从零开始的python生活①手撕爬虫扒一扒力扣的用户刷题数据
Posted XingleiGao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始的python生活①手撕爬虫扒一扒力扣的用户刷题数据相关的知识,希望对你有一定的参考价值。
☘前言☘
读完这篇博客,你可以学到什么?
- python的基础语法(适合c转python)
- excel的读取和写入方式
- 基本的爬虫定位方法
- python的安装(这个很容易的)
- 基本的环境配置(这个基本上不用配置)

这篇博客里,我将带领大家手撕第一个python的爬虫小程序,不用担心,都是从基础知识开始的。当你学完这篇博客就可以解放双手让python干费时费力的事情去吧!
全文大约阅读时间: 20min
🧑🏻作者简介:一个从工业设计改行学嵌入式的年轻人
✨联系方式:2201891280(QQ)
主要内容
一、必备的一些基础知识
python作为一个弱类型的语言,很多方面和c会有大的出入,在学习之前需要对这些基础语法有个基础了解。首先是python没有;哦,一个回车就代表一句结束
1. 创建变量
num = 10 #创建一个变量
ws = wb['Sheet1'] ##根据wb中的'Sheet'元素类型创建变量
是不是很简单?需要什么直接写名字赋值就好了0.0
2. 循环
for lie in df.index.values:
driver.get(lie)
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
wb.save(r'111.xlsx')#循环外的语句
这个和c有亿点点区别,python特别注意缩进,还是有助于改进一些人的代码习惯的,缩进打得好能大大提升代码的可读性。
这里就是遍历df.index.values中所有的元素,然后进行操作,只要是有一个缩进的都是for循环体内的语句!
只有最后一句不在循环体内。
3. 判断
if(len(submitTag) != 0):
break
else
continue
看完循环的话这个很好理解吧,一样的,都是相同缩进是一个循环或者判断体内的。
二、必备的一些库文件
python最伟大的地方就是有很多第三方库可以选择,有很多造好的轮子。我们只要使用就好了-.-
根据我们这次需要做的事情 我们引入了四个库文件
其中需要安装库文件的话可以在命令提示行下面的命令。其中xxx就是下面的标题名字
pip intsall xxx #一般这个就行
pip3 intsall xxx #不行试试这个
time
这个库顾名思义就是和时间相关的。我们需要的只是做个延时,所以我们只需要他的一点点功能。先导入功能
from time import sleep
这就是最常见的导入方式 ,我们只需要sleep就只导入功能就好了。
用法也很简单
sleep(3)
完事了?简单不。功能就是休息3s
pandas
Pandas 的主要数据结构是 Series (一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。
华丽呼哨的 咱也看不懂,反正我就用来打开excel的某一列。
老规矩,先导入
import pandas as pd
这次换个方式,我们把它导入,然后给他换个名字。(⊙o⊙)
用法也不难其实 . 有点借鉴c++,就是调用相应的方法。
df = pd.read_excel('111.xlsx',index_col='LeetCode地址')
这样我们就成功把名字叫做LeetCode地址的一列读进来了。
openpyxl
其实这个才是专门处理excel的,但是读入我用了pandas也不想改了。这个我用来保存读到的数据。
import openpyxl
这次我们不改名直接调用
用法也不难,我主要用下面的几个
wb=openpyxl.load_workbook(r'111.xlsx')#载入exlce数据
ws = wb['Sheet1'] #令ws为数据表1
ws.cell(row = i+1, column = num).value = distance#写入第i+1行第num行的值distance
wb.save(r'111.xlsx') #保存wb的更改
这样我们就完成修改对应的值并保存了。
selenium
这个是用来抓数据的 其实主要用来测试的,但是这次我们拿来用用
from selenium import webdriver
导入其中的webdriver方法 我们用到的主要是里面的方法
driver = webdriver.Chrome()#打开chrome浏览器
driver.get(lie)#打开对应的网址
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
上面的三句话分别对应我们打开浏览器,输入网址 找到数据。
注:这个需要安装selenium和chrome 具体可以参考这个Selenium安装教程
三、网站元素定位
对于元素定位这块会比较麻烦,我单独讲一讲
确定元素
首先要确定要找元素的特征
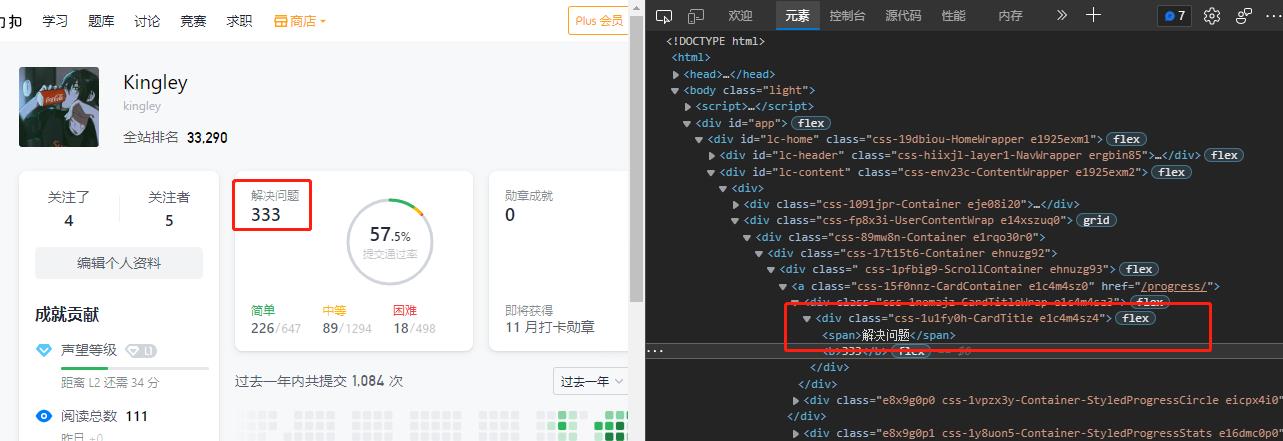
我这里就要扒一扒对应地址的解决问题数。我们可以按ctrl+shift+c 然后点对应的元素 就会像图上这样出现我要的元素位置。
然后我们很容易发现他是在解决问题的同级别的<b>标签下。
我们可以用相对位置来定位
//*[text()="解决问题"]
这个表示的是找到解决问题对应的标签
我们需要的数据其实是其同层级下的b标签的数据
那么就是
//*[text()="解决问题"]/../b
其中…表示上级目录 我们就可以定位到所要的数据了
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
distance = submitTag[0].text
最后就是拿到我们想要的数据 我们需要的数据格式是text
网络延迟
如果我们因为网络延迟或者访问量过大没有抓到数据怎么办呢?
我的想法就是休息3s再抓,如果重试5次还是抓不到那就下一个跳过
那我们怎么直到抓没抓到呢?
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
这句里面用的elements返回的是个列表,所以长度为0就是没找到
然后是等待重试语句
if(len(submitTag) == 0):
for k in range(1,5):
sleep(3)
driver.get(lie)
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
if(len(submitTag) != 0):
break
if(len(submitTag) == 0):
print("false")
i+=1
continue
看着很长。其实一点也不复杂,第一个for会进行五次重试,每次重试完如果拿到数据就跳出
如果5次循环结束还是拿不到,就让i+1其实就是跳过了这组数据啦。
五、最终成果
import pandas as pd
import openpyxl
from selenium import webdriver
from time import sleep
num = 10 #写入的数据列
driver = webdriver.Chrome()
df = pd.read_excel('111.xlsx',index_col='LeetCode地址')
#读取一整列的数据
wb=openpyxl.load_workbook(r'111.xlsx')
ws = wb['Sheet1']
i = 1
for lie in df.index.values:
driver.get(lie)
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
if(len(submitTag) == 0):
for k in range(1,5):
sleep(3)
driver.get(lie)
submitTag = driver.find_elements_by_xpath('//*[text()="解决问题"]/../b')
if(len(submitTag) != 0):
break
if(len(submitTag) == 0):
print("false")
i+=1
continue
distance = submitTag[0].text
ws.cell(row = i+1, column = num).value = distance
i=i+1
print(i)
wb.save(r'111.xlsx')
利用num保存写入列是为了以后能够方便修改 打印i是为了能看到进度
六、写在最后
当然这个只是第一次入门的小作品,其中没用封装成函数,也没有用到类对象什么的高级运用,但是可以作为一个语言的基础中的基础中的入门,如果大家喜欢这个系列还麻烦大家给个赞啥的。
如果赞超过100,楼主会尽快更新下一期
以上是关于从零开始的python生活①手撕爬虫扒一扒力扣的用户刷题数据的主要内容,如果未能解决你的问题,请参考以下文章