SparkStreaming读取kafka生产的数据,进行累计词频统计后将最新结果存入MySQL数据库
Posted 数据是个宝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkStreaming读取kafka生产的数据,进行累计词频统计后将最新结果存入MySQL数据库相关的知识,希望对你有一定的参考价值。
读取kafka数据,进行累计词频统计,将结果输出到mysql的数据表中!!!!
关于使用sparkstreaming读取kafka生产者生产的数据,并且将每一次输入的数据进行词频累计统计,然后将最终结果存储到MySQL数据库中。学习记录~
一、环境准备
- hadoop集群
- zookeeper
- kafka
- 在idea中添加依赖
<!--spark-Stream实时处理-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.1.1</version>
</dependency>
正常启动后应该有如下进程:
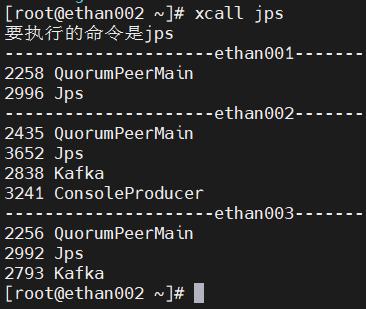
二、环境启动
- 启动hadoop集群
start-all.sh - 启动zookeeper
在zookeeper的bin目录下进行启动
./zkServer.sh start - 启动kafka服务
在kafka的bin目录下进行启动
./kafka-server-start.sh ../config/server.properties - 启动kafka生产者
kafka-console-producer.sh --broker-list ethan002:9092 --topic first
三、编写程序
在idea中编写SparkStreaming代码:
- 注意点:
- 在hdfs上添加检查点/spark/checkpoint
- 编写SQL语言实现存储DStream中的数据
import java.sql.Connection, DriverManager, PreparedStatement
import java.util.Properties
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.Seconds, StreamingContext
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
case class Word(
wordName: String,
count:Int
)
object KafkaDemo
def main(args: Array[String]): Unit =
val conf = new SparkConf().setMaster("local[2]").setAppName("KafkaDemo")
val streamingContext = new StreamingContext(conf,Seconds(5))
val sc = streamingContext.sparkContext
streamingContext.checkpoint("hdfs://ethan001:9000/spark/checkpoint")
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> "ethan002:9092", //从那些broker消费数据
"key.deserializer" -> classOf[StringDeserializer], //发序列化的参数,因为写入kafka的数据经过序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream", //指定group.id
"auto.offset.reset" -> "latest",//指定消费的offset从哪里开始:① earliest:从头开始 ;② latest从消费者启动之后开始
"enable.auto.commit" -> (false: java.lang.Boolean)
//是否自动提交偏移量 offset 。默认值就是true【5秒钟更新一次】,
// true 消费者定期会更新偏移量 groupid,topic,parition -> offset ;
// "false" 不让kafka自动维护偏移量 手动维护偏移
)
// 数组中存放的是在kafka中创建的topic
val topics = Array("first", "t100")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams) //订阅主题
)
val mapDStream: DStream[(String, String)] = stream.map(record => (record.key, record.value)) //转换格式
//对从kafka生产的一次消息进行词频统计
val resultRDD: DStream[(String, Int)] = mapDStream.flatMap(_._2.split(" ")).map((_, 1))//.reduceByKey(_ + _)
//**一下部分实现累计统计写入MySQL**
//**一下部分实现累计统计写入MySQL**
//**一下部分实现累计统计写入MySQL**
/*~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
//定义函数用于累计每个单词出现的次数
val addWordFunction = (currentValues:Seq[Int],previousValueState:Option[Int])=>
//通过spark内部的reduceByKey按key规约,然后这里传入某key当前批次的Seq/List,再计算当前批次的总和
val currentCount = currentValues.sum
//已经进行累加的值
val previousCount = previousValueState.getOrElse(0)
//返回累加后的结果,是一个Option[Int]类型
Some(currentCount+previousCount)
val result = resultRDD.updateStateByKey(addWordFunction)
//将DStream中的数据存储到mysql数据库中
result.foreachRDD(
rdd=>
val url = "jdbc:mysql://localhost:3306/hadoop?useUnicode=true&characterEncoding=UTF-8"
val user = "root"
val password = "123456"
Class.forName("com.mysql.jdbc.Driver").newInstance()
//截断数据表,将数据表原有的数据进行删除
var conn1: Connection = DriverManager.getConnection(url,user,password)
val sql1 = "truncate table word"
var stmt1 : PreparedStatement = conn1.prepareStatement(sql1)
stmt1.executeUpdate()
conn1.close()
rdd.foreach(
data=>
//将数据库数据更新为最新的RDD中的数据集
var conn2: Connection = DriverManager.getConnection(url,user,password)
val sql2 = "insert into word(wordName,count) values(?,?)"
var stmt2 : PreparedStatement = conn2.prepareStatement(sql2)
stmt2.setString(1,data._1.toString)
stmt2.setString(2,data._2.toString)
stmt2.executeUpdate()
conn2.close()
)
)
/*~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~*/
// 打印
//resultRDD.print()
result.print()
// 启动
streamingContext.start()
// 等待计算采集器的执行
streamingContext.awaitTermination()
四、进行测试
-
启动zookeeper
bin/zkServer.sh start -
启动kafka
bin/kafka-server-start.sh ./config/server.properties
-
启动kafka的producer进程
kafka-console-producer.sh --broker-list ethan002:9092 --topic first

-
运行SparkStreaming程序
-
在kafka的producer进程输入数据
[root@ethan002 ~]# kafka-console-producer.sh --broker-list ethan002:9092 --topic first >hello world >hello world >world hello >hello world -
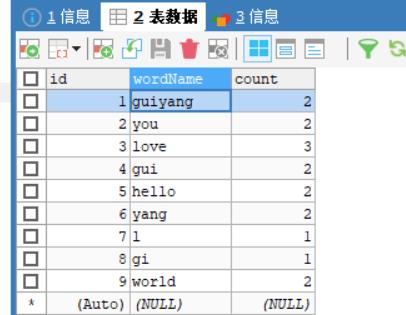
查看结果
-
idea控制台中查看结果

-
在mysql中查看
-
本篇博客实现SparkStreaming读取kafka的数据进行累计词频统计,这里使用的是对mysql表的截断删除原有的数据表中的数,每次都反复的操作数据库,严重影响了执行效率,如果您有其他的方法,希望您能分析分析
以上是关于SparkStreaming读取kafka生产的数据,进行累计词频统计后将最新结果存入MySQL数据库的主要内容,如果未能解决你的问题,请参考以下文章