Kyligence:Cube优化器
Posted 卖山楂啦prss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kyligence:Cube优化器相关的知识,希望对你有一定的参考价值。
作者:Kyligence
链接:Kyligence KAP2.4新特性:Cube优化器
来源:知乎
KAP2.4新特性之Cube优化器:基于数据特性与业务常用SQL样例,可以一键输出Cube优化设置,帮助分析师快速上手Cube的设计与优化。
什么是Cube
Cube是数据仓库中一个经典的概念。数据仓库作为一种数据环境,具有面向分析、提供企业决策支持的重要作用。而在数据仓库中,多维数据模型能够满足大多数企业的数据分析需求——它提供了多角度多层次的分析应用,比如基于时间维度、地域维度等构建的销售星形模型、雪花模型,可以实现在各时间维度和地域维度的交叉查询,以及基于时间维度和地域维度的细分。
数据立方体(Data Cube)是多维模型的一个形象的说法。Cube本身只有三维,但多维模型不仅限于三维模型,可以组合更多的维度。正是多个维度,甚至几十个维度的Cube,才能全面满足企业的复杂分析场景、上下钻取、切片切块等决策分析需求。
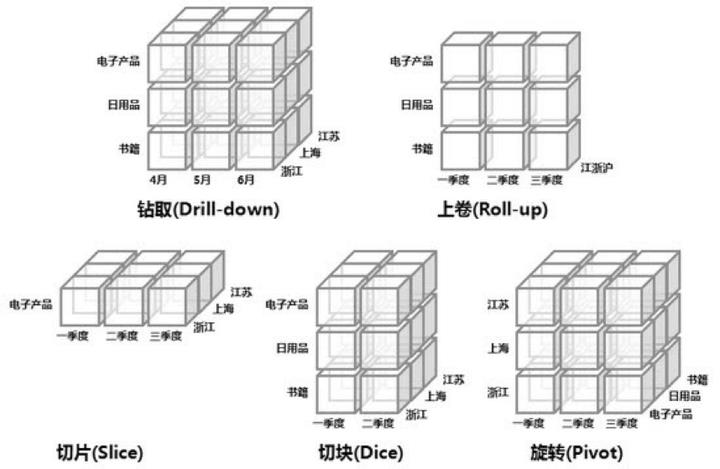
优化Cube,多维分析建模关键
Cube虽然能存储大量维度,但随着维度增加, Cube所需要的存储空间也会呈几何倍数增长。比如一个Cube中包含了N个维度,那么这N个维度将生成2N 个维度组合。这些成倍增长的维度组合中,有很多在Cube的生命周期里都不会被使用,同时由于维度组合数爆炸而带来的存储膨胀、构建时间冗长、甚至查询性能下降的弊病,都使Cube毁誉参半。
为了解决这个问题Kyligence Analytics Platform( KAP )提供了多种场景下,对Cube的优化设置,帮助用户筛选出真正会被使用到的 Cube维度组合,避免大量存储资源被无效的维度组合耗用,缩短Cube构建时间。优化设置包括衍生维度、聚合组、联合维度、层级维度、必要维度和Rowkey等。
结合不同的业务场景,合理的使用这些优化设置能够使数据建模事半功倍。根据这些优化设置的方法,业务分析师可以定制精确满足业务场景的Cube,避免Cube爆炸的问题。同时,KAP也提供了一键优化Cube的优化器,基于数据特性与常用SQL优化Cube,帮助分析师快速掌握优化Cube的关键。
基于数据特性的优化是指从模型检测的统计结果分析数据列之间的相关性;基于查询模式的优化主要指基于用户给定的常用SQL样例,分析数据列之间在SQL中呈现的相关性。综合两者的因素寻找可以做为层级维度、联合维度、必要维度的维度组,以及调整Rowkey顺序。
使用优化器,提升分析师生产力
Cube优化器对分析师非常友好,学习门槛低、上手快、使用方便。 优化器主要用于Cube设计的步骤,在使用前需要有一个已经设计好的数据模型。
在保存模型时,会看到默认勾选的模型检测功能,代表在保存时触发模型检测功能。一般在合适的资源环境下,模型检测都能在十几分钟内结束。
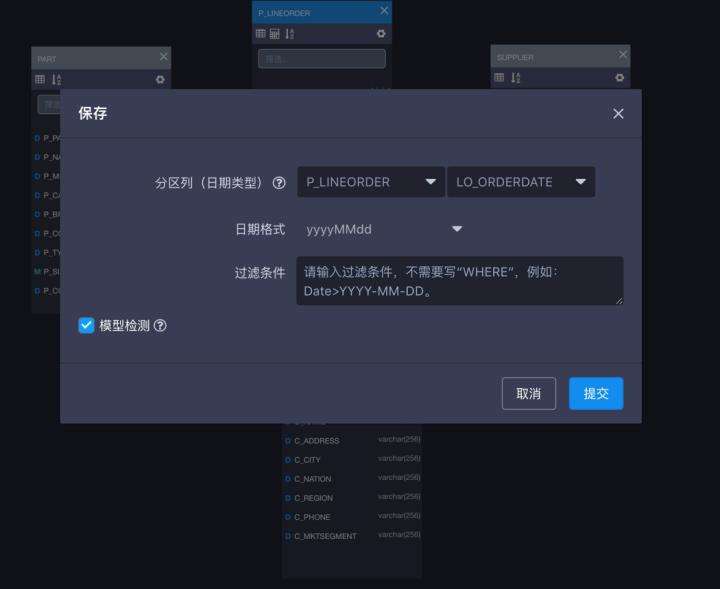
添加一个Cube。在Cube设计页可以看到关于Cube优化器的使用前提。如果此时模型检测已经完成,则检测结果返回如下。模型检测是Cube优化器一个非常重要的前置条件,一方面确保了模型设计的基本正确,另一方面对模型进行了充分的统计分析。
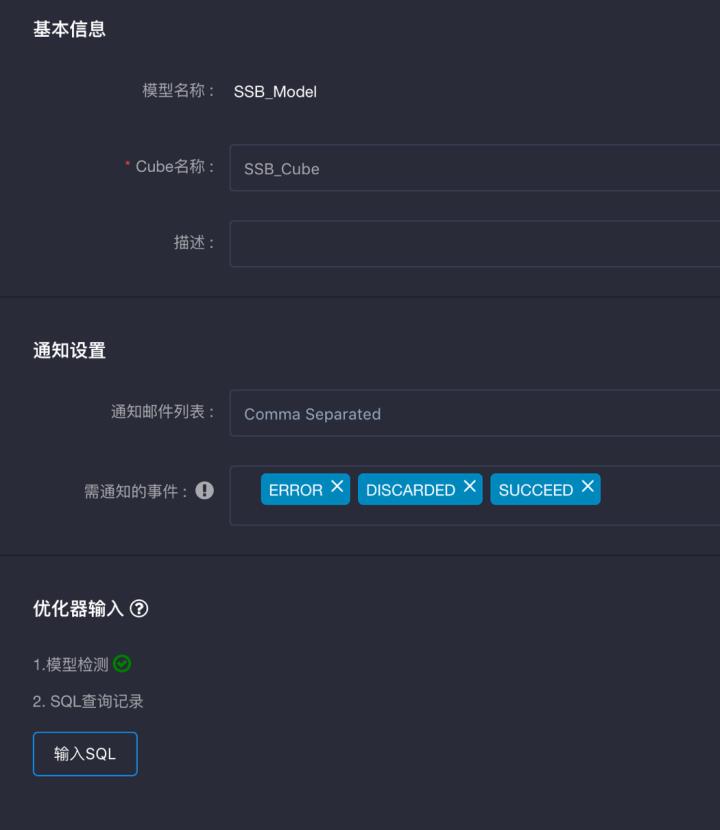
在本页也可以输入常用的查询SQL。这一特性帮助Cube优化器更好的参考业务查询中隐含的商业逻辑,有效提高Cube对业务的贴合程度。
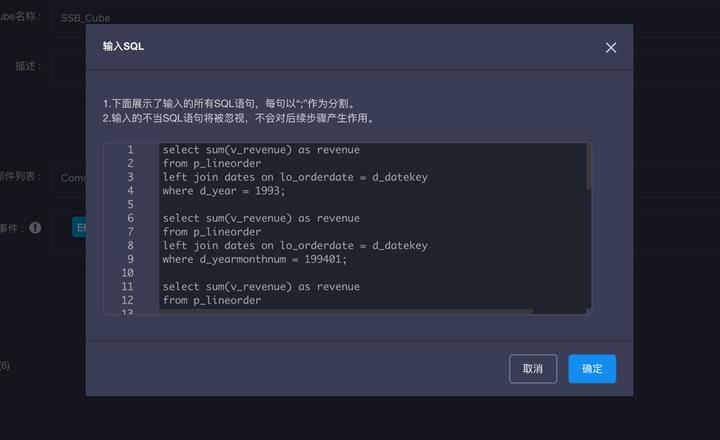
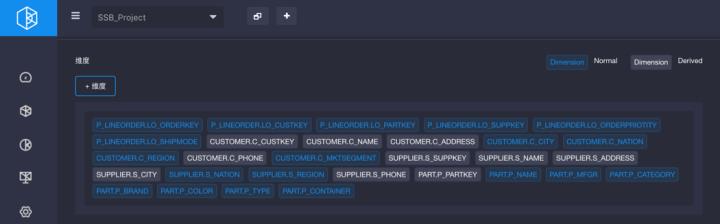
下一步,进入维度设计。单击“添加维度”按钮,可以勾选需要的Cube维度。勾选后默认的维度类型为Cube优化器的推荐结果,可以根据业务场景的差别而修改。完成后如下图,此时聚合组中还没有任何优化设置。
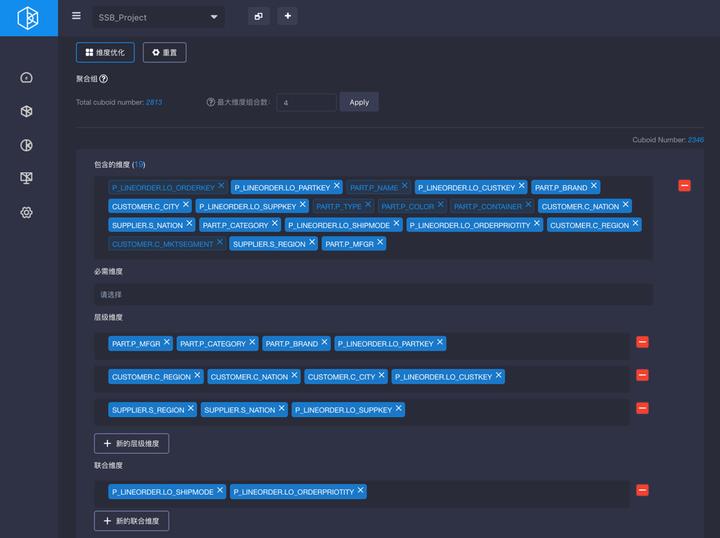
选好维度后,可以开始优化聚合组。有了Cube优化器之后,点击“优化维度”,可以直接输出聚合组的推荐优化设置。除了常规的必需维度,层级维度,联合维度之外,还包含Rowkey编码的推荐与排序,以及最大维度组合数的推荐值。
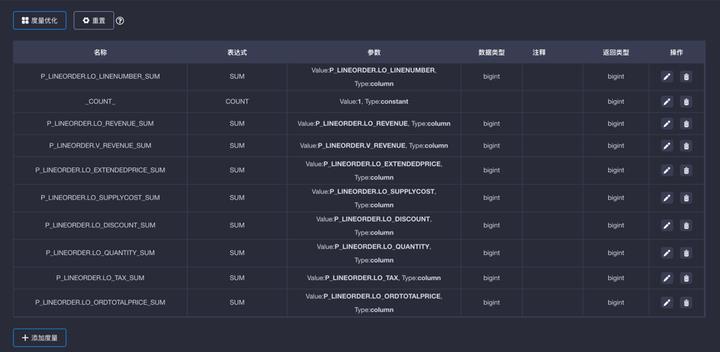
如果没有额外的优化需求,维度优化的部分就已经可以结束。点击“下一步”后,进入度量编辑。度量编辑页也有自动的“优化度量”与手工“添加度量”,方便分析师根据业务场景进行调整。
后续的Cube设计步骤与一般的编辑无差。获取更多细节请参考对应版本的产品手册。(http://docs.kyligence.io)
优化器小结
优化器主要对原始数据的数据特性和用户的查询模式进行分析,根据Cube调优的最佳实践,推荐出优化后的Cube设计。原理上,Cube优化器同时考虑了基于数据特性的优化和基于查询需求的优化。
- 基于数据特性的优化:从模型检测的统计结果分析数据列之间的相关性,寻找可以做为层级维度、联合维度、必要维度的维度组,以及Rowkey顺序。
- 基于查询模式的优化:基于用户给定的查询样例SQL,分析数据列之间在SQL中呈现的相关性,寻找可以做为层级维度、联合维度、必要维度的维度组,以及Rowkey顺序。
Cube优化器将Cube推向了智能优化的方向,可高效地提升Cube设计与加速Cube构建,是分析师设计多维模型的一把利器。
关于Kyligence Analytics Platform (KAP)
KAP是Kyligence提供的基于Apache Kylin的下一代企业级数据仓库及商务智能大数据分析平台,Kyligence是由首个来自中国的Apache软件基金会顶级开源项目Apache Kylin核心团队组建的数据科技公司。KAP支持超大数据集上的亚秒级查询分析,提供互联网级的高并发能力,赋能分析师以行业标准数据仓库与商业智能实施方法论架构基于Hadoop的数据仓库解决方案。从私有部署到云计算平台,都能使用户在超大规模数据集上获得极速的洞察能力,以释放数据价值,驱动业务增长。
以上是关于Kyligence:Cube优化器的主要内容,如果未能解决你的问题,请参考以下文章