NoSQL介绍及MongoDB的安装及使用
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NoSQL介绍及MongoDB的安装及使用相关的知识,希望对你有一定的参考价值。
前言
本篇文章会介绍Nosql和关系型数据库之间的区别,了解NoSQL ,NoSQL数据库与关系型数 据库有什么不一样。对比关系型数据库理解 MongoDB,MongoDB安装及JAVA客户端使用 ,以及spring对Mongodb的支持。
NoSQL

最开始因为简单 快速 使用nosql,到现在的sql,不断的进化, 然后发觉sql并不能满足时,有兴起了nosql数据库
为什么需要NoSQL
- 现代网站服务,是超大规模和高并发的SNS类型的web2.0纯动态网站
- 传统关系型数据库遇到了性能、扩展瓶颈
- NoSQL数据库为了解决大规模数据集合、多重数据种类带来的挑战而产生
- 应用在大数据应用难题,包括超大规模数据的存储
为了性能 一直在努力,一直在寻找着解决方案。
四大类NoSQL数据库

对于不同的场景进行选择不同nosql数据库,包括我在项目中 进行大数据量数据分析,采用hbase是非常使用的,当然还有现在比较流行的clickhouse等。
如果 数据库表中 有大量的null值,在关系型数据库中非常占资源的,而如果采用列式存储方式换一个角度 ,没有就不存,对于结构要求不是很严格 采用列式存储是非常有效的。功能是有限的,例如id去查不方便去查。


功能不能像传统型数据库一样做到sql支持完整。
对于文档存储方式,数据结构要求不严,表的结构可以变化,查询性能要求不高。实现的方式 大部分存储方式是json格式,包括es 和 mongodb都是的, 都是自定义的一套操作语法。
mapreduce、全文检索实现方式不一样的,这都是es和mongdb不同的地方。
包括上面的 利用图结构相关算法的数据库 这个一般很少使用的数据库。在地图这些应该用到很多。
针对这些的排名情况。
DB-Engines Ranking - popularity ranking of database management systems
最高的还是oracle 我觉得得益于政府 大企业的使用, 其实 SQlite数据库来说,我觉得还是得益于android手机 确实还是比较火的。

包括其他的一些排行榜数据库

NoSQL与传统数据库对比

这在对比起来,因为方向不一样,所以 各自的特点不一样,包括 强一致性 和弱一致性,都是 为了提高某一部分的能力提高,因此才用的结构。 一级 二维和多维表 json格式等。提高存储,以及大数据量的问题,并且对于事务这些问题,因此都会分开 nosql 关系型数据库的概念。
这些一般关系型数据库的优点 其实就是nosql数据库的缺点,反之, 也是得益于存储结构导致的。
Mongo核心概念

- 面向集合文档的存储:适合存储Bson(json的扩展)形式的数据;
- 格式自由,数据格式不固定,生产环境下修改结构都可以不影响程序运行;
- 强大的查询语句,面向对象的查询语言,基本覆盖sql语言所有能力;
- 完整的索引支持,支持查询计划;
- 支持复制和自动故障转移;
- 支持二进制数据及大型对象(文件)的高效存储;
- 使用分片集群提升系统扩展性;
- 使用内存映射存储引擎,把磁盘的IO操作转换成为内存的操作;
主要和js语言很像,所以书写时也比较简单了。而且在互联网公司中应用是非常广泛的。
- 不需要事务及复杂join支持
- 新应用,需求会变,数据模型不确定,想快速迭代开发
- 要应对2000-3000以上的读写QPS(或更高)
- 要存储TB甚至PB级别数据
- 只要有一项需求满足就可以考虑
- 应用发展迅速,能快速水平扩展
- 匹配越多,选择MongoDB越合适
- 要求存储的数据不丢失
- 要求99.999%高可用
- 有大量的地理位置查询、文本查询
这都是为什么要使用mongdb 情况。
使用场景
- 游戏场景,使用 MongoDB 存储游戏用户信息,用户的装备、积分等直接以内嵌文档的形式存储, 方便查询、更新
- 物流场景,使用 MongoDB 存储订单信息,订单状态在运送过程中会不断更新,以MongoDB嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
- 社交场景,使用 MongoDB 存储存储用户信息,以及用户发表的朋友圈信息,通过地理位置索引 实现附近的人、地点等功能
- 物联网场景,使用 MongoDB 存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这 些信息进行多维度的分析
- 视频直播,使用 MongoDB 存储用户信息、礼物信息等
都是得益于mongodb的自带的优缺点导致的。
不适合使用MongoDB
基本概念
- 实例:系统上运行库的进程及节点集,一个实例可以有多个库
- 库:多个集合组成数据库,每个数据库都是完全独立的,有自己的用户、权限信息,独立的存储文件集
- 集合:即一组文档的集合,文档是存放的数据。集合内的文档结构可以不同
- 文档:MongoDB数据库的最小数据集单位,其基本概念为:多个键值对有序组合在一起的数据单元

很多文档进行逻辑分组。
与关系型数据库对比


在bson里面有内嵌文档 可以相当于类似面向对象类型。
- 文档(即对象)对应于许多编程语言中的本机数据类型
- 嵌入式文档和数组减少了对连接的需求
- 动态模式支持流畅的多态性
数据类型
Bson是JSON文档的二进制表示形式,它包含比JSON更多的数据类型。
MongoDB中,一个BSON文档最大大小为16M,文档嵌套的级别不超过100
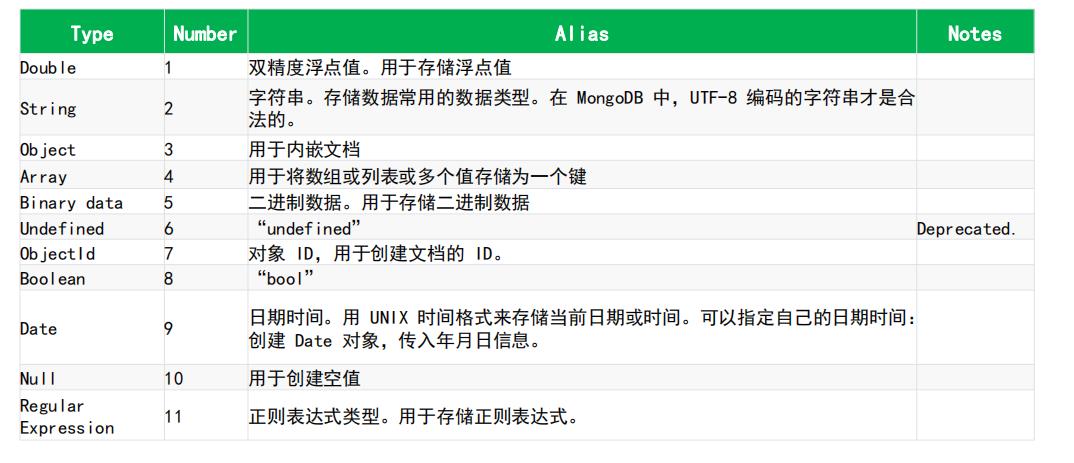

在mongodb中可以使用其他类型来存大对象 gridFS用来解除大块文件限制的问题

MongoDB安装
tgz方式安装
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-4.2.1.tgz
tar -vzxf mongodb-linux-x86_64-rhel70-4.2.1.tgz
mv mongodb-linux-x86_64-rhel70-4.2.1 /usr/local/mongodb
cd /usr/local/mongodbmkdir -p /usr/local/mongodb/logs /usr/local/mongodb/data # 创建目录备用
vim /usr/local/mongodb/logs/mongodb.log # 创建一个空日志文件即可
vim /usr/local/mongodb/bin/mongodb.conf # 创建MongoDB的配置文件# MongoDB的配置文件,mongod.conf
# 配置文件全部配置参考下面网址:
# http://docs.mongodb.org/manual/reference/configuration-options/
# 写入日志数据的位置
systemLog:
destination: file
logAppend: true
path: /usr/local/mongodb/logs/mongodb.log
# 存储数据的地点和方法
storage:
dbPath: /usr/local/mongodb/data
journal: enabled: true
# engine:
# wiredTiger:
# 进程如何运行
processManagement:
fork: true # 是否启用子进程在后台运行
pidFilePath: /usr/local/mongodb/mongod.pid # pidfile的位置
timeZoneInfo: /usr/share/zoneinfo
# 网络配置
net:
port: 27017 # 默认端口号
#bindIp: 127.0.0.1 # 设定ip地址白名单,此处我们注释掉为了方便学习
# 方便学习改为true,生产环境则使用白名单
bindIpAll: true # 是否允许所有的ip地址访问,默认是falsecd /usr/local/mongodb
sudo bin/mongod -f bin/mongodb.conf
# 通过制定配置文件来启动
# 通过kill命令关闭进程来关闭mongodbsudo service mongod start # 启动
sudo service mongod stop # 停止
sudo service mongod restart # 重启sudo tail -f /var/log/mongodb/mongod.log

sudo /usr/bin/mongod --help# 连接本地默认端口
sudo /usr/bin/mongo
# 连接远程
sudo /usr/bin/mongo -u <user> -p --host <host> --port 28015sudo /usr/bin/mongods --help
安装图形界面compass
- 64位Windows7以上的操作系统
- MongoDB3.6 以上
- Microsoft .NET Framework version 4.5以上
- 1. 到官网下载windows版本zip格式的安装包
- 2. 将zip文件移动到你想要放置的目录,解压zip文件到mongodb-compass目录
- 3. 进入mongodb-compass目录,双击MongoDBCompass.exe运行文件


使用MongoDB
./mongodb # 显示当前数据库
use dataBaseName # 如果dataBaseName不存在,在插入数据时将会创建数据库
show dbs # 显示当前实例中的数据库
db.dropDatabase() # 删除当前选择的库
db.createCollection("runoob") # 显式的创建runoob集合
show tables # 显示当前数据库中的集合信息
show collections
db.runoob.drop() # 删除runoob集合新建操作语法
db.collection.insertOne()
#插入单个文档
db.collection.insertMany() #插入多个文档
db.collection.insert()
#插入单条或多个文档- 自动创建不存在的集合、数据库,例如这里的inventory集合
- 如果不指定,自动生成主键_id及其值
- 写操作都是基于单个文档级别的原子操作
- 确认写操作级别,在分片集群中我们需要关注,目前忽略
db.collection.insert(
<document or array of documents>,
writeConcern: <document>,
ordered: <boolean>
)查询操作
# SELECT * FROM inventory WHERE item = "canvas"
db.inventory.find( item: "canvas" ).pretty()
# SELECT * FROM inventory WHERE status = "A" AND ( qty < 30 OR item LIKE "p%")
db.inventory.find(
status: "A",
$or: [ qty: $lt: 30 , item: /^p/ ]
)
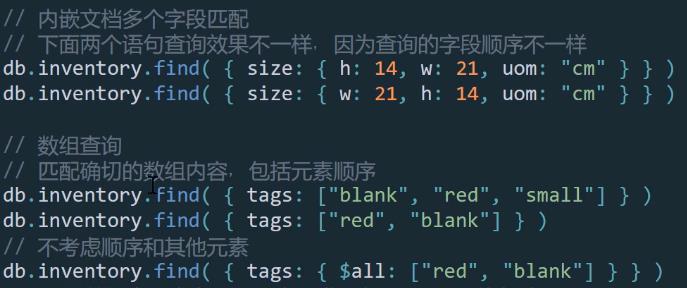
在加上本身的内嵌文档中数据查询 in all 满足一个就行,全部满足

查询摘要
db.collection.find(query, projection)- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。查询时返回 文档中所有键值, 只需省略该参数即可(默认省略)。
- 需要以易读的方式来读取数据,可以使用 pretty() 方法;

这都是逻辑符,这个是通用的。
查询其他操作
- 字段选择:db.inventory.find(,'item':1)
- 字段排除: db.inventory.find(,'item':0)
- 数组子元素选择:db.inventory.find(,'tags':'$slice':[1,2],'tags':1) $slice可以取两个元素数组,分别表示跳过和限制的条数;



这在使用中可以用得到。
// 分页查询,并排序
// offset limit
db.inventory.find().skip(2).limit(2).sort(qty:1);
db.inventory.find().sort(qty:1);聚合函数
// 单用途聚合操作
db.inventory.distinct("status");
// 要避免不通过查询器,直接使用count方法,会导致近似计数。
db.inventory.find( status: "A" ).count(); // 4.0弃用
// 基于count方法而来,估算集合中的文档数
db.inventory.estimatedDocumentCount();
// 通过对数据进行统计的,返回准确的计数,通过聚合计算而来
db.inventory.countDocuments( status: "A" )
// 统计集合中状态为A的文档数
db.inventory.aggregate([
$match: status: "A" ,
$group: _id: null, totalStatusADoc: $sum: 1
])计算 和估算操作,map-reduce.进行聚合查询。
统计可用物品这些。
更新操作语法
db.collection.updateOne()
db.collection.updateMany()
db.collection.replaceOne()- 所有写操作都是单个文档级别的原子操作
- _id无法被修改
- 更新操作对字段顺序的影响,一般都保留文档字段的原始顺序
- query,查询条件,类似sql update查询的where
- update,update的对象和一些更新的操作符(如 $,$inc...)等,类似sql update查询的set
- upsert,可选,表示如果记录不存在,是否插新文档,true为插入,默认false,不插入
- multi,可选,默认false,只更新找到的第一条记录。true,匹配的多条记录全部更新
- writeConcern,可选,写策略
- collation,可选,索引语言规则
- arrayFilters,可选,过滤文档数组,用于确定更新操作要修改数组中的具体元素
- hint,可选的,指定查询希望使用的索引字段,如 果没有这个索引就会报错

这都是更新操作。
更新操作符


更新单个文档,会更新第一个匹配到的文档
// UPDATE inventory SET size.uom='cm', status='P', lastModified=now() WHERE item = "paper"
db.inventory.updateOne(
item: "paper" ,
$set: "size.uom": "cm", status: "P" ,
$currentDate: lastModified: true
)批量更新
// UPDATE inventory SET size.uom='in', status='P', lastModified=now() WHERE qty < 50
db.inventory.updateMany(
"qty": $lt: 50 ,
$set: "size.uom": "in", status: "P" ,
$currentDate: lastModified: true
)db.inventory.replaceOne(
item: "paper" ,
item: "paper", instock: [ warehouse: "A", qty: 60 , warehouse: "B", qty: 40 ]
)把文档做掉进行更新。

直接隐式转换,
可以支持任意修改已存在字段的数据类型,直接转换数字



往tags数组中增加元素,如果tags字段不存在则会新增该字段,如果值有重复就不处理
数组中添加数组元素,并不是添加多个值
通过$each,往数组中添加多个值

更新所有记录,删除tags数组的red、big元素
db.inventory.find( tags: $in: ["red", "big"] )
db.inventory.update(
,
$pull: tags: $in: [ "red", "big" ] ,
multi: true
)删除length数组中包含50/90的元素
// 删除length数组中包含50/90的元素
db.inventory.update( item: "apple" , $pullAll: length: [ 150, 390 ] )
// 从前弹出一个元素,类似队列的pop api
db.inventory.update( item:"mobile", $pop: scores: -1 )
// 从后弹出两个元素
db.inventory.update( item:"mobile", $pop: scores: 2 )
以上是关于NoSQL介绍及MongoDB的安装及使用的主要内容,如果未能解决你的问题,请参考以下文章