机器学习--逻辑回归的原理与基础实现
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习--逻辑回归的原理与基础实现相关的知识,希望对你有一定的参考价值。
概述
逻辑回归(Logistic Regression,简称LR),其实是一个很有误导性的概念,虽然它的名字中带有“回归”两个字,但是它最擅长处理的却是分类问题。
LR分类器适用于各项广义上的分类任务,例如:评论信息的正负情感分析(二分类)、用户点击率(二分类)、用户违约信息预测(二分类)、垃圾邮件检测(二分类)、疾病预测(二分类)、用户等级分类(多分类)等场景。我们这里主要讨论的是二分类问题。

一、逻辑回归
逻辑回归和线性回归本质上都是得到一条直线,不同的是,线性回归的直线是尽可能去拟合输入变量X的分布,使得训练集中所有样本点到直线的距离最短;而逻辑回归的直线是尽可能去拟合决策边界,使得训练集样本中的样本点尽可能分离开。因此,两者的目的是不同的。
- Sigmoid函数

- 通过代码理解Sigmoid函数
import numpy as np
import math
import matplotlib.pyplot as plt
%matplotlib inline
X = np.linspace(-5,5,200)
y = [1/(1+math.e**(-x)) for x in X]
plt.plot(X,y)
plt.show()
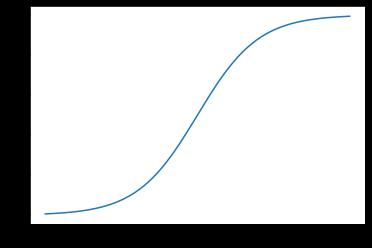
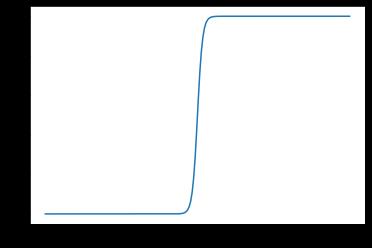
X = np.linspace(-60,60,200)
y = [1/(1+math.e**(-x)) for x in X]
plt.plot(X,y)
plt.show()
- 损失函数

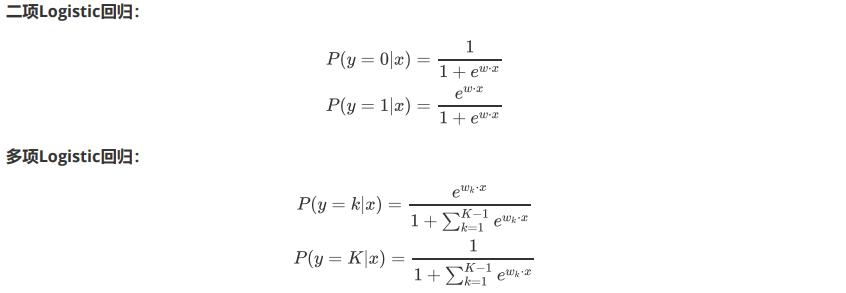

- 逻辑回归与线性回归
逻辑回归和线性回归是两类模型,逻辑回归是分类模型,线性回归是回归模型。
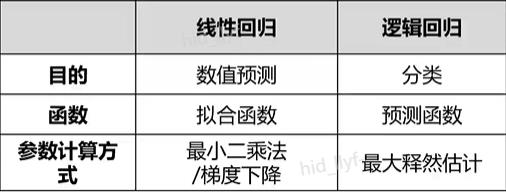
- 参考文章:
【ML】线性回归和逻辑回归的联系和区别:这篇文章中有最大似然估计的通俗简单理解
浅析机器学习:线性回归 & 逻辑回归:这篇文章简单推导了线性回归到逻辑回归的变换,介绍了几率几率和概率的不同之处
全面解析并实现逻辑回归(Python):这篇文章以模型、学习目标、优化算法的角度解析逻辑回归(LR)模型,并以Python从头实现LR训练及预测。
二、小案例
所用的数据集:./data/info.txt【我设置的0积分免费下载,若不是,请告知我!感谢!】
# 导入相关包
import numpy as np
# 从sklearn导入LogisticRegression方法
from sklearn.linear_model import LogisticRegression
# 导入划分训练集和测试集的方法
from sklearn.model_selection import train_test_split
import os
# 读取文件
if not os.path.exists('./data/info.txt'):
print('文件不存在!')
else:
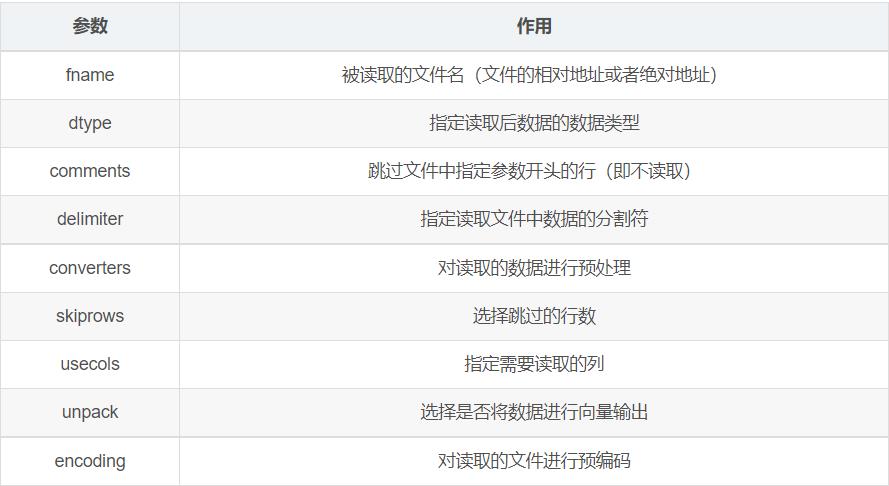
data = np.loadtxt('./data/info.txt',delimiter=",")# delimiter读取文件的分隔符
print(data)
[[2.697e+03 6.254e+03 1.000e+00]
[1.872e+03 2.014e+03 0.000e+00]
[2.312e+03 8.120e+02 0.000e+00]
[1.983e+03 4.990e+03 1.000e+00]
[9.320e+02 3.920e+03 0.000e+00]
[1.321e+03 5.583e+03 1.000e+00]
[2.215e+03 1.560e+03 0.000e+00]
[1.659e+03 2.932e+03 0.000e+00]
[8.650e+02 7.316e+03 1.000e+00]
[1.685e+03 4.763e+03 0.000e+00]
[1.786e+03 2.523e+03 1.000e+00]]
# 划分训练集与测试集
train_x, test_x, train_y, test_y = train_test_split(data[:, 0:2], data[:, 2], test_size=0.3)
# data[:, 0:2] 前两列 特征值
# data[:, 2] 最后一列 标签值
# test_size=0.3 测试数据所占比列
train_x
array([[1659., 2932.],
[2215., 1560.],
[2312., 812.],
[ 865., 7316.],
[ 932., 3920.],
[2697., 6254.],
[1786., 2523.]])
test_x
array([[1983., 4990.],
[1872., 2014.],
[1321., 5583.],
[1685., 4763.]])
train_y
array([0., 0., 0., 1., 0., 1., 1.])
test_y
array([1., 0., 1., 0.])
# 调用sklearn里面的方法
model = LogisticRegression()
# 通过训练集得到训练后的模型
model.fit(train_x, train_y)
# 利用测试数据集测试模型,并输出结果
# 测试模型
pred_y = model.predict(test_x)
# 输出判断预测是否与真实值相等
print(pred_y == test_y)
print(model.score(test_x, test_y))
[ True True True False]
0.75
pred_y
array([1., 0., 1., 1.])
test_y
array([1., 0., 1., 0.])
model.score(test_x, test_y)的作用就是将数据pred_y和test_y进行对比
总结
- numpy的loadtxt()方法
以上是关于机器学习--逻辑回归的原理与基础实现的主要内容,如果未能解决你的问题,请参考以下文章