MySQL索引
Posted 两片空白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL索引相关的知识,希望对你有一定的参考价值。
目录
前言
mysql是对用户的数据进行管理的,而数据都保存在磁盘中,MySQL对数据进行管理需要先将数据从磁盘读取到内存中,再将修改了的数据,刷新到磁盘中。然而,这是IO操作,效率是比较低的。
并且当数据量比较大时,当查询数据时,由于内存无法全部保存数据,只能将数据分批次读取上来,这样会导致IO次数增加。
索引是MySQL中提高查询数据的一种方式。但是查询数据的提高是以插入,更新,删除的速度为代价的。
所以索引的价值在于提高海量数据的查询速度。
下面来介绍索引是如何提高查询效率的,首先我们来了解一下磁盘,并且为什么磁盘操作会这么慢。
一.认识磁盘

磁盘的一个盘片:

- 磁道:磁盘表面有许多同心圆,每一个同心圆称为一个磁道。
- 扇区:每一个磁道又被划分成了若干段,每一段就是一个扇区。数据库文件保存在扇区中,一个扇区的大小一般是512字节。当一个数据库文件很大时,可能会占据多个扇区。
从上图看,离圆心越近扇区越小,离圆心越远,扇区越大。最新的磁盘技术已经让扇区大小不同。
所以找到一个数据库文件,需要定位到保存文件的扇区。
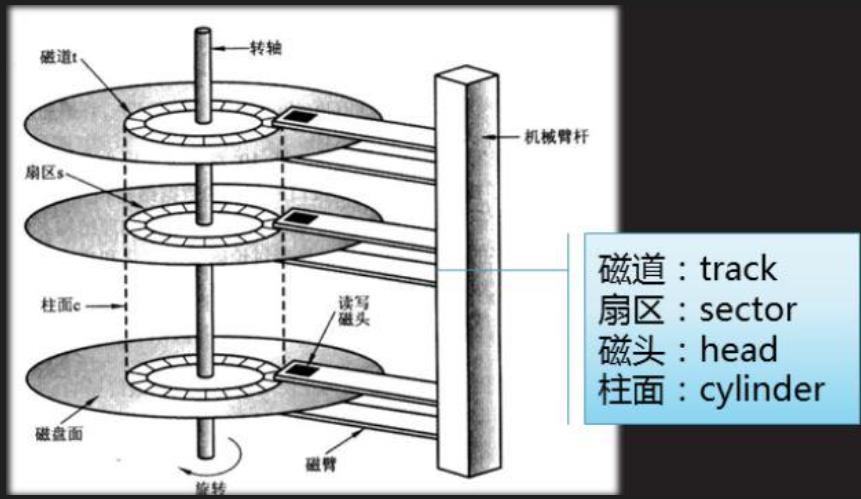
- 多盘磁盘,每个盘都有两个面,大小完全相同。
- 柱面:多个磁盘中,半径相同的同心圆构成一个柱面。
- 每一个盘面都有一个磁头,磁头和盘面的关系时一一对应的。
磁盘定位文件的扇区:
先定位盘面,也就确定了磁头。在确定柱面(磁头旋转到柱面处),再确定好扇区(盘片旋转,使得磁头指向对应扇区)。
这种磁盘数据定位方式叫做CHS。但是实际系统软件使用的并不是CHS(硬件是),使用的是LBA,一种线性地址,可以想象成虚拟地址和物理地址(可以抽象成一个大数组),系统将LBA的地址最后转化成CHS,交给磁盘进行数据读取。
这样是为了不需要让OS管理磁盘,是得OS和磁盘解耦。避免磁盘技术改动,需要改动OS代码。
磁盘传送数据并不耗时,最耗时的是磁头寻址。定位盘片,磁道和扇区。
在硬件层面上,我们已经可以定位一个扇区,那么在系统软件层面上,我们也是按一个扇区的大小来读进行IO交互吗?
答案是并不是。
- 如过操作系统使用硬件提供的数据大小来和磁盘进行交互,那么OS代码会和硬件强相关,当磁盘扇区大小改变,OS代码就会需要跟着变化。
- 并且,单次交互512字节,还是太小了。当文件很大时,意味着进行IO的次数会很多,大大降低效率。
- 操作系统的文件系统读取的基本单位不是扇区,而是数据块。基本单位是4KB。
磁盘随机访问和连续访问:
随机访问:是本次IO给出的扇区的地址和上一次IO给出的扇区地址不连续,需要重新定位盘片,磁道和扇区。
连续访问:是本次IO给出的扇区的地址和上一次IO给出的扇区地址连续,不需要过多的定位。
因此,连续访问的效率比随机访问的效率高。
二.MySQL与磁盘的交互基本单位
MySQL作为一款应用软件,可以想象成一个特殊的文件系统。它有着更高的IO场景,为了提高IO效率,MySQL与磁盘交互的基本单位是16KB。
用指令查看:
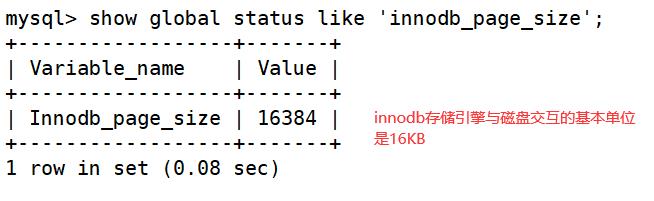
磁盘硬件设备的基本单位是512字节,操作系用户与磁盘交互的基本单位是4KB,称为一个page。MySQL和磁盘进行交互的基本单位是16KB,在MySQL中也被称为page,下面讨论的是MySQL的page。
MySQL与磁盘交互的基本单位是16字节是什么意思?
MySQL每次和磁盘交互(IO),一次性从磁盘拿16KB,不论数据大小是大于还是小于16KB,小于向上取整到16KB,大于分多次从磁盘获取,每次16KB。即,MySQL和磁盘交互的大小一定是16KB的整数倍。
MySQL为什么和磁盘交互交互是16KB,用多少加载多少不好吗?
一个表中可能会有很多数据。如果每次查询一次数据,查询多次,就会需要进行多次IO,导致效率会很慢。
而一次性加载16KB,16KB里会含有多条数据。用户连续申请的资源大概率在其中,大大减少了IO。提高了效率。
但是,我们也不能保证一定会在其中。但是又很大的概率,因为有局部性原理。往往IO效率低下的主要矛盾不是每次IO数据量的大小,而是IO的次数。
比如:一个表中有5条数据,用户查询数据,MySQL一次性获取16KB,可能就将数据全部拿上来了。下一次查询就不需要进行IO了。
注意:MySQL与磁盘交互(IO)每次是一个Page,也就是16KB。不是多个Page。
总结:
- MySQL的数据文件是以Page为单位保存在磁盘中的。
- MySQL的增删查改操作,都是需要通过计算的,找到对应插入位置,或者找到对应修改或者查询的数据。
- 只要涉及到计算就需要CPU的参与。根据冯诺依曼结构,数据需要加载到内存中。
- 所以在特定的时间内,数据一定是磁盘中有,内存中也有。后序操作完内存的数据之后,以特定的刷新策略,刷新到磁盘中。
- 从磁盘读取数据和将数据刷新到磁盘中,需要涉及和磁盘的交互(IO),此时IO的基本单位就是Page(16KB)。
- 为了更好的进行上面的操作,MySQL在运行的时候,在服务器(MySQLd)内部会向操作系统申请被称为buffer pool的大内存空间,进行各种缓存。
- buffer pool其实就是一个大块内存空间,一般125M或者256M。MySQL对该空间进行管理。
为什么MySQL要申请buffer pool大块空间?
MySQLd中肯定会存在大量的page,并且会需要频繁的进行申请内存和释放内存的操作,为了不用频繁的向OS申请内存和释放内存,OS管理的东西太多了。申请一块大内存自己管理是最好的。
画一个图来理解 一下:

MySQL增删查改表中的数据不是在磁盘里操作的,而是将数据加载到内存,准确点,是MySQL的buffer pool中。在buffer pool里操作。操作完之后,在刷新到磁盘中。
MySQL会用一种方式记录Page是否被修改,被修改的Page被称为脏页。这种方式可以理解成位图的方式。当修改了Page中的数据,MySQL只需要将修改的Page刷新到磁盘中,并不是将所有Page都刷新到磁盘中。
比如:buffer pool中有5个page,MySQL以0表示未修改,1表示修改。此时记录为00000,当用户修改了第2个page,此时记录变为00100,此时,第三个page 被称为脏页,MySQL只需要将第三个page刷新到磁盘中。
三.索引的理解
3.1 引出索引
建立测试表:

我们发现,我们主键插入的顺序并不是有序的,但是在表中,确变成了有序的,这是谁做的呢?这样有什么好处呢?
实际上这是因为MySQL的索引结构,要求的。好处下面介绍。
说明:如果这里没有主键,插入什么顺序,表中就是什么顺序。这说明,索引需要和特定的设定有关。

3.2 MySQL管理Page
3.2.1 单个Page的情况
MySQL中的数据文件可能有一个或者多个Page构成,而MySQL是管理数据的。所以MySQL中会有很多Page。MySQL需要对page进行管理,就需要先描述后组织。

不同的Page在MySQL中,都是16KB,同一文件的page使用双向链表组织起来。而数据都保存在page中,以链表的形式组织在page中。
如果有主键,MySQL会按照主键给我们的数据进行排序。
为什么进行排序呢?
插入数据时,排序的目的是为了优化查询效率。并且为B+数的结构做准备。
举个例子:
如果不是有序,如果一个数据不在表中,查询时,需要将每一个数据都查询。
如果是有序的,查询到大于当前值,还没找到,说明不存在。后面就不需要继续找了。
但是,当数据量很大时,说明,一个page中保存的数据量很多。而数据在page中是以链表的形式组织的。查找数据时,一定也是线性查找。比如:数据保存在很后面,效率也很低。
于是:MySQL在page中增加了一个类似于目录的结构,来将数据链表分成多段。目录结构中保存的是该段链表中的最小Key值和该结点的地址。如下:

于是在单个page中查找某个值时,先查询目录,找到对应链表段,再遍历链表段,找到数据。这样会大大提高效率。
比如:上面数据,查找id=5的数据。先在目录中查找,找到目录key值等于4的后,找到链表地址,遍历该段链表,即可找到5.寻找次数是4次。而如果没有目录,直接遍历链表,查找的次数是5次。但是由于上面的例子数据量不是很大,当数据量很大,目录跨度很大时,效率会有明显的提高。
3.2.2 多page的情况
MySQL中,Page的大小是固定的16KB。当一个文件数据很大时,需要由多个Page来构成。同一文件的多个Page使用双向链表组织起来。

在单表不断被插入的情况,MySQL会在一个Page容量不足的情况下,自动开辟新的Page来保存新的数据,然后通过指针方式,将所有page组织起来。
这样我们查找某个数据时,需要遍历整个双向链表,并且每一个page还需要遍历。
虽然遍历一个page的效率有所提高,但是,遍历整个链表,并且需要将每一个遍历的page从磁盘加载到内存,这也就意味着依旧需要进行大量的IO。这样会效率仍然会收到影响。
于是按照上面的思想,MySQL对每一个Page也添加了一个目录。
- 使用一个page里面保存一个目录,来指向双向链表的某一个page,并且里面保存指向page中最小的键值。
- 该page 中不保存数据信息,只保存目录。目录保存的是管理的page的地址和管理page中的最小键值。
- 和双向链表page里的目录不同的是,这个目录管理的是管理的级别是整个page。而双向链表中page的目录管理的级别是链表的结点。
于是有了下面的结构:

存在一个目录页来管理保存数据的page。先在目录页中比较,找到需要访问的保存数据的page,通过目录保存的指针找到保存数据的page。在在page中寻找数据。
但是当文件数据的page过多时,也就是双向链表过长时。管理双向链表的目录页也会过长。于是,可以通过增加了目录页来管理下一层的目录页,如此循环。
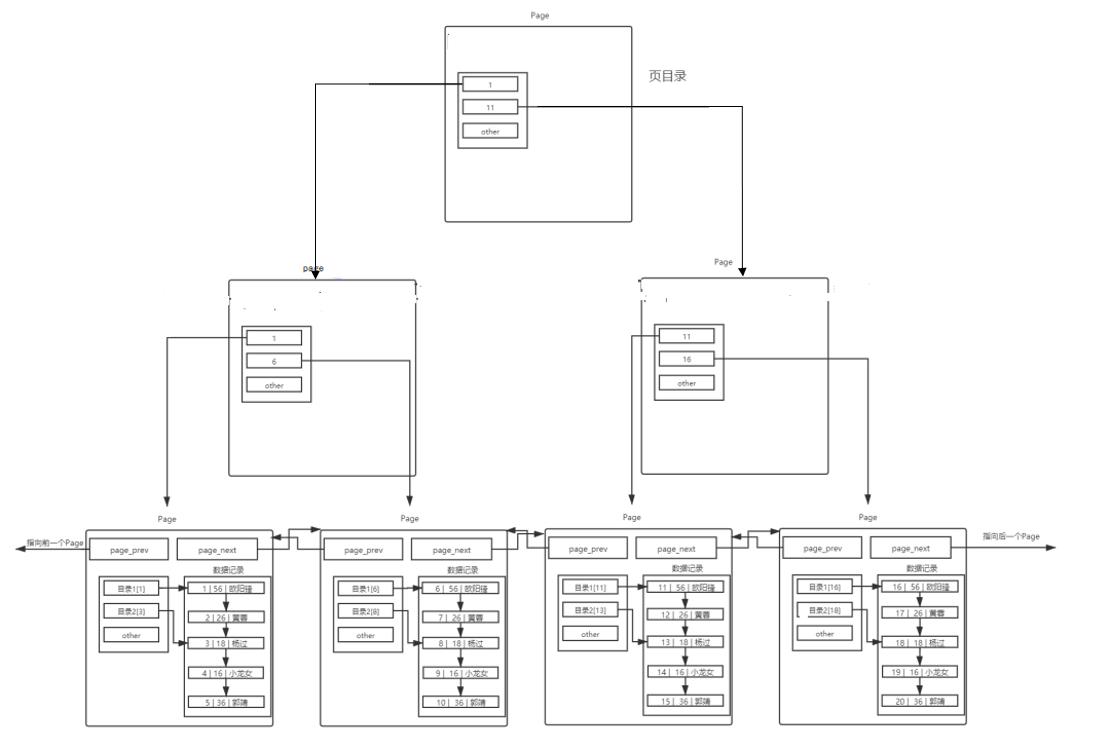
从上面可以看出,索引保存数据的结构采用的是B+树。由于上面的例子数据量太少,看不出有什么明显的差别。当数据量很大,并且,当一个page中保存的目录很多时,效率会明显提高。
这样随便找一个id,需要查询的page数一定会减少,也就意味着IO的次数减少了。
简单介绍一下B+树:B+树是一个多叉平衡搜索树。B树概念和插入实现
- B+树一个结点可以保存多个数据,并且是有序的。
- 非叶子节点,数据保存的是一个个子节点中数据最小的键值和子节点的地址。
- 叶子节点保存数据,是真实的所有用户数据。
- 叶子结点以链表的形式连接起来。
由于一个结点保存的数据很多,并且是多叉的,可以使得B+树的高度很低。
总结:
- 索引整个结构中page分为目录页和数据页,目录页中只保存管理page最小的键值和地址。不保存数据。数据页保存数据。
- 查找时,自顶向下查找,只需要将部分的目录page加载到内存找到保存数据的page,即可完成查找。大大减少了IO。
为什么目录page不保存数据?
page大小固定,不保存数据可以更多的保存目录信息,那说明一个目录page可以管理更多的page。使得树的高度变低。进行IO的次数变少。
怎么减少的IO?
数据在磁盘中以B+树的形式保存,每次只需要加载一个结点到内存,即可找到下一层的的page,直到最后找到叶子结点。
这样IO的次数最多是树的高度次,由于B+树的高度低,所以IO的次数会变少。
使用其它数据结构来管理数据行不行?
行肯定是行,但是,会大大的增加IO的次数,导致效率降低。
如果用链表,线性遍历,IO次数多。
用二叉搜索树,二叉搜索树由退化问题,插入有序,会退化成线性结构。
用红黑树或者AVL树,虽然查找的效率很高。但是由于是二叉树。树的高度也会很高。导致IO的次数页会增加。
用哈希表,虽然查找的效率为O(1),但是当哈希从都过多,一个桶中的链会比较长,效率也会降低。并且哈希桶不方便模糊匹配和范围查找。
但是,官方索引实现方式中,MySQL是支持哈希的,不过innodb和MyISAM不支持。
B树,非叶子结点也保存了数据,高度会有所增高。也只结点没有相连,不方便进行范围查找。
B+树非叶子结点不保存数据,可以使得管理的页变多,树的高度降低,IO次数变少。叶子结点相连,方便范围查找。
说明:
MySQL每次和磁盘交互大小是一个Page,当查找到数据,将数据拿到buffer pool中后,也会将其组织成B+树的形式。可以理解是,为了方便查找。
步骤:
用户查询数据,将磁盘B+树的结点拿到内存中,查找下一个结点,直到找到数据(叶子系结点)。
数据拿到内存(buffer pool)后,可能会有多个page。MySQL也会将其再buffer pool中组织成B+树。
注意:用户查询数据也不一定是将数据全部加载到内存中,是需要多少加载多少。
3.3 什么是索引
MySQL是管理用户数据的软件,数据保存在磁盘中。MySQL增删查改数据需要将数据拿到内存中,需要进行IO。而MySQL和磁盘每次交互的大小是一个page(16KB)。当数据量很大时,会导致IO次数变得很多,效率会降低。
索引是MySQL为了提高查询数据效率的一种方式。
实现是以page大小为结点构建一颗B+树,叶子结点保存数据,非叶子结点保存孩子结点的地址和最小键值,也只结点组织成了链表形式。
B+树的整体优势是,高度低,IO次数少。叶子结点组织成链表形式,方便范围查找。
四.聚簇索引和非聚簇索引
4.1 非聚簇索引
非聚簇索引:数据文件和索引文件分离。典型代表是MyISAM存储引擎。
MyISAM:同样是用B+树作为索引结构。叶子结点保存的是数据的地址或者路径。下图为MyISAM的主索引,col1为主键:
用主键建立的索引为主索引。

通过查询B+树,最终得到数据的地址或者路径。再通过地址或者路径找到数据。
使用MyISAM存储引擎建立一张表:

当然,可能用户在建立表是没有设定主键,并且,使用其它信息列建立索引。这种缩影可以叫做辅助索引。
MyISAM的辅助索引和主索引建立没有差别,主要差别是主索引保存的键值不能重复。辅助索引保存的键值可以重复。
下图是以Col2建立的辅助索引。

4.2 聚簇索引
聚簇索引:数据文件和索引文件是一个文件。典型是innodb存储引擎。
Innodb,使用的是B+树作为索引结构,叶子结点保存的就是数据。
下图是以主键建立的索引结构,称为主索引。

通过查询B+树,找到叶子结点就找到了数据。
用innodb存储引擎创建一张表:

innodb同样可以不使用主键建立表,也叫做辅助索引。但是,innodb的辅助索引叶子结点保存的是对应主键值。
查找数据向通过辅助索引找到主键值,再通过主键值,在主索引中找到数据。
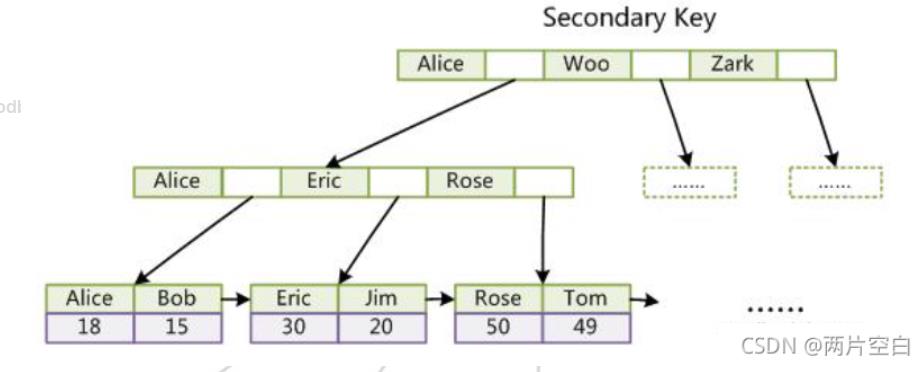
为什么辅助索引不给叶子结点也赋上数据呢?
原因是太浪费空间了。并且修改数据,需要修改全部索引数据。
说明:Innodb要求表中必须有主键,因为Innodb索引文件(数据文件),最后必须按照主键来找到是数据。如果用户没有显示设置主键,MySQL会自动选择一个可以唯一标识数据记录的列作为主键,比如:自增字段。如果不存在这种列,MySQL会为Innodb表自动生成一个隐含字段作为主键。这个字段占6字节,类型为长整型。
五.索引操作
索引分为:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引 (fulltext)
5.1 创建主索引
主要是设置主键。
- 第一种方式
在创建表时,在字段后面,直接加上primary key。
create table test2( id int primary key, name varchar(20));- 第二种方式
在创建表时,指定某列或者某几列为主键。
create table test3( id int, name varchar(20), primary key(id));- 第三种方式
创建表后增加主键。
create table test4( id int, name varchar(20));
alter table test4 add primary key(id);主键索引特点:
- 一个表中,最多有一个主键索引,当然可以使用复合主键。一个表中主键只能有一个。
- 主键索引效率高。
- 创建主键索引列不能为空,不能重复。
- 主键索引基本上是int类型。
5.2 唯一键索引创建
主要是创建唯一键。
- 第一种方式
在创建表时,给字段加上unique属性。
create table test5( id int primary key, name varchar(20) unique);- 第二种方式
在创建表时,指定某列或者某几列为唯一键。
create table test6( id int primary key, name varchar(20), unique (name));- 第三种方式
创建表后增加唯一键。
create table test7( id int primary key, name varchar(20));
alter table test7 add unique(name);唯一索引特点:
- 一个表中可以由多个唯一索引,因为唯一键可以由多个。
- 查询效率高
- 如果在某一列建立唯一索引,必须保证这一列数据不能重复。
5.3 普通索引
- 第一种方式
在创建表时,指定某列为普通索引
create table test8( id int primary key, name varchar(20), index(name));- 第二种方式
在创建表后,指定某一列为普通索引
create table test9( id int primary key, name varchar(20));
alter table test9 add index(name);- 第三种方式
创建表后,创建一个索引名为index_name的索引
create table test10( id int primary key, name varchar(20));
create index index_name on test10(name);普通索引特点:
- 一个表中可以有多个普通索引
- 普通索引,该列可以有重复值。
5.4 全文索引
对文章字段或者有大量文字的字段进行检索。
使用全文索引必须使用MyISAM存储引擎,默认支持英文,不支持中文。如果对中文进行全文索引,可以使用sphinx的中文版(coreseek)。
创建全文缩影:
在创建表时,指定某列为全文索引。
CREATE TABLE articles ( id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body)
)engine=MyISAM;插入一些值:

- 查询有没有包含database的语句
并没有使用全文索引,而是将数据全部遍历查找。

可以使用explain工具查看,是否使用索引。

- 使用全文索引


注意:上面的索引结构,在创建时,MySQL会自动创建对应索引结构。比如:创建表时,设置主键后,MySQL会自动创建主索引。唯一键创建后,MySQL会自动创建唯一索引。普通索引在创建后,也会自动创建等。

5.5 查询索引
-
show keys from 表名

- show index from 表名
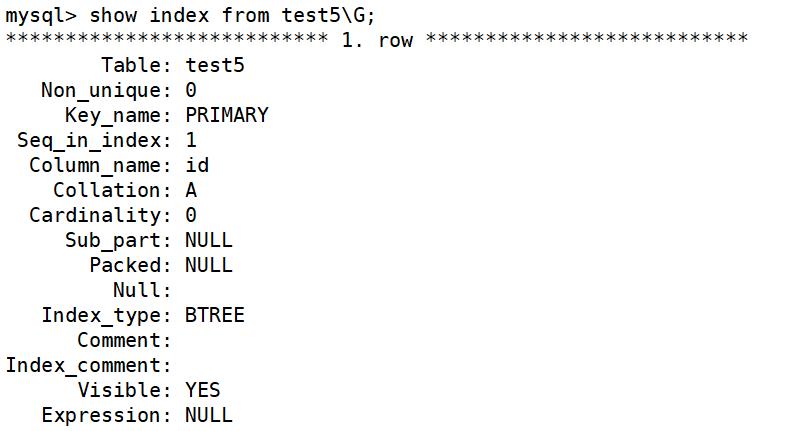
- desc 表名;


5.6 删除索引
- 删除主键索引
alter table 表名 drop primary key;删除主键。
- 删除其它索引
第一种方法:
alter table 表名 drop index 索引名;
索引名是show keys from 表名中的key_name 字段。
alter table test5 drop index name;第二种方法:
drop index 索引名 on 表名

5.7 索引创建原则
- 频繁查询的字段,应该创建索引。
- 唯一性差的字段,不应该单独创建索引,即使,频繁查询,查询耗时。
- 更新频繁的字段不应该建立索引。
- 不会出现在where语句中的字段,不应该建立索引。
索引提高了查询的效率,但是,降低了插入,删除和修改的效率。
六. 其它概念
- 复合索引
多个字段作为索引。
比如:主键,一个表中只能有一个。如果,设置多个主键,该表中也只有一个主键,是所有主键组合起来,充当这个表的主键。
在主索引中,关键字就会使所有主键的组合。

- 索引覆盖
使建立在复合主键的基础上。查询的字段正好在关键字里,不会再查询到也直接点,直接返回。相当于覆盖率往叶子系欸但查找的过程。
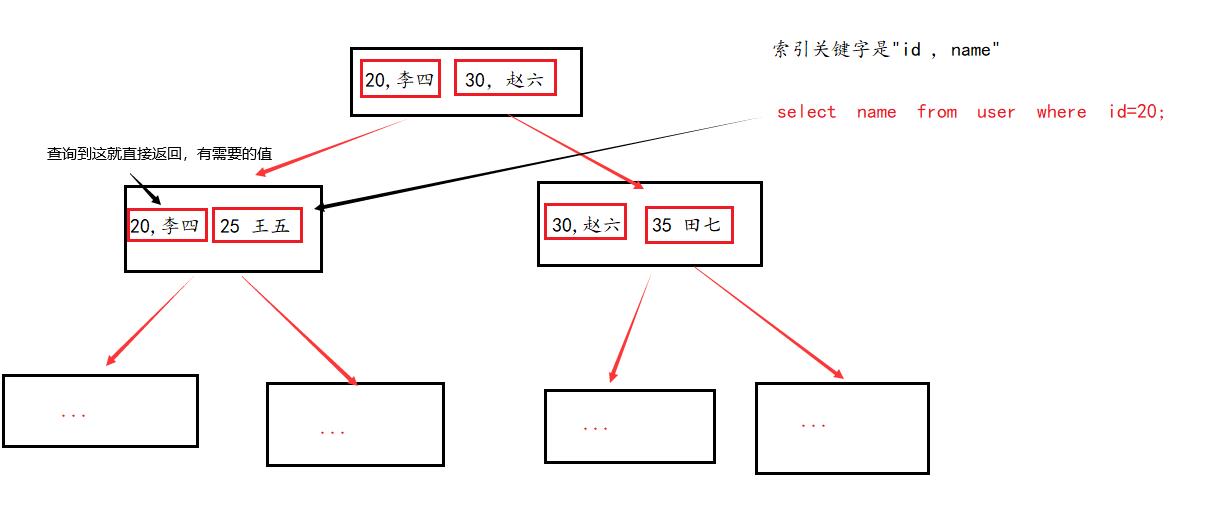
- 索引最左匹配原则
如果索引关键字是"id,name",如果使用select * from where name = '...',不能进行查找,因为name再关键字的右边。
以上是关于MySQL索引的主要内容,如果未能解决你的问题,请参考以下文章