[人工智能-深度学习-53]:LSTM长短记忆时序模型的简化GRU模型
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[人工智能-深度学习-53]:LSTM长短记忆时序模型的简化GRU模型相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121599096
目录
第1章 前序知识
1.1 RNN循环神经网络模型
 https://blog.csdn.net/HiWangWenBing/article/details/121387285
https://blog.csdn.net/HiWangWenBing/article/details/1213872851.2 LSTM长短记忆时序模型
1.3 LSTM模型的缺点
随着 LSTM 在自然语言处理特别是文本分类任务的广泛应用,人们逐渐发现 LSTM有如下一些缺点:
- 具有训练时间长
- 参数较多
- 内部计算复杂
LSTM的简化模型GRU因运而生。
第2章 GRU模型详解
2.1 GRU模型概述
GRU是LSTM网络的一种效果很好的变体,相比较LSTM网络,GRU网络的结构更加简单,效果也很好,同时它也可以较好的解决RNN网络中长依赖、梯度消失等问题。因此也是当前非常流形的一种网络。
2.2 RNN网络结构对比

2.3 LSTM网络结构对比

2.4 GRU网络的结构
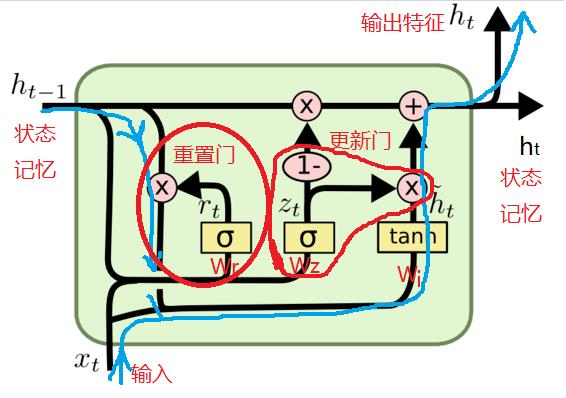
(1)输入:与RNN网络一致
- 当前的时序样本输入Xt
- 先前保存的状态Ht-1
- Ht-1与Xt组合成[Ht-1, Xt] ,作为后续控制门的输入
(3)输出:与RNN网络一致
- 输入:[Ht-1, Xt]
- 运算矩阵Wi
- 激活函数Tanh
- 功能:生成本次迭代提取的新的状态特征 ~Ht
- 数学表达式:

(3)Ht-1状态输入重置门:与LSTM类似
- 输入:[Ht-1, Xt]
- 运算矩阵Wr
- 激活函数sigmod
- 输出在[0, 1]之间
- 功能(乘法):用于对先前状态Ht-1的过滤选择。它决定了先前的状态Ht-1,有多大的比例能够参与本次特征状态输出Ht。0表示忽略先前保留的状态,1表示完全使用先前的状态,其他值表示使用先前状态的程度。
- 数学表达式:
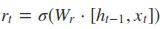
(4)Ht状态更新门: 与LSTM类似
- 输入:[Ht-1, Xt]
- 运算矩阵Wz
- 激活函数sigmod
- 输出在[0, 1]之间
- 功能(乘法):用于对当前状态Ht的更新控制。它决定了本次迭代的输出,多大程度可以用于最终的特征状态输出。0表示忽略本次迭代的状态输出,1表示100%使用当前的状态输出,其他值表示使用当前状态的程度。
- 数学表达式:
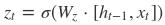
(5)Ht的状态更新:与LSTM类似
- 输入1= 先前状态Ht-1 * (1 - 状态更新门的输出)
- 输入2 = 当前新生成的状态~Ht * 状态更新门的输出
- 运算:累加/叠加 = 输入1 + 输入2 =》

2.5 GRU网络特点
LSTM和CRU都是通过各种门函数来将重要特征保留下来,这样就保证了在long-term传播的时候也不会丢失。
此外GRU相对于LSTM少了一个门函数,因此在参数的数量上也是要少于LSTM的,所以整体上GRU的训练速度要快于LSTM。
第3章 GRU的反向传播
从前向传播过程中的公式可以看出要学习的参数有Wr、Wz、Wh、Wo。其中前三个参数都是拼接的(因为后先的向量也是拼接的),所以在训练的过程中需要将他们分割出来:


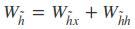
输出层的输入: 
输出层的输出: 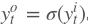
在得到最终的输出后,就可以写出网络传递的损失,单个样本某时刻的损失为:

则单个样本的在所有时刻的损失为:
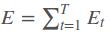
采用后向误差传播算法来学习网络,所以先得求损失函数对各参数的偏导(总共有7个):

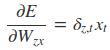
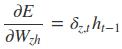
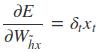


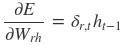
其中各中间参数为:
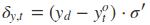
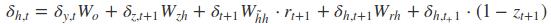

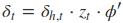

在算出了对各参数的偏导之后,就可以更新参数,依次迭代知道损失收敛。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/121599096
以上是关于[人工智能-深度学习-53]:LSTM长短记忆时序模型的简化GRU模型的主要内容,如果未能解决你的问题,请参考以下文章