RNN简介
Posted 三つ叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RNN简介相关的知识,希望对你有一定的参考价值。
RNN,或者说最常用的LSTM,一般用于记住之前的状态,以供后续神经网络的判断,它由input gate、forget gate、output gate和cell memory组成,每个LSTM本质上就是一个neuron,特殊之处在于有4个输入:z和三门控制信号 z i z_i zi、 z f z_f zf和 z o z_o zo,每个时间点的输入都是由当前输入值+上一个时间点的输出值+上一个时间点cell值来组成
RNN
用 RNN 处理流程举例如下:
- “arrive” 的 vector 作为 x 1 x^1 x1 输入 RNN,通过 hidden layer 生成 a 1 a^1 a1,再根据 a 1 a^1 a1 生成 y 1 y^1 y1,表示 “arrive” 属于每个 slot 的概率,其中 a 1 a^1 a1 会被存储到 memory 中
- “Taipei” 的 vector 作为 x 2 x^2 x2 输入 RNN,此时 hidden layer 同时考虑 x 2 x^2 x2 和存放在 memory 中的 a 1 a^1 a1,生成 a 2 a^2 a2,再根据 a 2 a^2 a2 生成 y 2 y^2 y2,表示 “Taipei” 属于某个 slot 的概率,此时再把 a 2 a^2 a2 存到 memory 中
- 依次类推

Elman Network & Jordan Network
RNN 有不同的变形:
- Elman Network:将 hidden layer 的输出保存在 memory 里
- Jordan Network:将整个 neural network 的输出保存在 memory 里
由于 hidden layer 没有明确的训练目标,而整个 NN 具有明确的目标,因此 Jordan Network 的表现会更好一些
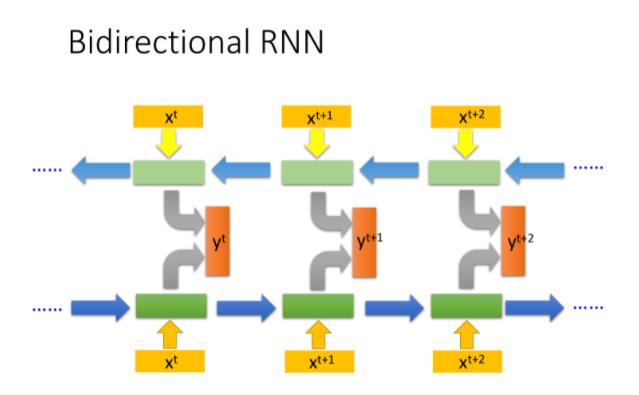
Bidirectional RNN
RNN 还可以是双向的,你可以同时训练一对正向和反向的 RNN,把它们对应的 hidden layer 拿出来,都接给一个output layer,得到最后的 y t y^t yt
使用 Bi-RNN 的好处是,NN 在产生输出的时候,它能够看到的范围是比较广的,RNN 在产生的时候,它不只看了从句首
x
1
x^1
x1 开始到
x
t
+
1
x^t+1
xt+1 的输入,还看了从句尾
x
n
x^n
xn 一直到
x
t
+
1
x^t+1
xt+1 的输入,这就相当于 RNN 在看了整个句子之后,才决定每个词汇具体要被分配到哪一个槽中,这会比只看句子的前一半要更好
LSTM
前文提到的 RNN 只是最简单的版本,并没有对 memory 的管理多加约束,可以随时进行读取,而现在常用的 memory 管理方式叫做长短期记忆(Long Short-term Memory),简称 LSTM
冷知识:可以被理解为比较长的短期记忆,因此是 short-term,而非是 long-short term
Three-gate
LSTM 有三个 gate:
- 当某个neuron的输出想要被写进 memory cell,它就必须要先经过一道叫做 input gate 的闸门,如果input gate关闭,则任何内容都无法被写入,而关闭与否、什么时候关闭,都是由神经网络自己学习到的
- output gate 决定了外界是否可以从 memory cell 中读取值,当 output gate 关闭的时候,memory 里面的内容同样无法被读取
- forget gate 则决定了什么时候需要把 memory cell 里存放的内容忘记清空,什么时候依旧保存

Memory Cell
如果从表达式的角度看 LSTM,它比较像下图中的样子
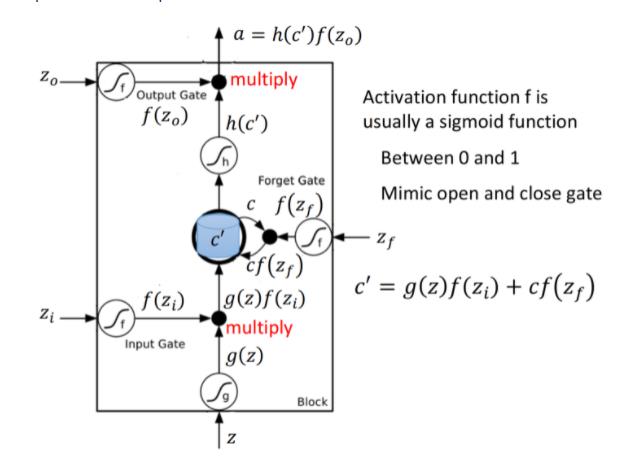
把
z
、
z
i
、
z
0
、
z
f
z、z_i、z_0、z_f
z、zi、z0、zf 通过 activation function,分别得到 $g(z)、f(z_i)、f(z_o)、f(z_f)
,
,
,f()$ 一般选用 sigmoid function,因为它的输出在 0~1 之间,代表 gate 被打开的程度
LSTM Example
下面演示了一个 LSTM 的基本过程, x 1 、 x 2 、 x 3 x_1、x_2、x_3 x1、x2、x3 是输入序列, y y y 是输出序列,基本原则是:
- 当 x 2 = 1 x_2 = 1 x2=1 时,将的值写入memory
- 当 x 2 = − 1 x_2 = -1 x2=−1 时,将memory里的值清零
- 当 x 3 = − 1 x_3 = -1 x3=−1 时,将memory里的值输出
- 当neuron的输入为正时,对应gate打开,反之则关闭

LSTM for RNN
下图是单个 LSTM 的运算情景

下图是同一个 LSTM 在两个相邻时间点上的情况

上图是单个 LSTM 作为 neuron 的情况,事实上 LSTM 基本上都会叠多层,如下图所示,左边两个 LSTM 代表了两层叠加,右边两个则是他们在下一个时间点的状态

GRU
另一个版本 GRU (Gated Recurrent Unit),只有两个gate,需要的参数量比 LSTM 少,鲁棒性比 LSTM 好,不容易过拟合,它的基本精神是旧的不去,新的不来,GRU会把 input gate 和 forget gate 连起来,当 forget gate 把 memory 里的值清空时,input gate 才会打开,再放入新的值
以上是关于RNN简介的主要内容,如果未能解决你的问题,请参考以下文章