大数据Azkaban Work Flow实战
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Azkaban Work Flow实战相关的知识,希望对你有一定的参考价值。
1 HelloWorld 案例
1)在 windows 环境,新建 azkaban.project 文件,编辑内容如下azkaban-flow-version: 2.0
注意:该文件作用,是采用新的 Flow-API 方式解析 flow 文件。
2.0 azkaban支持 properties配置文件,也支持yml配置文件!
3.0 azkaban默认支持yml配置文件!
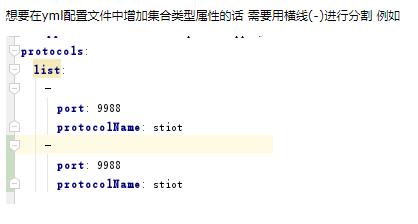
1.1 yarm语法:
yml: 简洁,适合表示层级关系复杂的数据!
- yml主要使用缩进表示层级关系,一旦下一行出现了缩进,表示下一行是上一行的子属性!
- 缩进时,如果缩进的距离一致,层级一致!
- 大量使用空格,缩进时不能使用tab,K-V之间必须使用空格!
K-V类型表示方法:
k:(空格)v
对象类型数据,map(k-v)
jack:
name: jack
age: 20
单行:
jack: name: jack,age: 20
数组类型数据,List,Set
fruits:
- apple
- banana
单行:
fruits: [apple,banana]
2)新建 basic.flow 文件,内容如下
nodes:
- name: jobA
type: command
config:
command: echo "Hello World"
(1)Name:job 名称
(2)Type:job 类型。command 表示你要执行作业的方式为命令
(3)Config:job 配置
3)将 azkaban.project、basic.flow 文件压缩到一个 zip 文件,文件名称必须是英文。

4)在 WebServer 新建项目:http://hadoop102:8081/index
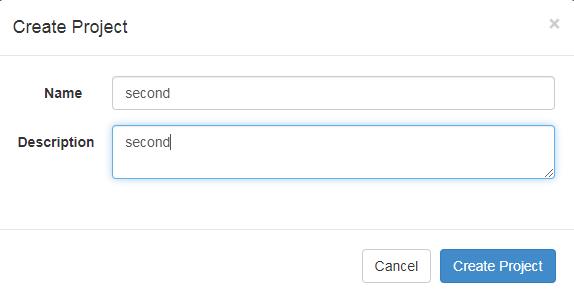
5)给项目名称命名和添加项目描述
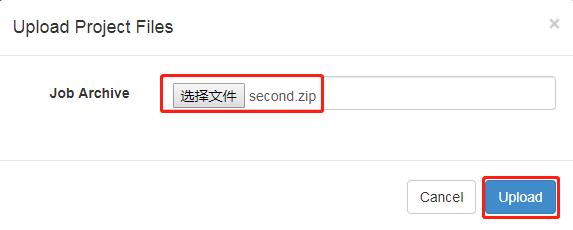
6)first.zip 文件上传
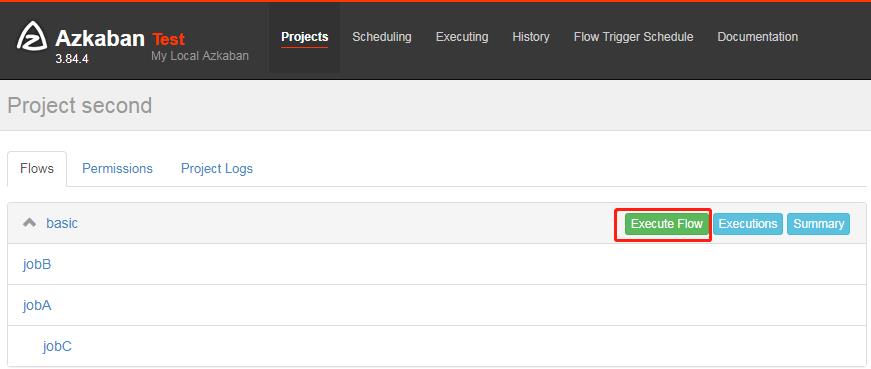
7)选择上传的文件
8)执行任务流
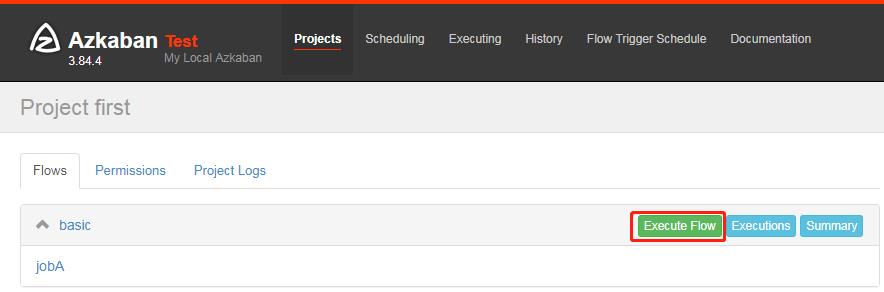
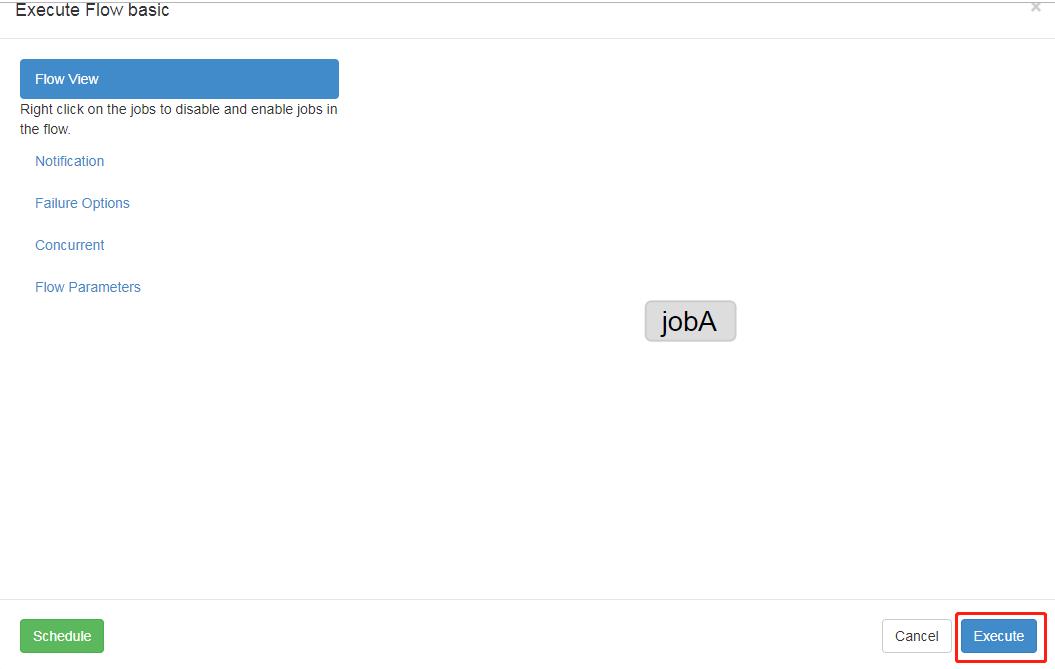
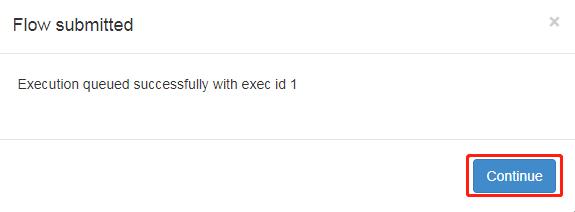
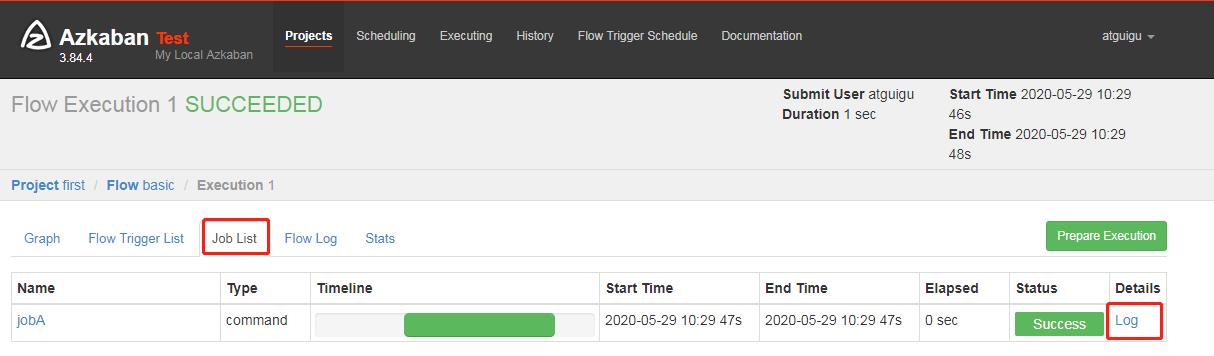
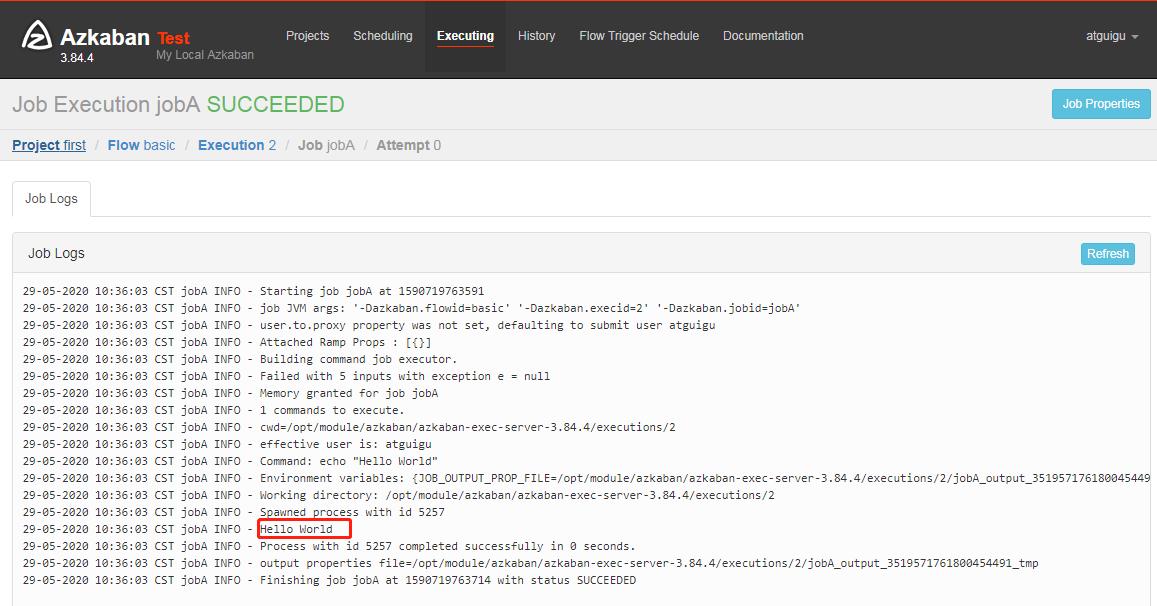
9)在日志中,查看运行结果
2 作业依赖案例
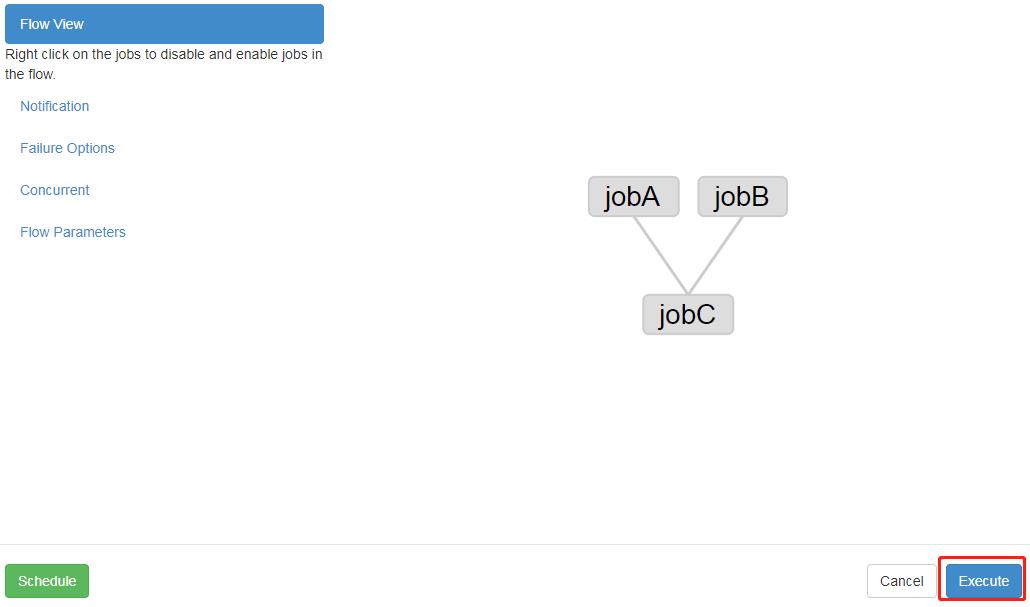
需求:JobA 和 JobB 执行完了,才能执行 JobC
具体步骤:
2.1 修改 basic.flow 为如下内容
nodes:
- name: jobC
type: command
# jobC 依赖 JobA 和 JobB
dependsOn:
- jobA
- jobB
config:
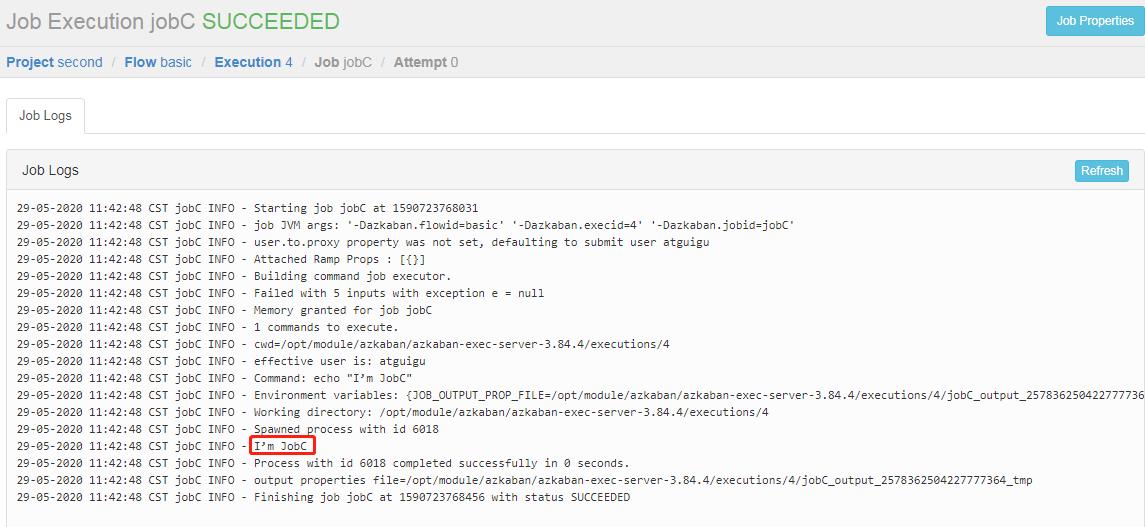
command: echo "I’m JobC"
- name: jobA
type: command
config:
command: echo "I’m JobA"
- name: jobB
type: command
config:
command: echo "I’m JobB"
(1)dependsOn:作业依赖,后面案例中演示
2.2 将修改后的 basic.flow 和 azkaban.project 压缩成 second.zip 文件

2.3 重复 HelloWorld 后续步骤。
3 自动失败重试案例
需求:如果执行任务失败,需要重试 3 次,重试的时间间隔 10000ms
具体步骤:
3.1 编译配置流
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
retries: 3
retry.backoff: 10000
这个sh文件是不存在的
参数说明:
retries:重试次数
retry.backoff:重试的时间间隔
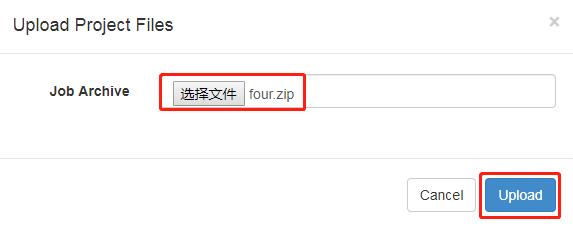
3.2 将修改后的 basic.flow 和 azkaban.project 压缩成 four.zip 文件

3.3 重复HelloWorld 后续步骤。
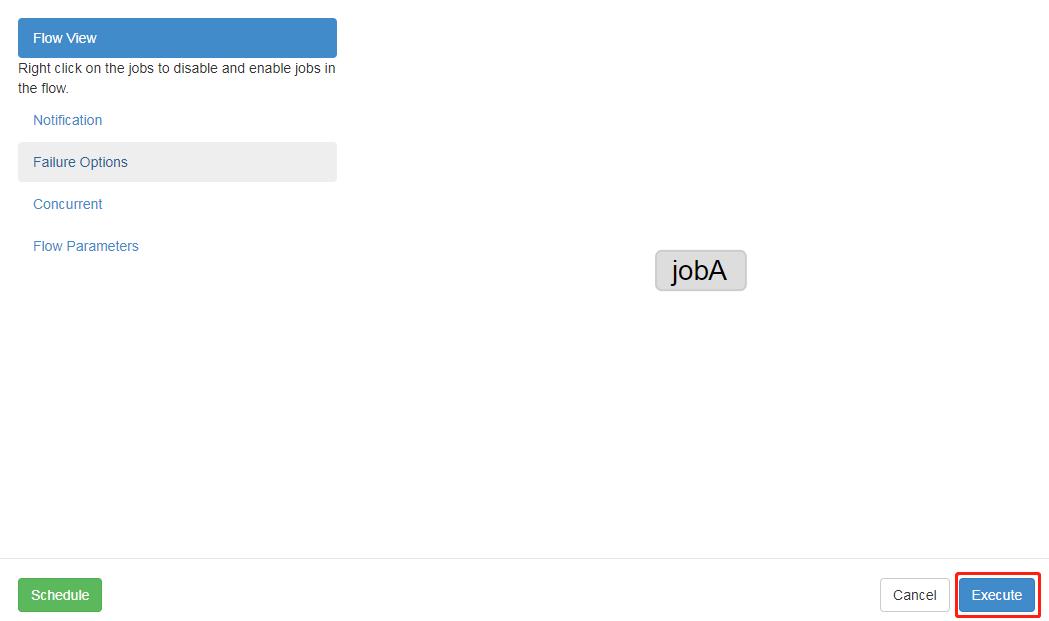
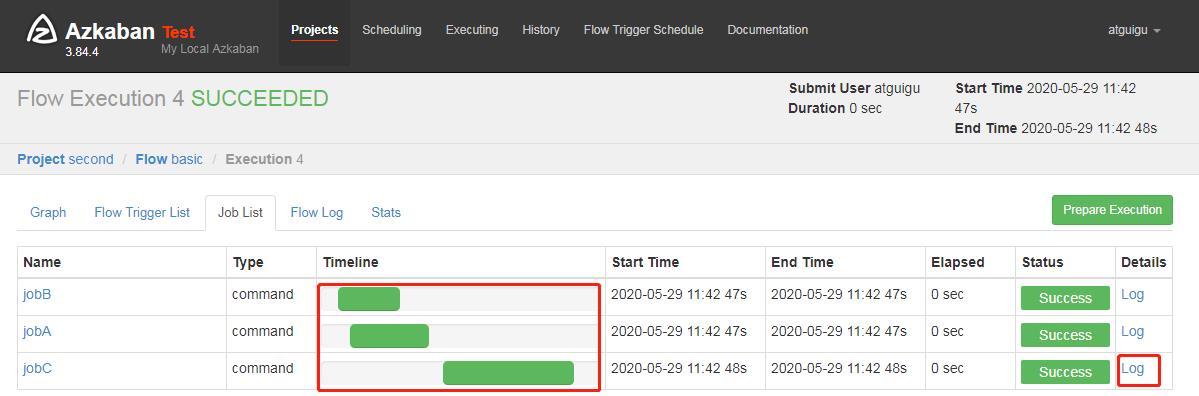
3.4 执行并观察到一次失败+三次重试
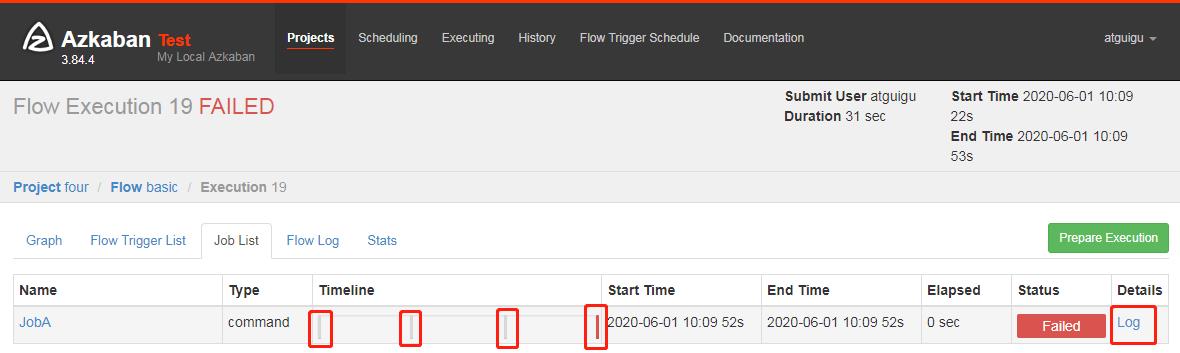
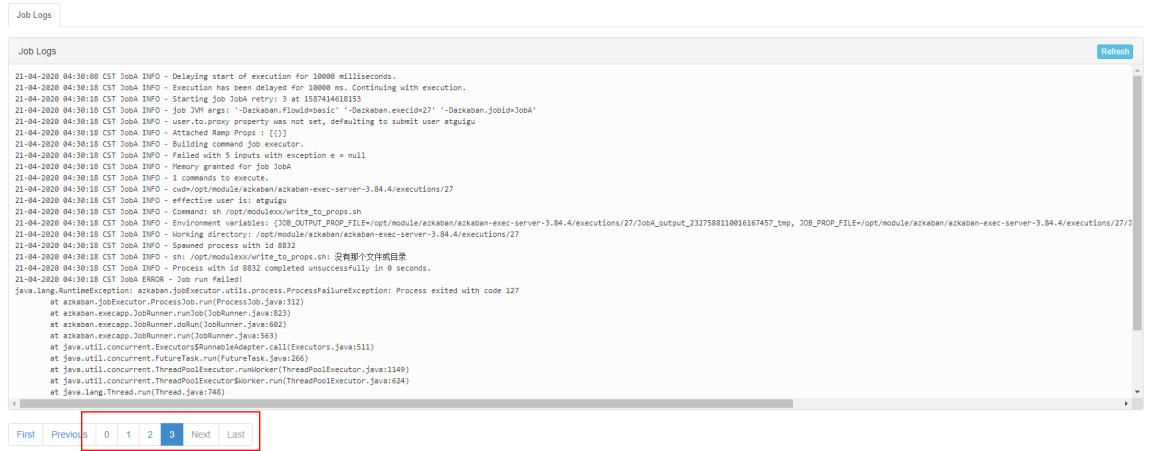
3.5 也可以点击上图中的 Log,在任务日志中看到,总共执行了 4 次
。
3.6 也可以在 Flow 全局配置中添加任务失败重试配置,此时重试配置会应用到所有 Job
案例如下:
config:
retries: 3
retry.backoff: 10000
nodes:
- name: JobA
type: command
config:
command: sh /not_exists.sh
4 手动失败重试案例
需求:JobA=》JobB(依赖于 A)=》JobC=》JobD=》JobE=》JobF。生产环境,任何 Job 都有可能挂掉,可以根据需求执行想要执行的 Job。
具体步骤:
4.1 编译配置流
nodes:
- name: JobA
type: command
config:
command: echo "This is JobA."
- name: JobB
type: command
dependsOn:
- JobA
config:
command: echo "This is JobB."
- name: JobC
type: command
dependsOn:
- JobB
config:
command: echo "This is JobC."
- name: JobD
type: command
dependsOn:
- JobC
config:
command: echo "This is JobD."
- name: JobE
type: command
dependsOn:
- JobD
config:
command: echo "This is JobE."
- name: JobF
type: command
dependsOn:
- JobE
config:
command: echo "This is JobF."
4.2 将修改后的 basic.flow 和 azkaban.project 压缩成 five.zip 文件

4.3 重复HelloWorld 后续步骤。
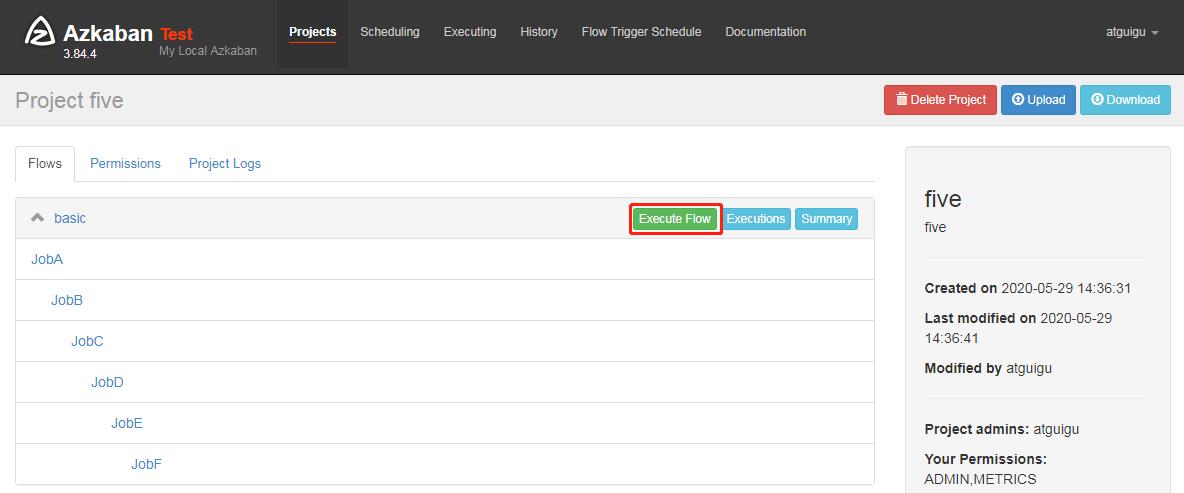
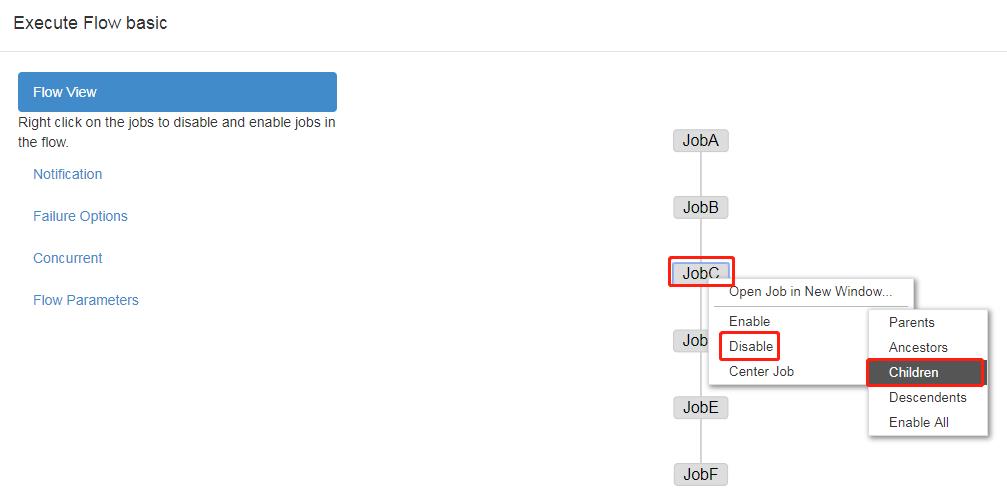
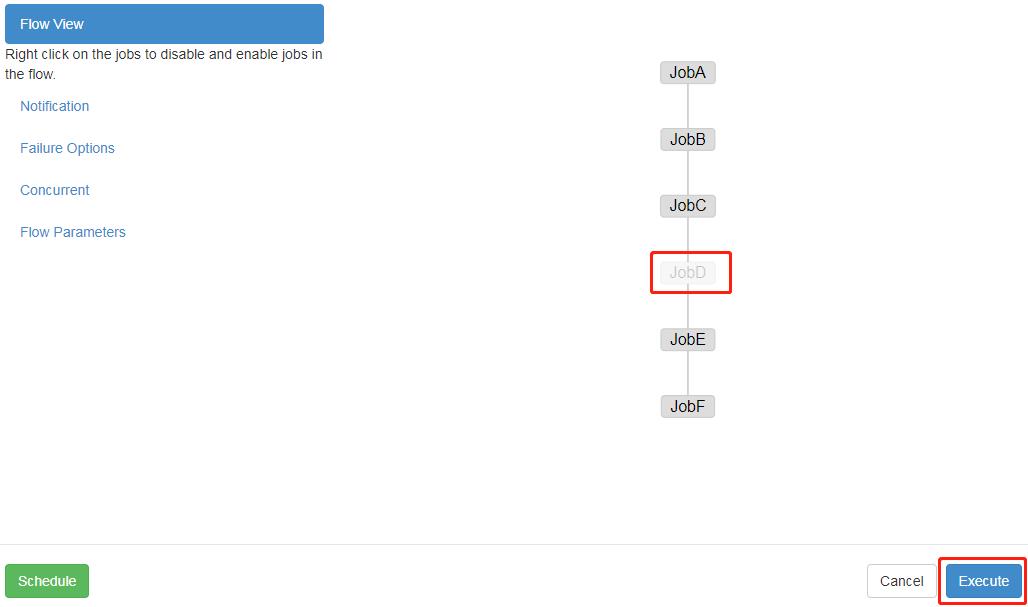
Enable 和 Disable 下面都分别有如下参数:
Parents:该作业的上一个任务
Ancestors:该作业前的所有任务
Children:该作业后的一个任务
Descendents:该作业后的所有任务
Enable All:所有的任务
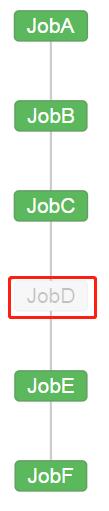
4.4 可以根据需求选择性执行对应的任务。
以上是关于大数据Azkaban Work Flow实战的主要内容,如果未能解决你的问题,请参考以下文章