基于多智能体强化学习的自动化集装箱码头无冲突AGV路径规划
Posted 码丽莲梦露
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于多智能体强化学习的自动化集装箱码头无冲突AGV路径规划相关的知识,希望对你有一定的参考价值。
《Anti-conflict AGV path planning in automated container terminals based on multi-agent reinforcement learning》
International journal of production research/2021
1 摘要
AGV冲突预防路径规划是提高集装箱码头运输成本和运营效率的关键因素。研究了集装箱自动化码头(ACTS)水平运输区自动导引车(AGV)的防冲突路径规划问题。根据磁钉导引AGVS的特点,构建了节点网络。通过对对向冲突和同点占领冲突两种冲突情况的分析,建立了求解最短路径的整数规划模型。针对这一问题,提出了多Agent深度确定性策略梯度(MADDPG)方法,并采用Gumbel-Softmax策略对节点网络产生的场景进行离散化。通过一系列的数值实验,验证了模型和算法的有效性和高效性。
2 介绍
如图1所示,ACT大体上分为三个区域,即岸边的码头起重机作业区、岸边的堆场作业区和水平运输区。自动导引车(AGV)是连接ACT陆岸和海边的重要运输设备,主要在水平运输区域行驶。AGV沿着指定的路径行驶,将集装箱从海边运送到堆场或从堆场运送到海边。
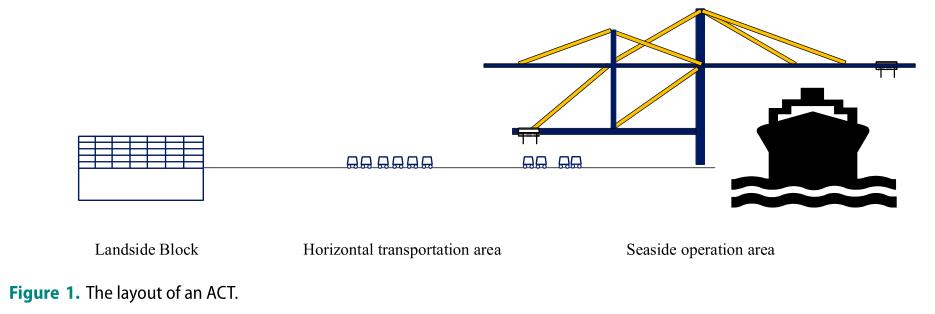
AGV到达海边或堆场的延误增加了装卸的等待时间,增加了成本。因此,对AGV行驶路径的合理规划和AGV冲突的优化不仅能提高整个自动化运输系统的运行效率,还能使AGV的运行效率得到很大的提高。
本文的贡献主要体现在以下几个方面:
(1)根据磁钉的分布和AGV在水平运输区域的驱动规律,构造了一个节点网络。通过分析反向冲突情况和同点占用冲突情况,建立了一个整数规划(IP)模型,该模型旨在同时获得多个AGV的无路径冲突的最短路径。
(2)针对AGV路径规划问题,提出了一种基于强化学习的多智能体深度确定性策略梯度(MADDPG)策略的AGV路径规划方法。由于节点网络创建的场景是离散的,MADDPG算法用于连续场景,因此采用Gumbel Softmax技术对问题进行离散化。
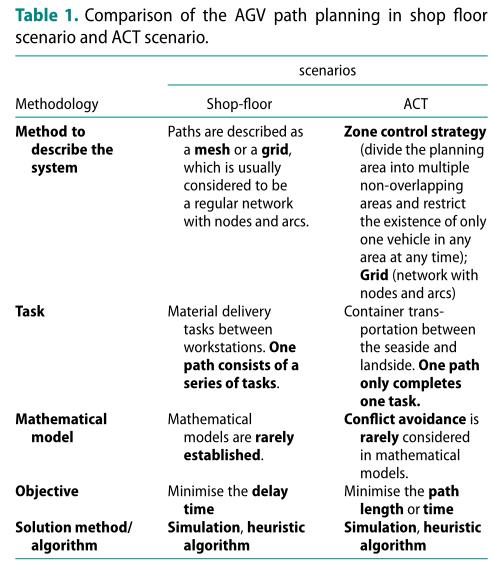
车间场景和ACT场景中AGV路径规划的比较:
3 问题描述和数学模型
3.1 问题描述
首先接收集装箱作业任务指令;然后规划到作业任务指令的装卸位置的合理路径;然后与装卸设备一起将集装箱装入AGV/从AGV卸下集装箱,完成装卸作业;最后等待下一指令。
AGV的任务分配在上层决策中完成。由于自动导引车路径规划问题是一个不确定的问题,规划周期相对较短。在这种情况下,大多数自动导引车在规划范围内只能完成一项任务。在本研究中,我们只考虑在如此短的规划时间内每个AGV第一个任务的路径规划。对于更长的规划范围,我们的算法可以纳入滚动优化方法。
3.2 港口布局
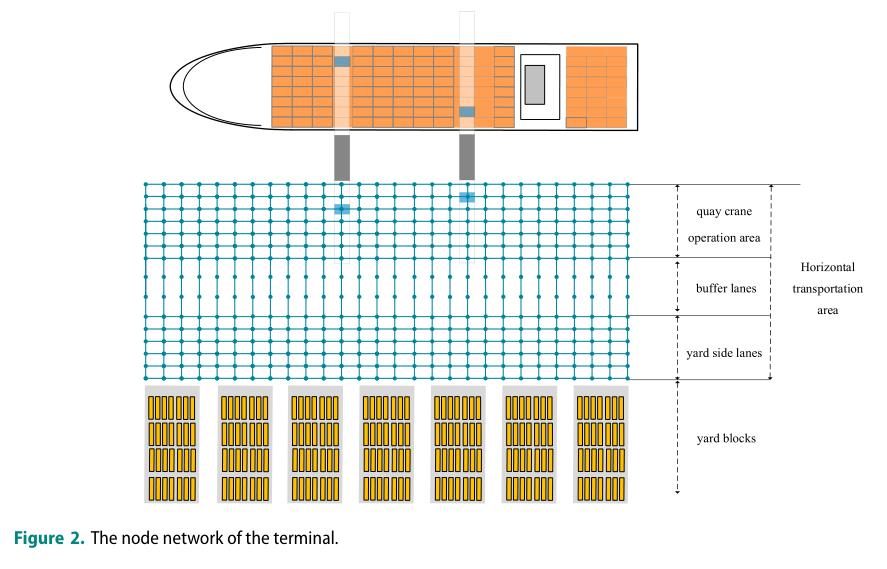
ACT的水平运输区是一个形状规则、无人操作的区域。与一般制造系统不同,该区域没有障碍物或工作站。为了准确描述ACT中的AGV路径规划问题,根据磁钉导向驱动的特点,构建了港口布局节点网络,如图2所示。AGV在完成任务分配后,需要经过多个节点才能完成任务。
3.3 行驶规则
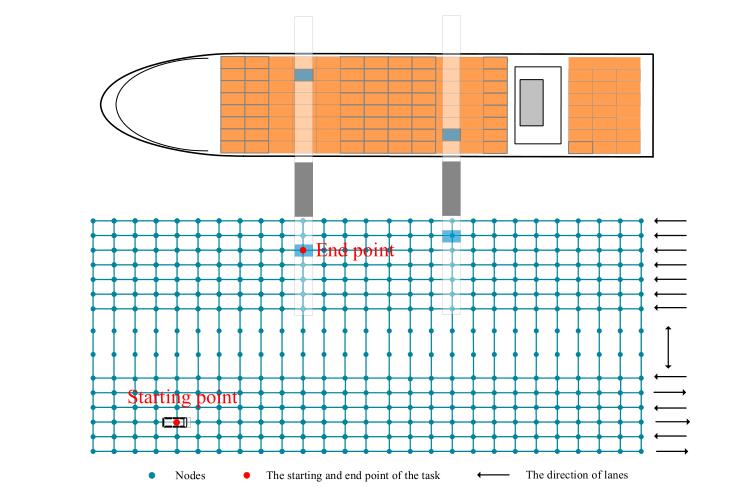
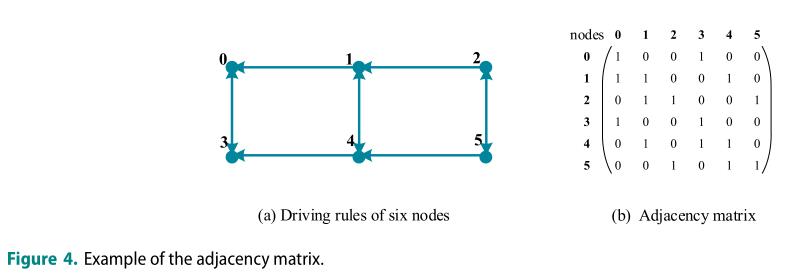
AGV在任何时候都可以保持在当前位置或者行驶到规则允许的相邻节点,每个节点最多能容纳一个AGV,AGV不允许在网络之外行驶,如图3所示,在水平方向上,岸吊作业区有7条单向车道,在场地一侧的车道上交替设置6条单向车道,垂直方向的节点是双向的。
邻接矩阵是根据数学模型中ACT的行驶规则来设定的。图4(a)显示了当有6个节点时的驱动规则。相邻节点可以在垂直方向上相互通过,并且可以通过水平方向传递信息。图4(b)显示相应的邻接矩阵。1表示可以达到,0表示不可能达到。
3.4 任务定义
通常,ACTs的任务分为装载任务和卸载任务。装载任务是AGV捡起集装箱并通过水平运输区将其运输到指定的码头起重机操作位置,而卸载任务则相反。本文不区分任务是加载任务还是卸载任务,只区分AGV的开始结束节点,而AGV的路径规划是生成从当前位置到终点的路径。
3.5 冲突情况
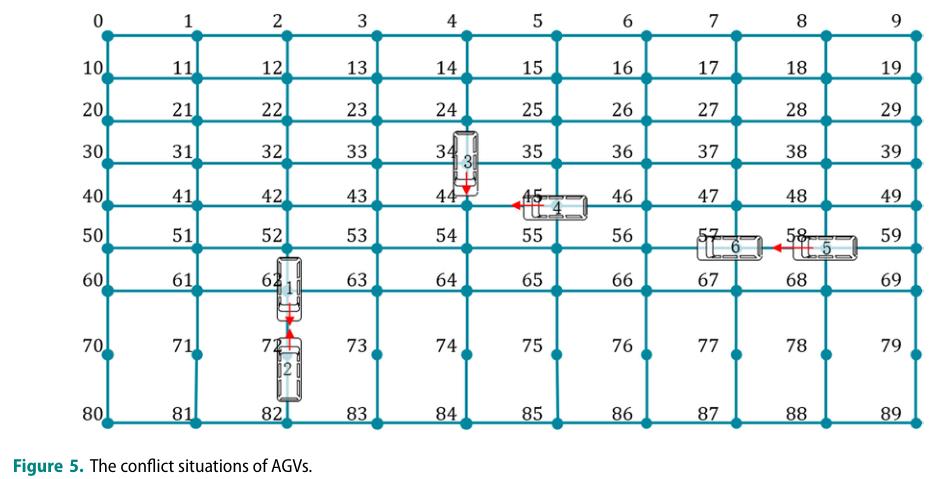
根据港口布局的节点网络和行为的实际情况,图5显示了两种冲突情况: 对立冲突和同点占领冲突。
4 多智能体强化学习
4.1 环境设置
状态:AGV的当前位置
动作:AGV的方向,移动速度
AGV之间的冲突风险可以通过距离函数获得:
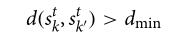
这是两辆 AGVs 之间最短的距离。例如,dmin = 1表示两个 agvs 之间有一个单位距离。当两个 agvs 之间的距离小于阈值距离时,将生成两个 agvs 之间的距离,直到下一个状态的 agvs 满足最小距离要求。
奖励:

4.2 Gumbel-softmax 抽样方法
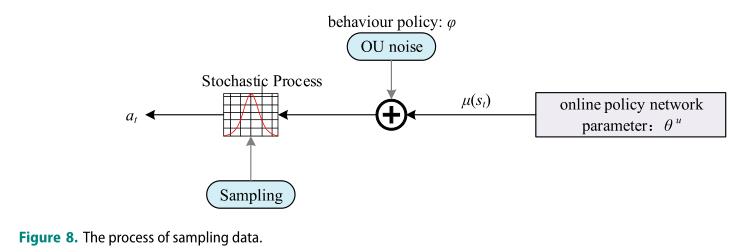
本文是离散的,这就需要行动空间的离散化。Gumbel-Softmax策略(Jang, Gu,和Poole2016)在终端环境中为离散的行为提供了可传递性,但也保持了动作空间的传递性。Gumbel-Softmax采样策略的具体过程如下:
(1)对于一个n维矢量多层感知器(MLP)输出,n个样本ε1,ε2,…,通过U(0,1)均匀分布产生;
(2)G是标准Gumbel分布的随机变量,计算公式为:G =−log(−log(εi));
(3)通过相应的+运算,得到一个新的值向量:
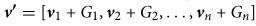
(4)通过Softmax函数计算概率得到最终的类别。
4.3 算法过程

以上是关于基于多智能体强化学习的自动化集装箱码头无冲突AGV路径规划的主要内容,如果未能解决你的问题,请参考以下文章