基于perf + 火焰图定位Postgres数据库性能问题
Posted 丶Summer ~Z
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于perf + 火焰图定位Postgres数据库性能问题相关的知识,希望对你有一定的参考价值。
目 录
注: 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
Flame Graphs地址,点击前往
内存泄漏(增长)火焰图分析,点击前往
基于perf + 火焰图定位Postgres数据库性能问题
Linux 性能监测工具Perf
Perf工具可用来对软件进行优化,包括算法优化(空间复杂度、时间复杂度)和代码优化(提高执行速度、减少内存占用)。还可以评估程序对硬件资源的使用情况,例如各级cache的访问次数,各级cache的丢失次数、流水线停顿周期、前端总线访问次数等。也可以评估程序对操作系统资源的使用情况,系统调用次数、上下文切换次数、任务迁移次数等。
通过perf,应用程序可以利用PMU、tracepoint和内核中的计数器来进行性能统计。它不但可以分析应用程序的性能问题(per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用程序和内核,从而全面理解应用程序中的性能瓶颈。
CentOS平台上安装 Perf
安装方法:sudo yum install perf
perf命令简要介绍
1、perf的使用方法
perf --help之后可以看到perf的二级命令。
[postgres@local104:~]$ perf --help
usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS]
The most commonly used perf commands are:
annotate Read perf.data (created by perf record) and display annotated code
archive Create archive with object files with build-ids found in perf.data file
bench General framework for benchmark suites
buildid-cache Manage build-id cache.
buildid-list List the buildids in a perf.data file
c2c Shared Data C2C/HITM Analyzer.
config Get and set variables in a configuration file.
data Data file related processing
diff Read perf.data files and display the differential profile
evlist List the event names in a perf.data file
ftrace simple wrapper for kernel's ftrace functionality
inject Filter to augment the events stream with additional information
kallsyms Searches running kernel for symbols
kmem Tool to trace/measure kernel memory properties
kvm Tool to trace/measure kvm guest os
list List all symbolic event types
lock Analyze lock events
mem Profile memory accesses
record Run a command and record its profile into perf.data
report Read perf.data (created by perf record) and display the profile
sched Tool to trace/measure scheduler properties (latencies)
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics
test Runs sanity tests.
timechart Tool to visualize total system behavior during a workload
top System profiling tool.
version display the version of perf binary
probe Define new dynamic tracepoints
trace strace inspired tool
See 'perf help COMMAND' for more information on a specific command.
|
|
|
|---|---|
| annotate | 解析perf record生成的perf.data文件,显示被注释的代码 |
| archive | 根据perf.data文件中的build-id将相关的目标文件打包。利方便在其他机器分析。 |
| bench | perf中内置的benchmark,目前包括两套针对调度器和内存管理子系统的benchmark |
| buildid-cache | 管理buildid缓存 |
| buildid-list | 列出perf.data文件中记录的所有buildid。 |
| c2c | 共享数据 C2C/HITM 分析器。 |
| config | 在配置文件中获取和设置变量。 |
| data | 将perf.data文件转换成其他格式 |
| diff | 读取多个perf.data文件,且给出差异分析。 |
| evlist | 列出 perf.data 文件中的事件名称 |
| ftrace | 该命令是内核 ftrace 功能的简单包装。 它目前仅支持单线程跟踪,并且只读取文本中的 trace_pipe,然后将其写入标准输出 |
| inject | 该工具读取perf record工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。 |
| kallsyms | 在运行的内核 kallsyms 文件中搜索给定符号并打印有关它的信息,包括 DSO、kallsyms 开始/结束地址和 ELF 中的地址,kallsyms 符号表(用于模块中的符号) |
| kmem | 针对内核内存(slab)子系统进行追踪测量的工具 |
| kvm | 用来追踪测试运行在KVM虚拟机上的Guest OS。 |
| list | 此命令显示可以在各种 perf 命令中使用 -e 选项选择的符号事件类型。 |
| lock | 该命令分析各种锁行为和统计信息。 |
| mem | “perf mem record”运行该命令并从中收集内存操作数据到 perf.data 文件中 |
record | 运行一个命令并从中收集性能计数器写入 perf.data文件中 |
report | 此命令显示通过 perf record 记录的性能计数器配置文件perf.data信息 |
| sched | 针对调度器子系统的分析工具。 |
script | 读取 perf.data(由 perf 记录创建)并显示跟踪输出 |
stat | 运行某个命令,并收集性能计数器统计信息,包括CPI、Cache丢失率等。 |
| test | perf对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持perf的所有功能。 |
| timechart | 针对测试期间系统行为进行可视化的工具 |
top | 类似于linux的top命令,对系统性能进行实时分析。 |
| version | 显示工具的版本 |
| probe | 定义新的动态跟踪点。 |
| trace | 此命令将显示与目标关联的事件,最初是系统调用,但会显示其他系统事件,如页面错误、任务生命周期事件、调度事件等。 |
- 全局性概况:
perf list查看当前系统支持的性能事件;perf bench对系统性能进行摸底,(如IPC, message or pipe, memcpy);perf test对系统进行健全性测试;perf stat对全局性能进行统计;
- 全局细节:
perf top可以实时查看当前系统进程函数占用率情况;perf probe可以自定义动态事件;
- 特定功能分析:
perf kmem针对slab子系统性能分析;perf kvm针对kvm虚拟化分析;perf lock分析锁性能;perf mem分析内存slab性能;perf sched分析内核调度器性能;perf trace记录系统调用轨迹;
常用命令使用
perf list列出所有采样事件
[postgres@local104:~]$ sudo perf list
List of pre-defined events (to be used in -e):
ref-cycles [Hardware event]
alignment-faults [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
ref-cycles OR cpu/ref-cycles/ [Kernel PMU event]
rNNN [Raw hardware event descriptor]
cpu/t1=v1[,t2=v2,t3 ...]/modifier [Raw hardware event descriptor]
(see 'man perf-list' on how to encode it)
mem:<addr>[/len][:access] [Hardware breakpoint]
block:block_bio_backmerge [Tracepoint event]
block:block_bio_bounce [Tracepoint event]
block:block_bio_complete [Tracepoint event]
block:block_bio_frontmerge [Tracepoint event]
block:block_bio_queue [Tracepoint event]
block:block_bio_remap [Tracepoint event]
block:block_dirty_buffer [Tracepoint event]
block:block_getrq [Tracepoint event]
block:block_plug [Tracepoint event]
block:block_rq_abort [Tracepoint event]
block:block_rq_complete [Tracepoint event]
block:block_rq_insert [Tracepoint event]
block:block_rq_issue [Tracepoint event]
block:block_rq_remap [Tracepoint event]
block:block_rq_requeue [Tracepoint event]
block:block_sleeprq [Tracepoint event]
block:block_split [Tracepoint event]
......
事件分为以下三类:
1)Hardware Event 是由 PMU 硬件产生的事件,比如 cache 命中,当您需要了解程序对硬件特性的使用情况时,便需要对这些事件进行采样;
2)Software Event 是内核软件产生的事件,比如进程切换,tick 数等 ;
3)Tracepoint event 是内核中的静态 tracepoint 所触发的事件,这些 tracepoint 用来判断程序运行期间内核的行为细节,比如 slab 分配器的分配次数等
perf stat概览程序的运行情况
面对一个问题程序,最好采用自顶向下的策略。先整体看看该程序运行时各种统计事件的大概,再针对某些方向深入细节。
Perf stat应该是最先使用的一个工具。它通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
测试用例test1.c:
#include <stdio.h>
void longa()
int i,j;
for(i = 0; i < 1000000; i++)
j=i; //am I silly or crazy? I feel boring and desperate.
void foo2()
int i;
for(i=0 ; i < 10; i++)
longa();
void foo1()
int i;
for(i = 0; i< 100; i++)
longa();
int main(void)
foo1();
foo2();
编译为可执行文件:
编译时指定-g将程序编译为debug版(带有符号表信息,应用程序的符号表用来将逻辑地址翻译成对应的函数和变量名)
对于内核代码的符号表,在编译内核时,使用CONFIG_KALLSYMS=y。 检查如下
# cat /boot/config-`uname -r` |grep CONFIG_KALLSYMS
CONFIG_KALLSYMS=y
CONFIG_KALLSYMS_ALL=y
gcc test1.c -g -o test1
sudo perf stat ./test1
Performance counter stats for './test1':
198.11 msec task-clock # 0.999 CPUs utilized
0 context-switches # 0.000 K/sec
4 cpu-migrations # 0.020 K/sec
116 page-faults # 0.586 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
0.198364754 seconds time elapsed
0.198382000 seconds user
0.000000000 seconds sys
下面看一下结果各项标签的含义:
task-clock: CPU 利用率,该值高,说明程序的多数时间花费在 CPU 计算上而非 IO。context-switches:程序在运行过程中上下文的切换次数cpu-migrations:程序在运行过程中发生的处理器迁移次数。Linux为了维持多个处理器的负载均衡,在特定条件下会将某个任务从一个CPU迁移到另一个CPU。page-faults:缺页异常的次数。当应用程序请求的页面尚未建立、请求的页面不在内存中,或者请求的页面虽然在内存中,但物理地址和虚拟地址的映射关系尚未建立时,都会触发一次缺页异常cycles:统计CPU周期数instructions:执行了多少条指令。IPC:是 Instructions/Cycles 的比值,该值越大越好,说明程序充分利用了处理器的特性。branches:遇到的分支指令数。branch-misses:预测失败的分支指令数。
perf record && perf report定位程序瓶颈
record常用选项如下:如需更多选项可通过(perf --help record查看)
-erecord指定PMU事件--filterevent事件过滤器-a记录所有CPU的事件-p记录指定pid进程的事件-o指定记录保存数据的文件名-g开启call-graph (默认fp)-C录取指定CPU的事件
report 常用选项:
-i导入的数据文件名称,如果没有则默认为perf.data--filterevent事件过滤器-g生成函数调用关系图(默认值是graph,表示使用树形图来展示)--sort从更高层面显示分类统计信息,比如: pid, symbol, parent, cpu,socket, srcline, weight, local_weight.
接下来以可执行程序test1演示上面两个命令的使用
- 查找热点函数:
sudo perf record -g -e cpu-clock ./test1(执行完之后生成对应的perf.data数据文件) sudo perf report查看生成的perf.data数据文件- 跟踪某个进程
perf record -e cpu-clock -g -p 26369 -- sleep 30跟踪进程号为26369的进程,采集30秒
[postgres@local99:~]$ sudo perf record -g -e cpu-clock ./test1
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0.029 MB perf.data (203 samples) ]
[postgres@local99:~]$ ls
benchmarksql-5.0 benchmarksql-5.0.tar.gz FlameGraph p2 perf.data test1
benchmarksql-5.0.bak depend p1 p3 Public test1.c
[postgres@local99:~]$ sudo perf report
Samples: 203 of event 'cpu-clock', Event count (approx.): 50750000
Children Self Command Shared Object Symbol
+ 100.00% 0.00% test1 libc-2.17.so [.] __libc_start_main
- 100.00% 0.00% test1 test1 [.] main
- main
- 91.09% foo1
longa
- 8.91% foo2
longa
+ 100.00% 99.51% test1 test1 [.] longa
+ 91.09% 0.00% test1 test1 [.] foo1
+ 8.91% 0.00% test1 test1 [.] foo2
0.49% 0.49% test1 [kernel.kallsyms] [k] run_timer_softirq
0.49% 0.00% test1 [kernel.kallsyms] [k] apic_timer_interrupt
0.49% 0.00% test1 [kernel.kallsyms] [k] smp_apic_timer_interrupt
0.49% 0.00% test1 [kernel.kallsyms] [k] irq_exit
0.49% 0.00% test1 [kernel.kallsyms] [k] do_softirq
0.49% 0.00% test1 [kernel.kallsyms] [k] call_softirq
0.49% 0.00% test1 [kernel.kallsyms] [k] __do_softirq
Symbol列[]中字符代表的含义如下:
[.]: user level[k]: kernel level[g]: guest kernel level (virtualization)[u]: guest os user space[H]: hypervisor
从上图可以看出main函数以及foo1和foo2函数各自所占的百分比,也可以进入热点函数longa
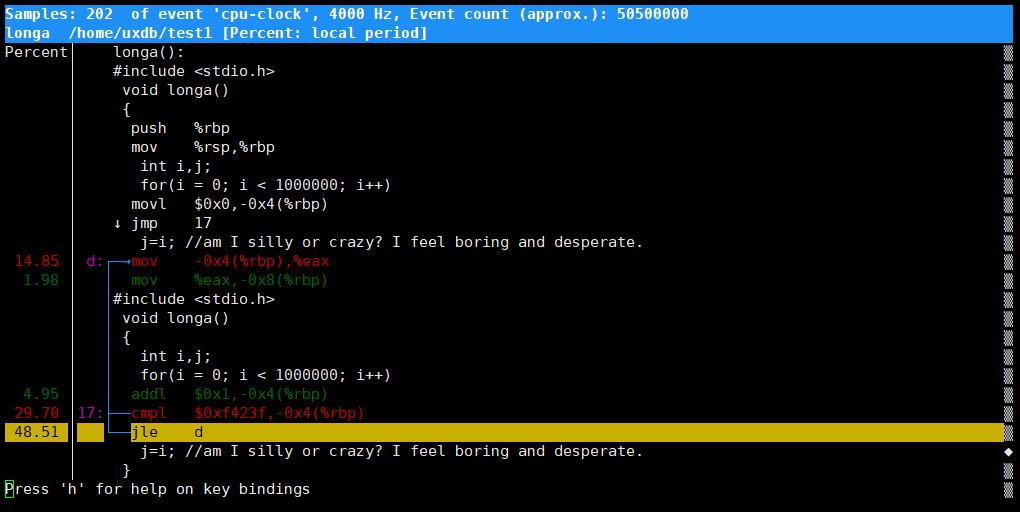
j=i赋值操作占用 16.83%
for 循环占用 83.16%
perf top监测系统性能
sudo perf top
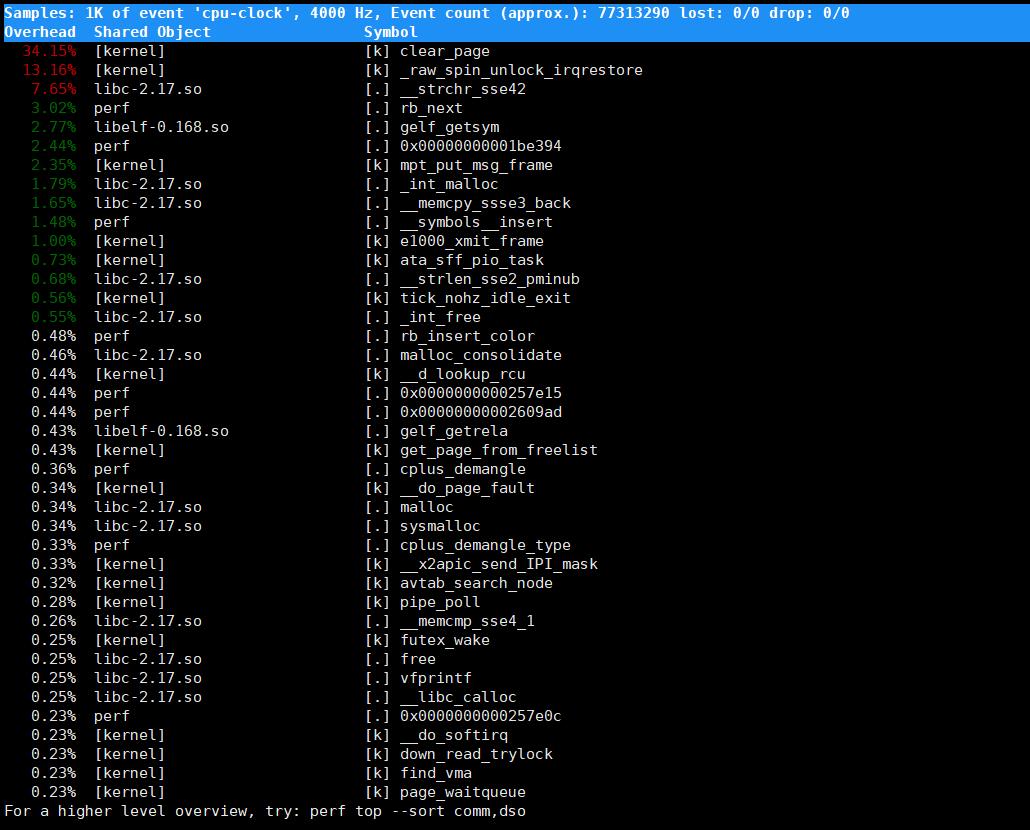
综上所述,可以看出top适合监控整个系统的性能,stat比较适合单个程序的性能分析,record/report更适合对程序进行更细粒度的分析。
注意:要跟踪完整的堆栈信息需要打开相关参数
- 有些编译优化项会忽略frame pointer,所以编译软件程序时必须指定
-fno-omit-frame-pointer、打开符号表的支持(gcc -g),开启annotate的支持(gcc -ggdb),才能跟踪完整的stack trace. - 编译内核时包含
CONFIG_FRAME_POINTER=y
可直接执行
vim /boot/config-`uname -r`
查看CONFIG_FRAME_POINTER值是否为Y
Perf + 火焰图分析Postgres 性能问题
数据库的性能优化是一个非常经典的话题,数据库的优化手段以及优化的角度也各不相同。例如,可以从OS内核、网络、块设备、编译器、文件系统、SQL、数据库参数、业务逻辑、源码等各个方面去进行优化。能够定位出数据库性能瓶颈问题对于优化具有事半功倍的效果。
源码编译安装数据库
- 使用perf工具监测PostgreSQL数据库的前提是需要编译DEBUG版本的数据库,目的是能够获取完备的跟踪信息,如符号表,call stack traces, 汇编指令等。因此必须在编译PostgreSQL时设置相应的编译开关,GCC需要增加
-g -O0 -ggdb -fno-omit-frame-pointer
[postgres@local99:~/src/postgresql-12.3]$./configure --prefix=/home/postgres/pg12.3 --enable-debug
[postgres@local99:~/src/postgresql-12.3]$vim src/Makefile.global
CFLAGS = -Wall -Wmissing-prototypes -Wpointer-arith -Wdeclaration-after-statement -Werror=vla -Wendif-labels -Wmissing-format-attribute -Wimplicit-fallthrough=3 -Wformat-security -fno-strict-aliasing -fwrapv -fexcess-precision=standa rd -Wno-format-truncation -g -O0 -ggdb -fno-omit-frame-pointer
make & makeinstall
- 确认Linux内核如下两个参数的值
CONFIG_KALLSYMS=y
CONFIG_FRAME_POINTER=y
几种性能问题分析的工具及使用方法
CPU FlameGraph用于查找程序执行的热点,找出性能瓶颈
采样跟踪
跟踪数据库跑tpcc过程中的两个进程,进行采样
- 安装并配置benchmarkSQL工具
下载benchmarksql-5.0.tar.gz包并解压,该工具包依赖jdk,因此在使用之前先检测是否安装jdk1.8
1、在~/benchmarksql-5.0/run下修改props.pg配置(先备份再修改)
vim props.pg
db=postgres //数据库类型,不需要更改
driver=org.postgresql.Driver //驱动,不需要更改
conn=jdbc:postgresql://localhost:5432/postgres
user=postgres //数据库用户名
password=1 //如上用户密码
warehouses=100 //仓库数量,每个warehouse大小大概是100MB,建议将数据库的大小设置为服务器物理内存的2-5倍
loadWorkers=10 //用于在数据库中初始化数据的加载进程数量
terminals=500 //终端数,即并发客户端数量,通常设置为CPU线程总数的2~6倍
runTxnsPerTerminal=0 //每个终端(terminal)运行的固定事务数量,该参数配置为非0值时,下面的runMins参数必须设置为0
runMins=15 //要测试的整体时间,单位为分钟,该值设置为非0值时,runTxnsPerTerminal参数必须设置为0。
limitTxnsPerMin=0 //每分钟事务总数限制
terminalWarehouseFixed=true //终端和仓库的绑定模式,设置为true时可以运行4.x兼容模式,意思为每个终端都有一个固定的仓库。设置为false时可以均匀的使用数据库整体配置。TPCC规定每个终端都必须有一个绑定的仓库,所以一般使用默认值true。
//下面五个值的总和必须等于100,默认值为:45, 43, 4, 4 & 4 ,与TPC-C测试定义的比例一致,实际操作过程中,可以调整比重来适应各种场景。
newOrderWeight=45
paymentWeight=43
orderStatusWeight=4
deliveryWeight=4
stockLevelWeight=4
resultDirectory=my_result_%tY-%tm-%td_%tH%tM%tS //测试数据生成目录,默认无需修改,默认生成在run目录下面,名字形如my_result_xxxx的文件夹。
osCollectorScript=./misc/os_collector_linux.py //操作系统性能收集脚本,默认无需修改,需要操作系统具备有python环境
osCollectorInterval=1 //操作系统收集操作间隔,默认为1秒
//osCollectorSSHAddr=user@dbhost //操作系统收集所对应的主机,如果对本机数据库进行测试,该参数保持注销即可,如果要对远程服务器进行测试,请填写用户名和主机名。
osCollectorDevices=net_eth0 blk_sda //操作系统中被收集服务器的网卡名称和磁盘名称
- 创建测试数据库实例
- 执行tpcc测试
[postgres@local99:~/benchmarksql-5.0/run]$ ./runDatabaseBuild.sh props.pg 初始化数据
[postgres@local99:~/benchmarksql-5.0/run]$ ./runBenchmark.sh props.pg 执行TPCC测试
- 收集性能统计数据
[postgres@local99:~]$ sudo perf stat
[sudo] password for postgres:
^C
Performance counter stats for 'system wide':
194,858.49 msec cpu-clock # 4.000 CPUs utilized
144,757 context-switches # 0.743 K/sec
13,878 cpu-migrations # 0.071 K/sec
30,431 page-faults # 0.156 K/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
48.715393817 seconds time elapsed
[postgres@local99:~]$
[postgres@local99:~]$ sudo perf stat -p 41426
^C
Performance counter stats for process id '41426':
664.91 msec task-clock # 0.009 CPUs utilized
4,692 context-switches # 0.007 M/sec
829 cpu-migrations # 0.001 M/sec
2,171 page-faults # 0.003 M/sec
<not supported> cycles
<not supported> instructions
<not supported> branches
<not supported> branch-misses
77.512187798 seconds time elapsed
[postgres@local99:~]$
- 采集数据
① TPCC执行期间执行ps afx | grep postgres,选取2个进程号
② 创建两个目录分别为p1,p2
③ 分别进入新创建的p1/p2目录下,运行sudo perf record -e cpu-clock -g -p pid -- sleep 840
-p指定进程号
-- sleep840 采集840秒和props.pg配置文件中的runMins指定的tpcc执行时间对应 - 分析采集数据
[postgres@local99:~/tpcctest/p1]$ sudo perf record -e cpu-clock -g -p 41424 -- sleep 840
[sudo] password for postgres:
[ perf record: Woken up 21 times to write data ]
[ perf record: Captured and wrote 5.626 MB perf.data (17111 samples) ]
[postgres@local99:~/tpcctest/p1]$ ls
sudo perf report -i perf.data
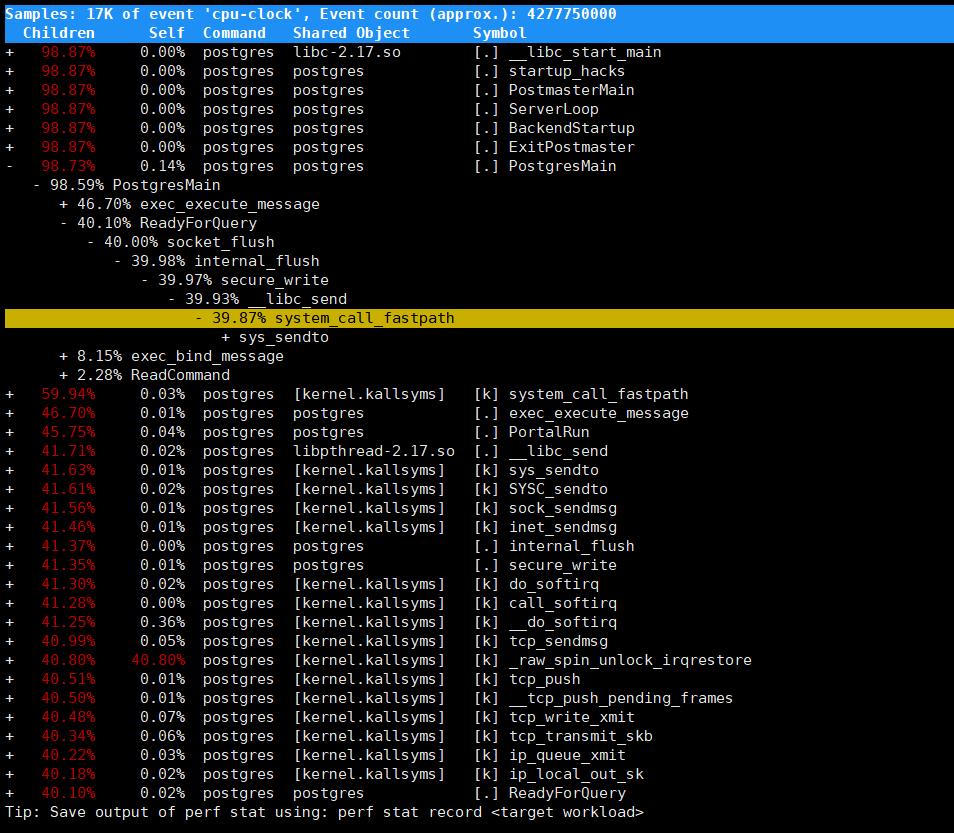
# 以树形结构显示函数调用关系
sudo perf report -n --stdio -i perf.data
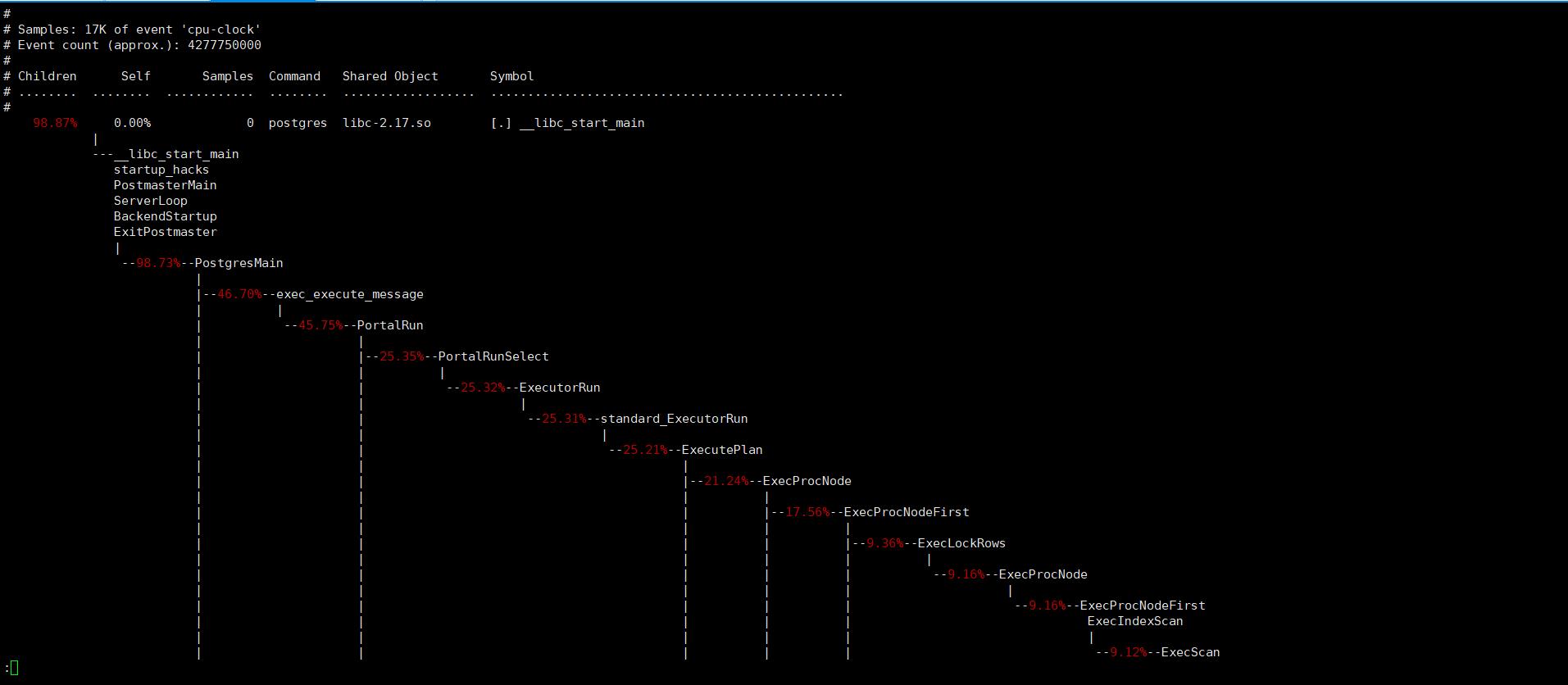
上面的操作可以查看函数调用执行占用cpu的比率
- 制作函数调用火焰图
制作火焰图的工具是Flame
Flame Graph项目仓库链接,点击前往
① 使用git克隆下载:
git clone https://github.com/brendangregg/FlameGraph.git
[postgres@local99:~]$ cd FlameGraph/
[postgres@local99:~/FlameGraph → master]$ ls
aix-perf.pl example-dtrace-stacks.txt flamegraph.pl record-test.sh stackcollapse-gdb.pl stackcollapse-ljp.awk stackcollapse-recursive.pl stackcollapse-wcp.pl
demos example-dtrace.svg jmaps stackcollapse-aix.pl stackcollapse-go.pl stackcollapse-perf.pl stackcollapse-sample.awk stackcollapse-xdebug.php
dev example-perf-stacks.txt.gz pkgsplit-perf.pl stackcollapse-bpftrace.pl stackcollapse-instruments.pl stackcollapse-perf-sched.awk stackcollapse-stap.pl test
difffolded.pl example-perf.svg range-perf.pl stackcollapse-chrome-tracing.py stackcollapse-java-exceptions.pl stackcollapse.pl stackcollapse-vsprof.pl test.sh
docs files.pl README.md stackcollapse-elfutils.pl stackcollapse-jstack.pl stackcollapse-pmc.pl stackcollapse-vtune.pl
[postgres@local99:~/FlameGraph → master]$
② 生成.svg图
## 折叠堆栈
[postgres@local99:~/tpcctest/p1]$ sudo perf script -i perf.data &> perf.unfold
[postgres@local99:~/tpcctest/p1]$ ls
perf.data perf.unfold
[postgres@local99:~/tpcctest/p1]$ sudo mv perf.unfold /home/postgres/FlameGraph/post1.unfold
## 用 stackcollapse-perf.pl 将 perf 解析出的内容 perf1.unfold 中的符号进行折叠
[postgres@local99:~/tpcctest/p1]$ cd /home/postgres/FlameGraph
[postgres@local99:~/FlameGraph → master]$ sudo ./stackcollapse-perf.pl post1.unfold &> post1.folded
## 生成火焰图
[postgres@local99:~/FlameGraph → master]$ sudo ./flamegraph.pl post1.folded > post1.svg
[postgres@local99:~/FlameGraph → master]$
TPCC结果值:
#POSTGRES
16:34:25,377 [Thread-17] INFO jTPCC : Term-00, Measured tpmC (NewOrders) = 26430.58
16:34:25,378 [Thread-17] INFO jTPCC : Term-00, Measured tpmTOTAL = 58685.63
16:34:25,378 [Thread-17] INFO jTPCC : Term-00, Session Start = 2021-09-29 16:19:25
16:34:25,378 [Thread-17] INFO jTPCC : Term-00, Session End = 2021-09-29 16:34:25
16:34:25,378 [Thread-17] INFO jTPCC : Term-00, Transaction Count = 880353
- 在浏览器中打开生成的.svg文件
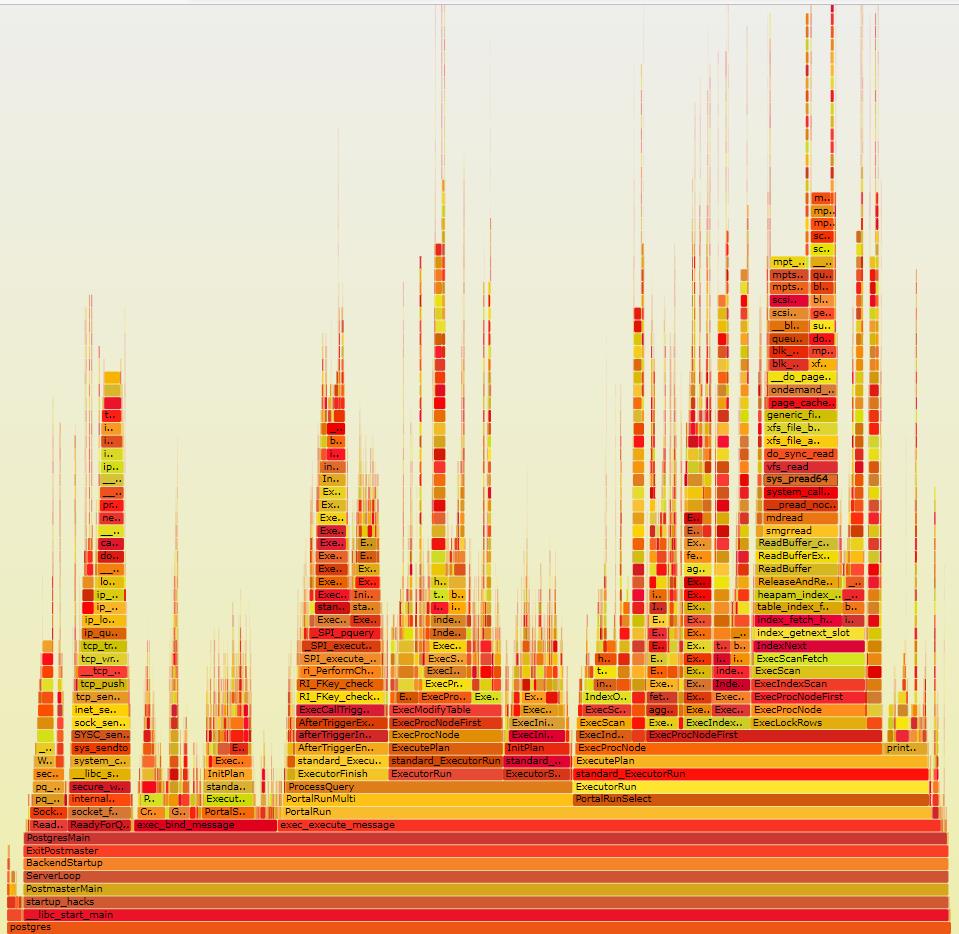
火焰图的含义:
y轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x轴表示抽样数,如果一个函数在x轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有"瓶颈"(plateaus),就表示该函数可能存在性能问题。
颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
Memory FlameGraph用于简单分析内存泄漏或者增长趋势
可参考内存泄漏(增长)火焰图分析,点击前往Differential FlameGraph用于性能Regression对比
该工具的介绍及使用可参考Differential Flame Graphs,点击前往
一般处理性能回退问题, 就要在修改前后或者不同时期和场景下的火焰图之间不断切换对比, 来找出问题所在。
Differential FlameGraph( 红蓝分叉火焰图)工具可用于比较不同场景下函数堆栈差异。
它的工作原理是这样的 :
- 抓取修改前的堆栈 profile1 文件
- 抓取修改后的堆栈 profile2 文件
- 使用 profile2 来生成火焰图. (这样栈帧的宽度就是以profile2 文件为基准的)
- 使用 “2-1” 的差异来对火焰图重新上色. 上色的原则是, 如果栈帧在 profile2 中出现出现的次数更多, 则标为红色, 否则标为蓝色. 色彩是根据修改前后的差异来填充的.
这样做的目的是, 同时使用了修改前后的 profile 文件进行对比, 在进行功能验证测试或者评估代码修改对性能的影响时,会非常有用. 新的火焰图是基于修改后的 profile 文件生成(所以栈帧的宽度仍然显示了当前的CPU消耗). 通过颜色的对比,就可以了解到系统性能差异的原因。
工具其他参数说明:
| 选项 | 描述 |
|---|---|
difffolded.pl -n | 这个选项会把两个profile文件中的数据规范化,使其能相互匹配上。如果你不这样做,抓取到所有栈的统计值肯定会不相同,因为抓取的时间和CPU负载都不同。这样的话,看上去要么就是一片红(负载增加),要么就是一片蓝(负载下降)。-n选项对第一个profile文件进行了平衡,这样你就可以得到完整红/蓝图谱 |
difffolded.pl -s | 这个选项会把16进制的地址删掉。 profiler时常会无法将地址转换为符号,这样的话栈里就会有16进制地址。如果这个地址在两个profile文件中不同,这两个栈就会认为是不同的栈,而实际上它们是相同的。遇到这样的问题就用-s选项搞定 |
flamegraph.pl --negate | 用于颠倒红/蓝配色 |
例如:以上面PostgreSQL数据库采集到的TCPP数据,经过stackcollapse-perf.pl折叠后的文件post1.folded调用difffolded.pl工具生成对应的差分火焰图
[postgres@local99:~/FlameGraph → master]$ ./difffolded.pl post1.folded post2.folded | ./flamegraph.pl > diff1.svg
以上是关于基于perf + 火焰图定位Postgres数据库性能问题的主要内容,如果未能解决你的问题,请参考以下文章 |
|---|