模型训练常见问题及Aadm优化器调参记录
Posted sereasuesue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型训练常见问题及Aadm优化器调参记录相关的知识,希望对你有一定的参考价值。
优化器参数
torch.optim.Adam(model.parameters(), lr=lr ,eps=args.epsilon)
-
params (iterable) – iterable of parameters to optimize or dicts defining parameter groups
-
lr (float, optional) – learning rate (default: 1e-3)
-
betas (Tuple[float, float], optional) – coefficients used for computing running averages of gradient and its square (default: (0.9, 0.999))
-
eps (float, optional) – term added to the denominator to improve numerical stability (default: 1e-8)
-
weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
-
amsgrad (boolean, optional) – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond (default: False)
epsilon从0.1到1e-06,测试auc从0.6到0.9太可怕了,
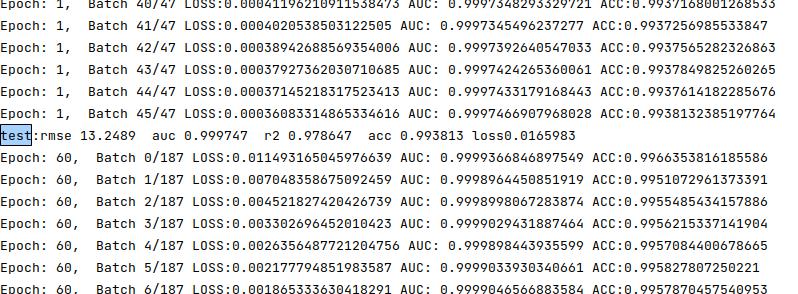
torch.optim.Adam(model.parameters(), lr=lr,weight_decay=0.0005)
加入weight_decay又到0.68附近
去掉weight_decay到测试的到0.88,训练集还在升高还往上升肯定有问题
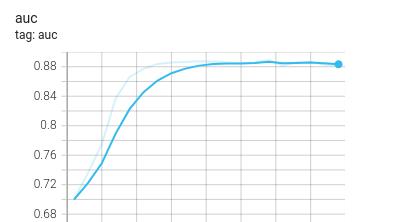
自适应优化器Adam还需加learning-rate decay
自适应优化器Adam还需加learning-rate decay吗? - 知乎
作者说加了lr decay的Adam还是有效提升了模型的表现。
但这只是在它的实验里进行了说明,并没有从理论上进行证明。因此不能说有定论,但是若你的模型结果极不稳定的问题,loss会抖动特别厉害,不妨尝试一下加个lr decay试一试。
如何加
torch中有很多进行lr decay的方式,这里给一个ExponentialLR API 的demo代码,就是这样就好了。
ExponentialLR原理: decayed_lr = lr * decay_rate ^ (global_step / decay_steps)
my_optim = Adam(model.parameters, lr)
decayRate = 0.96
my_lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer=my_optim, gamma=decayRate)
for e in epochs:
train_epoch()
my_optim.step()
valid_epoch()
my_lr_scheduler.step()学习率衰减策略
优化器NoamOpt
我们选择Adam[1]作为优化器,其参数为
 和
和 . 根据以下公式,我们在训练过程中改变了学习率:

在预热中随步数线性地增加学习速率,并且此后与步数的反平方根成比例地减小它。我们设置预热步数为4000。
注意:这部分非常重要,需要这种设置训练模型。
class NoamOpt:
"Optim wrapper that implements rate."
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"Implement `lrate` above"
if step is None:
step = self._step
return self.factor * \\
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))当前模型在不同模型大小和超参数的情况下的曲线示例。
# Three settings of the lrate hyperparameters.
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])
None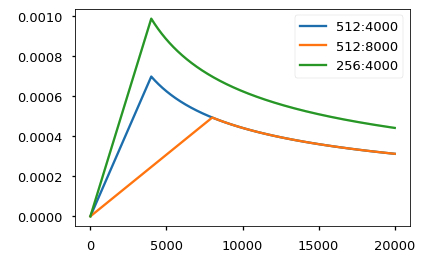
步数为4000是指,我使用时候设置为多大合适呢
loss为负
可能的原因:数据为归一化
网络中的:
self.softmax = nn.Softmax(dim=1)
改为:
self.softmax = nn.LogSoftmax(dim=1)
测试集AUC高于训练集AUC
感觉这个回答似乎有些道理,我的数据集划分的时候可能没有随机打乱
以上是关于模型训练常见问题及Aadm优化器调参记录的主要内容,如果未能解决你的问题,请参考以下文章