k8s核心组件详细介绍教程(配超详细实例演示)
Posted Baret-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s核心组件详细介绍教程(配超详细实例演示)相关的知识,希望对你有一定的参考价值。
- 本文实验环境基于上篇文章手把手从零开始搭建k8s集群超详细教程
- 本文根据B站课程云原生Java架构师的第一课K8s+Docker+KubeSphere+DevOps学习总结而来
k8s核心组件介绍
k8s中创建资源的方式有两种,一种是通过对应资源的专用命令来创建,一种是以yaml配置文件的形式来创建,其中以yaml配置文件来创建/删除资源的通用命令如下:
kubectl apply -f 文件名 # 创建资源
kubectl delete -f 文件名 # 删除资源
1. Namespace
Namespace:名称空间,用来对集群资源进行隔离划分(默认只隔离资源、不隔离网络)

当我们使用kubectl get pods -A查看所有应用时,也可以看到对应归属的命名空间

如果我们使用kubect get pods命令,将看不到任何应用,因为该命令是查看默认default名称空间内的应用
📄 命名空间相关命令
# 查看所有的名称空间
[root@k8s-master ~]# kubectl get ns
NAME STATUS AGE
default Active 21h
kube-node-lease Active 21h
kube-public Active 21h
kube-system Active 21h
kubernetes-dashboard Active 20h
# 创建名称空间
kubectl create ns hello
# 删除名称空间(会将该名称空间下的所有资源全部删除)
kubectl delete ns hello
除了用命令行的形式来创建名称空间,我们还可以用yaml配置文件的形式来创建
apiVersion: v1 # 版本号
kind: Namespace # 资源类型
metadata: # 元数据
name: hello
编写以上hello.yaml文件,然后用以下命令来创建/删除hello名称空间
kubectl apply -f hello.yaml
kubectl delete -f hello.yaml
2. Pod
Pod是运行中的一组容器,是kubernetes中应用的最小应用单位在k8s没有出现之前,单个应用都是以容器的方式运行,由doker提供容器时运行环境,K8s的目的就是将这些容器管理起来,将一个或多个容器封装起来成为一个 pod
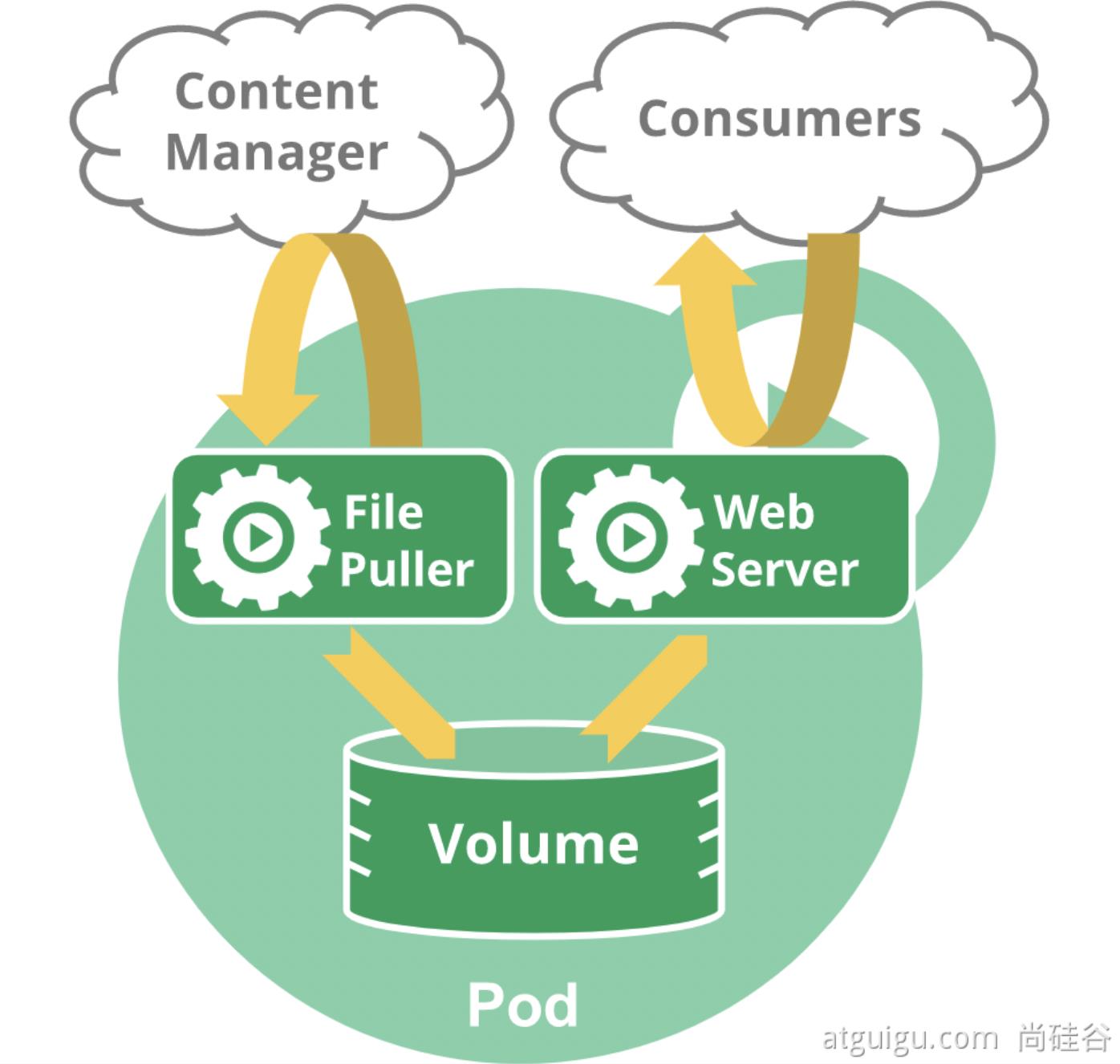

1. pod相关命令
# 创建一个pod,--image用于指定创建pod使用的镜像(因为pod中就是容器)
kubectl run pod名称 --image=镜像名
# 查看default名称空间的Pod
kubectl get pod
# 查看pod描述
kubectl describe pod pod名称
# 删除
kubectl delete pod pod名称1 [pod名称2...] [-n 所在命名空间]
# 查看pod的运行日志
kubectl logs pod名称
# 查看pod更详细信息(可以看到对于每个Pod,k8s都会分配一个ip,集群中的任意一个机器以及任意的应用都能通过Pod分配的ip来访问这个Pod)
kubectl get pod -owide
# 进入到pod容器中
kubectl exec -it pod名称 -- /bin/bash
2. 实例——创建一个包含redis容器的pod
创建一个包含redis容器的pod
kubectl run mypod --image=redis
然后我们用kubectl describe pod mypod可以查看创建pod的详细信息:

其中Events模块可以看到创建pod的流程,首先在default命名空间封装mypod分配到k8s-node2机器,然后拉取redis镜像并创建启动mypod
由于pod本质还是以容器的方式运行,只不过k8s做了封装,所以我们仍然可以通过docker ps命令来查看到mypod容器,由于mypod被分配到k8s-node2机器,所以我们可以在该机器上查看到

此外,我们还可以通过kubectl get pod -owide查看pod的更详细信息,假设这里创建一个包含nginx容器的pod
kubectl run mynginx --image=nginx
# 可以看到对于每个pod,k8s都为其分配了一个ip地址
[root@k8s-master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mynginx 1/1 Running 0 119s 192.168.169.134 k8s-node2 <none> <none>
# 通过pod的ip+端口号进行访问
[root@k8s-master ~]# curl 192.168.169.134
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html color-scheme: light dark;
body width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
可以看到对于每个pod,k8s都为其分配了一个ip地址,我们可以通过pod的ip+端口号进行访问
由于pod本质上也是以容器的方式运行,我们可以通过kubectl exec命令进入到容器中,如下所示:我们进入到mynginx中修改nginx的默认页面
# 进入到mynginx中
[root@k8s-master ~]# kubectl exec -it mynginx -- /bin/bash
root@mynginx:/# ls
bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var
boot docker-entrypoint.d etc lib media opt root sbin sys usr
root@mynginx:/# cd /usr/share/nginx/html/
root@mynginx:/usr/share/nginx/html# ls
50x.html index.html
root@mynginx:/usr/share/nginx/html# echo "hello">index.html
root@mynginx:/usr/share/nginx/html# exit
exit
[root@k8s-master ~]# kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mynginx 1/1 Running 0 10m 192.168.169.134 k8s-node2 <none> <none>
[root@k8s-master ~]# curl 192.168.169.134
hello
可以看到页面修改生效了,不仅在当前master机器可以对该ip进行访问,在集群中的任意机器都可以访问该ip
这里的ip地址所在网段就是我们前面初始化主节点时配置的--pod-network-cidr参数
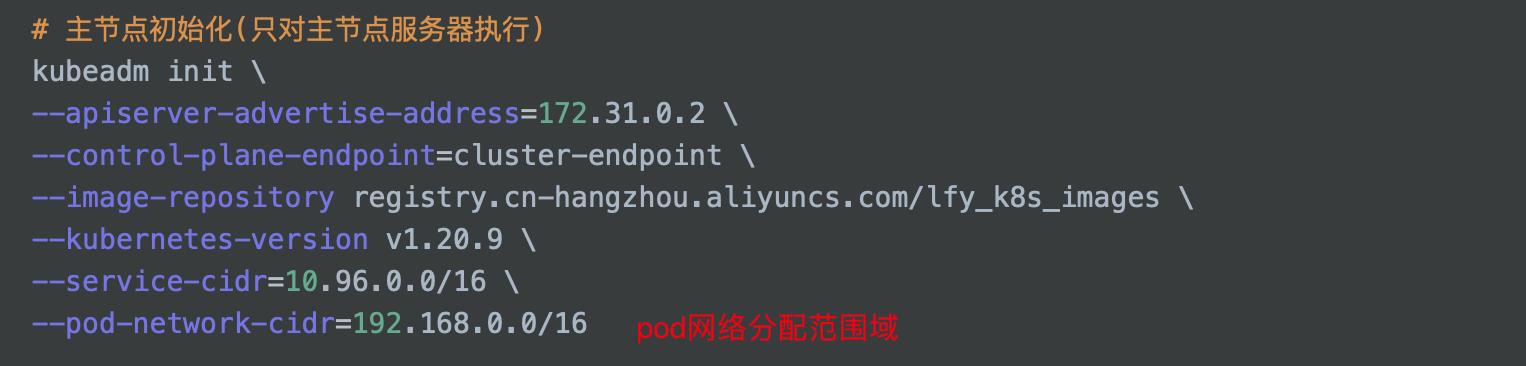
📄 同样,我们可以以yaml文件的方式来创建pod,用kubectl apply -f执行以下文件即可创建包含nginx和tomcat两个容器的pod
apiVersion: v1
kind: Pod
metadata:
labels:
run: mypod
name: mypod
spec:
containers:
- image: nginx
name: nginx
- image: tomcat:8.5.68
name: tomcat
3. Deployments
Deployments:部署应用,用于控制Pod,使Pod拥有多副本、自愈、扩缩容等能力,接下来我们将一一演示

📄 常用命令
# 创建一个deployment
kubectl create deployment deployment名称 --image 镜像名
# 删除deployment
kubectl delete deployment deployment名称
# 查看所有deployment
kubectl get deployment [-A] [-owide]
1. 多副本
一个部署可以包含多个pod副本,在创建Deployment时,我们可以加上--replicas参数来指定pod的个数
比如这里创建一个包含三个nginx容器的应用部署my-dep
# 创建一个deployment应用部署my-dep,控制3个nginx pod
kubectl create deployment my-dep --image=nginx --replicas=3
# 配置文件方式
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-dep
name: my-dep
spec:
replicas: 3
selector:
matchLabels:
app: my-dep
template:
metadata:
labels:
app: my-dep
spec:
containers:
- image: nginx
name: nginx
2. 扩缩容
当我们创建一个deployment来部署应用时,假设在两台机器分别部署了一个pod,但此时应用请求流量过大,两台机器无法负载均衡处理这些请求,此时我们通过k8s的kubectl scale命令一键给多个机器部署该pod,这个过程叫做扩容,与之相反,当应用高峰过去后,我们也可以使用kubectl scale命令下线几台机器上的pod,这个过程叫做缩容,可以腾出不需要的资源
这个过程就叫做扩缩容,除了用命令来控制之外,k8s还能做到动态的扩缩容,根据应用情况自动完成上述操作
# 将上述创建的my-dep从3个pod扩容到5个
kubectl scale deployment/my-dep --replicas=5
# 将my-dep中的pod从5个缩容到2个
kubectl scale deployment/my-dep --replicas=2
也可以通过以下命令来修改创建deployment的yaml文件中的replicas字段来扩缩容
# 修改my-dep应用部署yaml配置文件中的replicas
kubectl edit deployment my-dep
3. 自愈&故障转移
当我们通过deployment来部署应用时,应用在运行过程中可能会碰到服务器停机、容器崩溃、pod被删除等情况,此时k8s的自愈&故障转移能力就能很好的监控以及避免上述情况带来的问题
接下来演示一下Deployments最基础的自愈能力,我们对比分别使用以下两个命令创建容器
# 方式一:直接创建pod运行
kubectl run mynginx --image=nginx
# 方式二:通过创建deployment来部署pod运行
kubectl create deployment mytomcat --image=tomcat
此时,我们开启另一个终端实时监控默认命名空间的所有pod
watch -n -1 kubectl get pod # 间隔1s查看所有pod

假如此时我们删除这两个pod,mynginx和mytomcat-58b8488d44-xfgff

再查看监控,可以发现mynginx直接被删除了,而通过deployment创建的mytomcat-58b8488d44-xfgff也被删除,但是随后又自动启动了一个新的tomcat pod,这就是deployment最常见的自愈能力,当deployment中的某个pod挂掉时,它会自动在其他机器再启动一个一模一样的pod
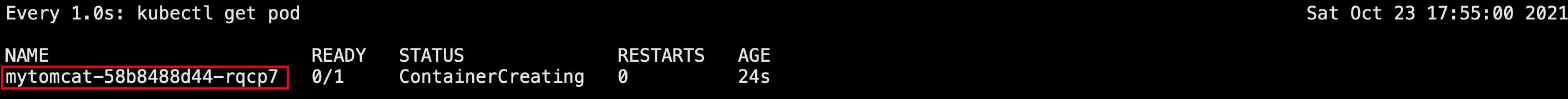
当然还会出现另一种情况,如果运行着pod的某个机器突然断电了,没法在集群中提供服务了,此时k8s会提供故障转移功能,在另一个机器拉起同样的一份pod提供服务,我们以上述创建包含三个nginx容器的应用部署my-dep为例进行演示
补充:由于运行的pod本质上就是一个容器,所以我们可以通过docker ps命令来查看到,比如这里我们查看my-dep中的一个nginx容器

如果我们在青云控制台将k8s-node1机器重启,再次查看所有pod可以看到部署在该机器上的pod容器状态变更为Completed

过了一会,当k8s-node1这台机器重启后,可以看到容器自动重启了一次

但是如果我们直接关机node1机器,等待5分钟后,我们用kubectl get pod -w实时监控,可以看到停止的pod已结束,而是在另一台node2机器重启

总结来说,deployment就是来保证pod数量不被各种意外情况影响
4. 滚动更新
假如当前deployment中的pod版本要从v1升级到v2,但此时用户仍然不断的访问应用,此时怎么保证更新能不间断对用户的处理过程呢?
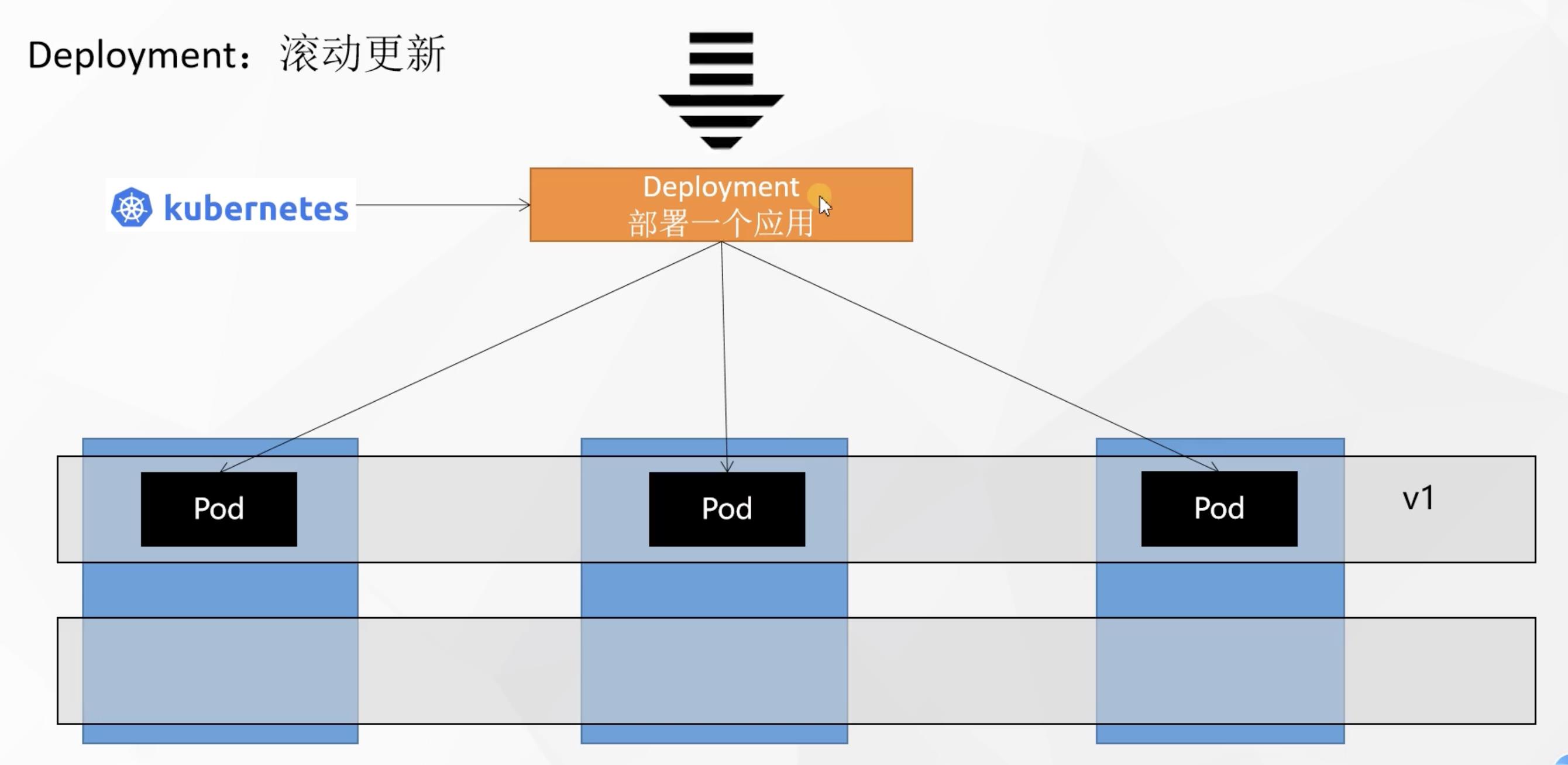
k8s的滚动更新的思想是先启动一个v2版本的pod,等该新版本的pod运行成功了,就将对应老版本的pod下线
以此类推,每个pod的更新都是新版本的pod启动成功再将老版本下线,实现滚动更新的效果,更新过程中无需停机维护,一个pod更新完了没有问题才会更新下一个,避免了以前一次性全部更新成新版本杀死老版本而新版本不可用的问题
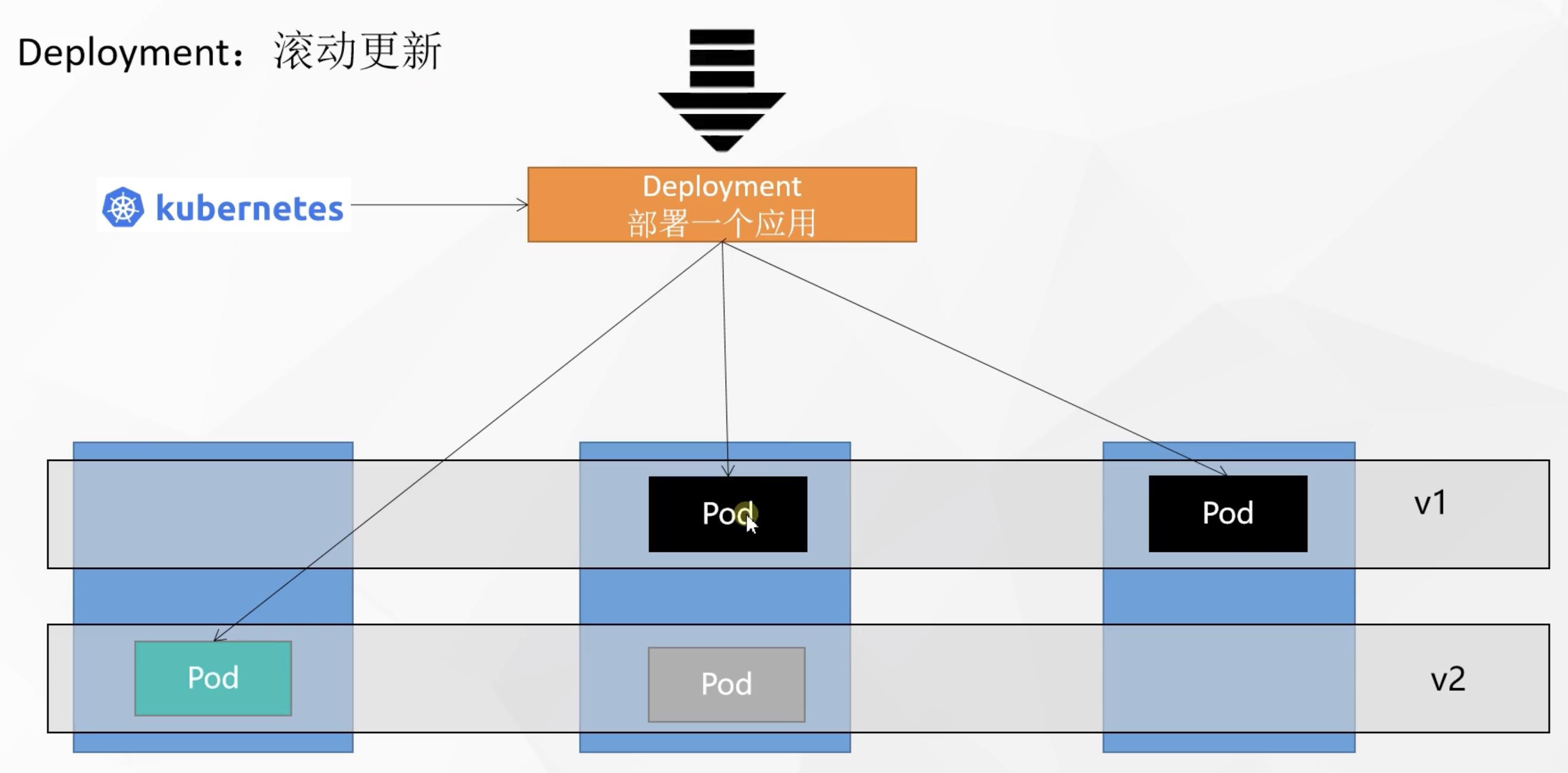
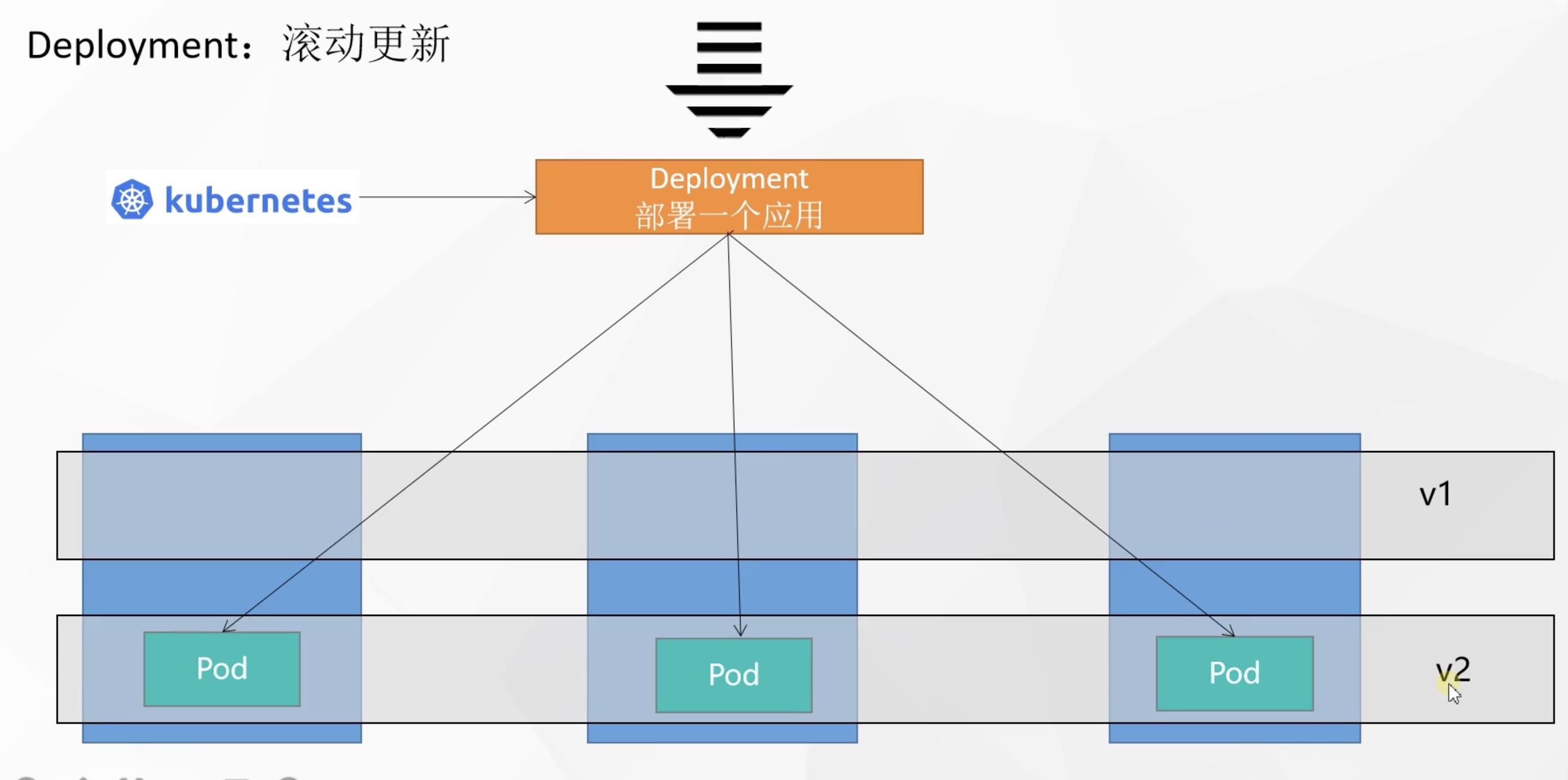
📄 实现滚动更新的命令
# 将pod中的镜像nginx更新版本,--record代表记录此次版本更新
kubectl set image deployment/my-dep nginx=nginx:1.16.1 --record
kubectl rollout status deployment/my-dep
或者通过如下方式修改deployment的配置文件中的image信息实现更新
kubectl edit deployment/my-dep
5. 版本回退
# 查看deployment版本历史记录
kubectl rollout history deployment/my-dep
# 查看某个版本历史详情
kubectl rollout history deployment/my-dep --revision=2
# 回滚(回到上次)
kubectl rollout undo deployment/my-dep
# 回滚(回到指定版本)
kubectl rollout undo deployment/my-dep --to-revision=2
实例演示:

更多
除了Deployment可以部署应用外,类似的,k8s还有StatefulSet、DaemonSet、Job 等类型资源。我们都称为工作负载,不同工作负载的使用方向如下所示,工作中我们按需选择即可

总结:在k8s系统中,虽然pod是应用的真正载体,但我们不直接部署pod,而是使用上述工作负载来控制pod,让每个pod都具有更强大的功能
4. Service
Service:一组 Pods 公开为网络服务的抽象方法,用于pod的服务发现与负载均衡假设我们以前后端分离的方式开发了一个后台管理系统应用,我们将后端通过deployment部署了三份pod位于不同的机器上,此时前端需要请求后端api,但由于每个pod都有自己的一个ip地址,那前端请求的地址到底是三台pod中的哪个呢?为了解决这个问题,k8s提供了
Service统一对所有pod暴露一个对外的公共地址,这样前端只需要请求该service地址即可。此外,service还提供了对于pod的服务发现与负载均衡的功能,负载均衡就是service均匀的分担前端来的请求到每一个pod,服务发现就是假如deployments中pod宕机或新增pod,service能及时发现,将请求交给其他pod处理
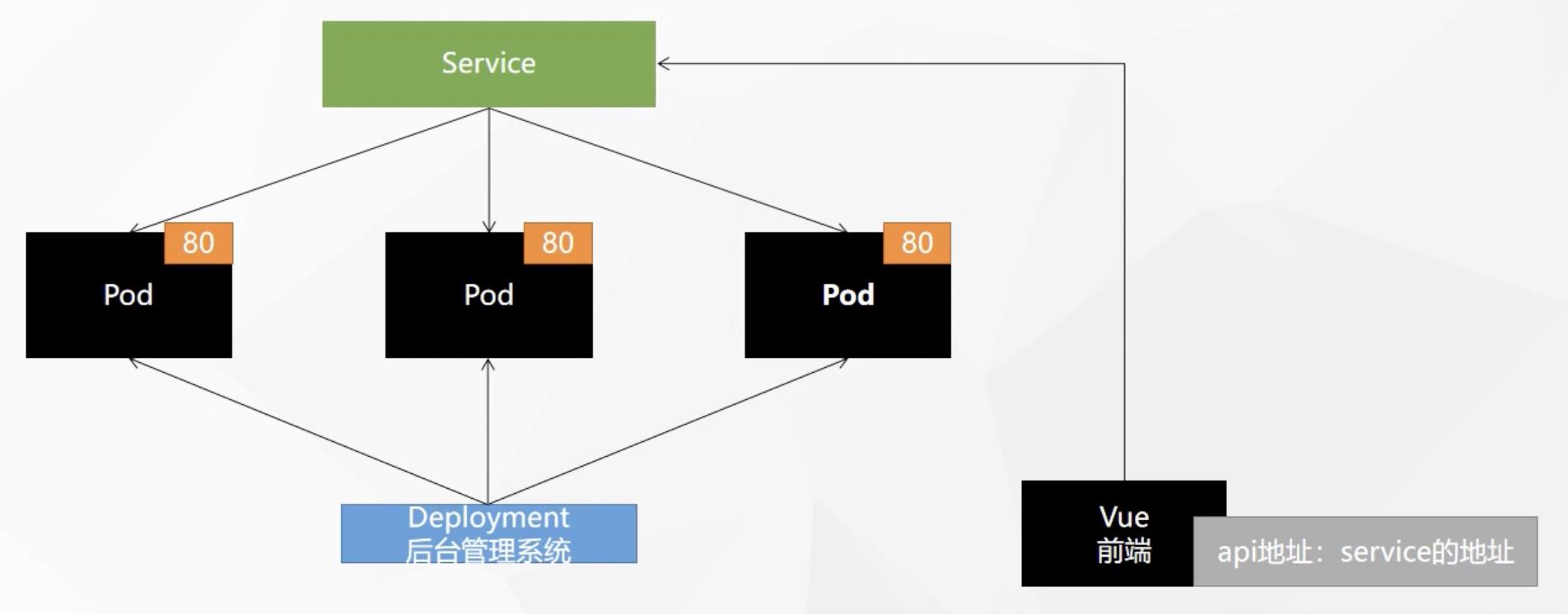
1. service相关命令
# 查看所有service
kubectl get service
# 删除service
kubectl delete service
# 使用标签检索Pod
kubectl get pod -l app=标签名
重要:暴露一个deployee
# 暴露deployee内容器的80端口到service的8000端口(集群内使用service的ip:port即可负载均衡的任意访问)
# 还可以通过域名的方式进行访问,域名的默认名称为`服务名.所在名称空间.svc`
kubectl expose deployment my-dep --port=8000 --target-port=80
同样也可以用配置文件的方式创建service服务
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
selector:
app: my-dep
ports:
- port: 8000
protocol: TCP
targetPort: 80
2. 实例
这里创建一个Deployment包含三个nginx实例,然后分别进入容器内修改其默认的页面更改为hello 1、hello 2、hello 3
[root@k8s-master ~]# kubectl create deployment my-nginx --image=nginx --replicas=3
deployment.apps/my-nginx created
[root@k8s-master ~]# kubectl get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-nginx-6b74b79f57-79lk5 1/1 Running 0 49s 192.168.36.75 k8s-node1 <none> <none>
my-nginx-6b74b79f57-cxzct 1/1 Running 0 49s 192.168.36.76 k8s-node1 <none> <none>
my-nginx-6b74b79f57-gf2sh 1/1 Running 0 49s 192.168.36.74 k8s-node1 <none> <none>
[root@k8s-master ~]# kubectl exec -it my-nginx-6b74b79f57-79lk5 -- /bin/bash
root@my-nginx-6b74b79f57-79lk5:/# cd /usr/share/nginx/html
root@my-nginx-6b74b79f57-79lk5:/usr/share/nginx/html# echo "hello 1" > index.html
root@my-nginx-6b74b79f57-79lk5:/usr/share/nginx/html# exit
exit
[root@k8s-master ~]# kubectl exec -it my-nginx-6b74b79f57-cxzct -- /bin/bash
root@my-nginx-6b74b79f57-cxzct:/# cd /usr/share/nginx/html
root@my-nginx-6b74b79f57-cxzct:/usr/share/nginx/html# echo "hello 2" > index.html
root@my-nginx-6b74b79f57-cxzct:/usr/share/nginx/html# exit
exit
[root@k8s-master ~]# kubectl exec -it my-nginx-6b74b79f57-gf2sh -- /bin/bash
root@my-nginx-6b74b79f57-gf2sh:/# cd /usr/share/nginx/html/
root@my-nginx-6b74b79f57-gf2sh:/usr/share/nginx/html# echo "hello 3" > index.html
root@my-nginx-6b74b79f57-gf2sh:/usr/share/nginx/html# exit
exit
然后我们使用一下命令给my-nginx创建一个service暴露以上三个容器的80端口
# 创建一个service—mydep,将三个nginx容器的80端口映射到my-dep的8000端口
[root@k8s-master ~]# kubectl expose deployment my-nginx --port=8000 --target-port=80
service/my-nginx exposed
[root@k8s-master ~]# kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6d3h
my-nginx ClusterIP 10.96.9.101 <none> 8000/TCP 7s
[root@k8s-master ~]# curl 10.96.9.101:8000
hello 1
[root@k8s-master ~]# curl 10.96.9.101:8000
hello 2
[root@k8s-master ~]# curl 10.96.9.101:8000
hello 1
[root@k8s-master ~]# curl 10.96.9.101:8000
hello 3
[root@k8s-master ~]# curl 10.96.9.101:8000
hello 2
然后可以通过kubectl get service命令查看所有服务,然后我们直接访问my-nginx对应服务的ip:8000即可访问到nginx容器,且service默认为我们做了负载均衡处理
那service是如何判断将哪些pod暴露出来的呢,是因为每个pod在部署期间绑定了一个标签,我们可以通过如下后缀查看到
[root@k8s-master ~]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
my-nginx-6b74b79f57-79lk5 1/1 Running 0 80m app=my-nginx,pod-template-hash=6b74b79f57
my-nginx-6b74b79f57-cxzct 1/1 Running 0 80m app=my-nginx,pod-template-hash=6b74b79f57
my-nginx-6b74b79f57-gf2sh 1/1 Running 0 80m app=my-nginx,pod-template-hash=6b74b79f57
service就是根据标签来选择需要暴露的一组pods
注意:除了通过service的ip:port方式访问之外,还可以在pod内部(注意只能在集群pod内部)通过域名的方式进行访问,域名的默认名称为服务名.所在名称空间.svc
[root@k8s-master ~]# curl my-nginx.default.svc:8000
curl: (6) Could not resolve host: my-nginx.default.svc; Unknown error
# 在pod内部通过service域名方式访问
[root@k8s-master ~]# kubectl exec -it my-nginx-6b74b79f57-79lk5 -- /bin/bash
root@my-nginx-6b74b79f57-79lk5:/# curl my-nginx.default.svc:8000
hello 1
root@my-nginx-6b74b79f57-79lk5:/# curl my-nginx.default.svc:8000
hello 3
root@my-nginx-6b74b79f57-79lk5:/# curl my-nginx.default.svc:8000
hello 2
3. ClusterIP & NodePort模式

以上我们创建service的时候没有通过--type指令指定模式,默认就是ClusterIP模式,但这种模式只能在集群内部进行访问
# 使用ClusterIP模式创建service,等同于没有--type的
kubectl expose deployment my-dep --port=8000 --target-port=80 --type=ClusterIP
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: ClusterIP
如果我们想在集群外,公网上也可以访问,就需要使用NodePort模式,可以看到如果指定NodePort方式创建service默认分配了一个对外端口,默认范围为30000~32767

# 使用NodePort模式创建service
kubectl expose deployment my-nginx --port=8000 --target-port=80 --type=NodePort
apiVersion: v1
kind: Service
metadata:
labels:
app: my-dep
name: my-dep
spec:
ports:
- port: 8000
protocol: TCP
targetPort: 80
selector:
app: my-dep
type: NodePort
通过此种方式就可以直接通过服务器公网ip:端口号进行访问

5. Ingress
Ingress是整个集群流量的统一网关入口,K8s集群中可能会部署很多service服务,这些服务service需要对外提供功能,所有的请求流量都首先需要通过Ingress这一层,由Ingress负责将流量打给哪些服务
比如这里有三台机器,现在要部署一个商城应用,其中使用deployments a来部署订单服务,对应两个pod;deployments b来部署用户服务,对应三个pods;deployments c来部署商品服务,也对应三个pod,这些pods组成了pod网络。在这三个deployments上也对应着三个service、也就是订单服务、用户服务、商品服务,形成了service网络,用于处理pod网络的中的服务发现与负载均衡。不仅如此,K8s在service基础上提供了一个统一的网关入口
Ingress,底层就是一个nginx来帮我们负载均衡,所有的流量都打给Ingress,由其来判断交给哪个service进行处理。
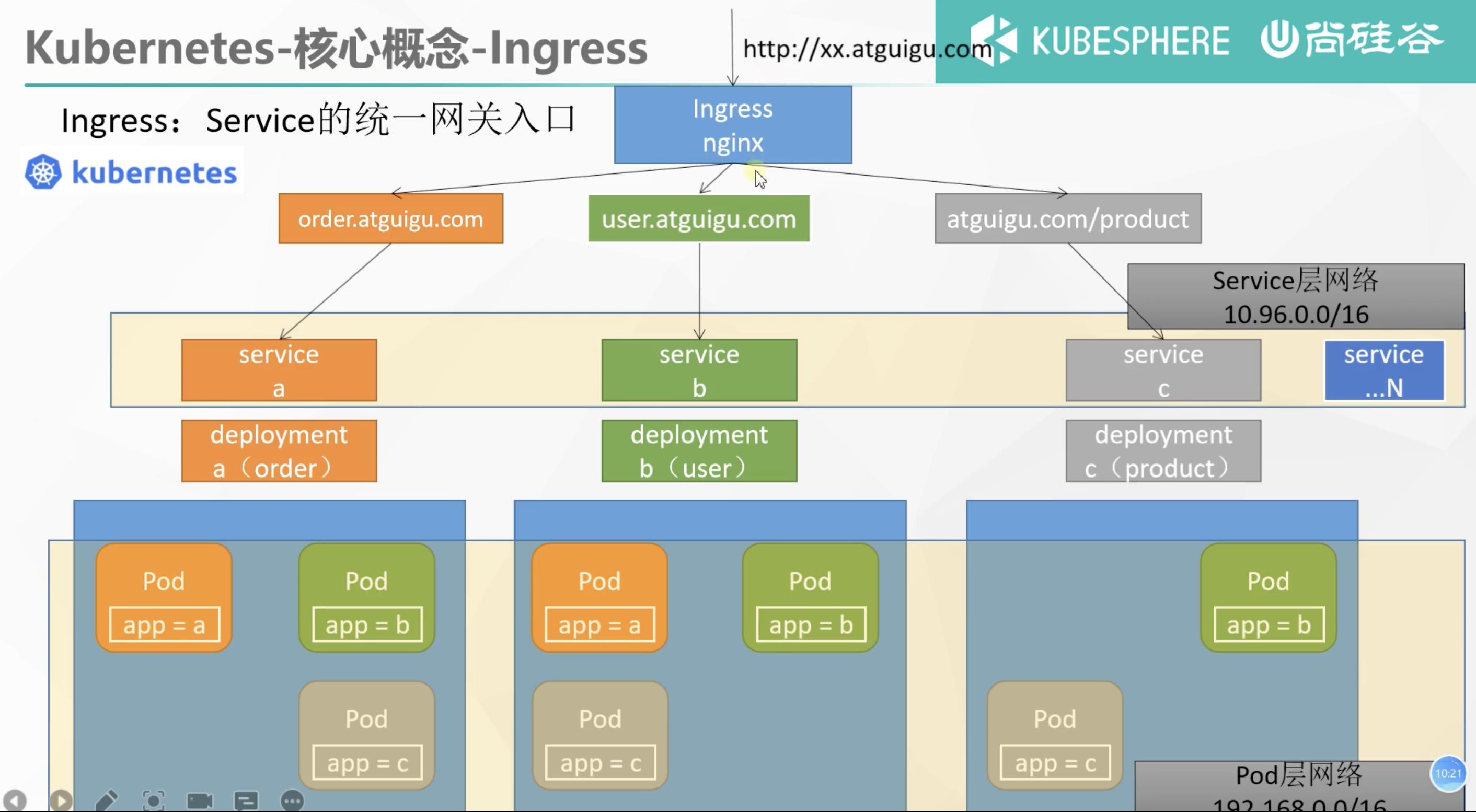
k8s默认未安装Ingress没我们首先进行安装
# 安装Ingress
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.47.0/deploy/static/provider/baremetal/deploy.yaml
或者用以下yaml配置文件进行安装
apiVersion: v1
kind: Namespace
metadata:
name: ingress-nginx
labels:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
---
# Source: ingress-nginx/templates/controller-serviceaccount.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
helm.sh/chart: ingress-nginx-3.33.0
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.47.0
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx
namespace: ingress-nginx
automountServiceAccountToken: true
---
# Source: ingress-nginx/templates/controller-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
labels:
helm.sh/chart: ingress-nginx-3.33.0
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.47.0
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx-controller
namespace: ingress-nginx
data:
---
# Source: ingress-nginx/templates/clusterrole.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
helm.sh/chart: ingress-nginx-3.33.0
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.47.0
app.kubernetes.io/managed-by: Helm
name: ingress-nginx
rules:
- apiGroups:
- ''
resources:
- configmaps
- endpoints
- nodes
- pods
- secrets
verbs:
- list
- watch
- apiGroups:
- ''
resources:
- nodes
verbs:
- get
- apiGroups:
- ''
resources:
- services
verbs:
- get
- list
- watch
- apiGroups:
- extensions
- networking.k8s.io # k8s 1.14+
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- events
verbs:
- create
- patch
- apiGroups:
- extensions
- networking.k8s.io # k8s 1.14+
resources:
- ingresses/status
verbs:
- update
- apiGroups:
- networking.k8s.io # k8s 1.14+
resources:
- ingressclasses
verbs:
- get
- list
- watch
---
# Source: ingress-nginx/templates/clusterrolebinding.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
helm.sh/chart: ingress-nginx-3.33.0
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.47.0
app.kubernetes.io/managed-by: Helm
name: ingress-nginx
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: ingress-nginx
subjects:
- kind: ServiceAccount
name: ingress-nginx
namespace: ingress-nginx
---
# Source: ingress-nginx/templates/controller-role.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
labels:
helm.sh/chart: ingress-nginx-3.33.0
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/version: 0.47.0
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/component: controller
name: ingress-nginx
namespace: ingress-nginx
rules:
- apiGroups:
- ''
resources:
- namespaces
verbs:
- get
- apiGroups:
- ''
resources:
- configmaps
- pods
- secrets
- endpoints
verbs:
- get
- list
- watch
- apiGroups:
- ''
resources:
- services
verbs:
- get
- list