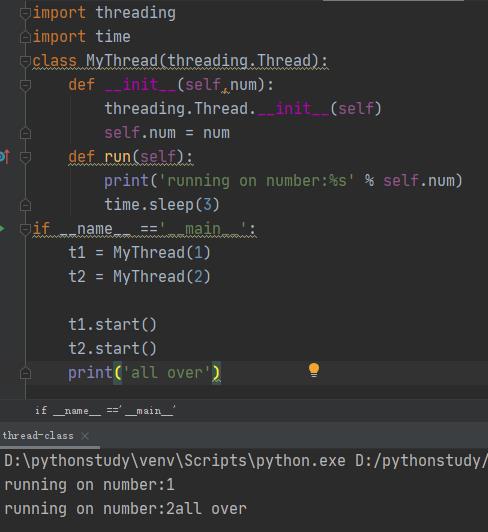
我们定义的类要继承threading.Thread类,其中的__init__()就是生成一个线程,相当于我们前面的t1 = threading.Thread(target=,args=(,)),而类中的run方法定义每个线程要运行的函数,相当于前面语句中的target,args则在self中保存了。
以上是关于Python入门自学进阶——10-线程进程的主要内容,如果未能解决你的问题,请参考以下文章