Linux系统虚拟化模型及障碍
Posted 宋宝华
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux系统虚拟化模型及障碍相关的知识,希望对你有一定的参考价值。
作者简介
王柏生 资深技术专家,先后就职于中科院软件所、红旗Linux和百度,现任百度主任架构师。在操作系统、虚拟化技术、分布式系统、云计算、自动驾驶等相关领域耕耘多年,有着丰富的实践经验。著有畅销书《深度探索Linux操作系统》(2013年出版)。
谢广军 计算机专业博士,毕业于南开大学计算机系。资深技术专家,多年的IT行业工作经验。现担任百度智能云副总经理,负责云计算相关产品的研发。多年来一直从事操作系统、虚拟化技术、分布式系统、大数据、云计算等相关领域的研发工作,实践经验丰富。
本文内容节选自《深度探索Linux虚拟化技术》,已获得机械工业出版社华章公司授权。
x86架构CPU虚拟化
Gerald J. Popek和Robert P. Goldberg在1974年发表的论文“Formal Requirements for Virtualizable[A1] [A2] Third Generation Architectures”中提出了符合虚拟化的3个条件:
(1)等价性,即VMM需要在宿主机上为虚拟机模拟出一个本质上与物理机一致的环境。虚拟机在这个环境上运行与其在物理机上运行别无二致,除了可能因为资源竞争或者VMM的干预导致在虚拟环境中表现上略有差异,比如虚拟机的I/O、网络等因宿主机的限速或者多个虚拟机共享资源,导致速度可能要比独占物理机的慢一些。
(2)高效性,即虚拟机指令执行的性能与其在物理机上运行相比并无明显损耗。该标准要求虚拟机中的绝大部分指令无须VMM干预而直接运行在物理CPU上,比如我们在x86架构上通过Qemu运行的ARM系统并不是虚拟化,而是仿真(Emulator)。
(3)资源控制,即VMM完全控制系统资源。由VMM控制协调宿主机资源给各个虚拟机,而不能由虚拟机控制了宿主机的资源。
陷入和模拟模型
为了满足GeraldJ. Popek和Robert P. Goldberg提出的满足虚拟化的3个条件,一个典型的解决方案是Trap andEmulate模型。
一般来说,处理器可以归结为两种运行模式:系统模式和用户模式。相应的,CPU的指令也分为特权指令和非特权指令。特权指令只能在系统模式运行,如果特权指令运行在用户模式就将触发处理器异常。操作系统将内核运行在系统模式,因为内核需要管理系统资源,需要运行特权指令,而普通的用户程序则运行在用户模式。
在虚拟化场景下,虚拟机的用户程序仍然运行在用户模式,但是虚拟机的内核将运行在用户模式,这种方式称为Ring Compression。在这种方式下,虚拟机中的非特权指令直接运行在处理器上,满足了Popek和Goldberg提出的虚拟化标准中高效的要求,即指令的大部分无须VMM干预直接在处理器上运行。但是,当虚拟机执行特权指令时,因为是在用户模式执行特权指令,将触发处理器异常,从而陷入到VMM中,由VMM代理虚拟机完成系统资源的访问,即所谓的模拟(emulate)。如此,又满足了Popek和Goldberg提出的虚拟化标准中VMM控制系统资源的要求,虚拟机将不会因为可以直接运行特权指令而修改宿主机的资源,从而破坏宿主机的环境。
x86架构虚拟化的障碍
Gerald J. Popek和Robert P. Goldberg指出,修改系统资源的,或者在不同模式下行为有不同表现的,都属于敏感指令。在虚拟化场景下,VMM需要监测到这些敏感指令。一个支持虚拟化的体系架构的敏感指令都属于特权指令,即在非特权级别执行这些敏感指令时,CPU会抛出异常,进入VMM的异常处理函数,从而实现了控制VM访问敏感资源的目的。
但是,x86架构恰恰不能满足Gerald J. Popek和Robert P. Goldberg定义的这个准则,且并不是所有的敏感指令都是特权指令,有些敏感指令在非特权模式下执行时并不会抛出异常,此时VMM就无法拦截或者处理VM的行为。以修改FLAGS寄存器中的IF(interrupt flag)为例,我们首先使用指令pushfd将寄存器FLAGS的内容压到栈中,然后将栈顶的IF清0,最后使用popf指令从栈中恢复FLAGS寄存器。如果将虚拟机内核运行在ring 1,x86的CPU并不会抛出异常,而只是默默地忽略指令popfd,因此虚拟机关闭IF的目的并没有生效。
有人提出半虚拟化的方式,即修改Guest的代码,但是这不符合虚拟化的透明准则。后来,人们提出了二进制翻译的方式,包括静态翻译和动态翻译。静态翻译就是在运行前,扫描整个可执行文件,对敏感指令进行翻译,重新形成一个新的文件。静态翻译是有其局限性的,必须提前处理,而且有些指令只有在运行时才产生的副作用,无法静态处理。于是,动态翻译应运而生,即在运行时以代码块为单元动态地修改二进制代码。动态翻译在很多VMM中得到应用,而且优化的效果非常不错。
VMX扩展
虽然程序员们从软件层面采用了多种方案去解决x86架构在虚拟化方面的问题,但是软件层的解决方案除了额外的开销外,也给VMM的实现带来了巨大的复杂性。于是,Intel尝试从硬件层面解决这个问题。Intel并没有将那些非特权的敏感指令修改为特权指令,因为并不是所有的特权指令都需要Trap and Emulate。我们举个典型的例子,每当操作系统内核切换进程时,都会切换cr3寄存器,使其指向当前运行进程的页表。当使用影子页表进行GVA到HPA的映射时,需要捕获Guest的每一次设置cr3寄存器的操作,VMM模块使其指向影子页表。而当启用了硬件层面的EPT支持后,cr3仍然指向Guest的进程页表,无须捕捉Guest设置cr3寄存器的操作,也就是说,虽然写cr3寄存器是特权指令,但是其不需要陷入VMM。
Intel开发了VT技术支持虚拟化,为CPU增加了Virtual-Machine Extensions,简称为VMX。一旦启动了CPU的VMX支持,CPU将提供2种运行模式:VMX Root Mode和VMX non-Root Mode,每一种模式都支持ring0 ~ ring3。VMM运行在VMX RootMode,除了支持VMX外,VMX Root Mode和普通的模式并无本质区别。VM运行在VMX non-Root Mode,Guest无须再采用Ring Compression方式,Guest kernel可以直接运行在VMX non-Root Mode的ring0,如图1所示。
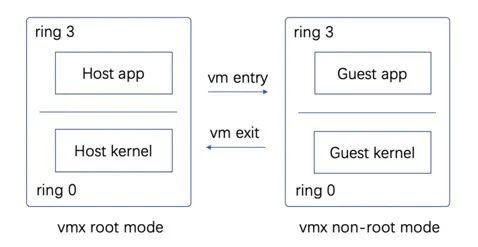
图1 VMX运行模式
处在VMX RootMode的VMM可以通过执行CPU提供的虚拟化指令VMLaunch切换到VMX non-Root Mode,因为这个过程相当于进入Guest[3] ,所以通常也被称为VM entry。当Guest内部执行了敏感指令,比如某些I/O操作后,将触发CPU发生陷入的动作,从VMX non-Root Mode切换回VMX Root Mode,这个过程相当于退出VM,所以也称为VM exit。然后VMM将对Guest 的操作进行模拟。相比于Ring Compression方式,即将Guest的内核也运行在用户模式(ring 1 ~ ring 3)的方式,支持VMX扩展的CPU[4] :
(1)运行于Guest模式时,Guest用户空间的系统调用直接陷入Guest模式的内核空间,而不是再陷入到Host模式的内核空间。
(2)对于外部中断,因为需要让VMM控制系统的资源,所以处于Guest模式的CPU收到外部中断,则触发CPU从Guest模式退出到Host模式,由Host内核处理外部中断。处理完中断后,再重新切入Guest模式。为了提高I/O效率,Intel支持外设透传模式,在这种模式下,Guest可以不必产生VM exit,“设备虚拟化”一章将讨论这种特殊方式。
(3)不再是所有的特权指令都会导致处于Guest模式的CPU发生VM exit,仅当运行敏感指令时才会导致CPU从Guest模式陷入Host模式,因为有的特权指令并不需要由VMM介入处理。
如同一个CPU可以分时运行多个任务一样,每个任务有自己的上下文,由调度器在调度时切换上下文,从而实现同一个CPU同时运行多个任务。在VMX扩展下,同一个物理CPU“一人分饰多角”,分时运行着Host及Guest,在不同模式间按需切换,因此,不同模式也需要保存自己的上下文。为此,VMX设计了一个保存上下文的数据结构:VMCS。每一个Guest都有一个VMCS实例,当物理CPU加载了不同的VMCS时,将运行不同的Guest,,如图2所示。
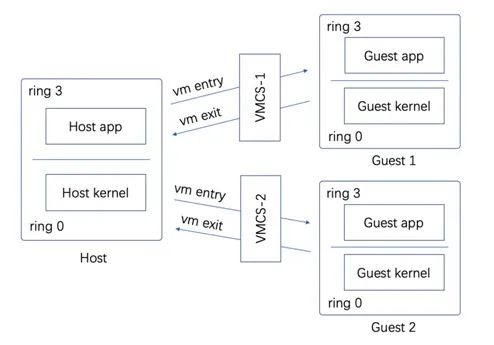
图2 多个Guest切换
VMCS中主要保存着两大类数据,一类是状态,包括Host的和Guest的,另外一类是控制Guest运行时的行为。
(1)Guest-state area,保存虚拟机状态的区域。当发生VM exit时,Guest的态保存在这个区域;当VM entry时,这些状态将被装载到CPU中。这些都是硬件层面的自动行为,VMM无须编码干预。
(2)Host-state area,保存宿主机状态的区域。当发生VM exit时,CPU自动从VMCS装载这些状态到物理CPU;当VM entry时,CPU自动将状态保存到这个区域。
(3)VM-exit information fields。当虚拟机发生VM exit时,VMM需要知道导致VM exit的原因,然后才能对症下药,进行相应的模拟操作。为此,CPU会自动将Guest退出的原因保存在这个区域,供VMM使用。
(4)VM-execution control fields。这个区域中的各种字段控制着虚拟机运行时的一些行为,比如设置Guest运行时访问cr3时是否触发VM exit;控制VM entry与exit时的行为的VM-entry control fields和VM-exitcontrol fields。我们不再一一列出细节,读者如有需要可以查阅Intel手册。
在创建VCPU时,KVM模块将为每个VCPU申请一个VMCS,每次CPU准备切入Guest模式时,将设置其VMCS指针指向即将切入的Guest对应的VMCS实例:
commit 6aa8b732ca01c3d7a54e93f4d701b8aabbe60fb7
[PATCH] kvm: userspace interface
linux.git/drivers/kvm/vmx.c
static struct kvm_vcpu *vmx_vcpu_load(structkvm_vcpu *vcpu)
u64phys_addr = __pa(vcpu->vmcs);
int cpu;
cpu =get_cpu();
…
if(per_cpu(current_vmcs, cpu) != vcpu->vmcs)
…
per_cpu(current_vmcs, cpu) = vcpu->vmcs;
asmvolatile (ASM_VMX_VMPTRLD_RAX "; setna %0"
: "=g"(error) : "a"(&phys_addr),"m"(phys_addr)
: "cc");
…
…
并不是所有的状态都由CPU自动保存与恢复,我们还需要考虑效率。以cr2寄存器为例,大多数时候,从Guest退出到Host再次进入Guest期间,Host并不会改变cr2寄存器的值,而且写cr2的开销不小,如果每次VM entry都更新一次cr2,除了浪费CPU指令周期,毫无意义。因此,将这些状态交给VMM由软件自行控制更合适。
VCPU生命周期
对于每个虚拟处理器(VCPU),VMM使用一个线程代表VCPU这个实体。在Guest运转过程中,每个VCPU基本都在如图1-3所示的状态中不断地转换。
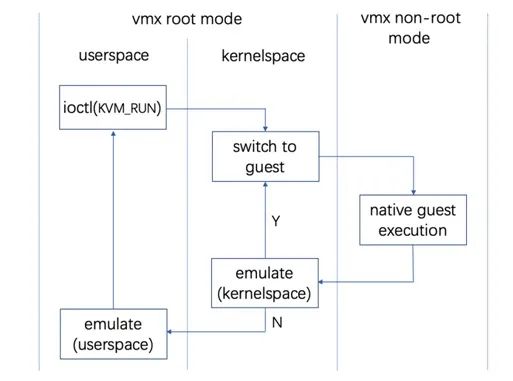
图3 VCPU生命周期
在用户空间准备好后,VCPU所在线程向内核中KVM模块向发起一个ioctl请求KVM_RUN,告知内核中的KVM模块,用户空间的操作已经完成,可以切入Guest模式运行Guest了。
在进入内核态后,KVM模块将调用CPU提供的虚拟化指令切入Guest模式。如果是首次运行Guest,则使用VMLaunch指令,否则使用VMResume指令。在这个切换过程中,首先,CPU的状态,也就是Host的状态,将会被保存到VMCS中存储Host状态的区域,非CPU自动保存的状态由KVM自行保存。然后,加载存储在VMCS中的Guest的状态到物理CPU,非CPU自动恢复的状态则由KVM自行恢复。
物理CPU切入Guest模式,运行Guest指令。当执行Guest指令遇到敏感指令时,CPU将从Guest模式切回到Host模式的ring0,进入Host内核的KVM模块。在这个切换过程中,首先,CPU的状态,也就是Guest的状态,将会被保存到VMCS中存储Guest状态的区域,然后,加载存储在VMCS中的Host的状态到物理CPU。同样的,非CPU自动保存的状态,由KVM模块自行保存。
处于内核态的KVM模块从VMCS中读取虚拟机退出原因,尝试在内核中处理。如果内核中可以处理,那么虚拟机就不必再切换到Host模式的用户态了,处理完后,直接快速切回Guest。这种退出也称为轻量级虚拟机退出。
如果内核态的KVM模块不能处理虚拟机退出,那么VCPU将再进行一次上下文切换,从Host的内核态切换到Host的用户态,由VMM的用户空间部分进行处理。VMM用户空间处理完毕后,再次发起切入Guest模式的指令。在整个虚拟机运行过程中,这个过程循环往复。
下面是内核空间切入、切出Guest的代码:
commit 6aa8b732ca01c3d7a54e93f4d701b8aabbe60fb7
[PATCH] kvm: userspace interface
linux.git/drivers/kvm/vmx.c
static int vmx_vcpu_run(struct kvm_vcpu *vcpu, …)
u8 fail;
u16fs_sel, gs_sel, ldt_sel;
intfs_gs_ldt_reload_needed;
again:
…
/*Enter guest mode */
"jne launched \\n\\t"
ASM_VMX_VMLAUNCH "\\n\\t"
"jmp kvm_vmx_return \\n\\t"
"launched: " ASM_VMX_VMRESUME "\\n\\t"
".globl kvm_vmx_return \\n\\t"
"kvm_vmx_return: "
/*Save guest registers, load host registers, keep flags */
…
if(kvm_handle_exit(kvm_run, vcpu))
…
goto again;
return 0;
在从Guest退出时,KVM模块首先调用函数kvm_handle_exit尝试在内核空间处理Guest退出。函数kvm_handle_exit有个约定,如果在内核空间可以成功处理虚拟机退出,或者是因为其他干扰比如外部中断导致虚拟机退出等无须切换到Host的用户空间,则返回1;否则返回0,表示需要求助KVM的用户空间部分处理虚拟机退出,比如需要KVM用户空间的模拟设备处理外设请求。
如果内核空间成功处理了虚拟机的退出,则函数kvm_handle_exit返回1,我们看到上述代码直接跳转到标签again处,然后程序流程会再次切入Guest。这种虚拟机退出被称为轻量级虚拟机退出。如果函数kvm_handle_exit返回0,则函数vmx_vcpu_run结束执行,CPU从内核空间返回到用户空间,以kvmtool为例,其相关代码片段如下:
commit 8d20223edc81c6b199842b36fcd5b0aa1b8d3456
Dump KVM_EXIT_IO details
kvmtool.git/kvm.c
int main(int argc, char *argv[])
…
for (;;)
kvm__run(kvm);
switch (kvm->kvm_run->exit_reason)
caseKVM_EXIT_IO:
…
…
根据代码可见,kvmtool发起进入Guest的代码处于一个无限的for循环中。当从KVM内核空间返回用户空间后,kvmtool在用户空间处理Guest的请求,比如调用模拟设备处理I/O请求。在处理完Guest的请求后,重新进入下一轮for循环,kvmtool再次请求KVM模块切入Guest。
以上是关于Linux系统虚拟化模型及障碍的主要内容,如果未能解决你的问题,请参考以下文章