基于CarbonData的电信时空大数据探索
Posted 华为云开发者社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于CarbonData的电信时空大数据探索相关的知识,希望对你有一定的参考价值。
摘要:作为IOT最底层的无线通信网络生成大量与位置相关的数据,用于无线通信网络规划和优化,帮助电信运营商建设更好体验的精品网络,构建万物互联的信息社会。
本文分享自华为云社区《基于CarbonData的电信时空大数据探索》,作者: 张军、龚云骏 。
1使用场景
随着万物互联的时代到来,以及智慧终端普及,现实世界超过80%的数据与地理位置相关,比如日常使用的社交、支付、出行相关APP。作为IOT最底层的无线通信网络也会生成大量与位置相关的数据,用于无线通信网络规划和优化,帮助电信运营商建设更好体验的精品网络,构建万物互联的信息社会。
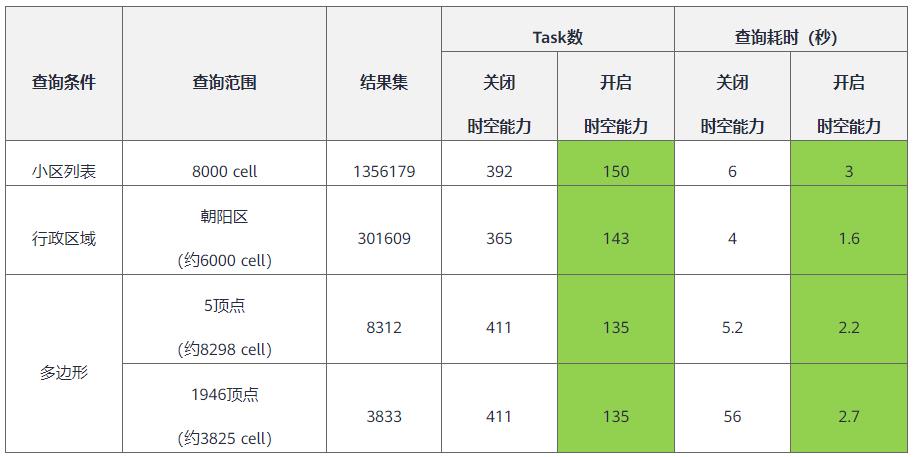
为表征无线网络相关指标在地理空间的分布情况,将地表按50*50米正方形网格进行切分,并按照网格累加统计指标,数据可以按时间(hour/day)、行政区(region ID)、无线小区(cell ID)、网格(网格中心经纬度坐标)进行管理。表结构如下:

比如,需要分析某CBD无线通信网络信号覆盖情况,使用CBD的边界作为查询条件,返回网格和业务KPI,对返回的网格经纬度和KPI进行可视化渲染,得到如下效果。
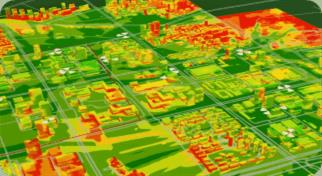
某CBD通信网络覆盖情况
2 技术挑战
查询性能:以2000万左右用户规模的无线通信网络为例:每秒约接入240万条事件,每天约产生14TB数据,数据保存若干天。基于行业常用数据仓库查询耗时在10-15秒左右,与用户体验2/5/8秒要求存在较大差距;同时单个查询占用资源较多,多用户并发分析时,查询性能明显下降,以5用户查询为例,查询耗时劣化为30-60秒;
线性扩展:随着数据中心“云化”演进,数据集中化存储和管理趋势明显,支持省级、国家级超大规模网络交付场景明显,急需体系化的方法解决海量数据治理的线性扩展问题。
考虑到业务数据是在时间和空间上持续增长,同时业务分析流程中,主要查询包括:行政区域/问题区域/无线小区簇查询。对数据查询特性进行分析:
1) 行政区域查询:行政区域查询返回结果是在空间上聚集的;
2) 问题区域查询:问题区域是指有网络问题的某个地表区域,查询返回结果集是在空间上聚集的;
3) 无线小区簇查询:无线网络的小区不是孤立存在的,一般把一定数量相邻的无线小区按小区簇进行管理,因此小区簇查询返回结果集是在空间上聚集的
综上,查询返回结果集都是在空间上聚集的,因此有必要考虑数据入库时,支持按空间坐标建立时空索引,提升查询过程中的数据过滤效率。
3 优化方案
3.1 时空索引算法
优化前使用如下方式设定表的Sort Column,数据先按纬度排序再按经度排序后,本来在空间相邻的经过排序后划分被切割为不相邻的条带。

条带化问题可以参考下图,行业内解决此问题的方法是引入空间排序方法,常用空间排序方式包括Z序和H序,最常用的方法是GeoHash。技术原理可以参考Halfrost的神作:高效的多维空间点索引算法。
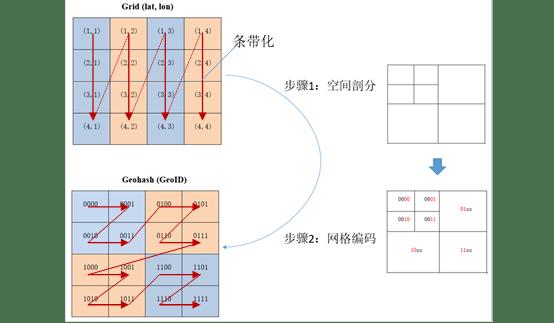
关于Z序和H序的优缺点行业有较多讨论。Z序曲线虽然有局部保序性,但是它也有突变性,在每个 Z 字母的拐角,都有可能出现顺序的突变。H序相比较Z序解决了拐角的突变问题,H序聚簇特性比Z序提升15%左右,但是生成复杂度却提升很多,动态维护的代价会更高些。另外,还有很多应用,需要不同维度实时分解的应用,H序拆分耗时会增加不少。综合考虑,当前使用简单易用的Z序编码:GeoSOT。
--建表SQL—
create table IF NOT EXISTS <table> ( timevalue bigint,
longitude bigint,
latitude bigint,
regionid bigint,
cellkey bigint,
kpi bigint,
kpi2 bigint,
kpi3 bigint)
STORED AS carbondata TBLPROPERTIES
('SPATIAL_INDEX'='geoid',
'SPATIAL_INDEX.geoid.type'='geosot',
'SPATIAL_INDEX.geoid.sourcecolumns'='longitude, latitude',
'SPATIAL_INDEX.geoid.level'='21',
'SPATIAL_INDEX.geoid.class'='org.apache.carbondata.geo.GeoSOTIndex',
'SPATIAL_INDEX.geoid.conversionRatio'='1000000',
'SORT_COLUMNS'='timevalue,geoid,regionid,cellkey');注:
1. 'SPATIAL_INDEX'='geoid':用于设置空间编码的字段名,当前表中字段名为geoid;
2. 'SPATIAL_INDEX.geoid.type'='geohash':用于设置空间编码的生成方法,当前设置为GeoSOT,考虑到行业内还存其他在多种网格编码系统,比如GeoHash、Google S2、Uber H3。CarbonData网格编码支持插件化能力,可以支持不同业务场景快速引入匹配的网格编码系统。;
3. 'SPATIAL_INDEX.geoid.sourcecolumns'='longitude, latitude':用于指定计算空间编码的参数字段,需要设置为经纬度对应的字段名称;
4. 'SPATIAL_INDEX.geoid.level'='21': 基于GeoSOT计算空间编码需要设置栅格等级,当前设置为21;
5. 'SPATIAL_INDEX.geoid.class'='org.apache.carbondata.geo.GeoSOTIndex':设置空间索引的实现方法,当前设置为GeoSOT的实现算法;
6. 'SPATIAL_INDEX.geoid.conversionRatio'='1000000':经纬度小数点后的位数可以确定栅格数据的精度,一般场景下栅格数据的精度是固定的,经纬度就是一个具有固定位数的小数,通过该参数来设置系统内的经纬度小数位数。
3.2 时空查询加速
在使用多边形作为查询条件时,简单的方法是提前多边形的外接矩形先进行粗过滤,再对查询结果进行精过滤。精过滤过程就是将每个粗过滤的查询记录与多边形进行关系判断,识别出在多边形内部的记录。
点和多变形的关系判断非常耗时,空间数据库的这类查询一般是将多边形转化为网格编码的线段集,如下图所示,浅蓝色为多边形过滤条件,可以将该多边形变换为有序的网格编码线段集11-15,20,22,36-37,48,将线段集作为数据库底层过滤条件,可以将复杂过滤方式转换为简单过滤方式,并复用CarbonData的高效过滤下推能力。
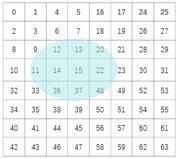
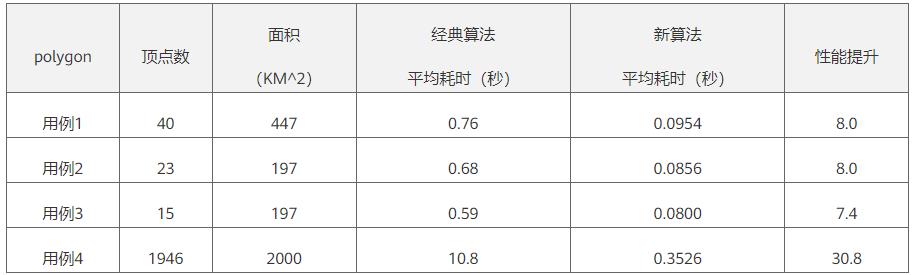
时空索引的关键点在于如何高效的将多边形转换位网格编码的线段集,通过对该流程分析,并与行业经典算法进行比较,探索出一种新算法解决该问题,相比较行业经典算法,新算法再剖分性能上有8倍的性能提升,在复杂多边形的处理上更具性能优势,并可将该优势拓展到支持多边形列表查询场景。
3.3 优化效果
基于CarbonData增加时空数仓能力,SQL查询资源开销为优化前的1/5, 其中SQL耗时提升1.5倍,并发能力提升3倍。
3.4 线性扩展
CarbonData在数据排序机制上比较灵活,除了提供global sort能力外,还支持local sort,该能力可以大幅提升数据入库性能,在实际的交付应用中,大多采用local sort方式。数据在空间位置上的分布是唯一的,在超大规模交付场景中,为保证查询性能不受影响,需要考虑如何避免同一入库批次内的相同位置数据分散到不同的入库节点。短期可以基于“分区”和“分桶”机制进行相关实践,长期看需要考虑时空密度和时空潮汐,制定配套的时空负载均衡策略,相关研究已经启动,并取得初步成效。
3.5 插件化
时空能力是基于插件化的模式进行开发,整个插件包主要包括两个部分:
1、 对空间数据经纬度到空间网格编码的转换以及各种基于网格编码进行空间分析的算法实现,目前基于GeoSOT算法,后续随着算法的演进可以独立进行迭代更新;
2、 基于CarbonData提供的索引接口,只需要在安装部署时作为外带Library加载到运行环境,创建数据表时指定插件包内支持的空间索引类型以及算法即可使用。
基于插件化的能力,CarbonData原有的多维查询能力不受影响,通过对业务数据和查询特征进行充分识别,制定合理的sort column定义,在综合查询性能上应该会有较大收益。同时时空能力可以独立于CarbonData进行算法演进,并支持对于其他场景的接口扩充。
4 应用场景举例
人的日常活动离不开道路和楼宇两大类场景。实际业务分析过程中,除了对某个区域的地表进行整体分析外,还涉及道路和楼宇两类高价值场景的应用进行讲解。
4.1 道路分析
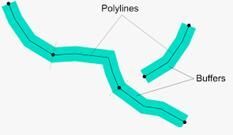
示例1:重点道路分析场景
--SQL示例1—
select longitude, latitude, kpi
from <table>
where in_polyline_list('LINESTRING (100.785924 4.464369,100.785924 4.446571)' , 1000);使用 SQL 语句对这些线路辐射范围内的数据进行过滤、汇总分析,获取网络体验相关的kpi指标,提供直接支持制图、制表的道路、地铁、高铁网络性能分析数据。SQL语法细节可以参考Carbon社区接口说明文档。
对返回的道路经纬度和KPI进行渲染,得到如下效果:
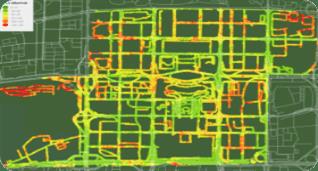
初步验证,polyline总长度为50公里,缓存区为1000米,查询返回记录数为25832条,SQL执行耗时为3.6秒。
4.1 楼宇分析
楼宇相关场景分析,一般分为2D楼宇分析和3D楼宇分析。2D楼宇分析时,建筑物一般用Polygon对象表达,因此需要SQL语句上支持Polygon对象查询相关操作。业务表里面包含经纬度字段和通信网络相关指标,空间维表包含建筑物类型、建筑物轮廓(Polygon对象)、建筑统一编号。3D楼宇分析时,需要增加楼宇高度信息。
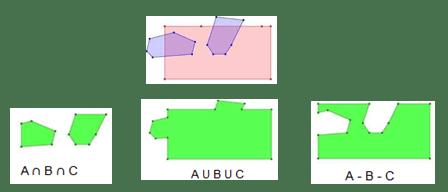
按建筑物列表进行业务分析时,一般需要支持对多边形取并(OR)的操作。除此外,可能会出现“回”字形建筑。因此需要提供多样化的多边形关系的操作方法,SQL语法细节可以参考Carbon社区接口说明文档。
示例2:2D楼宇分析场景
查询某城市所有学校建筑的通信网络信号覆盖。先选用“学校”作为过滤条件,由空间维表获取对应的Polygon对象集的临时表t2,再通过业务表t1与t2进行join获取在Polgyon内的所有记录,最后按照polygon进行聚合,并按Polygon返回对应的业务指标。
--SQL示例2--
select t2.polygon as polygon, sum(t1.data.kpi ) as kpi
from <table> t1
inner join
(
select t2.polygon, t2.type from buildingTable as t2 where t2.type = “school”
) on in_polygon_join(t1.geoid,t2.polygon)
group by t2.polygon;对返回的Polygon和KPI进行渲染,得到如下效果:
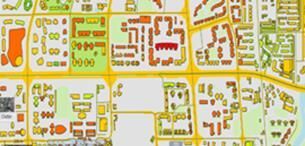
示例3:2D楼宇栅格分析场景
查询某CBD的建筑物内部通信网络覆盖分布。先用CBD的范围获取该范围内的Polygon对象列表,再用Polygon对象列表作为查询条件获取对应业务记录,最后按网格的经纬度进行聚合,返回网格经纬度和对应业务指标。
--SQL示例3--
select longitude, latitude, sum(kpi)
from <table>
where in_polygon_list('POLYGON ((116.292365 39.845140,116.292477 39.845165,116.292523 39.845045,116.292291 39.844993,116.292245 39.845113,116.292365 39.8451402470383)), POLYGON ((116.292477 39.845165,116.292365 39.845140,116.292335 39.845218,116.292449 39.845243,116.292479 39.845165,116.292477 39.845165))
','OR')
group by longitude, latitude;对返回网格的经纬度和KPI进行渲染,得到如下效果:
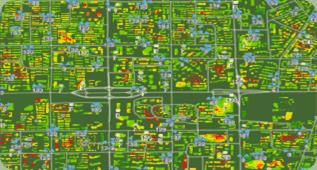
示例2.1是按整个建筑进行聚合,获取整栋建筑的指标,在进行某些热点区域分析时,还要分析建筑内部指标分布情况。
初步验证,对1000个多边形取OR进行查询,返回结果记录数22545条,SQL执行耗时为4.333秒。
示例4:3D楼宇分析场景
体育馆、音乐厅、购物中心、机场、火车站人流量比较大的场馆在网络实际运营过程中需要重点分析,需要了解每个楼层的立体空间的网络分布情况。行业内已经提供了按经度、纬度、高度建模的三维空间数据库,考虑通信行业在高度上诉求与人的活动和楼的高度有关,并不是所有地区都存在大量的高度信息,因此高度信息暂时不参与时空排序,仅作为一般维度参与业务分析。
--SQL示例4--
select longitude, latitude, height, sum(kpi)
from <table>
where in_polygon_list('POLYGON ((116.292365 39.845140,116.292477 39.845165,116.292523 39.845045,116.292291 39.844993,116.292245 39.845113,116.292365 39.8451402470383)), POLYGON ((116.292477 39.845165,116.292365 39.845140,116.292335 39.845218,116.292449 39.845243,116.292479 39.845165,116.292477 39.845165))
','OR')
group by longitude, latitude, height;使用建筑物的轮毂作为查询条件,获取到经度、纬度、高度和业务KPI后,进行3D渲染,展示立体楼宇的外立面和每个楼层的业务分布,得到如下效果:
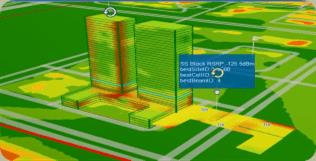
在进行3D楼宇分析时,因为数据精度问题,可能部分数据偏移到楼的外部,需要对楼宇的多边形进行适当外扩,确保业务数据查全。
5 技术展望
基于CarbonData的电信时空大数据的探索的初衷是解决产品查询性能问题,通过我们的实践看,带来的收益远不只是查询性能大幅提升。
常用的数据库有关系型数据库、空间数据库、图数据库,为满足不同场景的业务分析和用户最佳体验,需要选用合适的数据库。这样会导致业务进行融合分析时,依赖多种不同分析引擎,且业务分析流程冗长。基于CarbonData的时空大数据能力使得“湖仓一体”的融合分析成为可能,在湖仓内部使用统一SQL完成普通数据分析和时空分析,大大提升研发效率和湖仓架构的健壮性。
CarbonData的SQL接口还不是行业标准接口,后续计划完成GeoMesa与Carbon对接,提供符合OGC标准的通用时空查询接口。另外,时空分析的查询流程包括了数据过滤、聚合、制图,3D场景下还涉及3D建模,这几个场景都可以通过GPU加速获得极大性能提升,未来是否可以通过硬件加速提供极致的用户体验,让我们拭目以待。
以上是关于基于CarbonData的电信时空大数据探索的主要内容,如果未能解决你的问题,请参考以下文章
TransBigData:一款基于 Python 的超酷炫交通时空大数据工具包