元宇宙中可跨语种交流,Meta 发布新语音模型,支持128种语言无障碍对话
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了元宇宙中可跨语种交流,Meta 发布新语音模型,支持128种语言无障碍对话相关的知识,希望对你有一定的参考价值。
编译 | 禾木木
出品 | AI科技大本营(ID:rgznai100)
语言交流是人类互动一种自然的方式,随着语音技术的发展,我们可以与设备以及未来的虚拟世界进行互动,由此虚拟体验将于我们的现实世界融为一体。
然而,语音技术仅适用于全世界数千种语言中的一小部分。基于有限标记数据的少样本学习,甚至无人监督的语音识别是有帮助的,但这些方法的成功取决于自监督模型的质量。
近日,Meta 正式发布 XLS-R ——一套用于各类语音任务的新型自监督模型。XLS-R 由海量公共数据训练而成,能够将传统多语言模型的语言支持量增加两倍以上。
而 XLS-R 作为元宇宙社交中必不可少的一环,可以帮助母语不同的人在元宇宙中直接对话。
为了能够通过单一模型实现对多种语言的理解,Meta 对 XLS-R 进行了微调,使它能够执行语音识别、语音翻译和语言识别等功能。XLS-R 在 BABEL、CommonVoice 以及 VoxPopuli 语音识别基准测试,CoVoST-2 的外语到英文翻译基准测试,以及 VoxLingua107 语言识别基准测试中都有了先进的水平。
为了进一步使这些能够被广泛地访问,Meta 与 Hugging Face 联手发布了模型在 Github 上。
https://huggingface.co/spaces/facebook/XLS-R-2B-22-16
XLS-R 工作原理
XLS-R 基于 wav2vec 2.0 训练集上接受了超过 436,000 小时的公开语音录音训练,这是对语音表示进行自监督学习的方法。这样的训练量已经达到去年发布的最好的模型 XLSR-53 的 10 倍。利用从会议记录到有声读物等不同来源的语音数据,XLS-R 的语言已扩展到 128 种,涵盖的语言数量是钱袋模型的近2.5倍。
Meta 在4种主要多语言语音识别测试中对 XLS-R 做出评估,发现在测试的 37 种语言中,它的表现超越先前的模型工作;具体来说,在 BABEL 的 5 种语言、CommonVoice 的 10 种语言、MLS 的 8 种语言和 VoxPopuli 的 14 种语言上进行了尝试。
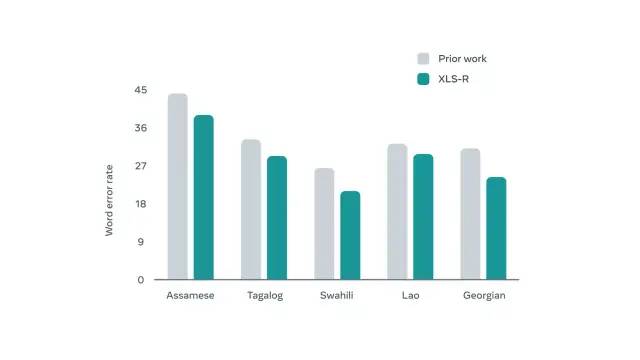
BABEL 上的单词错误率基准测试结果。XLS-R 较前代模型实现了显著改进。
Meta 还评估了语音翻译模型,将录音直接翻译成另一种语言。为了打造一套能够执行多种任务的模型, Meta 同时在 CoVoST-2 基准测试的数个不同翻译方向上对 XLS-R 进行了微调。最后结果是能够在英语与多达 21 种语言之间实现内容互译。
在使用 XLS-R 对英语以外的其他语言进行编码时,获得了显著的改进,这也是多语言语音表达领域的一次突破。XLS-R 在低资源语言学习中实现了显著改进,例如印尼语到英语的翻译,其中 BLEU 准确率平均翻了一番。BLEU 指标的提升是指模型给出的自动翻译结果与处理同一内容的人工翻译结果间重合度更高,代表着模型在改进口语翻译能力方面迈出了一大步。
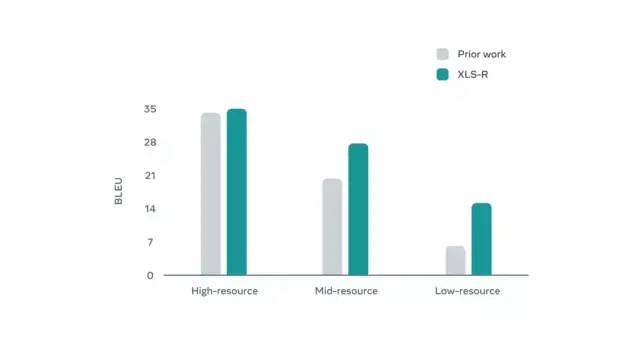
以 BLEU 指标衡量的自动语音翻译准确率,其中较高值表示 XLS-R 从高资源语言(例如法语、德语)、中资源语言(例如俄语、葡萄牙语)或低资源语言(例如泰米尔语、土耳其语)语音记录翻译至英语时的准确率。
结语
XLS-R 表明,扩展跨语言预训练可以进一步提高低资源语言的性能。它不仅提高了语音识别的性能,还能将外语到英语的语音翻译的准确性提高了一倍以上。XLS-R 是朝着能够理解多种不同语言单一模型迈出的重要一步,它是所知道的利用公共数据进行多语言预训练的最大努力。
Meta 相信这个方向将使机器学习应用程序更好地理解所有人类语音并促进进一步研究,使语音技术在全球范围内更容易使用,尤其是在服务欠缺的人群中。Meta 将通过不断开发新方法来从较少的监督中学习,并将方法扩展到全球 7,000 多种语言,实现算法的持续更新。
参考链接:
https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages/
以上是关于元宇宙中可跨语种交流,Meta 发布新语音模型,支持128种语言无障碍对话的主要内容,如果未能解决你的问题,请参考以下文章
Meta发布支持128种语言的新语音模型:指向元宇宙跨语种交流,可在线试玩
“十四五”信通行业发展规划:2025年区块链设施服务能力将显著增强 | 产业区块链发展周报...