『TensorFlow』网络操作API
Posted 叠加态的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『TensorFlow』网络操作API相关的知识,希望对你有一定的参考价值。
卷积层
卷积操作是使用一个二维的卷积核在一个批处理的图片上进行不断扫描。具体操作是将一个卷积核在每张图片上按照一个合适的尺寸在每个通道上面进行扫描。为了达到好的卷积效率,需要在不同的通道和不同的卷积核之间进行权衡。
三个卷积函数:
conv2d: 任意的卷积核,能同时在不同的通道上面进行卷积操作。depthwise_conv2d: 卷积核能相互独立的在自己的通道上面进行卷积操作。separable_conv2d: 在纵深卷积depthwise filter之后进行逐点卷积separable filter。
卷积步长:
strides ,比如 strides = [1, 1, 1, 1] 表示卷积核对每个像素点进行卷积,即在二维屏幕上面,两个轴方向的步长都是1。strides = [1, 2, 2, 1] 表示卷积核对每隔一个像素点进行卷积,即在二维屏幕上面,两个轴方向的步长都是2。
输出shape:
padding = \'SAME\': 向下取舍,仅适用于全尺寸操作,即输入数据维度和输出数据维度相同。padding = \'VALID: 向上取舍,适用于部分窗口,即输入数据维度和输出数据维度不同,输出维度如下。
shape(output) = [batch,
(in_height - filter_height + 1) / strides[1],
(in_width - filter_width + 1) / strides[2],
...]
conv2d
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)输入参数:
input: 一个Tensor。数据类型必须是float32或者float64。filter: 一个Tensor。数据类型必须是input相同。strides: 一个长度是4的一维整数类型数组,每一维度对应的是input中每一维的对应移动步数,比如,strides[1]对应input[1]的移动步数。padding: 一个字符串,取值为SAME或者VALID。use_cudnn_on_gpu: 一个可选布尔值,默认情况下是True。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型是input相同。
解释:这个函数的作用是对一个四维的输入数据 input 和四维的卷积核 filter 进行操作,然后对输入数据进行一个二维的卷积操作,最后得到卷积之后的结果。
给定的输入张量的维度是 [batch, in_height, in_width, in_channels] ,卷积核张量的维度是 [filter_height, filter_width, in_channels, out_channels] ,具体卷积操作如下:
- 将卷积核的维度转换成一个二维的矩阵形状
[filter_height * filter_width * in_channels, output_channels] - 对于每个批处理的图片,我们将输入张量转换成一个临时的数据维度
[batch, out_height, out_width, filter_height * filter_width * in_channels]。 - 对于每个批处理的图片,我们右乘以卷积核,得到最后的输出结果。
更加具体的表示细节为:
output[b, i, j, k] = sum_{di, dj, q}
input[b, strides[1] * i + di, strides[2] * j + dj, q] * filter[di, dj, q, k]
注意,必须有 strides[0] = strides[3] = 1。在大部分处理过程中,卷积核的水平移动步数和垂直移动步数是相同的,即 strides = [1, stride, stride, 1] 。
depthwise_conv2d
tf.nn.depthwise_conv2d(input, filter, strides, padding, name=None)输入参数:
input: 一个Tensor。数据维度是四维[batch, in_height, in_width, in_channels]。filter: 一个Tensor。数据维度是四维[filter_height, filter_width, in_channels, channel_multiplier]。strides: 一个长度是4的一维整数类型数组,每一维度对应的是input中每一维的对应移动步数,比如,strides[1]对应input[1]的移动步数。padding: 一个字符串,取值为SAME或者VALID。use_cudnn_on_gpu: 一个可选布尔值,默认情况下是True。name: (可选)为这个操作取一个名字。输出参数:
- 一个四维的
Tensor,数据维度为[batch, out_height, out_width, in_channels * channel_multiplier]。
解释:这个函数也是一个卷积操作。
给定一个输入张量,数据维度是 [batch, in_height, in_width, in_channels] ,一个卷积核的维度是 [filter_height, filter_width, in_channels, channel_multiplier] ,在通道 in_channels 上面的卷积深度是 1 (我的理解是在每个通道上单独进行卷积),depthwise_conv2d 函数将不同的卷积核独立的应用在 in_channels 的每个通道上(从通道 1 到通道 channel_multiplier ),然后把所有的结果进行汇总。最后输出通道的总数是 in_channels * channel_multiplier 。
更加具体公式如下:
output[b, i, j, k * channel_multiplier + q] =
sum_{di, dj} input[b, strides[1] * i + di, strides[2] * j + dj, k] *
filter[di, dj, k, q]
注意,必须有 strides[0] = strides[3] = 1。在大部分处理过程中,卷积核的水平移动步数和垂直移动步数是相同的,即 strides = [1, stride, stride,1]。
使用例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
input_data = tf.Variable( np.random.rand(10, 6, 6, 3), dtype = np.float32 )
filter_data = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32)
y = tf.nn.depthwise_conv2d(input_data, filter_data, strides = [1, 1, 1, 1], padding = \'SAME\')
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(y)
print sess.run(tf.shape(y))
separable_conv2d
tf.nn.separable_conv2d(input, depthwise_filter, pointwise_filter, strides, padding, name=None)输入参数:
input: 一个Tensor。数据维度是四维[batch, in_height, in_width, in_channels]。depthwise_filter: 一个Tensor。数据维度是四维[filter_height, filter_width, in_channels, channel_multiplier]。其中,in_channels的卷积深度等于input的in_channels。pointwise_filter: 一个Tensor。数据维度是四维[1, 1, channel_multiplier * in_channels, out_channels]。其中,pointwise_filter是在depthwise_filter卷积之后的混合卷积。strides: 一个长度是4的一维整数类型数组,每一维度对应的是input中每一维的对应移动步数,比如,strides[1]对应input[1]的移动步数。padding: 一个字符串,取值为SAME或者VALID。name: (可选)为这个操作取一个名字。输出参数:
- 一个四维的
Tensor,数据维度为[batch, out_height, out_width, out_channels]。异常:
数值异常: 如果channel_multiplier * in_channels > out_channels,那么将报错。
解释:这个函数的作用是利用几个分离的卷积核去做卷积,可以参考这个解释。
比如下图中,常规卷积和分离卷积的区别:
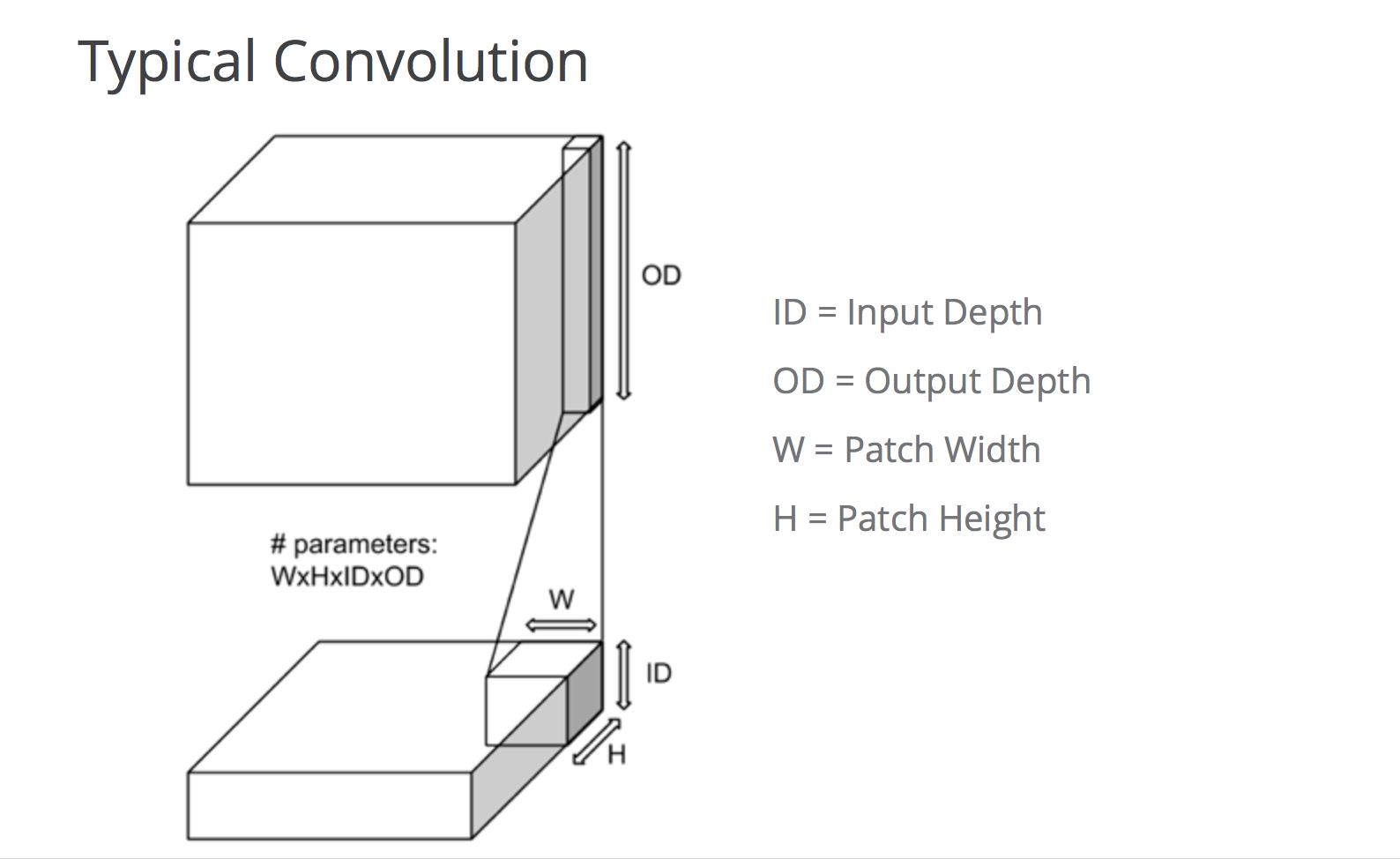
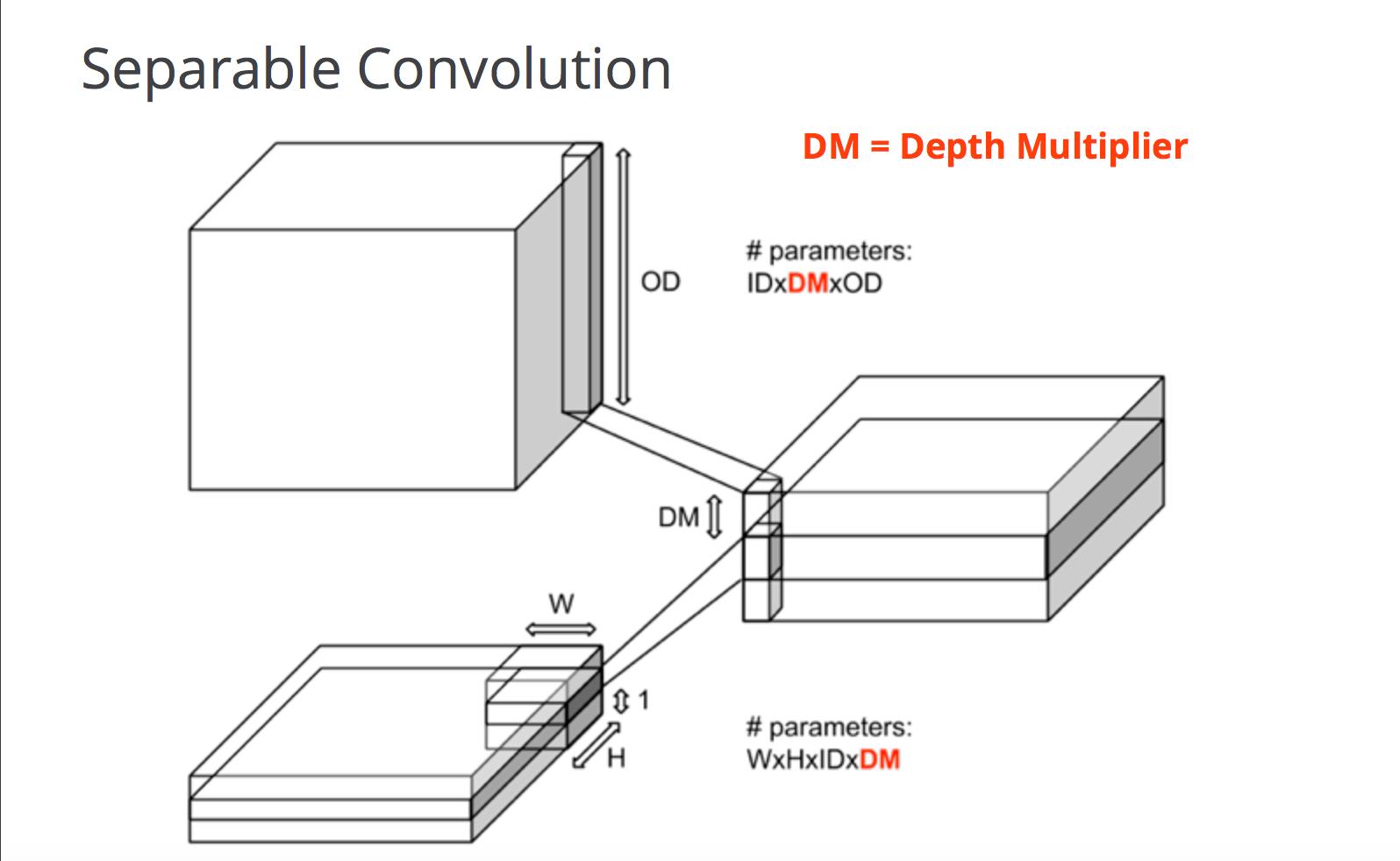
首先使用一个二维的卷积核,在每个通道上,以深度 channel_multiplier 进行卷积。也就是先使用 depthwise_conv2d ,将 ID 的通道数映射到 ID * DM 的通道数上面,之后从 ID * DM 的通道数映射到 OD 的通道数上面,这也就是又进行了一次常规卷积。
具体公式如下:
output[b, i, j, k] = sum_{di, dj, q, r}
input[b, strides[1] * i + di, strides[2] * j + dj, q] *
depthwise_filter[di, dj, q, r] *
pointwise_filter[0, 0, q * channel_multiplier + r, k]
strides 只是仅仅控制 depthwise convolution 的卷积步长,因为 pointwise convolution 的卷积步长是确定的 [1, 1, 1, 1] 。注意,必须有 strides[0] = strides[3] = 1。在大部分处理过程中,卷积核的水平移动步数和垂直移动步数是相同的,即 strides = [1, stride, stride, 1]。
使用例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
input_data = tf.Variable( np.random.rand(10, 6, 6, 3), dtype = np.float32 )
depthwise_filter = tf.Variable( np.random.rand(2, 2, 3, 5), dtype = np.float32) # 输入通道等于input的通道
pointwise_filter = tf.Variable( np.random.rand(1, 1, 15, 20), dtype = np.float32) # 卷积核两项必须是1
# out_channels >= channel_multiplier * in_channels
y = tf.nn.separable_conv2d(input_data, depthwise_filter,
pointwise_filter, strides = [1, 1, 1, 1], padding = \'SAME\')
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(y)
print sess.run(tf.shape(y))
池化层
最大汇聚效果优于平均汇聚
池化操作是利用一个矩阵窗口在输入张量上进行扫描,并且将每个矩阵窗口中的值通过取最大值,平均值或者XXXX来减少元素个数。每个池化操作的矩阵窗口大小是由 ksize 来指定的,并且根据步长参数 strides 来决定移动步长。比如,如果 strides 中的值都是1,那么每个矩阵窗口都将被使用。如果 strides 中的值都是2,那么每一维度上的矩阵窗口都是每隔一个被使用。以此类推。
输出数据维度是:
shape(output) = (shape(value) - ksize + 1) / strides
padding = \'SAME\': 向下取舍,仅适用于全尺寸操作,即输入数据维度和输出数据维度相同。padding = \'VALID: 向上取舍,适用于部分窗口,即输入数据维度和输出数据维度不同,输出维度如上。
avg_pool
tf.nn.avg_pool(value, ksize, strides, padding, name=None)解释:这个函数的作用是计算池化区域中元素的平均值。
输入参数:
value: 一个四维的Tensor。数据维度是[batch, height, width, channels]。数据类型是float32,float64,qint8,quint8,qint32。ksize: 一个长度不小于4的整型数组。每一位上面的值对应于输入数据张量中每一维的窗口对应值。strides: 一个长度不小于4的整型数组。该参数指定滑动窗口在输入数据张量每一维上面的步长。padding: 一个字符串,取值为SAME或者VALID。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和value相同。
max_pool
tf.nn.max_pool(value, ksize, strides, padding, name=None)解释:这个函数的作用是计算池化区域中元素的最大值。输入参数:
value: 一个四维的Tensor。数据维度是[batch, height, width, channels]。数据类型是float32,float64,qint8,quint8,qint32。ksize: 一个长度不小于4的整型数组。每一位上面的值对应于输入数据张量中每一维的窗口对应值。strides: 一个长度不小于4的整型数组。该参数指定滑动窗口在输入数据张量每一维上面的步长。padding: 一个字符串,取值为SAME或者VALID。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和value相同。
激活函数
在神经网络中,我们有很多的非线性函数来作为激活函数,比如连续的平滑非线性函数(sigmoid,tanh和softplus),连续但不平滑的非线性函数(relu,relu6和relu_x)和随机正则化函数(dropout)。
所有的激活函数都是单独应用在每个元素上面的,并且输出张量的维度和输入张量的维
分类:
平滑非线性(sigmoid,tanh,elu,softplus,softsign)
连续但不是处处可导(relu,relu6,crelu,relu_x)
随机正则化(dropout)
relu
tf.nn.relu(features, name = None)解释:这个函数的作用是计算激活函数
relu,即max(features, 0)。输入参数:
features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16,int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同。
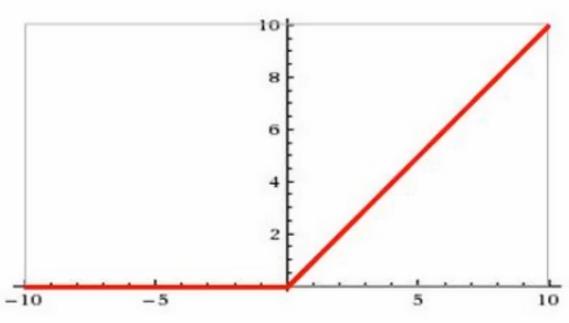
relu6
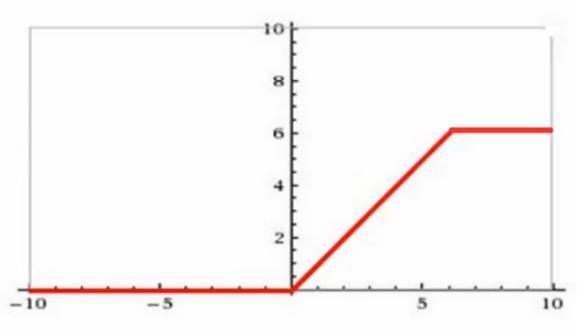
tf.nn.relu6(features, name = None)解释:这个函数的作用是计算激活函数
relu6,即min(max(features, 0), 6)。输入参数:
features: 一个Tensor。数据类型必须是:float,double,int32,int64,uint8,int16或者int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同。
crelu
tf.nn.crelu(features, name = None)
解释:这个函数会倍增通道,一个是relu,一个是relu关于y轴对称的形状。
输入参数:
features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16,int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同,通道加倍。
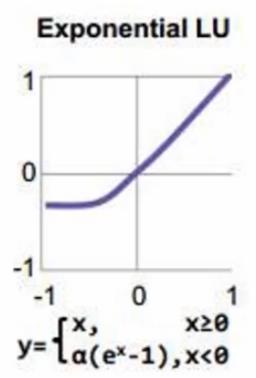
elu
tf.nn.elu(features, name = None)
解释:x小于0时,y = a*(exp(x)-1),x大于0时同relu。
features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16,int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同。
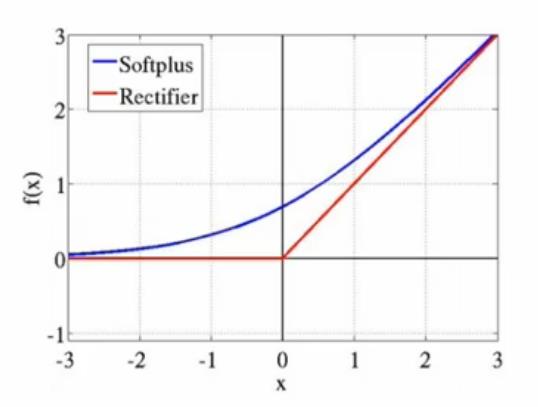
softplus
tf.nn.softplus(features, name = None)解释:这个函数的作用是计算激活函数
softplus,即log( exp( features ) + 1)。输入参数:
features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16或者int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同。
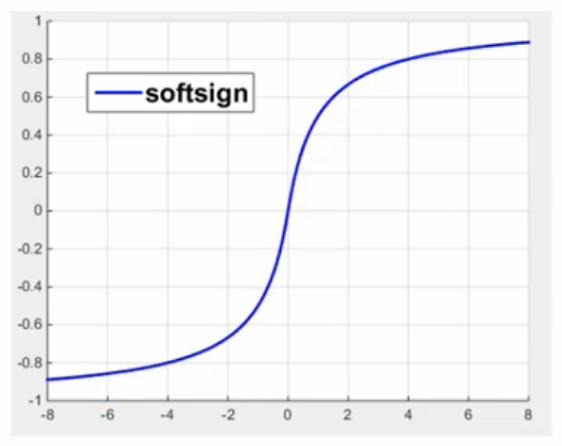
softsign
softsign
tf.nn.soft(features, name = None)sign解释:这个函数的作用是计算激活函数
softsign,即features / (abs(features) + 1)。输入参数:
features: 一个Tensor。数据类型必须是:float32,float64,int32,int64,uint8,int16或者int8。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和features相同。
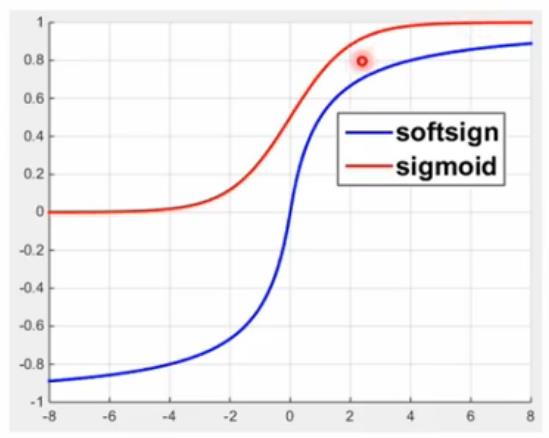
sigmoid
sigmoid
tf.sigmoid(x, name = None)解释:这个函数的作用是计算
x的 sigmoid 函数。具体计算公式为y = 1 / (1 + exp(-x))。输入参数:
x: 一个Tensor。数据类型必须是float,double,int32,complex64,int64或者qint32。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,如果x.dtype != qint32,那么返回的数据类型和x相同,否则返回的数据类型是quint8。
sigmoid输出恒大于零,相当于加了偏置分量。
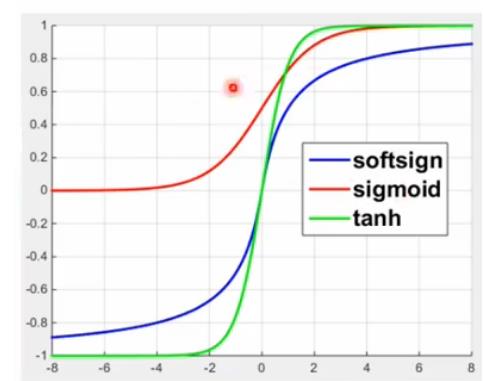
tanh
tf.tanh(x, name = None)解释:这个函数的作用是计算
x的 tanh 函数。具体计算公式为( exp(x) - exp(-x) ) / ( exp(x) + exp(-x) )。
x: 一个Tensor。数据类型必须是float,double,int32,complex64,int64或者qint32。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,如果x.dtype != qint32,那么返回的数据类型和x相同,否则返回的数据类型是quint8。
[-2,2]之间tanh最敏感
[-8,-2]之间tanh不敏感
dropout
tf.nn.dropout(x, keep_prob, noise_shape = None, seed = None, name = None)解释:这个函数的作用是计算神经网络层的
dropout。一个神经元将以概率
keep_prob决定是否放电,如果不放电,那么该神经元的输出将是0,如果该神经元放电,那么该神经元的输出值将被放大到原来的1/keep_prob倍。这里的放大操作是为了保持神经元输出总个数不变。比如,神经元的值为[1, 2],keep_prob的值是0.5,并且是第一个神经元是放电的,第二个神经元不放电,那么神经元输出的结果是[2, 0],也就是相当于,第一个神经元被当做了1/keep_prob个输出,即2个。这样保证了总和2个神经元保持不变。默认情况下,每个神经元是否放电是相互独立的。但是,如果
noise_shape被修改了,那么他对于变量x就是一个广播形式,而且当且仅当noise_shape[i] == shape(x)[i],x中的元素是相互独立的。比如,如果shape(x) = [k, l, m, n], noise_shape = [k, 1, 1, n],那么每个批和通道都是相互独立的,但是每行和每列的数据都是关联的,即要不都为0,要不都还是原来的值。输入参数:
x: 一个Tensor。keep_prob: 一个 Python 的 float 类型。表示元素是否放电的概率。noise_shape: 一个一维的Tensor,数据类型是int32。代表元素是否独立的标志。seed: 一个Python的整数类型。设置随机种子。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据维度和x相同。异常:
输入异常: 如果keep_prob不是在(0, 1]区间,那么会提示错误。
bias_add
tf.nn.bias_add(value, bias, name = None)解释:这个函数的作用是将偏差项
bias加到value上面。这个操作你可以看做是
tf.add的一个特例,其中bias必须是一维的。该API支持广播形式,因此value可以有任何维度。但是,该API又不像tf.add可以让bias的维度和value的最后一维不同,tf.nn.bias_add中bias的维度和value最后一维必须相同。输入参数:
value: 一个Tensor。数据类型必须是float,double,int64,int32,uint8,int16,int8或者complex64。bias: 一个一维的Tensor,数据维度和value的最后一维相同。数据类型必须和value相同。name: (可选)为这个操作取一个名字。输出参数:
- 一个
Tensor,数据类型和value相同。
范例:
#!/usr/bin/env python # -*- coding: utf-8 -*- import tensorflow as tf a = tf.constant([[1.0, 2.0],[1.0, 2.0],[1.0, 2.0]]) b = tf.constant([2.0,1.0]) c = tf.constant([1.0]) sess = tf.Session() print sess.run(tf.nn.bias_add(a, b)) # 因为 a 最后一维的维度是 2 ,但是 c 的维度是 1,所以以下语句将发生错误 print sess.run(tf.nn.bias_add(a, c)) # 但是 tf.add() 可以正确运行 print sess.run(tf.add(a, c))
以上是关于『TensorFlow』网络操作API的主要内容,如果未能解决你的问题,请参考以下文章