『Sklearn』自带数据集API
Posted 叠加态的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了『Sklearn』自带数据集API相关的知识,希望对你有一定的参考价值。
自带数据集类型如下:
# 自带小型数据集
# sklearn.datasets.load_<name>
# 在线下载数据集
# sklearn.datasets.fetch_<name>
# 计算机生成数据集
# sklearn.datasets.make_<name>
# svmlight/libsvm格式数据集
# sklearn.datasets.load_svmlight_file(path)
# mldata.org在线下载网站数据集
# sklearn.datasets.fetch_mldata(path)
以鸢尾花数据为例,介绍一下自带数据集的使用。
基本使用:
import sklearn import matplotlib.pyplot as plt # 载入数据集 iris = sklearn.datasets.load_iris() # 鸢尾花数据 # 打印数据集中的类型 print(iris.keys()) # dict_keys([\'target\', \'data\', \'feature_names\', \'DESCR\', \'target_names\']) # target:标签 # data :数据 # feature_names :特征名称,list,按照data中排序生成 # target_names : 标签名称,list,按照target中排序生成 print(iris.target.shape) print(iris.data.shape) print(iris.feature_names) print(iris.target_names) # (150,) # (150, 4) # [\'sepal length (cm)\', \'sepal width (cm)\', \'petal length (cm)\', \'petal width (cm)\'] # [\'setosa\' \'versicolor\' \'virginica\']
使用一个特征绘制柱状图:
x_index = 3
colors = [\'blue\', \'red\', \'green\']
for label, color in zip(range(len(iris.target_names)), colors):
plt.hist(iris.data[iris.target==label, x_index],
label = iris.target_names[label], color=color)
plt.xlabel(iris.feature_names[x_index])
plt.legend(loc=\'upper right\')
plt.show()
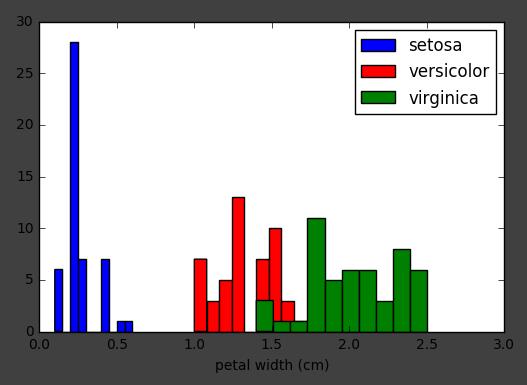
使用两个特征绘制散点图:
x_index = 0
y_index = 1
colors = [\'blue\', \'red\', \'green\']
for label, color in zip(range(len(iris.target_names)), colors):
plt.scatter(iris.data[iris.target == label, x_index],
iris.data[iris.target == label, y_index],
label=iris.target_names[label], # 图例内容
color=color)
plt.xlabel(iris.feature_names[x_index])
plt.ylabel(iris.feature_names[y_index])
plt.legend(loc=\'upper right\') # 显示图例
plt.show()
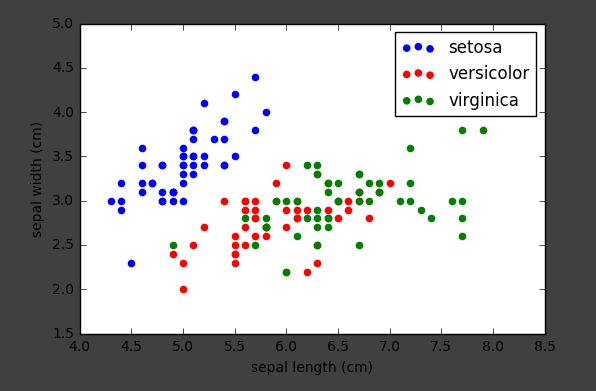
其他自带小型数据集(load的)均同理,以后遇到教程使用时不用再慌了。
以上是关于『Sklearn』自带数据集API的主要内容,如果未能解决你的问题,请参考以下文章