两条华子也换不来的数据湖讲解
Posted 敏叔V587
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了两条华子也换不来的数据湖讲解相关的知识,希望对你有一定的参考价值。
前言
数据湖一词进入我的视野是两年前,我记得当时是我们老板给做了DataBricks的技术分享报告,那个时候其实是介绍Spark的一些新特性,然后顺便介绍了数据湖。在此期间,数据湖技术也由一开始的想法、落地、迭代,各大企业纷纷推出自己的基于湖仓技术的解决方案,可以说是全面开花。正如十多年前了解到hadoop那样,大数据技术的发展可谓迅猛,所以我们也是要不断更新自己的知识体系,今天我们来侃一侃数据湖的巴拉巴拉。
数仓的现状
一谈到大数据的历史,我们都熟知的Google引爆大数据时代的三篇论文Google FS、MapReduce、BigTable,随后社区出了开源版本的Hadoop、Hive,事实上,我们在不同的时期解决的问题其实是不一样的。
hadoop为我们海量数据的存储和计算提供了底层的能力,而hive则可以把我们的SQL解析成MR程序,使得用大数据处理数据的用户得到火速增长。随着数据体量的进一步扩大,企业对大数据处理人员也开始出现了进一步的分工,出现了以业务运营指标体系建设的BI人员,也有以数据建模作为工作目标的数仓建模人员,还有一部分以机器学习算法为核心目标的算法工程师,当下,我们的数据分工基本是这个状态。
数仓的发展其实是大数据史上的一个里程碑级别的阶段,数仓本身不是新的技术,业界主要是从传统的DBMS数据处理模式转变到使用大数据技术处理的方式,自从有了数仓,数据的模型便有了分层次的规范,也有了强类型的约束,并且会有不同层层度的治理保障和安全约束,数据的价值进一步挖掘出来。
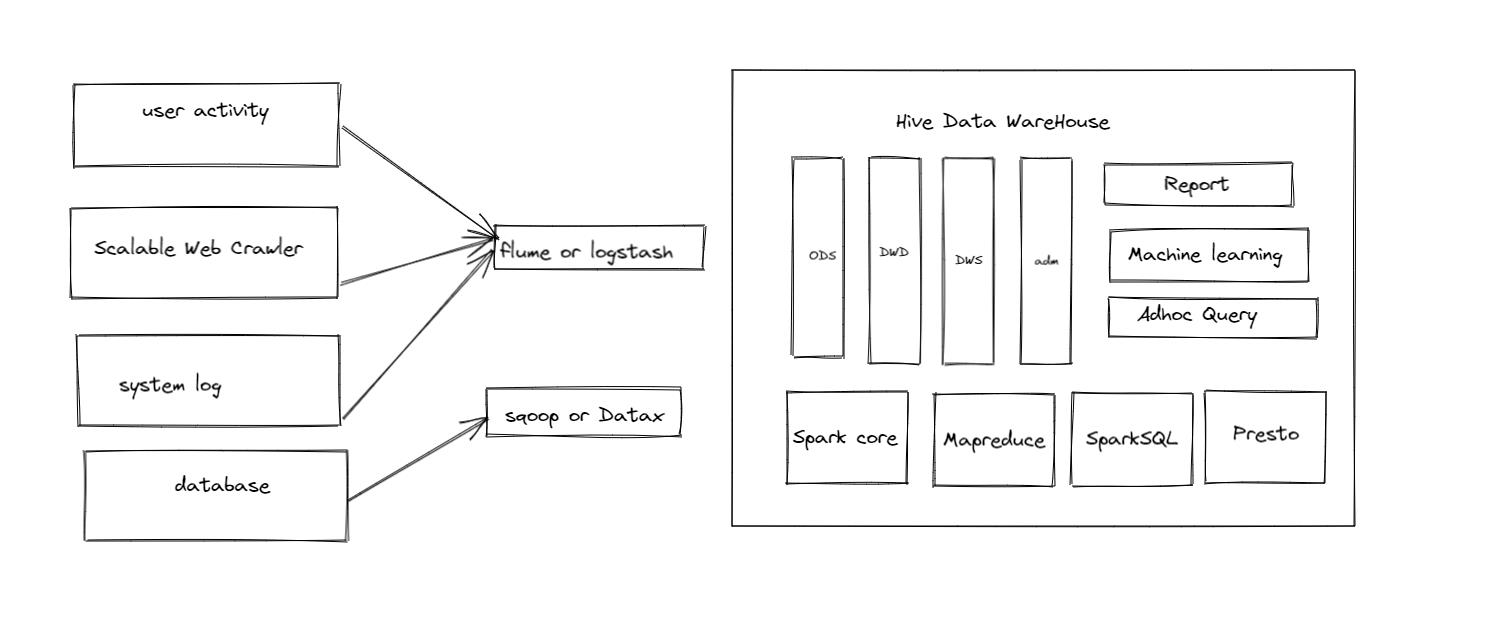
数仓时代的架构如图,数仓解决了几大问题:
1、数据孤岛问题
2、数据类型约束
3、数据质量保证
4、数据的规范建模
其中孤岛问题打通了企业内部的数据信息,数据的模型统一则是扩大了数据的使用场景,更加广泛地支持营销,运营,甚至一些账务场景。
数仓的问题
数仓的优点则是使得企业使用数仓技术建模出现了一时的数据繁荣,即便如此,我们碰到了一系列的问题,这也是数据湖出现的动因。
数仓是建立在Hive元数据体系下的,即使是SparkSQL、Presto这种也只是做计算引擎,元数据的还是使用hive metastore,这样我们有以下困难:
底层结构本身带来的操作困难
1、我们只能增加字段,很难去下线一个字段,比较坑的事情是,真要干掉字段需要把表干掉,风险非常高。
2、MR/Spark模型下的数据更新,底层实现其实是把整个表是数据重新生成一遍,再覆盖掉历史数据,这种做法带来的成本非常高,还很笨拙
3、没有所谓的事务性保障、这在传统db里面很成熟的一致性解决方案
4、没有索引,查询基本靠全量扫
机器学习场景使用很笨拙
我们看传统机器学习场景的一般流程:
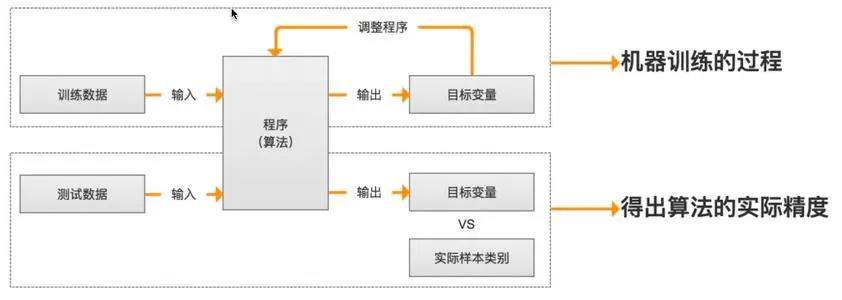
这个是使用scikit-learn 幸存者预测的小简单看一下我们代码:
def decision():
"""
决策树
:return:
"""
titan=pd.read_csv("./data/titanic.txt")
print("数据集中0的个数:",titan[titan.survived==0].count())
print("数据集中1的个数:", titan[titan.survived==1].count())
x=titan[['pclass','age','sex']]
y=titan['survived']
print(x)
##缺失值处理,补足年龄为平均年龄
x['age'].fillna(x['age'].mean(),inplace=True)
#分割数据集到训练集合测试集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.25)
print(y_train)
我们输入的数据实际是下面那个样子的
"row.names","pclass","survived","name","age","embarked","home.dest","room","ticket","boat","sex"
"1","1st",1,"Allen, Miss Elisabeth Walton",29.0000,"Southampton","St Louis, MO","B-5","24160 L221","2","female"
"2","1st",0,"Allison, Miss Helen Loraine", 2.0000,"Southampton","Montreal, PQ / Chesterville, ON","C26","","","female"
"3","1st",0,"Allison, Mr Hudson Joshua Creighton",30.0000,"Southampton","Montreal, PQ / Chesterville, ON","C26","","(135)","male"
"4","1st",0,"Allison, Mrs Hudson J.C. (Bessie Waldo Daniels)",25.0000,"Southampton","Montreal, PQ / Chesterville, ON","C26","","","female"
"5","1st",1,"Allison, Master Hudson Trevor", 0.9167,"Southampton","Montreal, PQ / Chesterville, ON","C22","","11","male"
"6","1st",1,"Anderson, Mr Harry",47.0000,"Southampton","New York, NY","E-12","","3","male"
在实践过程中,我们发现做机器学习的时候和数仓上有比较大的矛盾
1、字段高频寻找特征场景几乎不支持
以我们最直接的决策树模型来说,实际的场景中其实是不断去尝试寻找有利特征和剔除无效特征的过程,在这种背景下,我们其实经常是不断要有字段和换一个字段,而且中间有些特征简单加工,这种时候要数仓人员做十有八九奔溃了。
2、没有存储非结构化的数据
在机器学习的场景中,例如文本的识别,语音,视频或者一些半结构化的JSON,XML 使用hive也是很困难的一件事情,而且大部分场景就是原始数据提取特征再进行加工
3、没得原始数据,所以在提炼过程中会剔除掉一些内容,或者做一些加工,这样的数据我们去做模型训练会带来模型预测的结果和实际的生产产生很大的误差,这种事情对做算法的同学可是接受不了的。
流批开发长周期
当下最流行的流批一体开发模式是基于Lambda 架构的,这种模式其实需要同时进行离线和实时的单独开发,由于数据的开发模式,引入了新的架构复杂度。这种时候即使是一模一样的数据,也是搞两套。
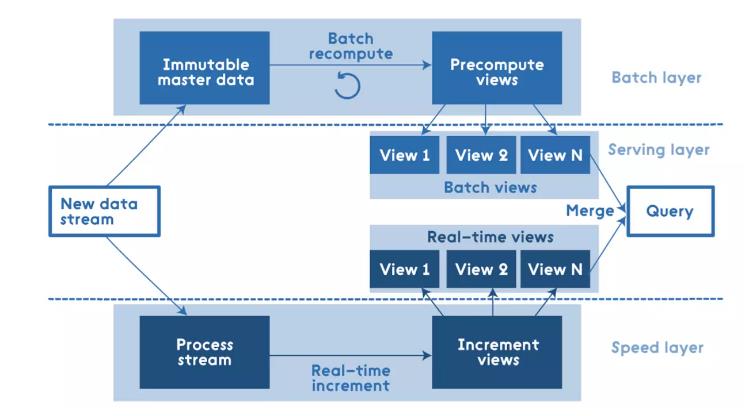
对数据使用场景的一些美好的愿望
在人类声势浩大的对这个世界进行改造的时候,心中有梦便是最原始的动力了,我们其实对数据使用会有一些美好的想象,我们按照要是可以XX,就可以怎样我们罗列一下。
首先是数仓同学的好梦:
1、要是数仓可以像数据库一样,直接update或者delete话,我们也不至于刷一笔数据搞几个小时了
2、要是我们离线数据可以很快写入,那么也不用实时和离线各自搞一套了
3、要是可以支持事务,我们数据不就可以接在线系统了嘛
4、我不喜欢那么折腾的不断去加字段减字段、那该多好
5、要是可以回滚历史版本多好,想用老的新的我都有
然后是算法同学的好梦:
1、我其实有时候也就是直接传递字段下来就好了,我直接用最原始的数据就好
2、我其实字段是不断变来变去的,数据可以在我使用的时候定义出列名就行的,或者不定义其实都可以
3、我其实搞图片,文档输入也是很多的,现在表是没办法支持的,还得直接从底层文件搞
…
当然其次就是基本的问题:
成本低,性能好
基于那么多问题,实际上是我们大数据行业发展到本身的瓶颈,带来最直接的问题就是人力成本高,效率差,我们期望是有更加优雅的方式解决问题,这个便是办法。
数据湖的引入
首先一点说明,数据湖其实是一种设计的理念,所以不管是历史的产品,或者新的产品,基于这类理念设计的我们都叫做数据湖产品。数据湖最核心的目标是敏捷,基于上诉背景,对数据湖主要有以下特性:
1、能够存储海量的原始数据
2、能够支持任意的数据格式
3、有较好的分析和处理能力
当我们系统做到了这个地步的时候,我们就叫做数据湖了。数据湖是一个很形象的比喻:把我们的数据
数据相当于我们的水,任意格式的数据就相当于我们的河流了,它们都可汇聚到一个湖泊里面,这就对应我们的集中存储了,我们可以用湖里面的各种水进行使用,则就可以产生价值 这就对应我们基于湖的数据分析。当然,如果这一坨那一坨,这种就叫做数据沼泽了,这也是数据ugly设计的结果了。
数据湖目标
我们说数仓是为了整合数据,解决数据孤岛问题,到了数据湖的时代,则是把数据沼泽改造成良性流动的数据有用资产的目标,delta官网的图很清晰表达把数据逐步从青铜变成黄金的目标。
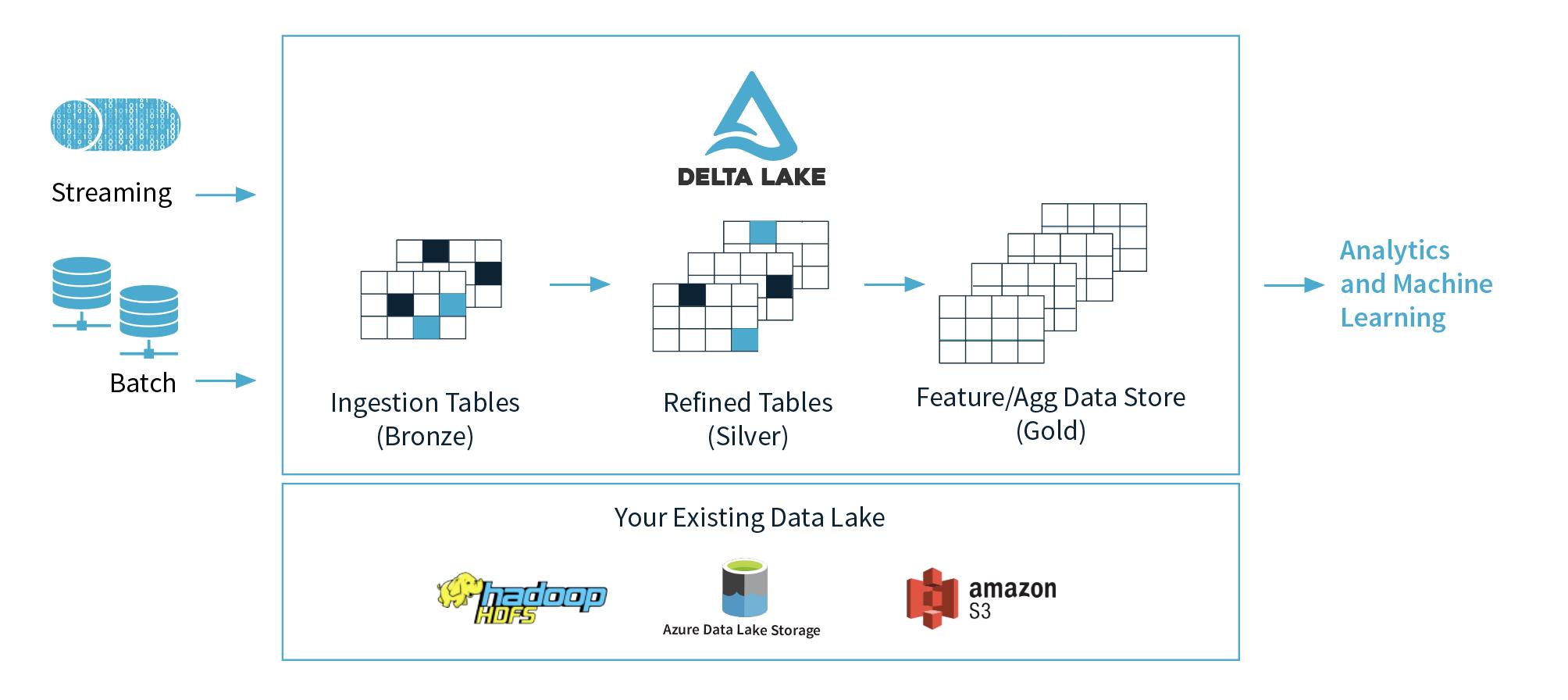
当然,更近一步的目标来说,也是期望解决企业业务复杂数据量大的时候的效率问题,至于技术人员的角度来说,就是希望有优雅的链路设计,高效的处理模式。
数据湖时代
我记得多年前学Java的时候就是一堆什么Spring、Struct、Hibernate要学,后面又有JPA和SpringMVC啥的,这个圈就是个卷。大数据下面好不容易把hadoop flink spark啥的搞了一圈之后,数据湖的出现,又得去倒腾数据湖的产品了,开源界三大数据湖产品便是Delta Lake、Iceberg 和 Hudi 了。当然对于我们学习来讲,我们不用去特定比较一定要哪个,年轻人来说,我们三个都要。实际情况来说,当下的产品还不是完全取代原有的离线计算体系的状态,比较大的公司自己拿开源去改造,或者就直接自己开发,小一点的公司也是在特定的业务场景中引入,所以按照开源社区的一贯作风,后续的各家产品功能不断会互补的。
Delta Lake特性分析
我们看看Delta Lake有哪些特性:官网地址

1、Spark 上的 ACID 事务:可序列化的隔离级别确保读者永远不会看到不一致的数据。
2、可扩展的元数据处理:利用 Spark 分布式处理能力轻松处理 PB 级表的所有元数据,其中包含数十亿个文件。
3、流批一体:Delta Lake 中的表是批处理表,也是流式源和接收器。流数据摄取、批量历史回填、交互式查询都是开箱即用的。
4、Schema 约束:自动处理Schame变化以防止在摄取期间插入不良记录。
5、时间旅行:数据版本控制支持回滚、完整的历史审计跟踪和可重复的机器学习实验。
6、Upserts 和 deletes:支持合并、更新和删除操作,以支持复杂的用例,如更改数据捕获、缓慢变化维度 (SCD) 操作、流式更新插入等。
Hudi特性分析
再看看hudi的,官网

1、使用快速、可插入索引进行更新、删除
2、事务、回滚、并发控制
3、自动文件大小调整、数据聚类、压缩、清理
4、自动调整文件大小、数据集群、压缩、清理。内置元数据跟踪可扩展存储访问
5、增量查询、记录级变更流
6、从Spark, Presto, Trino, Hive 等用SQL 读/写
7、流摄取、内置 CDC 源和工具
8、向后兼容的模式演变和执行
我们看到数据湖其实就是一个对数据模式改造过程,基于我们实际的诉求
数据湖带来的变化
数据湖与数据仓库相比 – 两种不同的方法
引用亚马逊官网给出的对比:连接
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据 | 来自事务系统、运营数据库和业务线应用程序的关系数据 | 来自 IoT 设备、网站、移动应用程序、社交媒体和企业应用程序的非关系和关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 分析 | 机器学习、预测分析、数据发现和分析 |
ETL方式的变化
1、离线TB级的作业数据有问题,要修复数据,只需要delete或者update一下就可以了
2、数据增加字段问题,数据可以躺在那,需要的时候自己给schema
3、流批一体的环境构建数仓,链路变的简化了,核心思想就是我们使用统一的Delta Lake来做数据的中转。
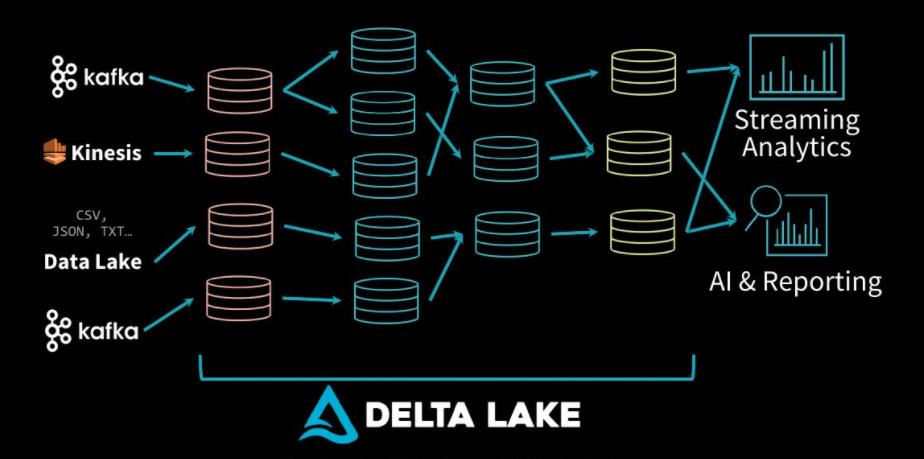
一些后话
可以回答一下之前小粉们的疑问,简单总结一下:
1、数据湖其实改造的是底层的数据存储方式和构建方式的,面向我们当下实时计算、机器学习、以及数仓的模型约束数据质量上可以很大程度的解决掉痛点。
2、数据湖和数仓的关系,其实是一种相互补充的关系,生产落地的场景数据湖会作为上游存在的,数仓变成规范的ETL会把数据湖作为数据源去走etl链路,可以说数仓的地位并不是直接替代的关系
3、数据湖并没有解决大规模的shuffle带来的资源消耗的,所以需要join的话还是得join
理解数据湖我经过了比较长的一段时间,主要原因是一开始delta lake出来的时候企业版才有比较多的功能,再后续其实是搁置了。落地的情况来说,我发现使用下来性能上还是很大差异,没有大规模投产,因为底层需要去实现多版本数据的时候其实带来了大量小文件,这个在传统的HDFS方式下其实是受不的,后续有一系列的迭代,这也是为什么有一些快速合并小文件的特性了,企业级的数据湖产品例如OSS,底层其实已经做了比较大的改造的。另一方面来说,这样子的话,就业岗位就又多了一个工种了哈~~
我也有自己的公众号,喜欢相互学习的

以上是关于两条华子也换不来的数据湖讲解的主要内容,如果未能解决你的问题,请参考以下文章